
神级网络 - UFLDL教程笔记
激活函数:
1)sigmoid函数 - 值域(0,1)
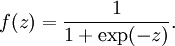
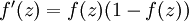
2)tanh函数 - 值域(-1,1)
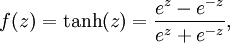
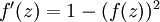
两个函数都扩展至向量表示: ![\textstyle f([z_1, z_2, z_3]) = [f(z_1), f(z_2), f(z_3)]](http://ufldl.stanford.edu/wiki/images/math/d/b/8/db84346dcd6187f0fbb0f6c1a72eecf8.png)
![\textstyle f'([z_1, z_2, z_3]) = [f'(z_1), f'(z_2), f'(z_3)]](http://ufldl.stanford.edu/wiki/images/math/c/7/5/c7515c53b59e670ceee277e06c1229cb.png)
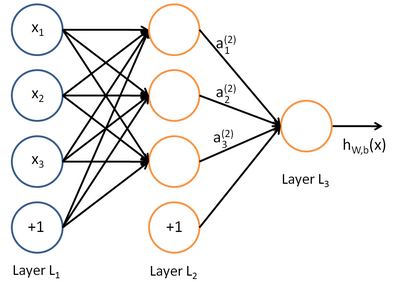
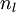 - 网络层数
- 网络层数
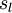 - 第l层的节点数(不包括偏置单元)
- 第l层的节点数(不包括偏置单元)
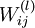 - 第l层第j单元 与 第l+1层第i单元之间的连接参数,大小为
- 第l层第j单元 与 第l+1层第i单元之间的连接参数,大小为
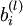 - 第l+1层第i单元的偏置项
- 第l+1层第i单元的偏置项
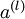 - 第l层的激活值
- 第l层的激活值
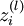 - 第l层第i单元输入加权和(包括偏置单元)
- 第l层第i单元输入加权和(包括偏置单元)
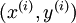 - 样本
- 样本
m - 样本数
α - 学习率
λ - 权重衰减参数,控制方差代价函数两项的相对重要性。
hw,b(x)=a
前向传播
初始化 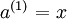
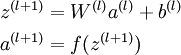 (1)
(1)
后向传播
===> 目标:整体代价函数最小化
![\begin{align}
J(W,b)
&= \left[ \frac{1}{m} \sum_{i=1}^m J(W,b;x^{(i)},y^{(i)}) \right]
+ \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2
\\
&= \left[ \frac{1}{m} \sum_{i=1}^m \left( \frac{1}{2} \left\| h_{W,b}(x^{(i)}) - y^{(i)} \right\|^2 \right) \right]
+ \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2
\end{align}](http://ufldl.stanford.edu/wiki/images/math/4/5/3/4539f5f00edca977011089b902670513.png) (2)
(2)
由单样本代价函数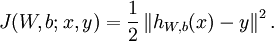 , 加上规则化项减少权重幅度,防止过拟合。
, 加上规则化项减少权重幅度,防止过拟合。
===> 梯度下降法
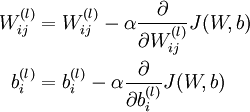 (3)
(3)
问题转化为求后面两个偏导数
===> 整体偏导数转化为单样本偏导数
![\begin{align}
\frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) &=
\left[ \frac{1}{m} \sum_{i=1}^m \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b; x^{(i)}, y^{(i)}) \right] + \lambda W_{ij}^{(l)} \\
\frac{\partial}{\partial b_{i}^{(l)}} J(W,b) &=
\frac{1}{m}\sum_{i=1}^m \frac{\partial}{\partial b_{i}^{(l)}} J(W,b; x^{(i)}, y^{(i)})
\end{align}](http://ufldl.stanford.edu/wiki/images/math/9/3/3/93367cceb154c392aa7f3e0f5684a495.png) (4)
(4)
===> 后向传播求单样本偏导
先求最后一层
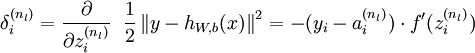
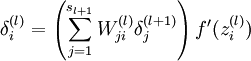
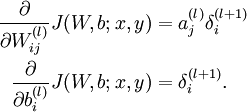 (5)
(5)
神经网络伪代码
当不满足结束条件(迭代次数/结果误差率等):
对所有层,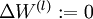
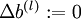 0
0
对每个样本(x,y):
#前向传播
#后向传播
利用公式组(5)计算 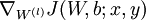 和
和 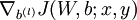
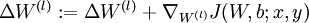
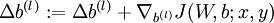
更新权重参数
![\begin{align}
W^{(l)} &= W^{(l)} - \alpha \left[ \left(\frac{1}{m} \Delta W^{(l)} \right) + \lambda W^{(l)}\right] \\
b^{(l)} &= b^{(l)} - \alpha \left[\frac{1}{m} \Delta b^{(l)}\right]
\end{align}](http://ufldl.stanford.edu/wiki/images/math/0/f/7/0f7430e97ec4df1bfc56357d1485405f.png)
--------------------------------------------------
(* "・∀・)ノ ------◎ 去吧!大师球!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号