

斜率优化
斜率优化是一种优化
点击查看代码
给你一个长度为首先不妨先思考
这时候引入斜率优化,不妨将转移点设为
这个式子是可以看做一个一次函数的,我们不妨设
发现没有?我们把这个玩应打开。
我们其实不需要在乎
也就是说,假设存在两个点
这个地方更优秀。
我们继续沿用刚才的思路,设
这时候就是斜率优化要做的事情了。我们可以把式子改成:
但是还没完,
所以我们要变号。
也就是说
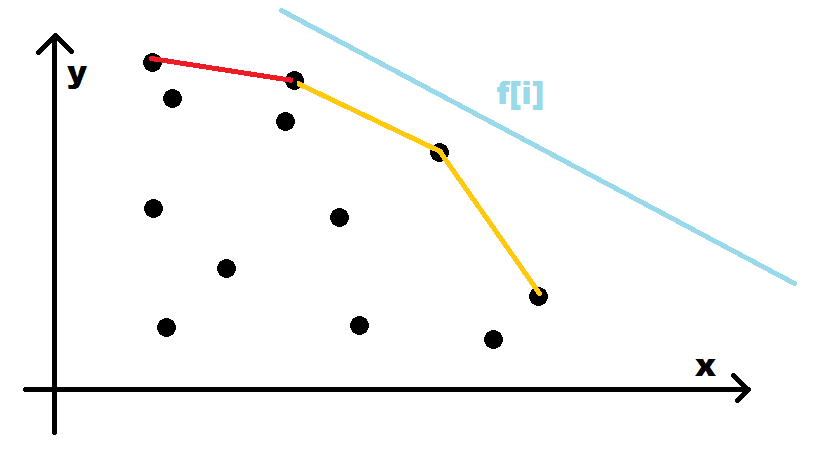
不难发现,这是一个凸包,又具有单调性,我们可以使用单调队列维护。
具体的,我们每一次都是用队头更新答案(看图你会发现这道题这个东西单调递减)。在更新答案时,我们维护队头元素的点即可。使用我们前面推的式子即可轻松维护。同时,为了保证最优性,所以我们还需要在队尾也这样写。
Code
#include<bits/stdc++.h> //fj-fk+a(sumj^2-sumk^2)-b(sumj-sumk)/2a*(sumj-sumk) <sumi using namespace std; #define int long long const int Maxn=2e6; int n,aa,b,c,Sum[Maxn],per[Maxn],dp[Maxn],l,r,q[Maxn]; double slove(int j,int k){ return double( (dp[j]-dp[k]+aa*(Sum[j]*Sum[j]-Sum[k]*Sum[k])+b*(Sum[k]-Sum[j]))/double(2*aa*(Sum[j]-Sum[k])) ); } signed main(){ cin>>n; cin>>aa>>b>>c; for(int i=1;i<=n;i++){ cin>>per[i]; Sum[i]=Sum[i-1]+per[i]; } //memset(dp,~0x3f,sizeof(dp)); dp[0]=0; l=r=1; for(int i=1;i<=n;i++){ while(l<r&&slove(q[l],q[l+1])<=1.0*Sum[i])l++; dp[i]=dp[q[l]]+(Sum[i]-Sum[q[l]])*(Sum[i]-Sum[q[l]])*aa+b*(Sum[i]-Sum[q[l]])+c; while(l<=r&&slove(q[r-1],q[r])>=slove(q[r],i)) r--; q[++r]=i; } cout<<dp[n]; return 0; }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具