
CNSS 2022 招新赛 Reverse方向write up
😇 [Baby]Welcome to Reverse World
step:
打开IDA,F5即可
flag:
cnss{1t_s3ems_l1ke_Y0u_c4n_us3_IDA_n0w!}
💔 [Baby]Find Me
step:
打开IDA,F5反汇编看到如下提示
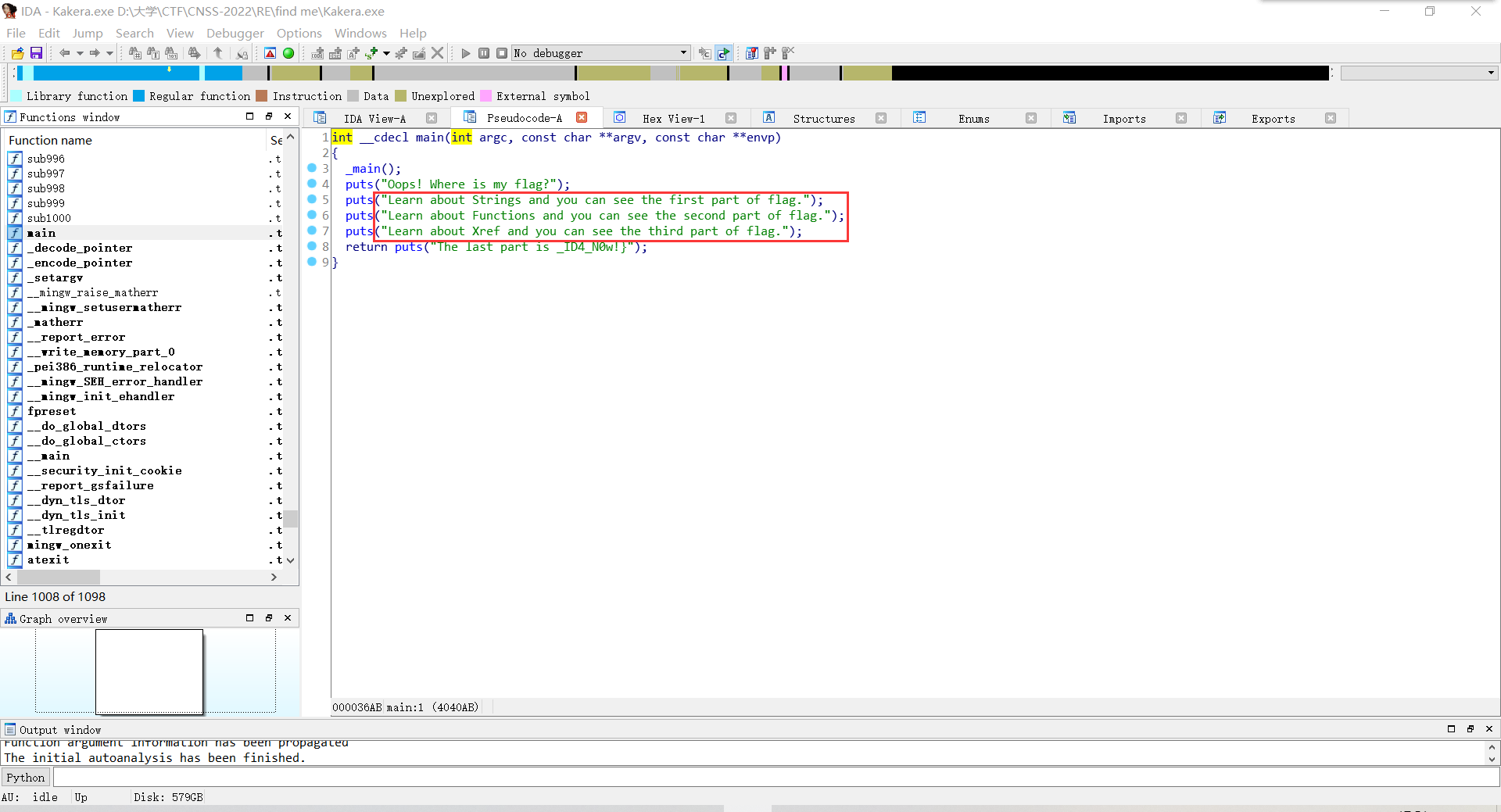
1.string
在Hex View页面按下Alt+T,根据flag格式搜索‘cnss’
获得第一段flag
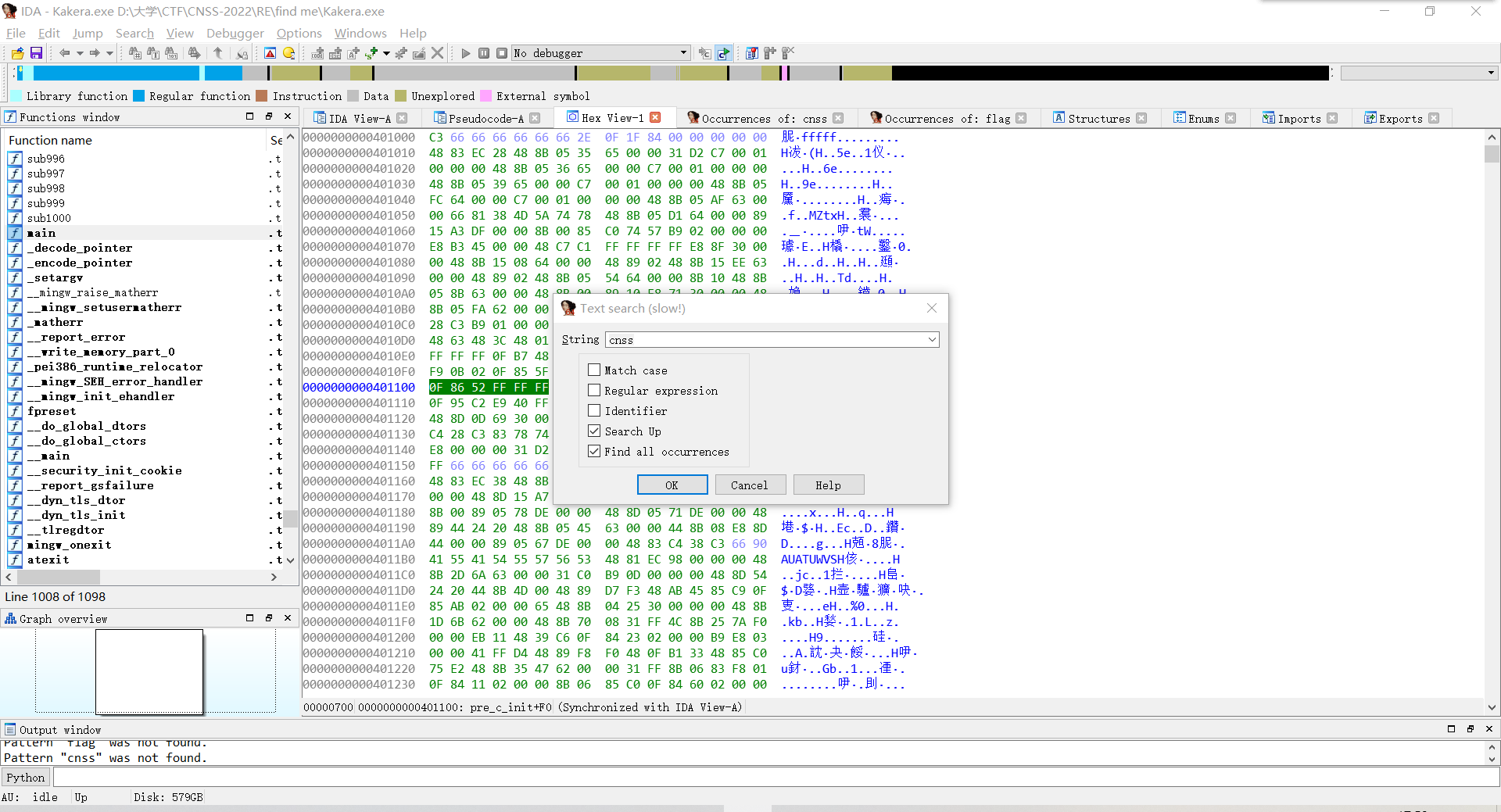
2.function
根据语法与语意找到函数区域藏着的第二段flag
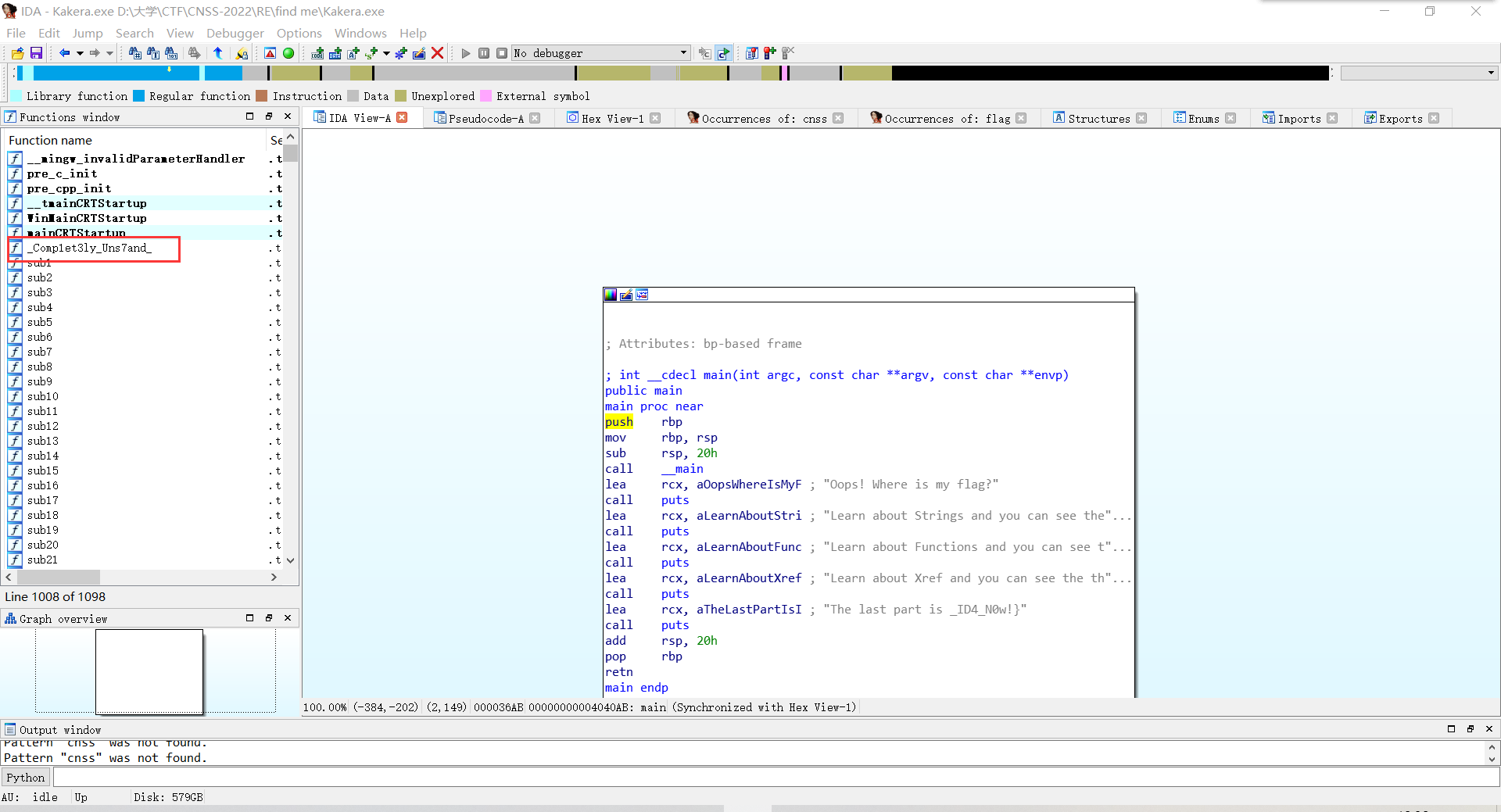
3.xref
右键puts函数,选择xref找到调用puts函数的函数。
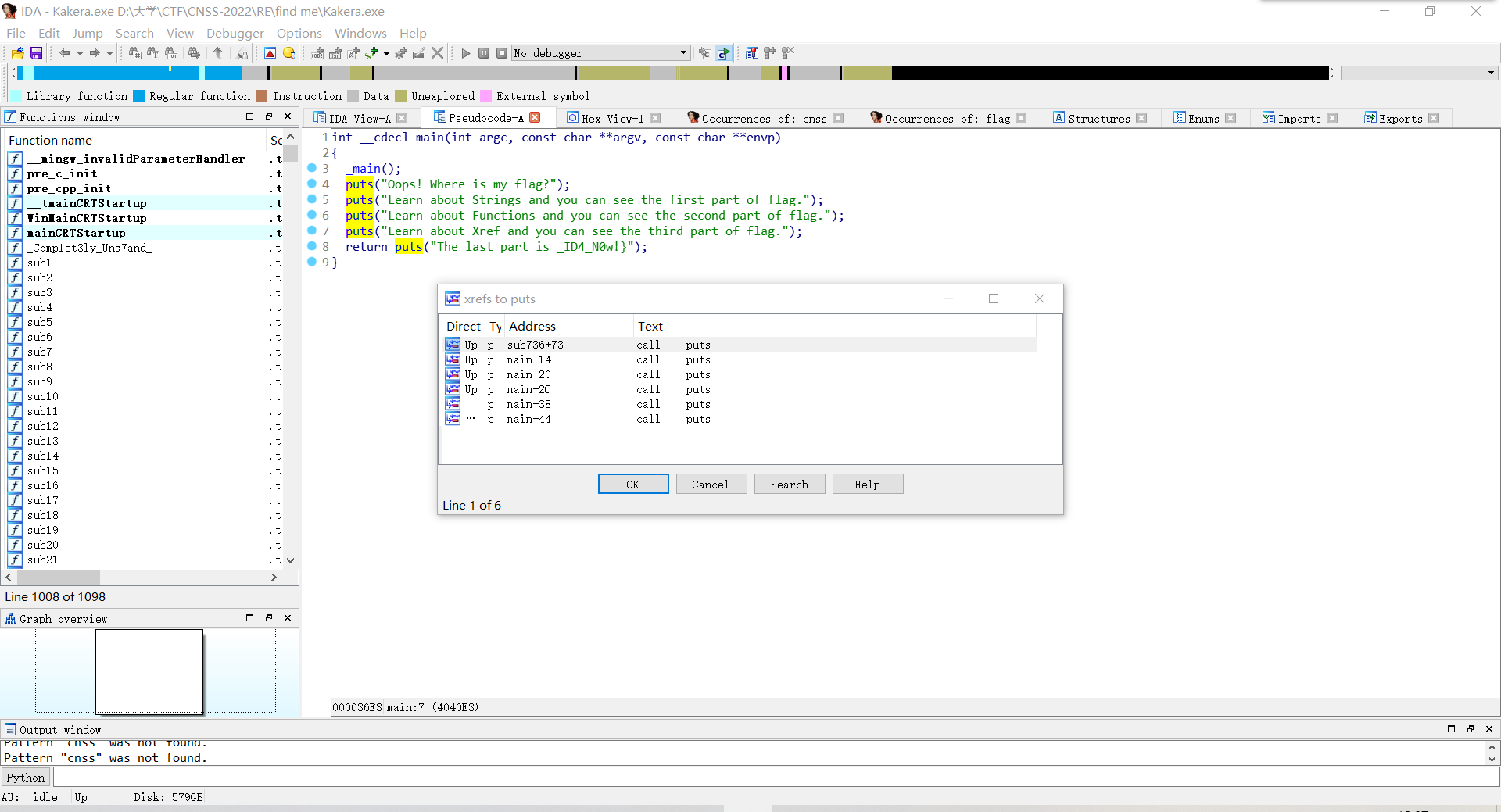
发现第一个长得比较奇怪,点进去。
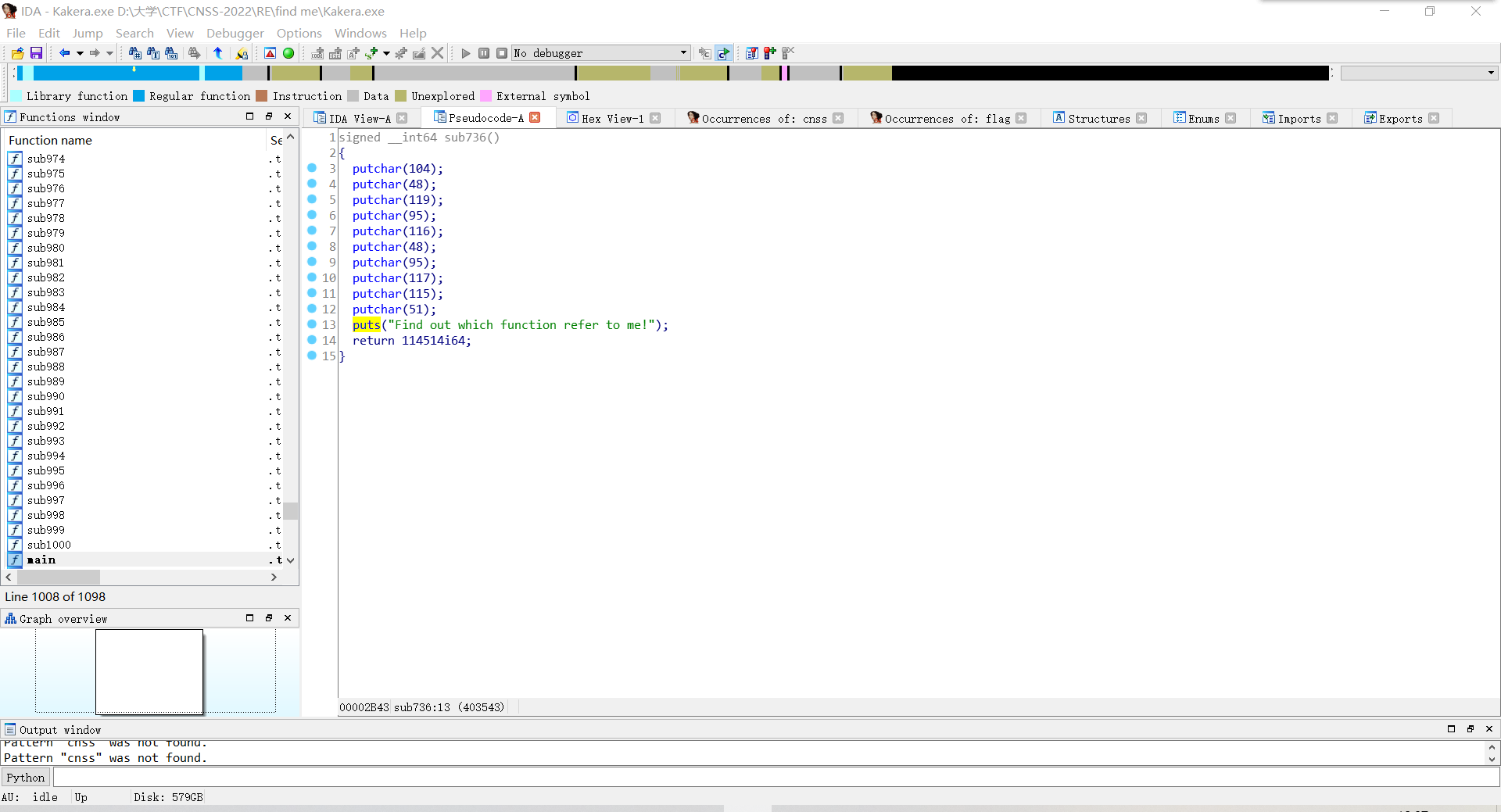
按r将前面的一堆putchar内容ASCII码转换成字符
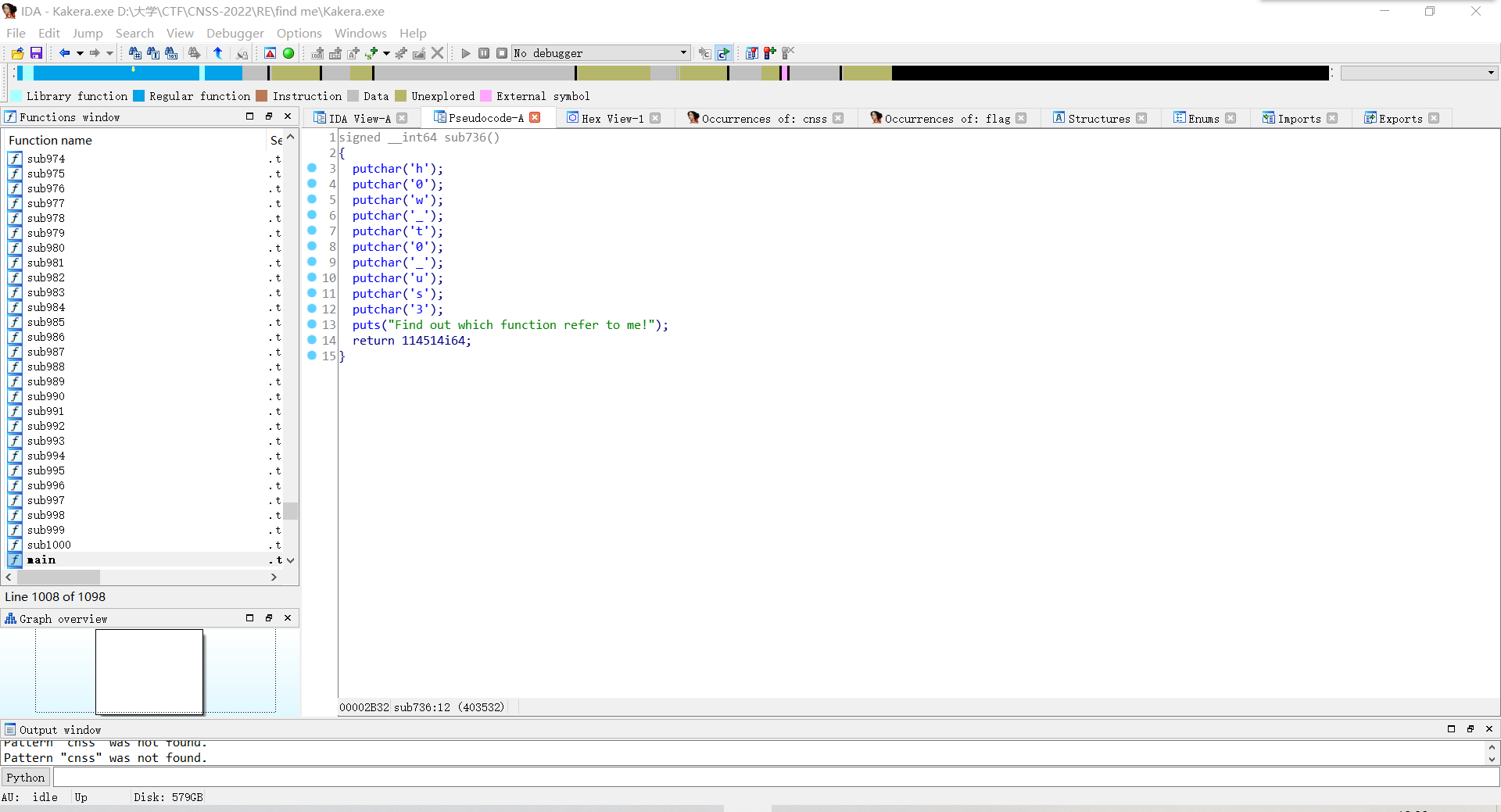
获得第三段flag。
最后一段flag白给
flag:
cnss{W0w!Y0u_Comp1et3ly_Uns7and_h0w_t0_us3_ID4_N0w!}
💫 [Easy] 回レ! 雪月花
hint:
位运算
step:
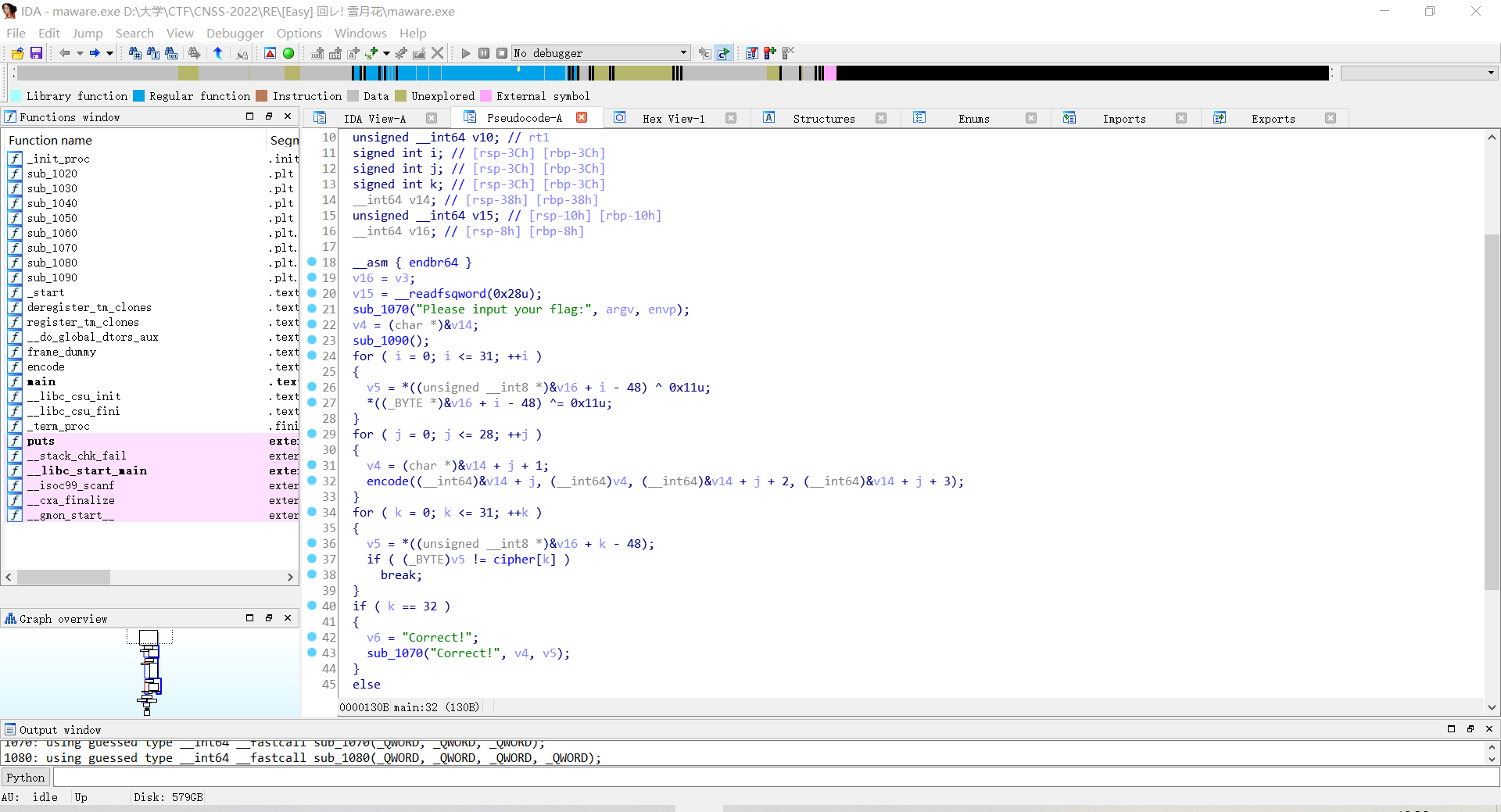
打开IDA,F5
发现是输入一个flag,然后第一个循环是异或0x11,第二个循环是进行一个encode操作,第三个循环是将输入的flag与正确的flag进行比较。
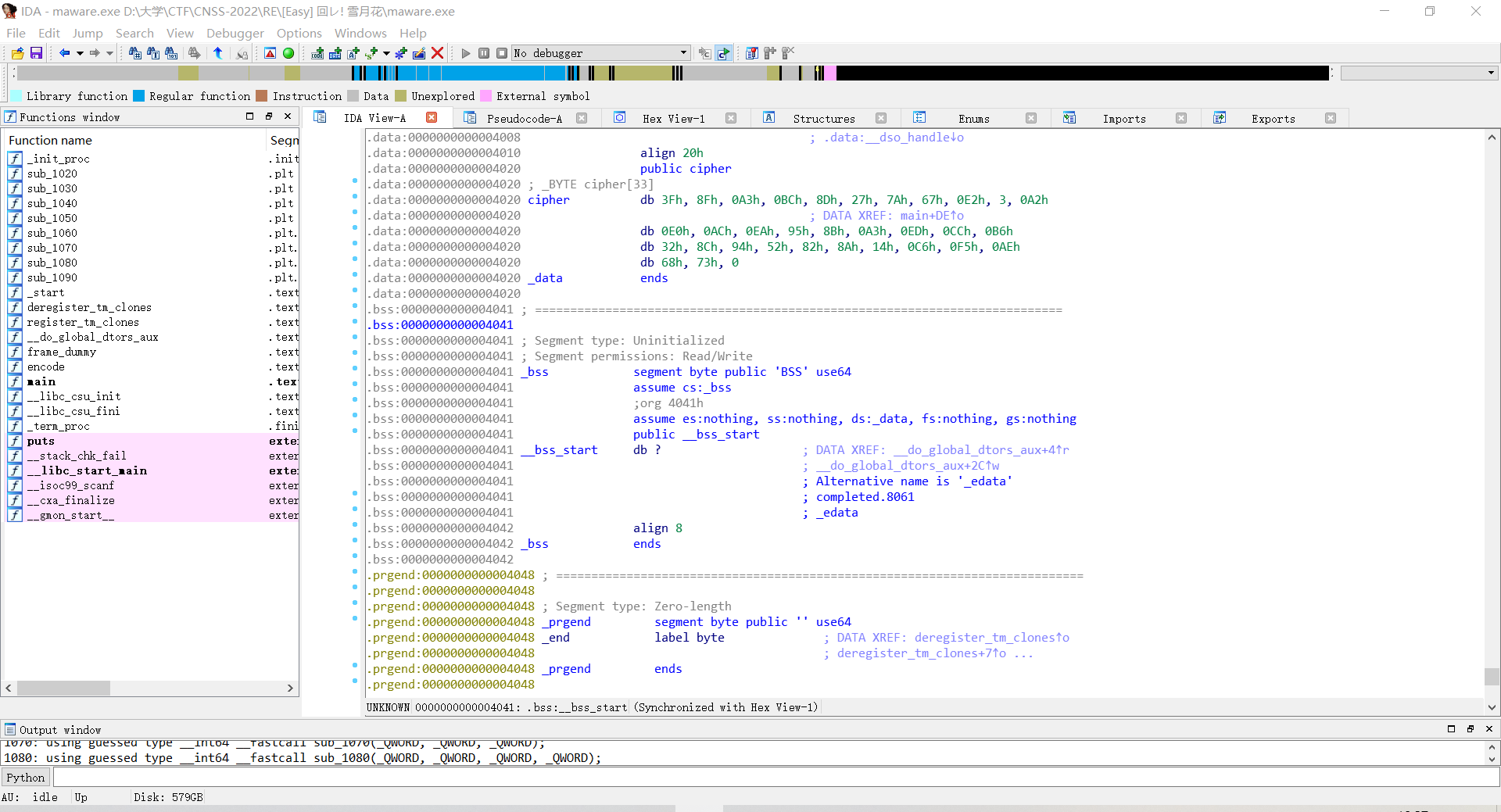
点进‘cipher[k]’,看到加密后的flag
按Shift+E取出字符串数据(C语言格式)
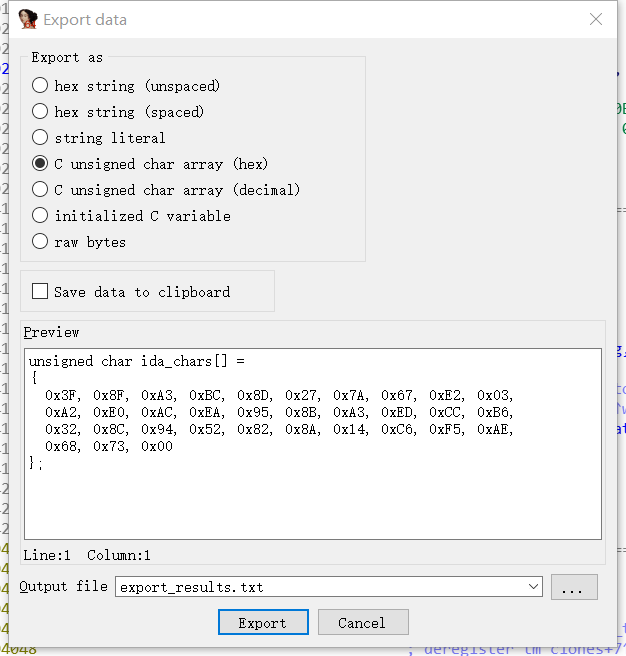
然后点进encode看,发现进行了一些位运算操作
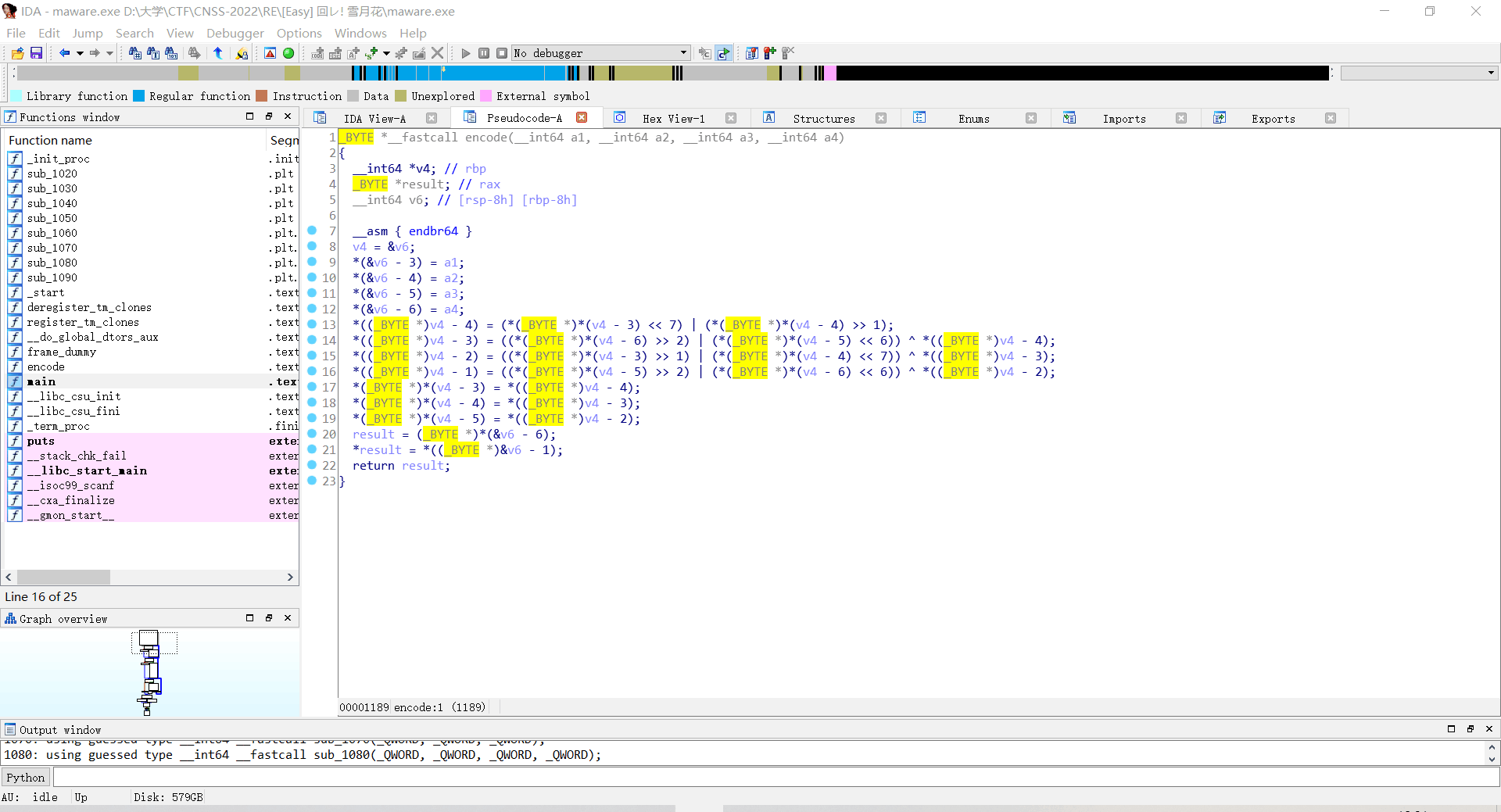
大致是每四个一组,然后(用移位运算)取出某个数的前几位和另一个数的后几位(用或运算)拼起来,可以手动推出逆向后的解密代码。
附完整脚本:
#include <cstdio>
using namespace std;
int a[] = {0x3F, 0x8F, 0x0A3, 0x0BC, 0x8D, 0x27, 0x7A, 0x67, 0x0E2, 0x3, 0x0A2, 0x0E0, 0x0AC, 0x0EA, 0x95, 0x8B, 0x0A3, 0x0ED, 0x0CC, 0x0B6, 0x32, 0x8C, 0x94, 0x52, 0x82, 0x8A, 0x14, 0x0C6, 0x0F5, 0x0AE, 0x68, 0x73, 0x0};
int v1, v2, v3, v4;
int i;
void decode()//对encode进行解密
{
v4 = a[i - 3], v3 = a[i - 2], v2 = a[i - 1], v1 = a[i];
a[i - 3] = ((v4 >> 7) & 0x1) | (((v2 ^ v3) << 1) & 0xfe);
a[i - 2] = (((v2 ^ v3) >> 7) & 0x1) | ((v4 << 1) & 0xfe);
a[i - 1] = (((v1 ^ v2) << 2) & 0xfc) | (((v3 ^ v4) >> 6) & 0x3);
a[i] = (((v3 ^ v4) << 2) & 0xfc) | (((v1 ^ v2) >> 6) & 0x3);
}
int main()
{
i = 31;
while (i >= 3)
{
decode();
i--;
}
for (int j = 0; j <= 32; j++)
{
a[j] ^= 0x11;
printf("%c", a[j]);
}
return 0;
}
flag:
cnss{So_d1zzy...Wh3r3_am_i_N0w?}
👁 [Easy] 邪王真眼
hint:
字节序
step:
打开IDA,F5。
发现是输入一个字符串'buf1',经过encode函数加密后与一个字符串'buf2'进行比较。
注意到'buf2'是一串申必数据,后面还有更申必的v6,v7。
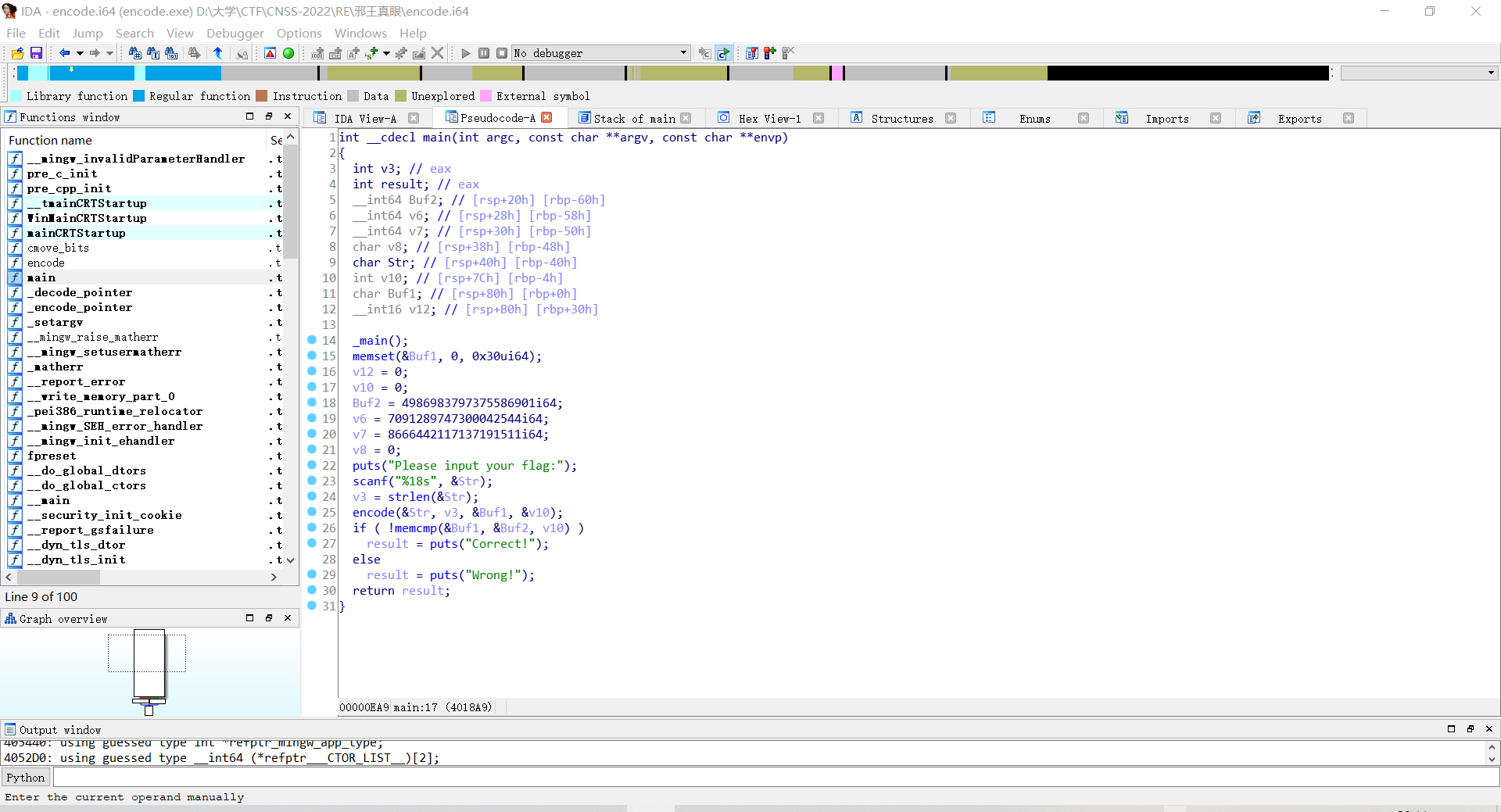
点进汇编看一眼
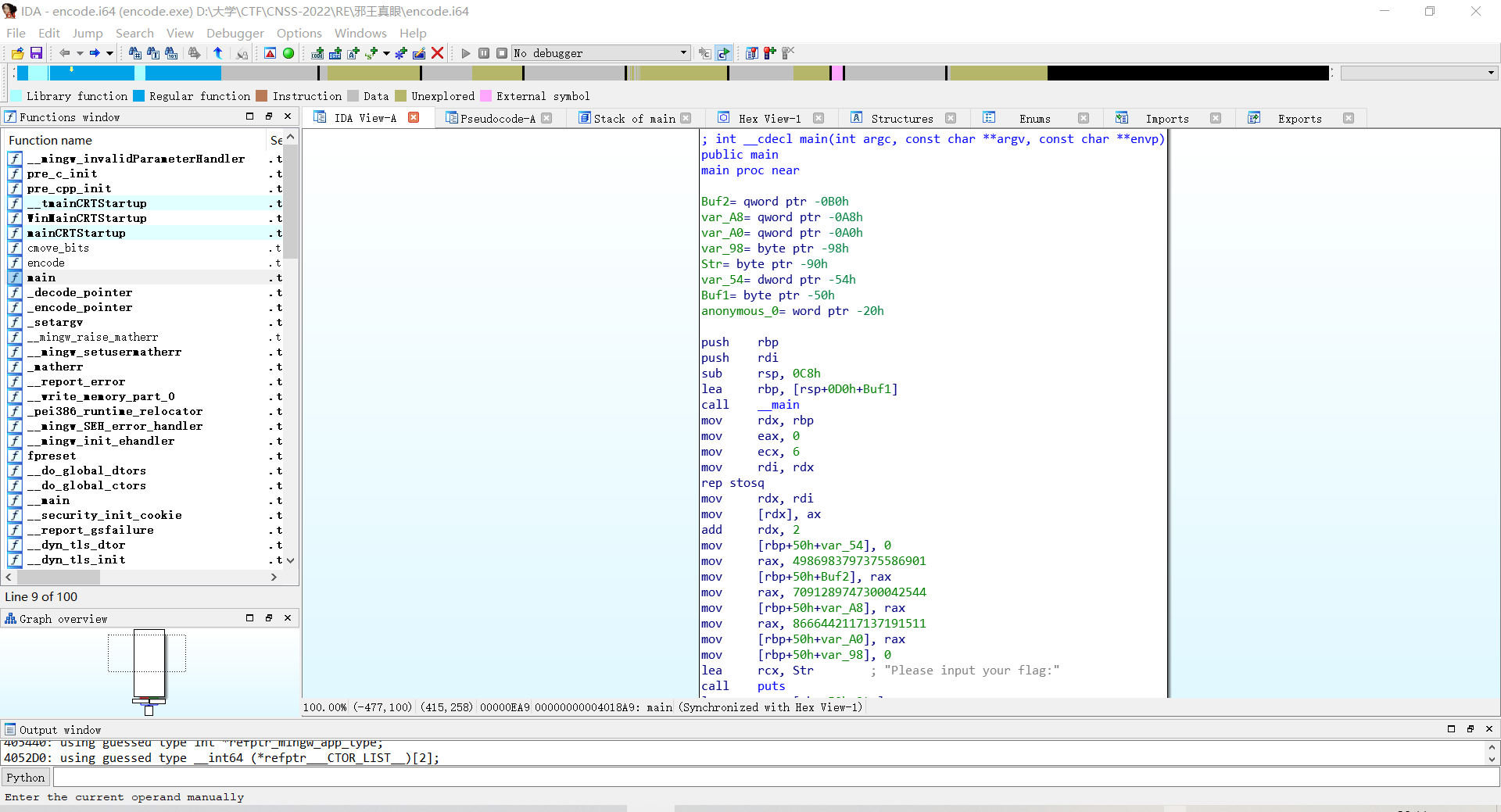
发现buf2以及后面两个使用qword定义的(即long long,占八个字节)但字符串后面是使用char指针来访问这段数据的,因此先按r将数据转换成字符串。
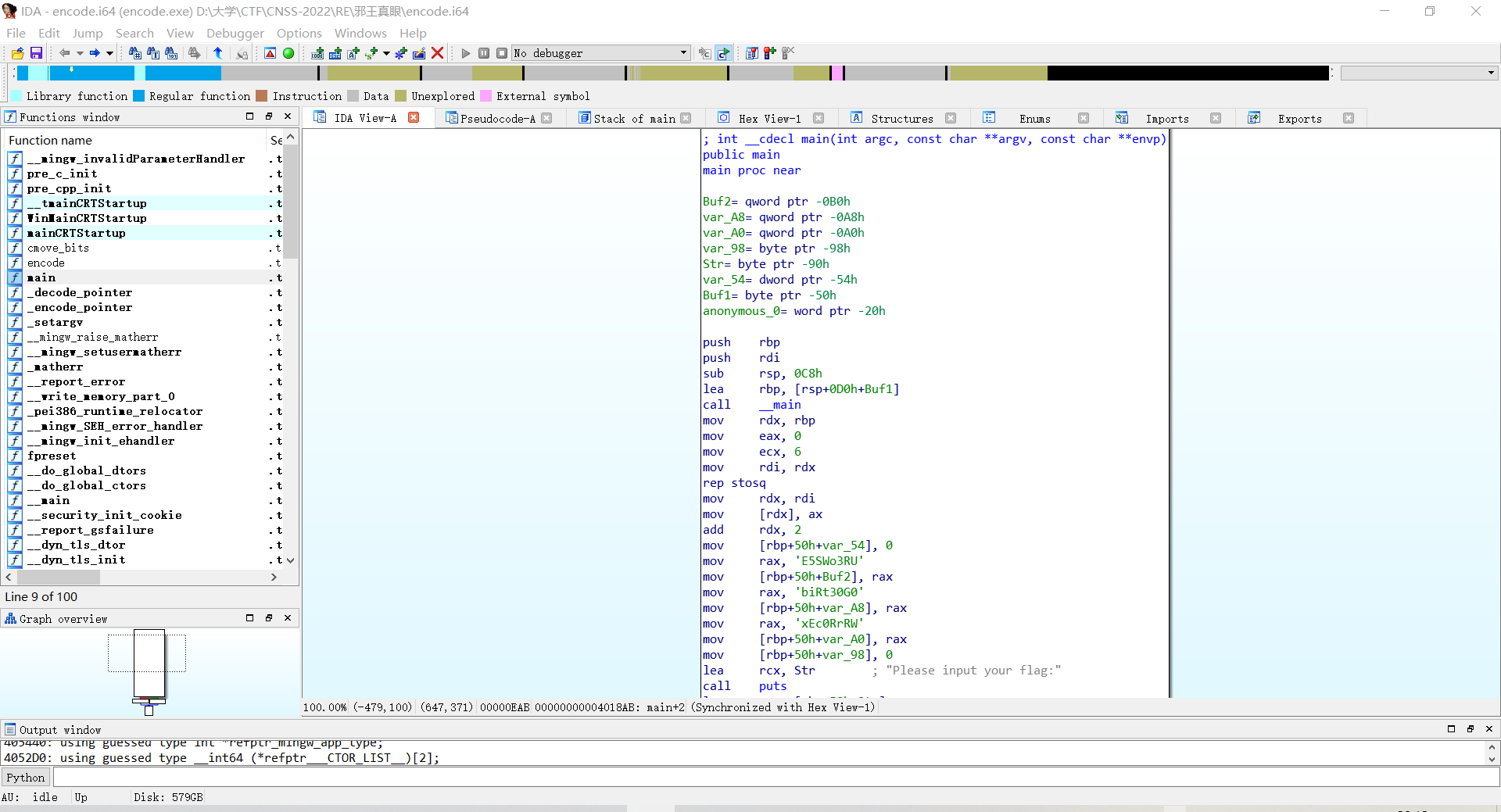
由于计算机读取内存是按照小端序,所以这三段要分别反过来再进行拼接,得到标准字符串:
UR3oWS5E0G03tRibWRrR0cEx
然后去看encode函数
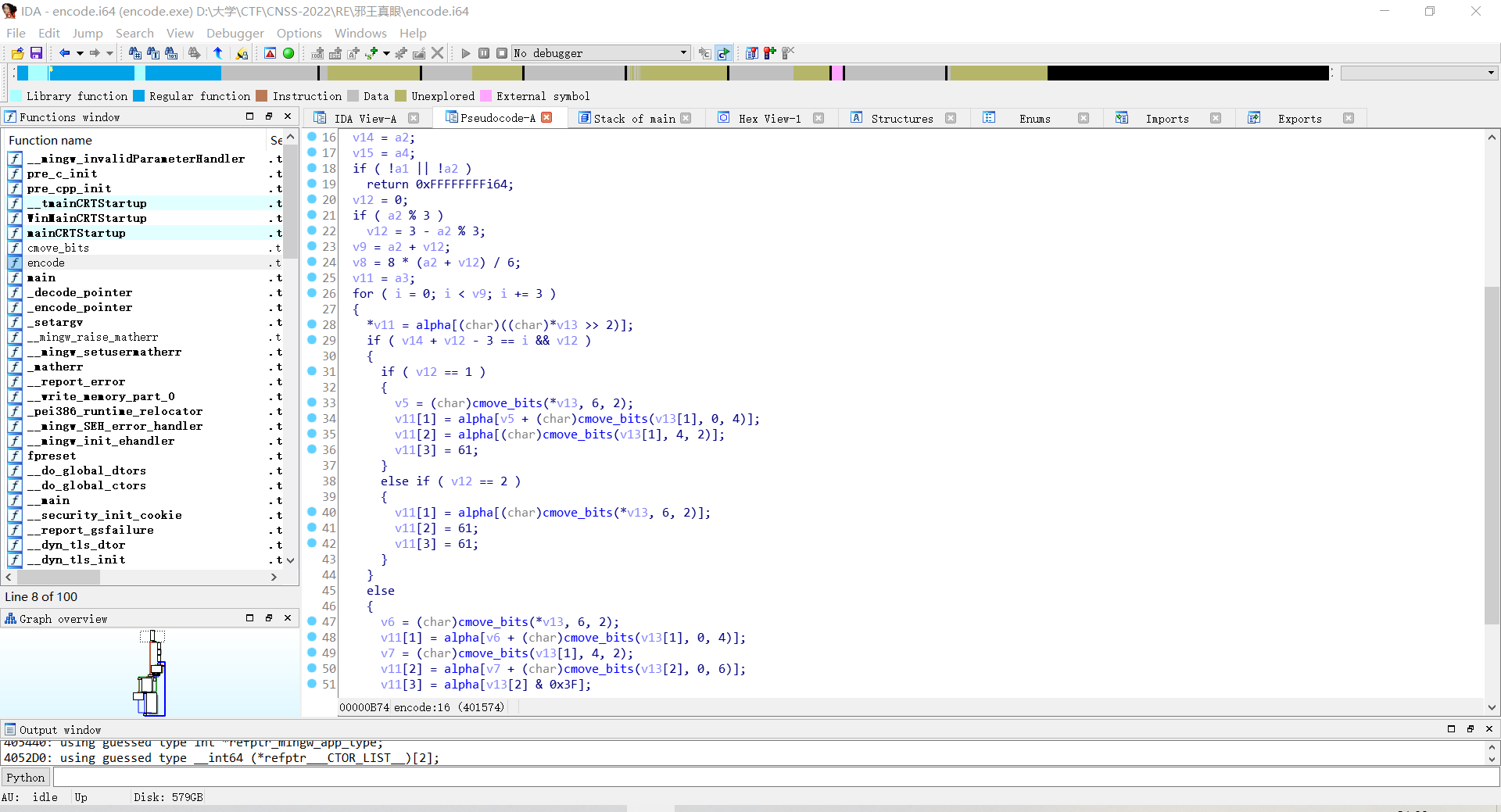
注意到有一个“alpha”,点进去看
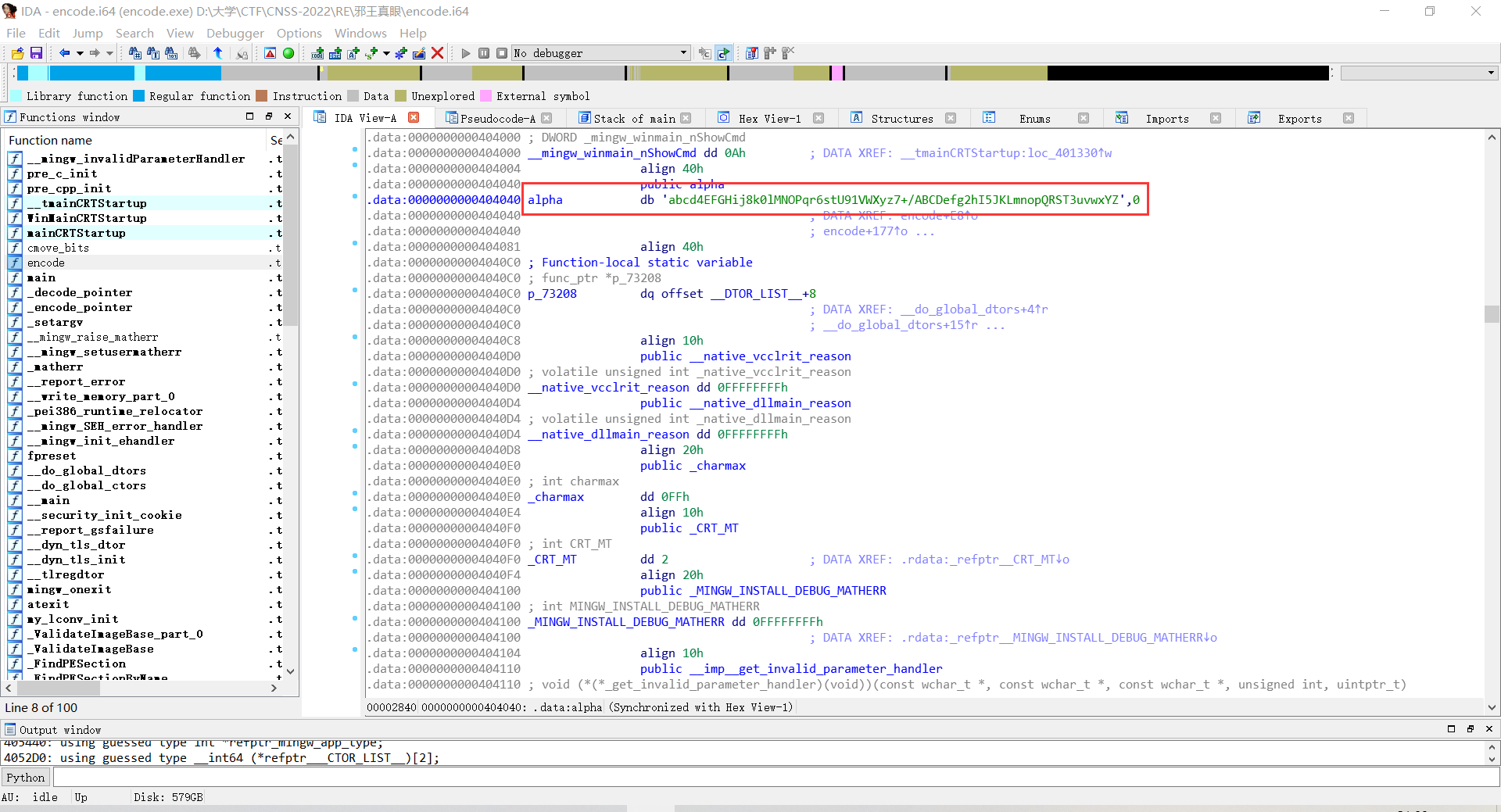
发现是base64编码的变体。
接下来使用脚本解码
#include <assert.h>
#include <stdio.h>
#include <string.h>
typedef unsigned char uint8;
typedef unsigned long uint32;
uint8 alphabet_map[] = "abcd4EFGHij8k0lMNOPqr6stU91VWXyz7+/ABCDefg2hI5JKLmnopQRST3uvwxYZ";//此处输入alpha字母表
uint8 reverse_map[] =
{
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 58, 255, 255, 255, 51,
52, 63, 41, 26, 27, 28, 34, 45, 53, 17, 255, 255, 255, 255, 255, 255,
255, 1, 8, 49, 43, 35, 2, 57, 3, 50, 42, 6, 54, 18, 5, 32,
56, 55, 31, 4, 7, 9, 15, 20, 19, 12, 23, 255, 255, 255, 255, 255,
255, 22, 14, 16, 46, 62, 47, 10, 37, 21, 24, 30, 50, 25, 59, 38,
33, 1, 13, 60, 61, 39, 44, 36, 29, 48, 40, 255, 255, 255, 255, 255};
uint32 base64_encode(const uint8 *text, uint32 text_len, uint8 *encode)
{
uint32 i, j;
for (i = 0, j = 0; i + 3 <= text_len; i += 3)
{
encode[j++] = alphabet_map[text[i] >> 2]; //取出第一个字符的前6位并找出对应的结果字符
encode[j++] = alphabet_map[((text[i] << 4) & 0x30) | (text[i + 1] >> 4)]; //将第一个字符的后2位与第二个字符的前4位进行组合并找到对应的结果字符
encode[j++] = alphabet_map[((text[i + 1] << 2) & 0x3c) | (text[i + 2] >> 6)]; //将第二个字符的后4位与第三个字符的前2位组合并找出对应的结果字符
encode[j++] = alphabet_map[text[i + 2] & 0x3f]; //取出第三个字符的后6位并找出结果字符
}
if (i < text_len)
{
uint32 tail = text_len - i;
if (tail == 1)
{
encode[j++] = alphabet_map[text[i] >> 2];
encode[j++] = alphabet_map[(text[i] << 4) & 0x30];
encode[j++] = '=';
encode[j++] = '=';
}
else // tail==2
{
encode[j++] = alphabet_map[text[i] >> 2];
encode[j++] = alphabet_map[((text[i] << 4) & 0x30) | (text[i + 1] >> 4)];
encode[j++] = alphabet_map[(text[i + 1] << 2) & 0x3c];
encode[j++] = '=';
}
}
return j;
}
uint32 base64_decode(const uint8 *code, uint32 code_len, uint8 *plain)
{
assert((code_len & 0x03) == 0); //如果它的条件返回错误,则终止程序执行。4的倍数。
uint32 i, j = 0;
uint8 quad[4];
for (i = 0; i < code_len; i += 4)
{
for (uint32 k = 0; k < 4; k++)
{
quad[k] = reverse_map[code[i + k]]; //分组,每组四个分别依次转换为base64表内的十进制数
}
assert(quad[0] < 64 && quad[1] < 64);
plain[j++] = (quad[0] << 2) | (quad[1] >> 4); //取出第一个字符对应base64表的十进制数的前6位与第二个字符对应base64表的十进制数的前2位进行组合
if (quad[2] >= 64)
break;
else if (quad[3] >= 64)
{
plain[j++] = (quad[1] << 4) | (quad[2] >> 2); //取出第二个字符对应base64表的十进制数的后4位与第三个字符对应base64表的十进制数的前4位进行组合
break;
}
else
{
plain[j++] = (quad[1] << 4) | (quad[2] >> 2);
plain[j++] = (quad[2] << 6) | quad[3]; //取出第三个字符对应base64表的十进制数的后2位与第4个字符进行组合
}
}
return j;
}
int main(void)
{
//修改解码表
for(int i=0;i<64;i++)
{
reverse_map[(int)alphabet_map[i]]=i;
}
char input[256];
while (true)
{
printf("Please input what you want to decode: ");
scanf("%s", input);
uint8 *text = (uint8 *)input;
uint32 text_len = (uint32)strlen((char *)text);
uint8 buffer[1024], buffer2[4096];
uint32 size = base64_decode(text, text_len, buffer);
buffer[size] = 0;
printf("Decoded content: %s\n", buffer);
size = base64_encode(buffer, size, buffer2);
buffer2[size] = 0;
printf("Confirmation of the original content: %s\n", buffer2);
}
return 0;
}
//解码
flag:
cnss{E4sy_bAse64!}
🔪 [Easy] 恭喜你获得了flag提现机会!
hint:
IDA修改汇编代码——patch program
step:
打开IDA,按F5
注意到v6是到1000还需要的硬币,但是有一个判断使得v6永远不可能小于0,也就是说不可能调用到‘outputflag’函数。
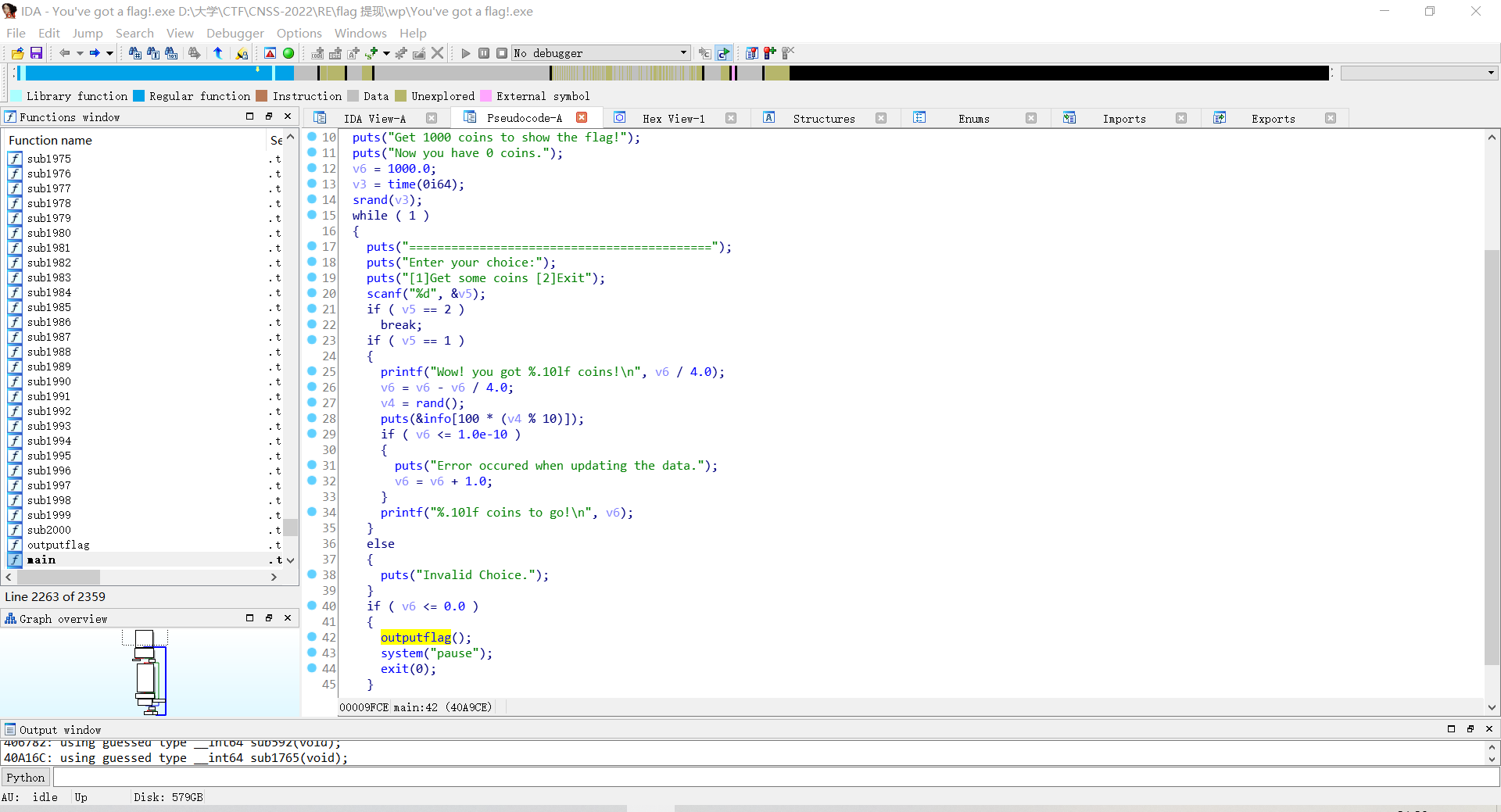
点进函数看一眼:
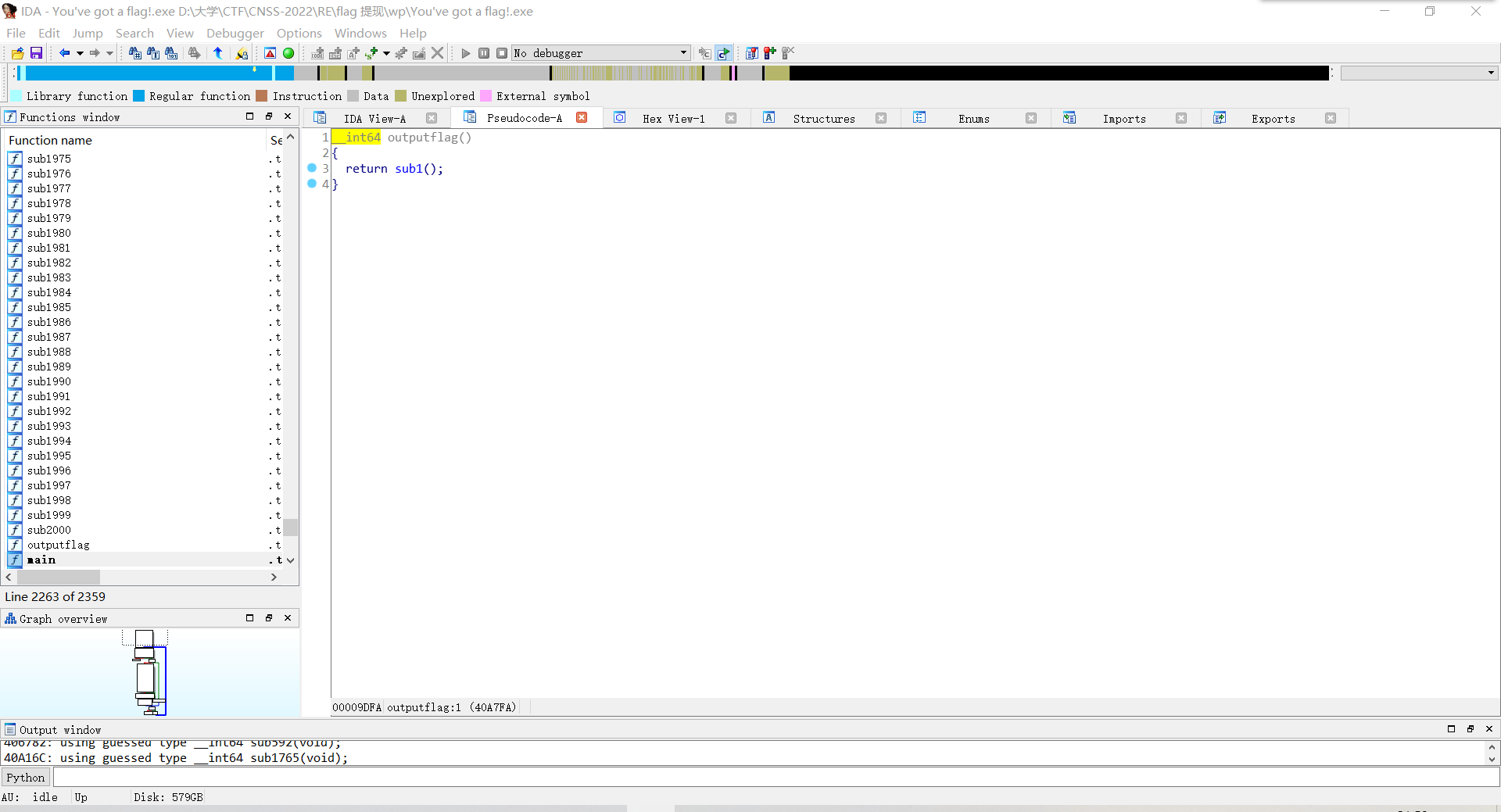
发现是不断调用sub函数,结合左边函数栏显示有2000个,不可能一个个找,所以考虑修改代码。
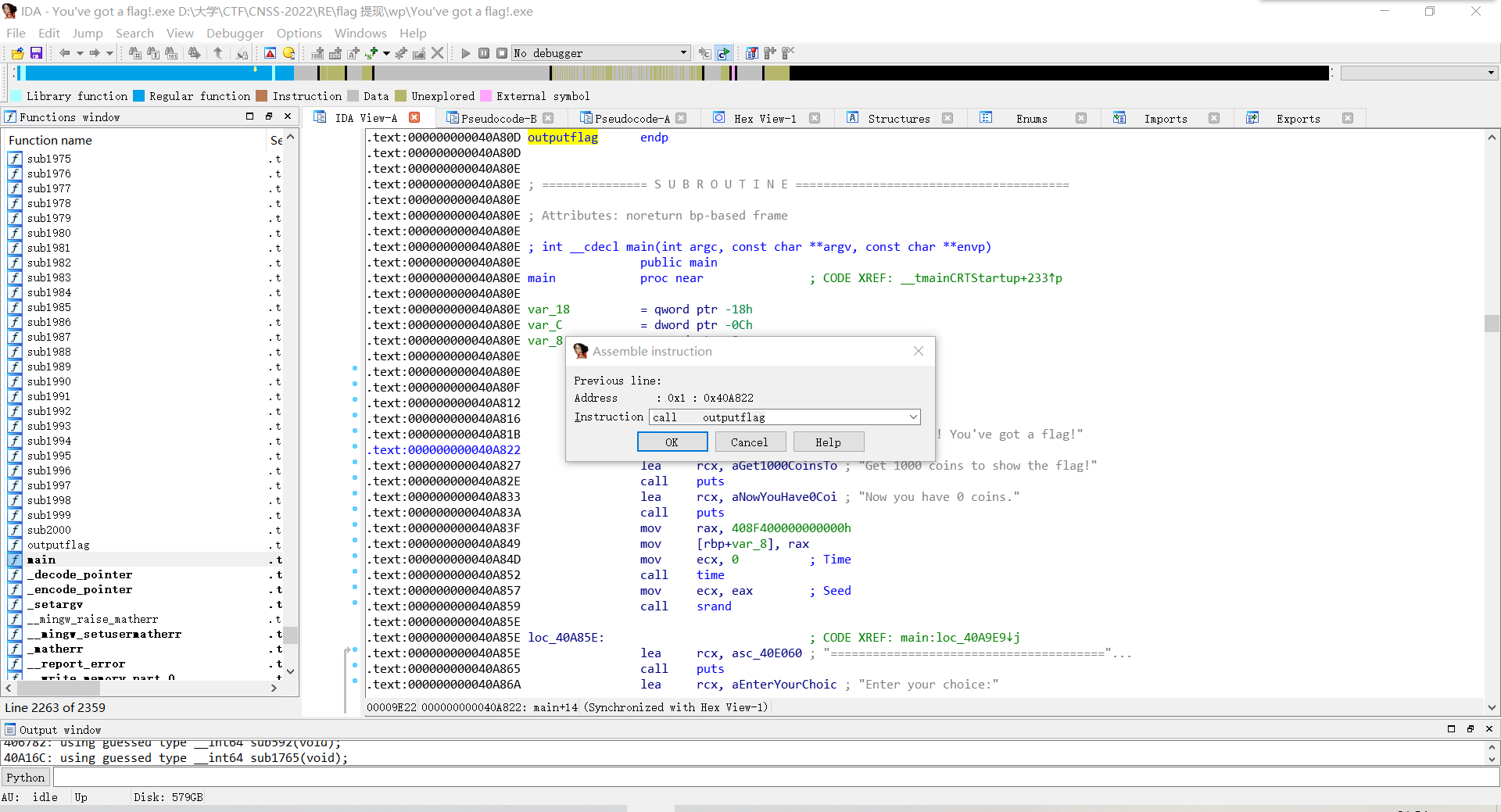
Edit-patch program-Assemble
将第一次调用puts改为直接调用outputflag。
然后将修改后的代码保存进原来的exe文件,运行后得到flag
Edit-patch program-……File
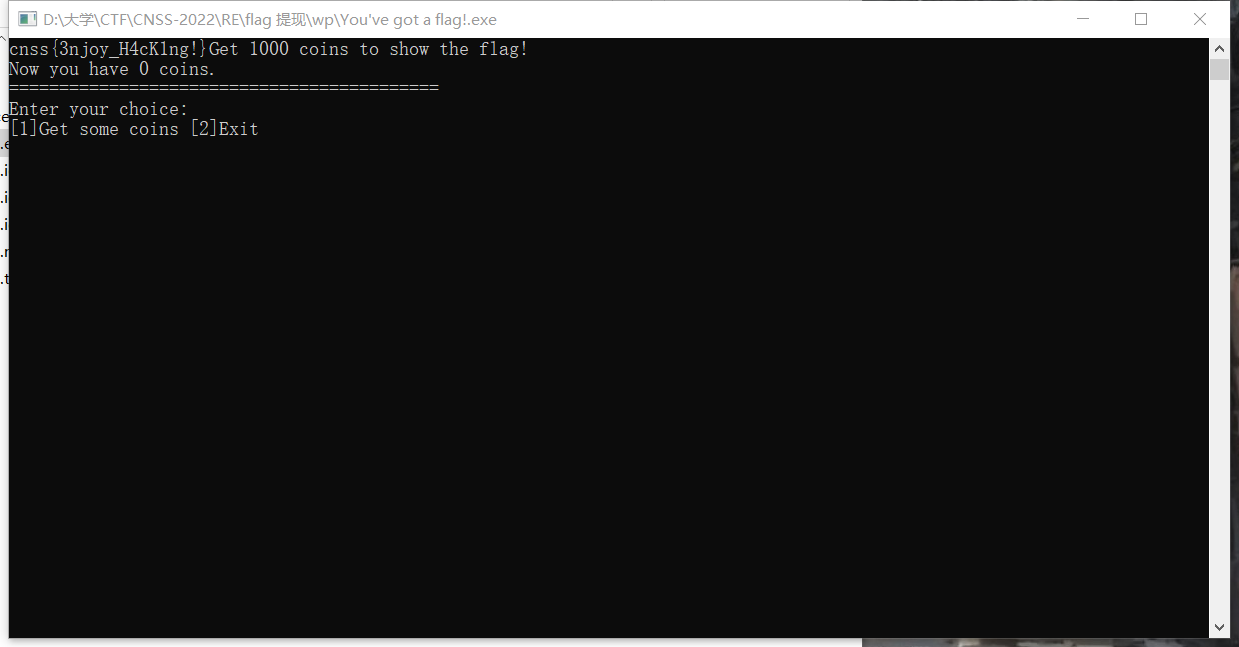
(第一次改了后面的判断那边的汇编代码,导致后面的代码无法被反编译成正常代码被当成垃圾数据舍弃了,然后图形界面运行就会打印一个一闪而过的flag,复现的时候优化了一下。当然使用命令行运行就不用担心这个问题)
flag:
cnss{3njoy_H4cK1ng!}
💻 [Easy+] diannaobaozhale
hint:
简单汇编指令
step:
先看题目给的汇编指令
main proc near
var_5 = byte ptr -5
var_4 = dword ptr -4
; __unwind {
endbr64
push rbp //栈帧操作
mov rbp, rsp
sub rsp, 10h
mov [rbp+var_5], 63h //var5=63h
mov edi, 63h
call _putchar //c
mov edi, 6Eh
call _putchar //n
mov edi, 73h
call _putchar //s
mov edi, 73h
call _putchar //s
mov edi, 7Bh
call _putchar //{
mov [rbp+var_4], 0 //var4=0
jmp short loc_11B0
loc_1194:
movsx eax, [rbp+var_5]
mov edi, eax //
call _putchar //print(var5)
movzx eax, [rbp+var_5] //i=var5
add eax, 2 //i+=2
xor eax, 1 //i^=1
mov [rbp+var_5], al //var5=i
add [rbp+var_4], 1 //var4++
loc_11B0:
cmp [rbp+var_4], 9 //将var4与9比较
jle short loc_1194 //小于等于跳转
mov edi, 7Dh //}
call _putchar
mov eax, 0
leave
retn
; }
main endp
附脚本
#include<cstdio>
using namespace std;
int main()
{
char i=0x63;
int t=10;
while(t--)
{
printf("%c",i);
i+=2;
i^=1;
}
return 0;
}
flag:
cnss{cdghklopst}
🗣 [Easy+] Tell me your secret
hint:
字节序
step:
打开IDA,F5。并按R翻译ASCII码。
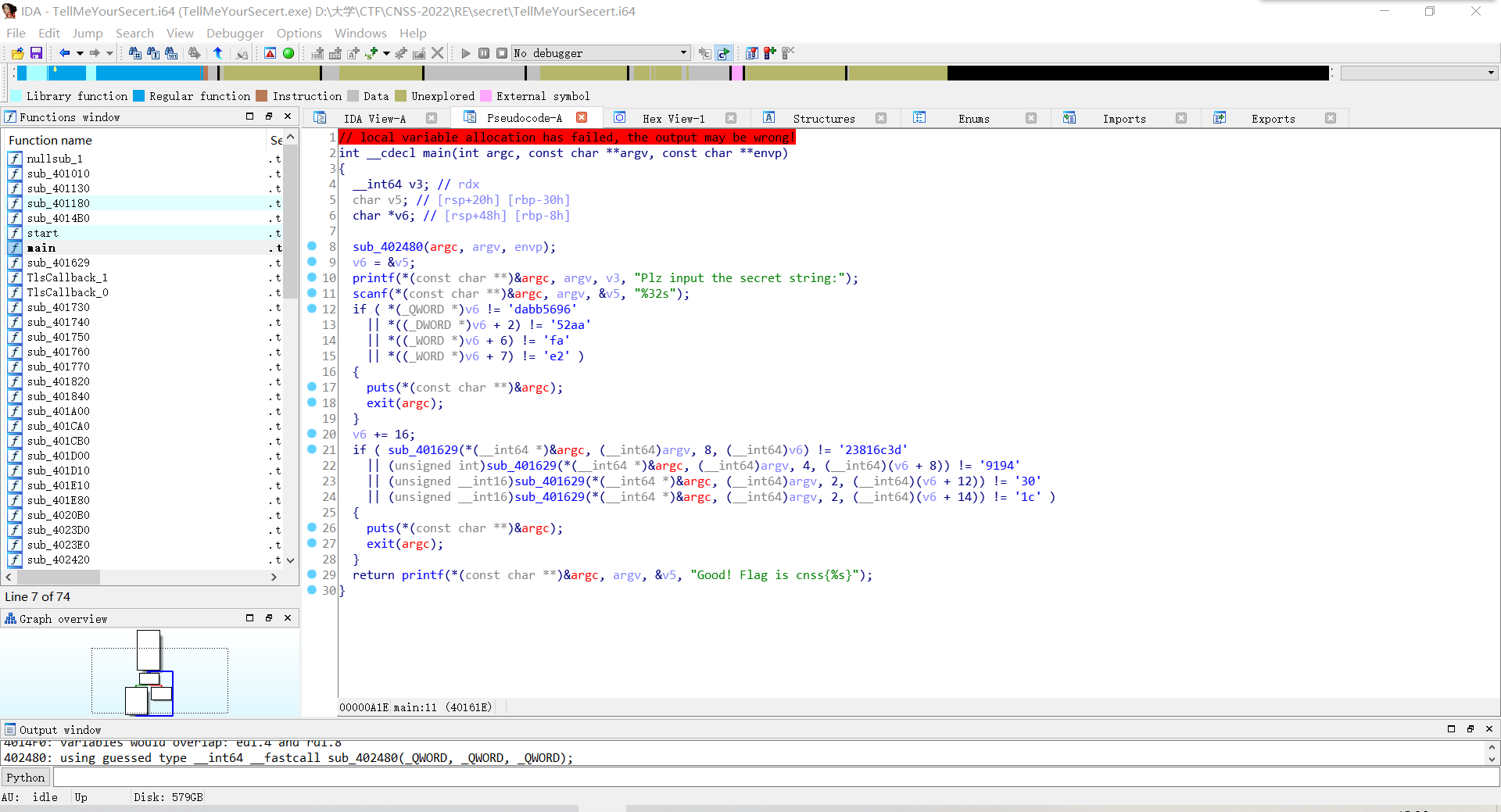
发现是输入一个字符串(32个字符即32字节),然后与分成标准串进行比较。
两段标准串里再切割成更多小段,不断转换v6的指针类型进行访问,由于计算机内存访问是用的小端序,所以每一段要倒过来再连起来。
得到:6965bbadaa25af2e
中间v6+16(字节)意味着跳到了后半段。
后半段里注意到调用了一个函数,点进去看发现是把每一段倒过来,相当于改回了大端序,所以第二个串不需要每一段倒过来记录。
得到:23816c3d9194301c
flag:
cnss{6965bbadaa25af2e23816c3d9194301c}
🤡 [Middle] Vip of Mihoyo
hint:
Z3正向暴力求解
step:
打开IDA,F5.发现一串奇怪的switch-case
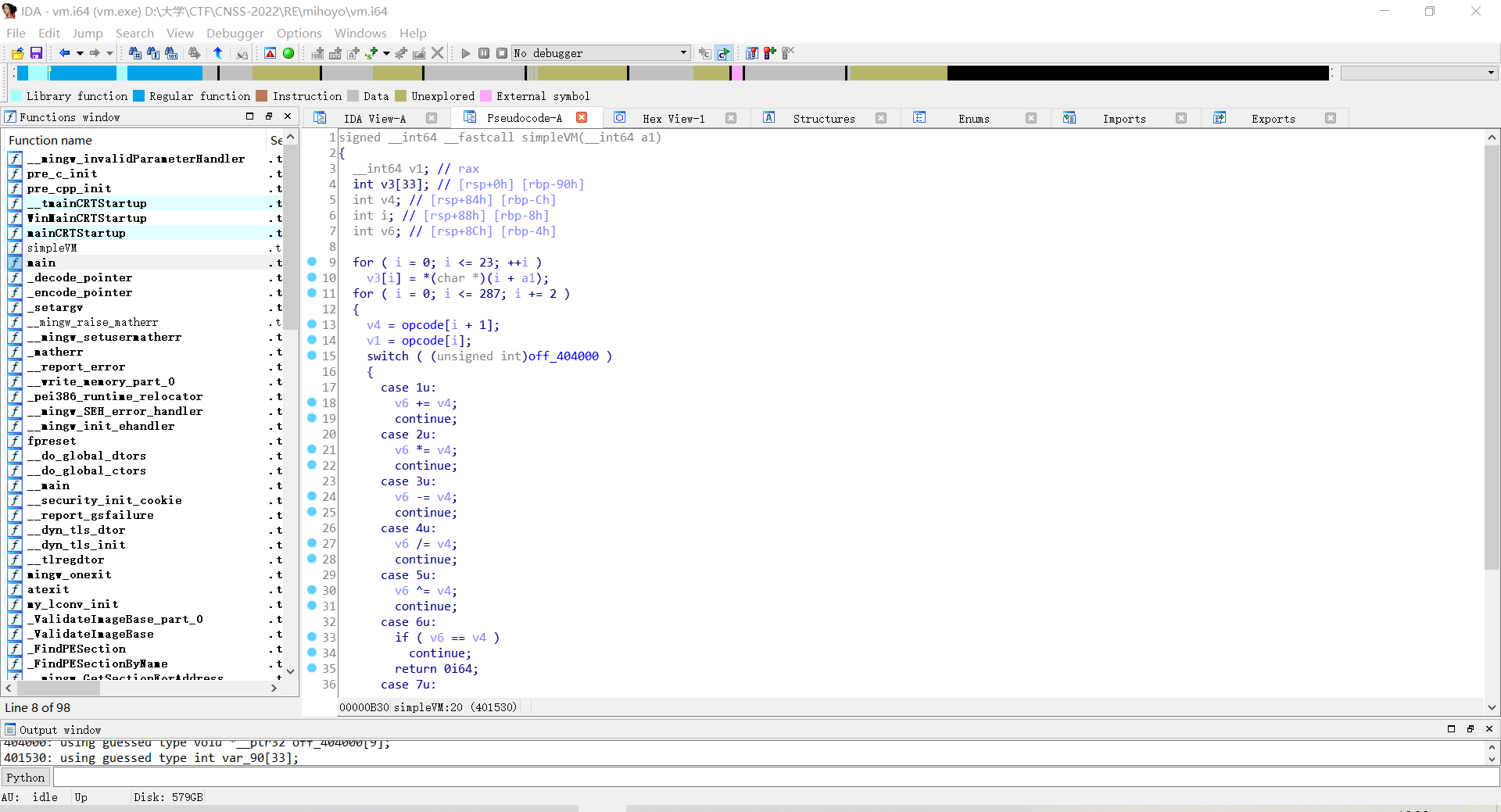
发现是根据opcode的偶数位(包括0)作为判断操作类型条件、奇数位作为操作数v4来进行加密的。
点进opcode看一眼
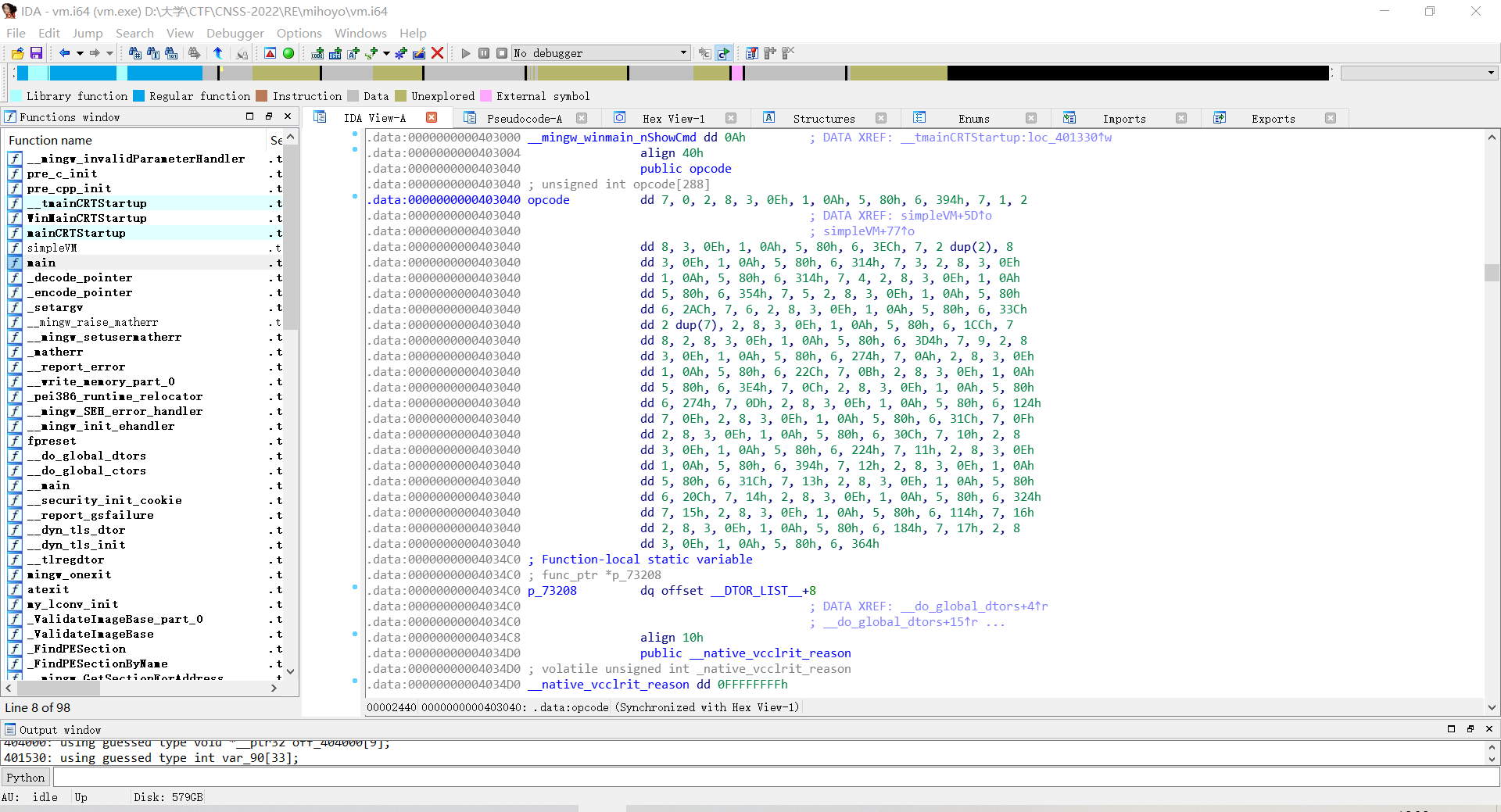
Shift+E导出
发现运算是有规律的。按照7,2,3,1,5,6的顺序给每个字符进行加密。(有规律应该可以写逆向脚本?没有尝试)
python写的z3脚本如下
Tips:一开始用的返回值,把返回值加进方程z3解不了,就改成每轮加一个x.add(v6 == v4)方程了
from z3 import *
x = Solver()
X = [BitVec(f"x_{i}", 64) for i in range(24)]
arr = [
7, 0, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x394,
7, 1, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x3EC,
7, 2, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x314,
7, 3, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x314,
7, 4, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x354,
7, 5, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x2AC,
7, 6, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x33C,
7, 7, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x1CC,
7, 8, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x3D4,
7, 9, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x274,
7, 0x0A, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x22C,
7, 0x0B, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x3E4,
7, 0x0C, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x274,
7, 0x0D, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x124,
7, 0x0E, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x31C,
7, 0x0F, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x30C,
7, 0x10, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x224,
7, 0x11, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x394,
7, 0x12, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x31C,
7, 0x13, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x20C,
7, 0x14, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x324,
7, 0x15, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x114,
7, 0x16, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x184,
7, 0x17, 2, 8, 3, 0x0E, 1, 0x0A, 5, 0x80, 6, 0x364]
for i in range(144):
v4 = arr[2*i+1]
v1 = arr[2*i]
if (v1 == 1):
v6 += v4
elif (v1 == 2):
v6 *= v4
elif (v1 == 3):
v6 -= v4
elif (v1 == 4):
v6 /= v4
elif (v1 == 5):
v6 ^= v4
elif (v1 == 6):
x.add(v6 == v4)
elif (v1 == 7):
v6 = X[v4]
elif (v1 == 8):
X[v4] = v6
if x.check() == sat:
result = x.model()
print(result)
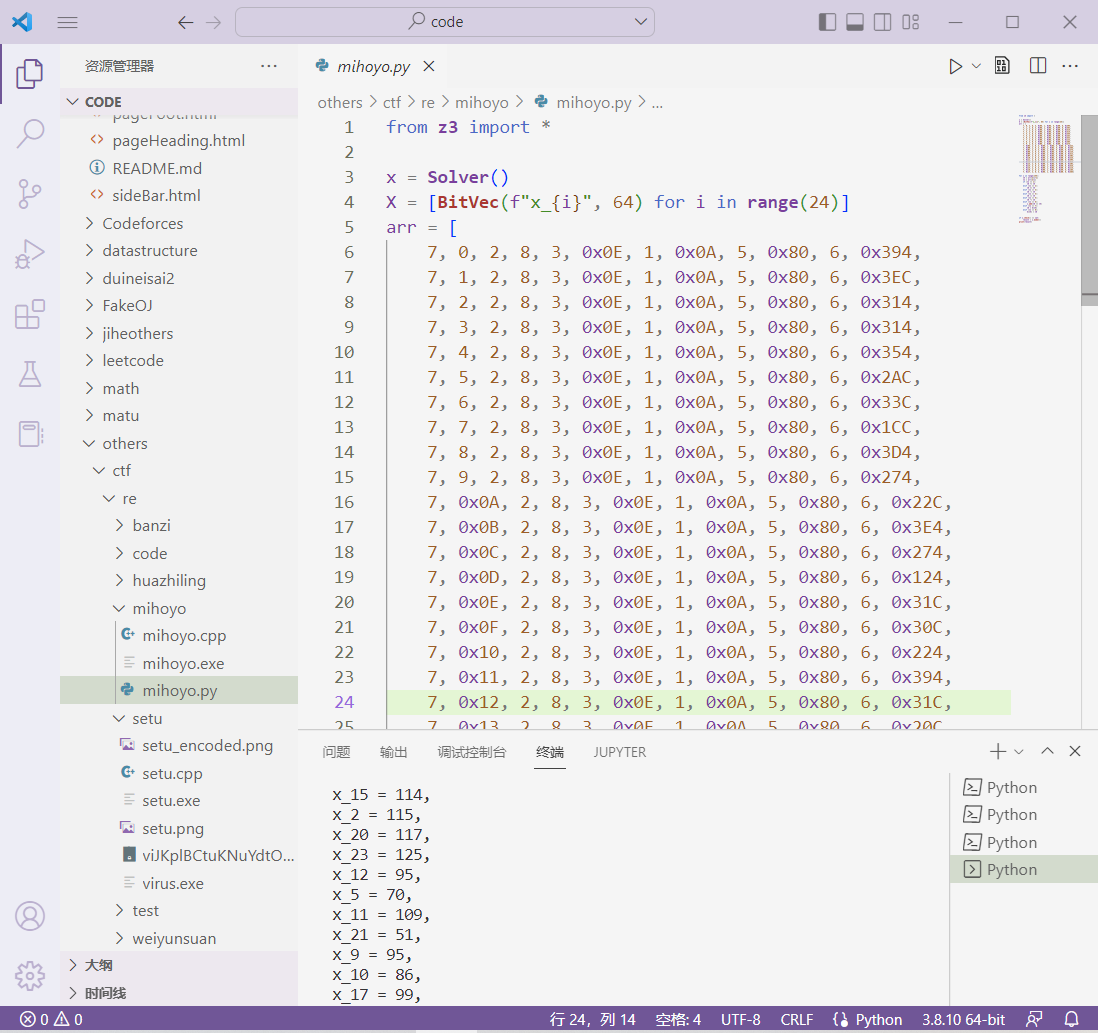
然后再用一个脚本把数据转换成字符串(因为还不会python语法)
#include <cstdio>
using namespace std;
char x[24];
int main()
{
x[3] = 115;
x[16] = 85;
x[15] = 114;
x[2] = 115;
x[20] = 117;
x[23] = 125;
x[12] = 95;
x[5] = 70;
x[11] = 109;
x[21] = 51;
x[9] = 95;
x[10] = 86;
x[17] = 99;
x[0] = 99;
x[19] = 82;
x[7] = 42;
x[14] = 116;
x[22] = 33;
x[1] = 110;
x[6] = 120;
x[13] = 53;
x[18] = 116;
x[8] = 107;
x[4] = 123;
printf("%s", x);
return 0;
}
flag:
cnss{Fx*k_Vm_5trUctRu3!}
⭐ [Middle] Super Mario Code
hint:
elf文件动态调试
step:
好像这个题难点在配环境(bushi
hint 里说这个题要用到 smc,动态调试环境需要 linux ,配一下虚拟机(被vmware tools的锅卡了好久)
再按 https://www.52pojie.cn/thread-730499-1-1.html 里的方法配一下环境
随便丢一个flag进去跑,在 printf 和 RIP 之间没有其他的函数调用,可以推测此处的函数是 scanf,22h 应该是字符串长度参数。
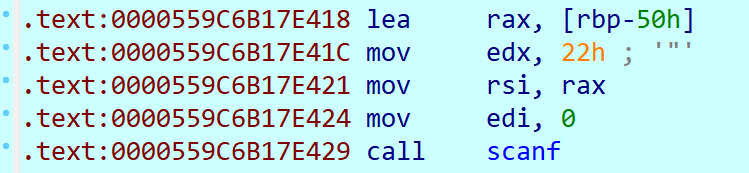
总之我们找到了正确的主函数位置,重新跑一下发现正常的函数已经出现了,这里应该可以创建函数f5但感觉直接看汇编就可以了
这段代码把读入的串丢给rbp-50h,然后给 rbp-80h 这个字符串赋初始值,赋值还会有重叠(rbp-80h和rbp-78h这俩指令),不过也可以忽略这个问题,直接上内存里找这段串。
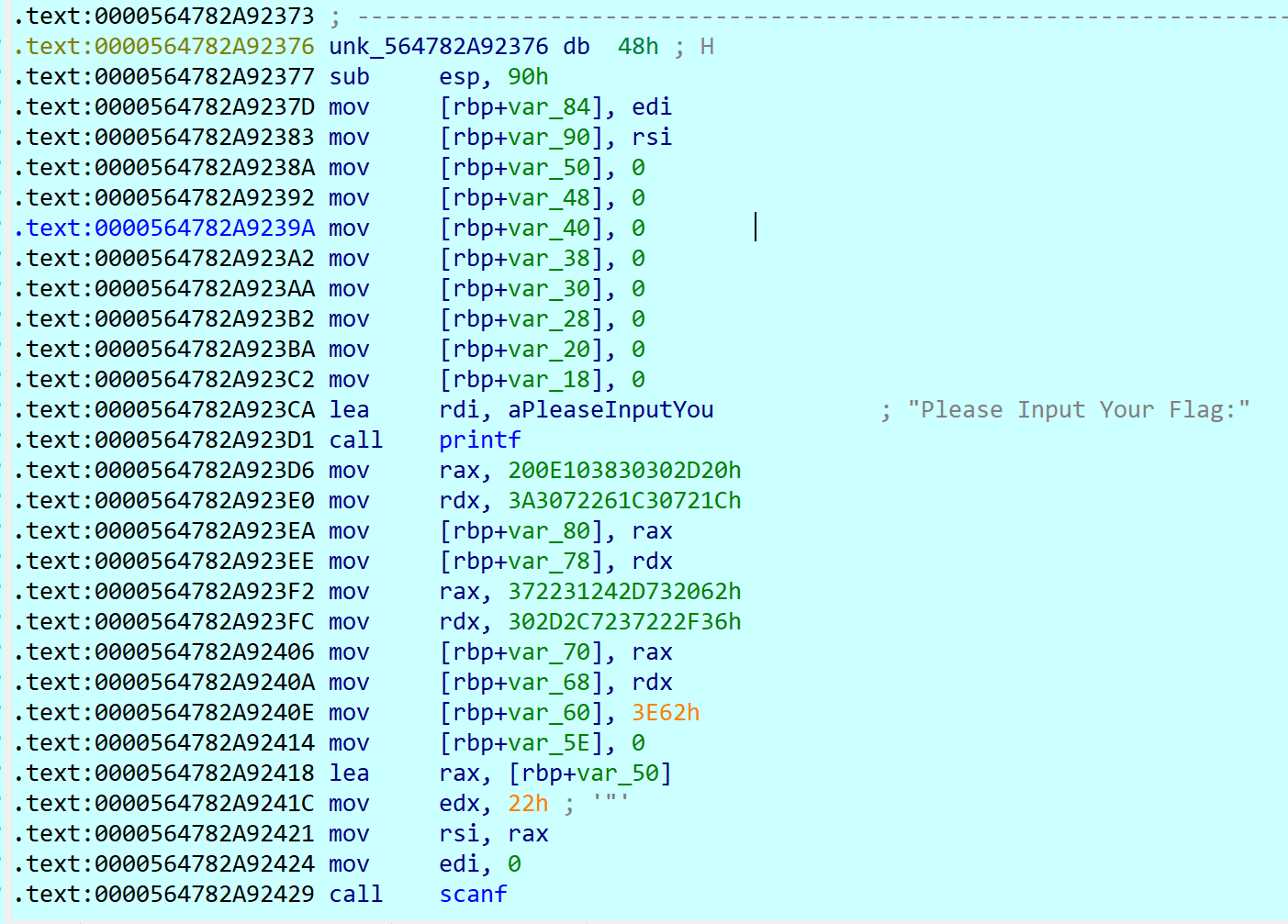
接下来两俩循环,一段是异或处理,一段是把读入串 [rbp-50h] 和标准串 [rbp-80h] 逐字节比较
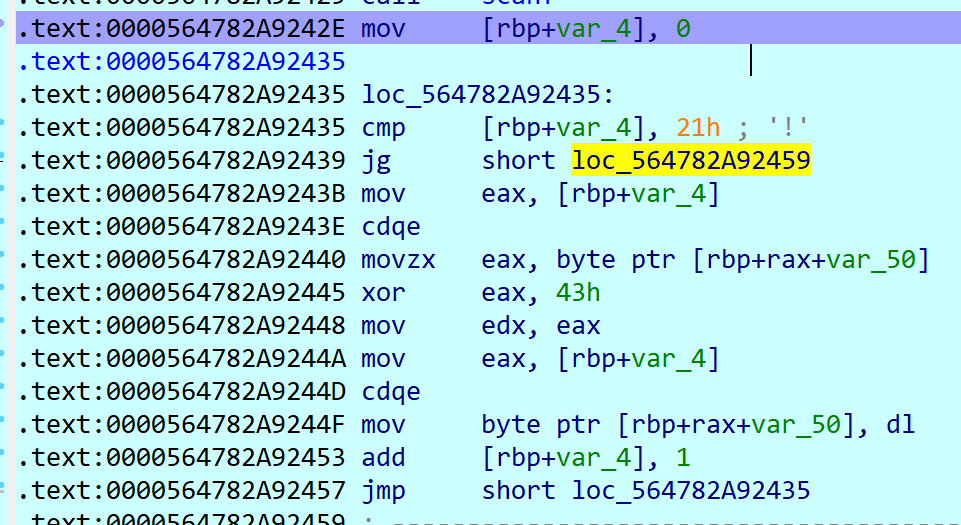
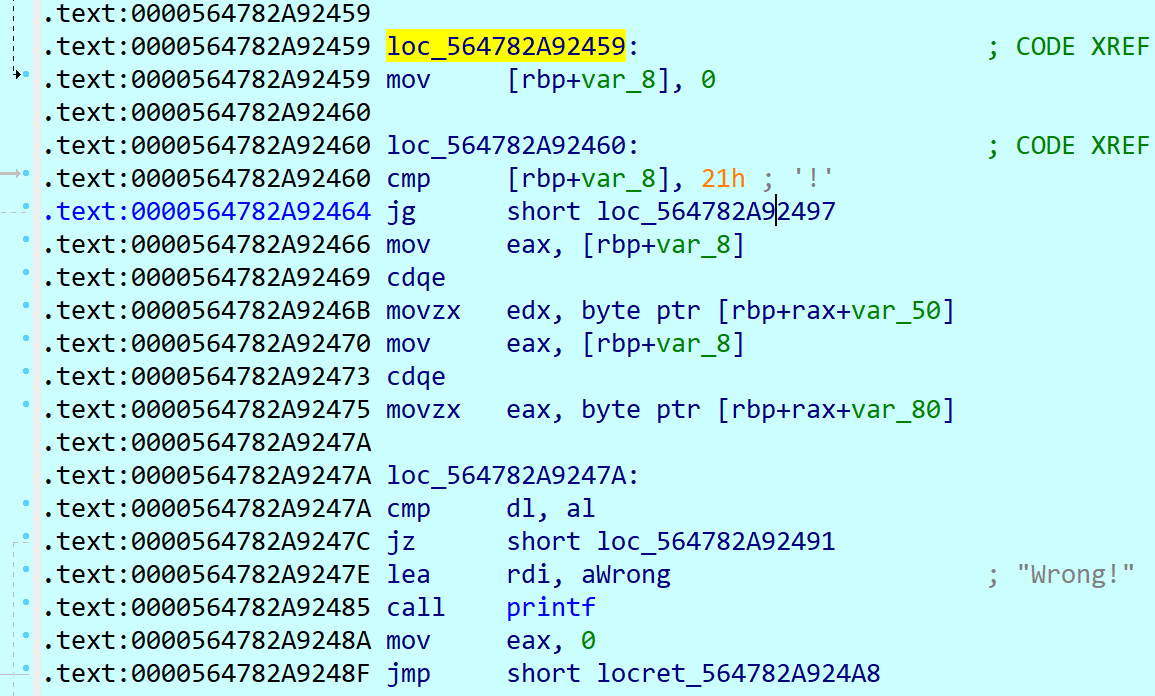
非常好逆,脚本如下
#include <bits/stdc++.h>
using namespace std;
unsigned char op[] ={
0x20, 0x2D, 0x30, 0x30, 0x38, 0x10, 0x0E, 0x20, 0x1C, 0x72,
0x30, 0x1C, 0x26, 0x72, 0x30, 0x3A, 0x62, 0x20, 0x73, 0x2D,
0x24, 0x31, 0x22, 0x37, 0x36, 0x2F, 0x22, 0x37, 0x72, 0x2C,
0x2D, 0x30, 0x62, 0x3E
};
int main()
{
for (int i = 0; i <= 33; i++)
{
op[i] ^= 0x43;
printf("%c", op[i]);
}
puts("");
return 0;
}
flag:
cnss{SMc_1s_e1sy!c0ngratulat1ons!}
🌸 [Middle] 花花
hint:
花指令
step:
打开IDA,发现地址都被标红了
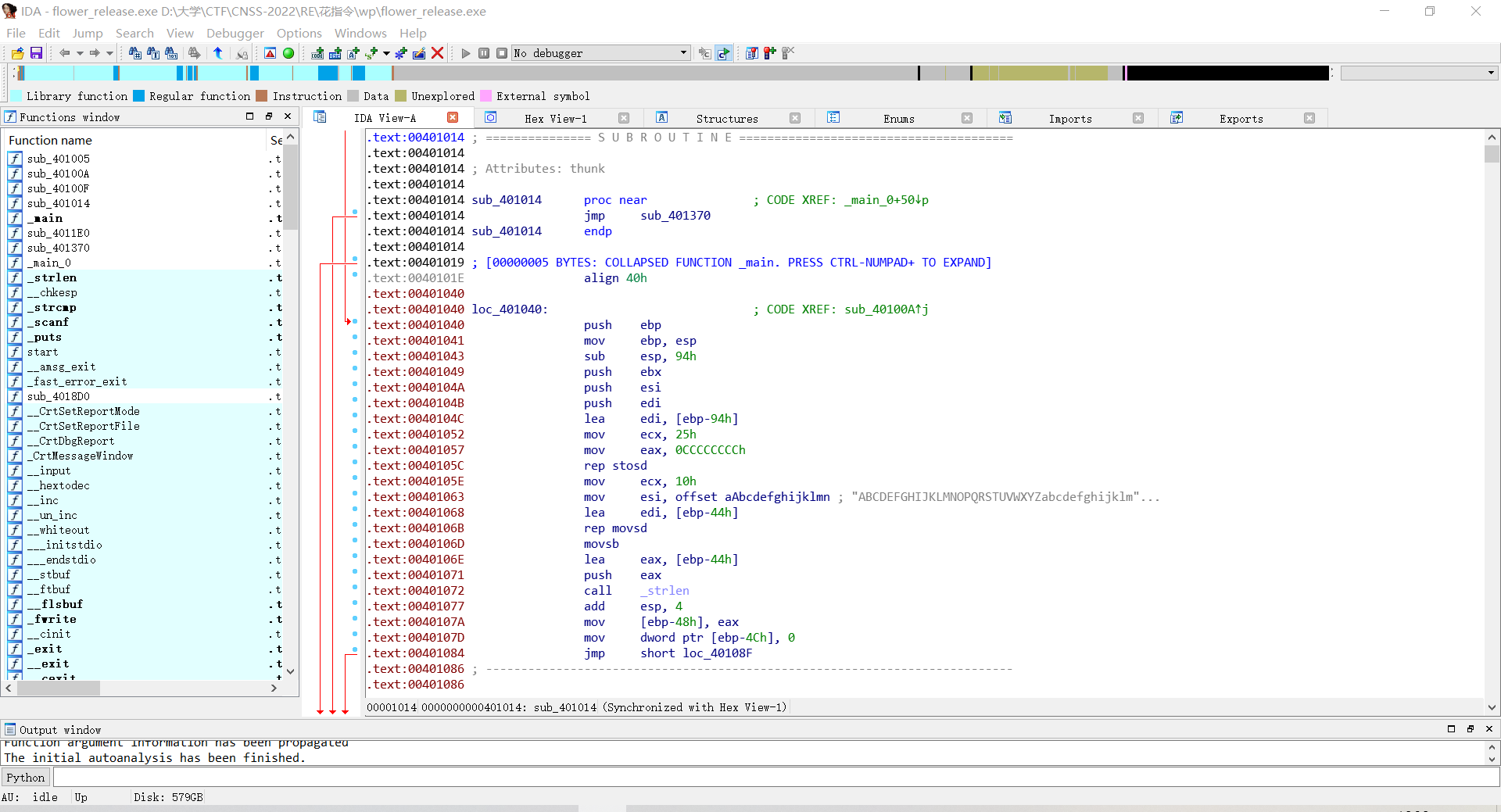
看汇编代码,注意到这里有奇怪的地址+1以及连续两个跳转函数
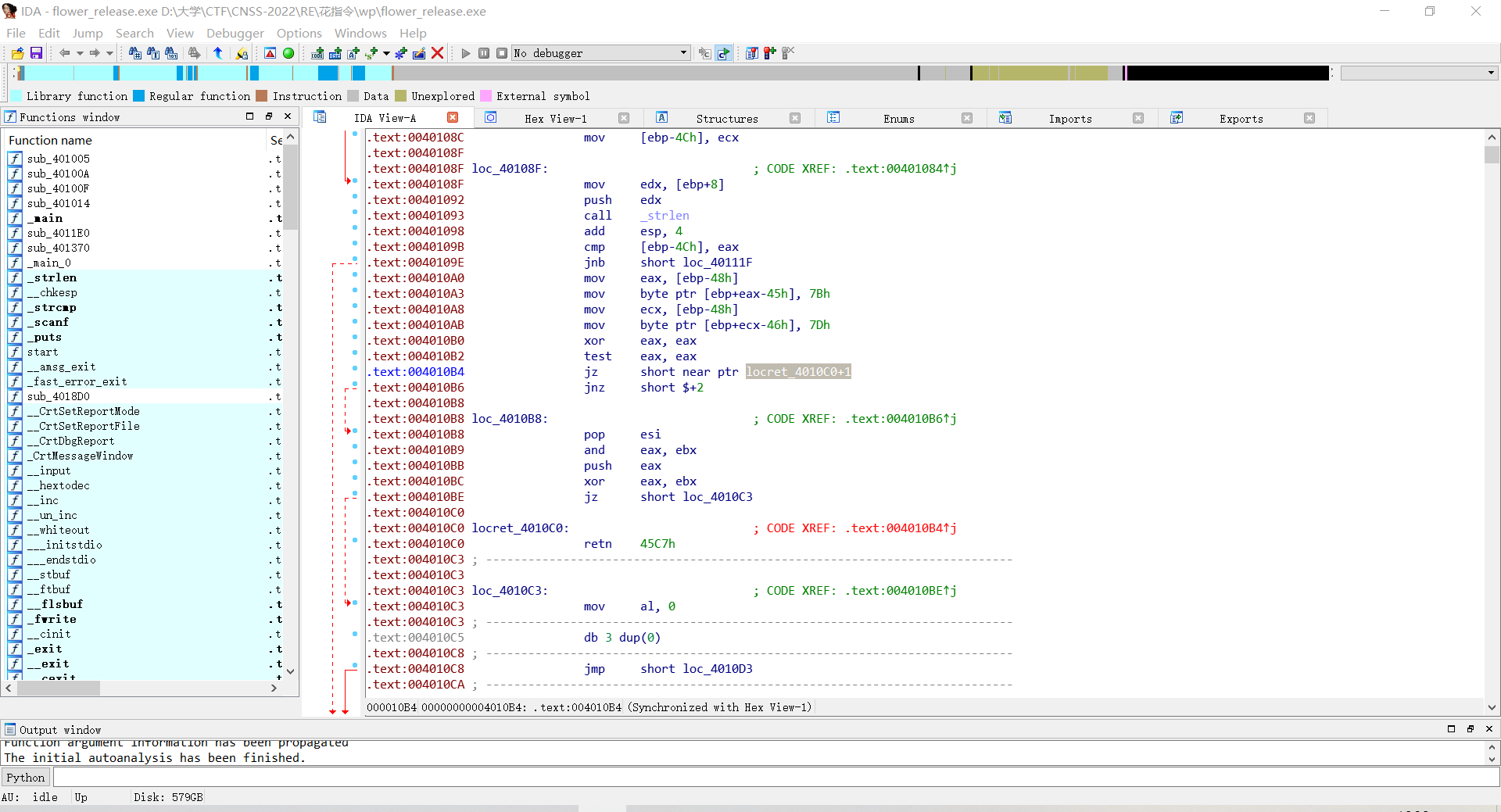
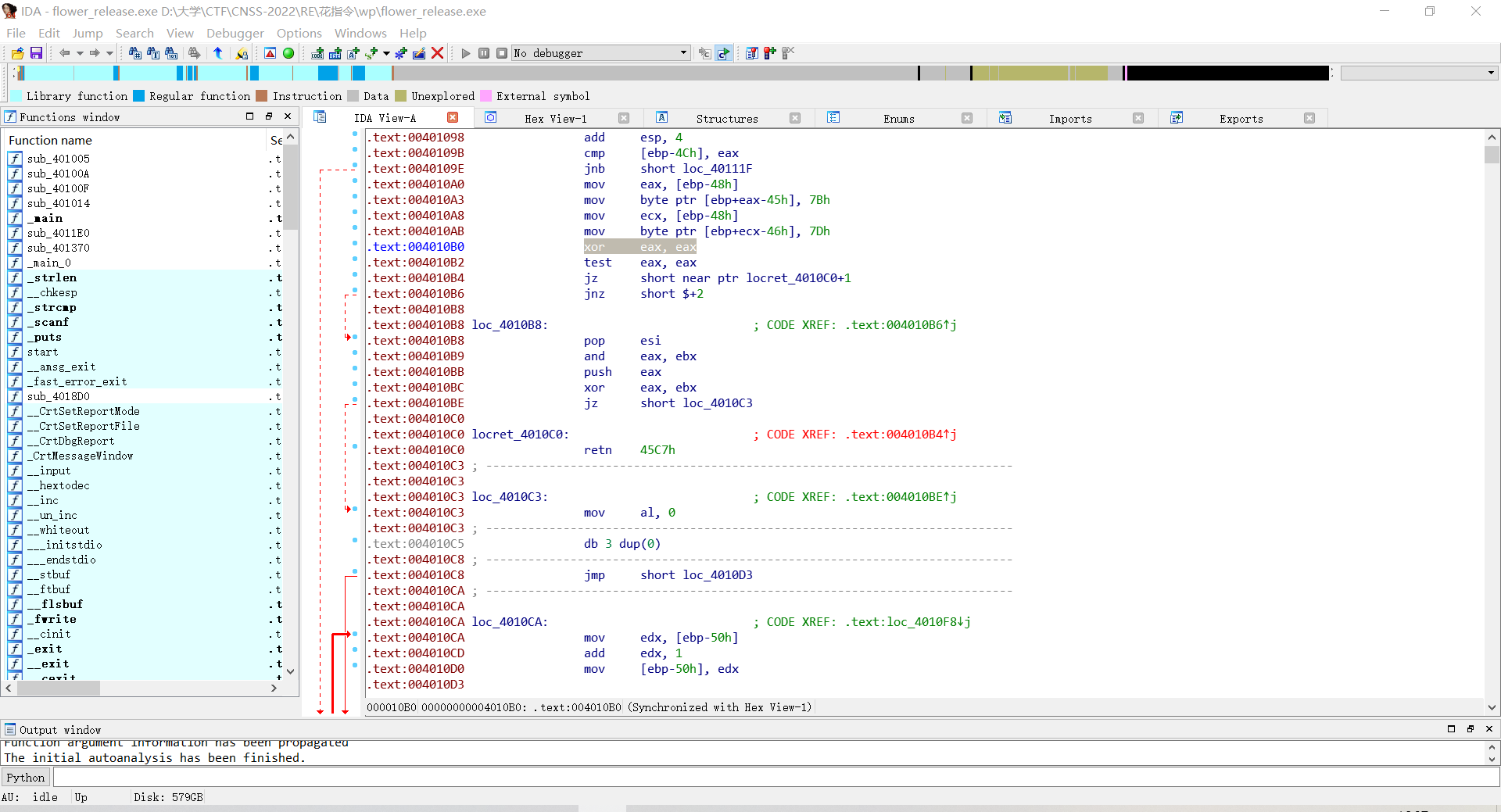
说明4010C0处有一个垃圾字节,另外第二个JZ是垃圾指令。
按Uundefine这段代码把它变回数据,再按C将4010C1重新code回来。
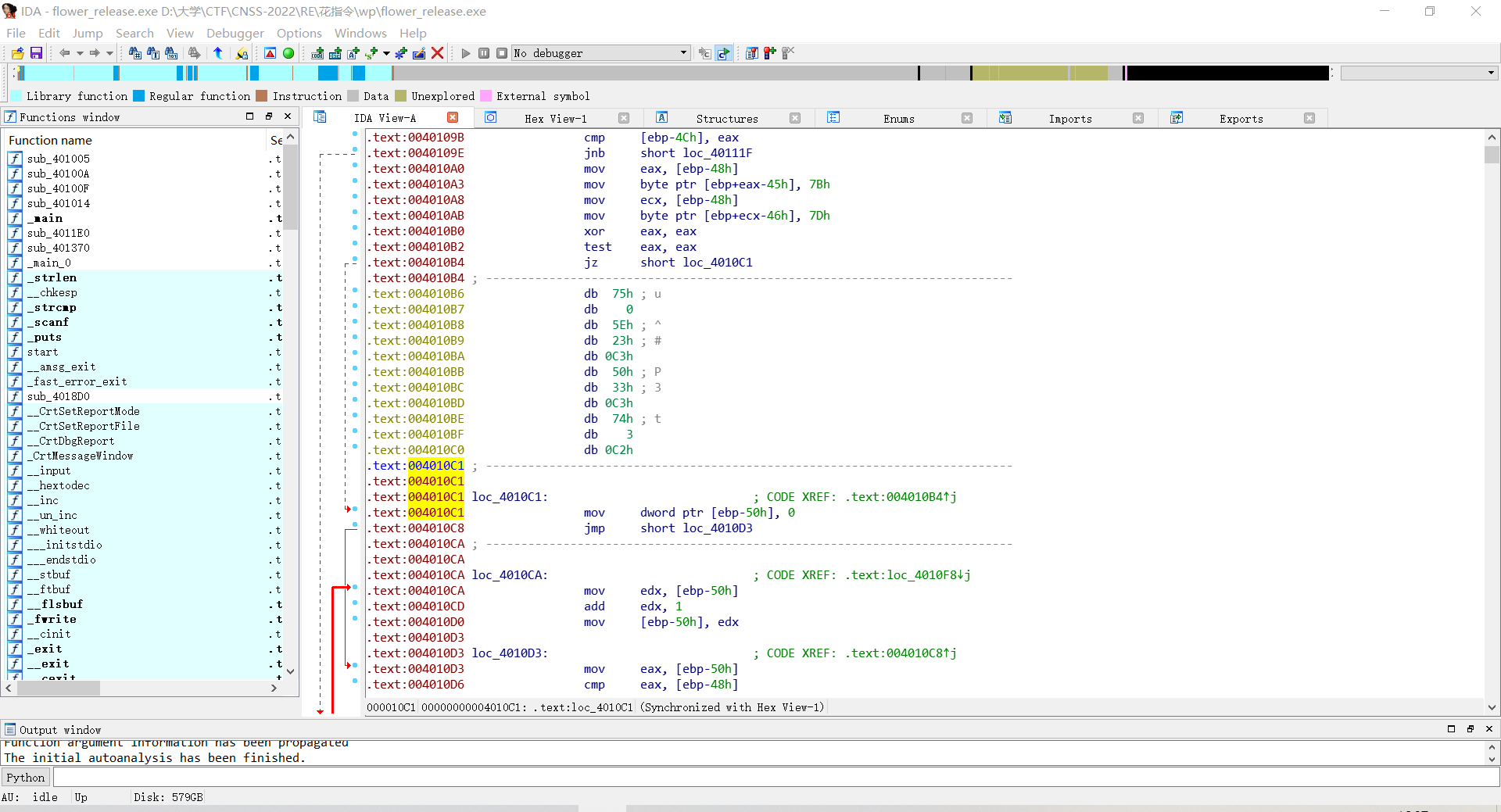
使用
patch program-change byte
将这段无效指令改成90,即nop无操作指令(注意改的是一整个字节,所以改到对应位置(0C2h)需要停下)。
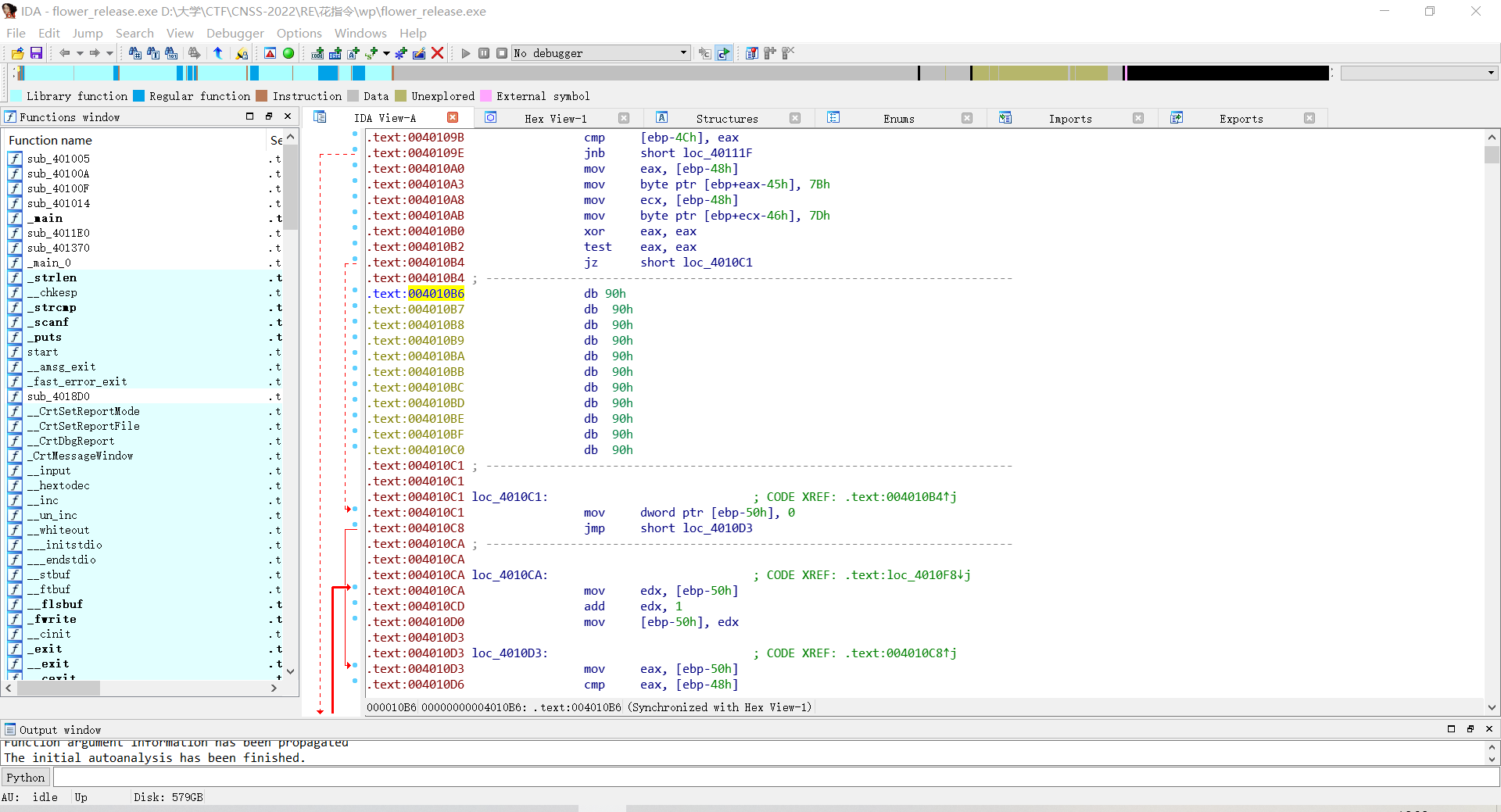
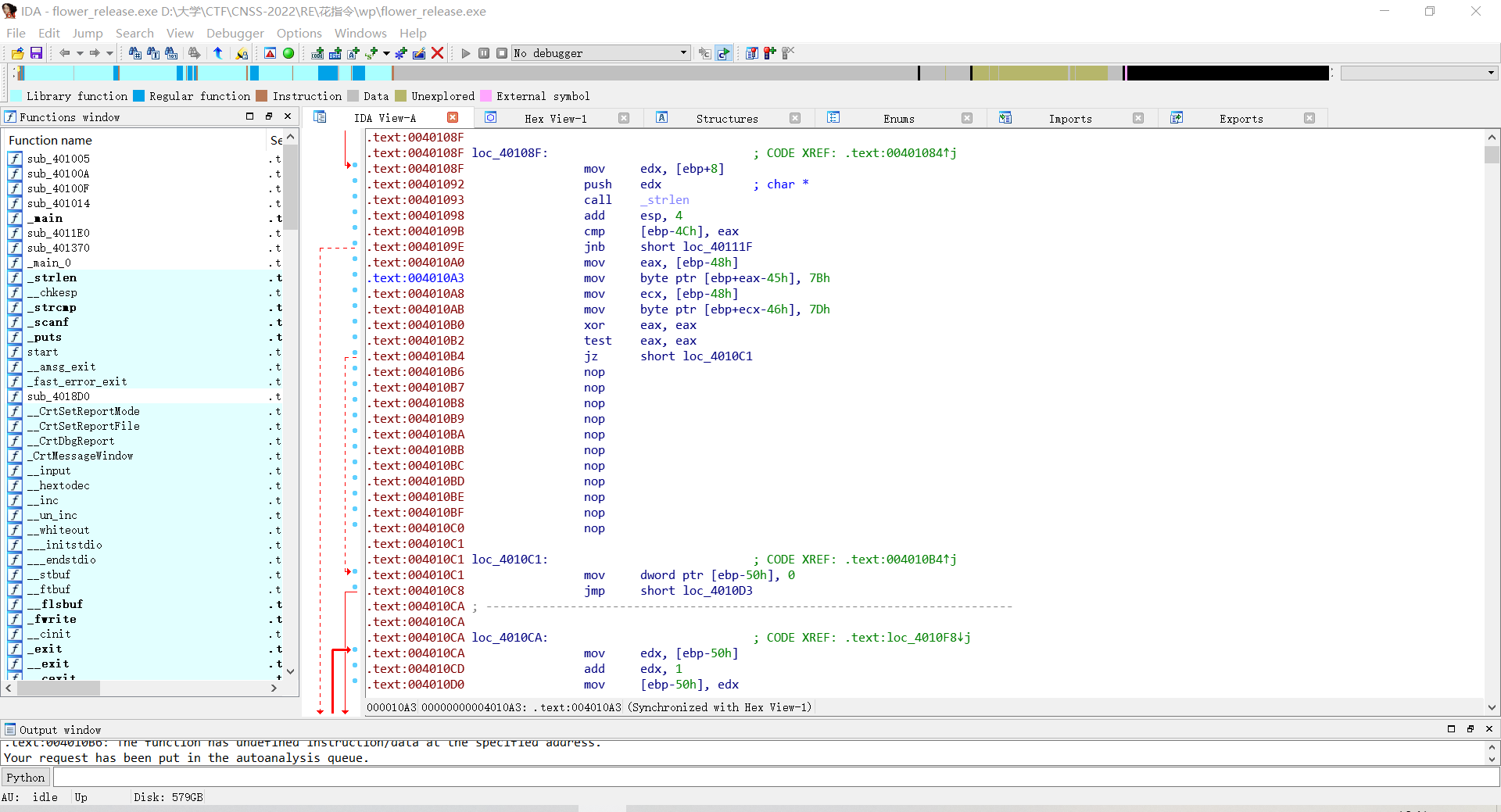
在函数开头:地址401040处按P创建函数。
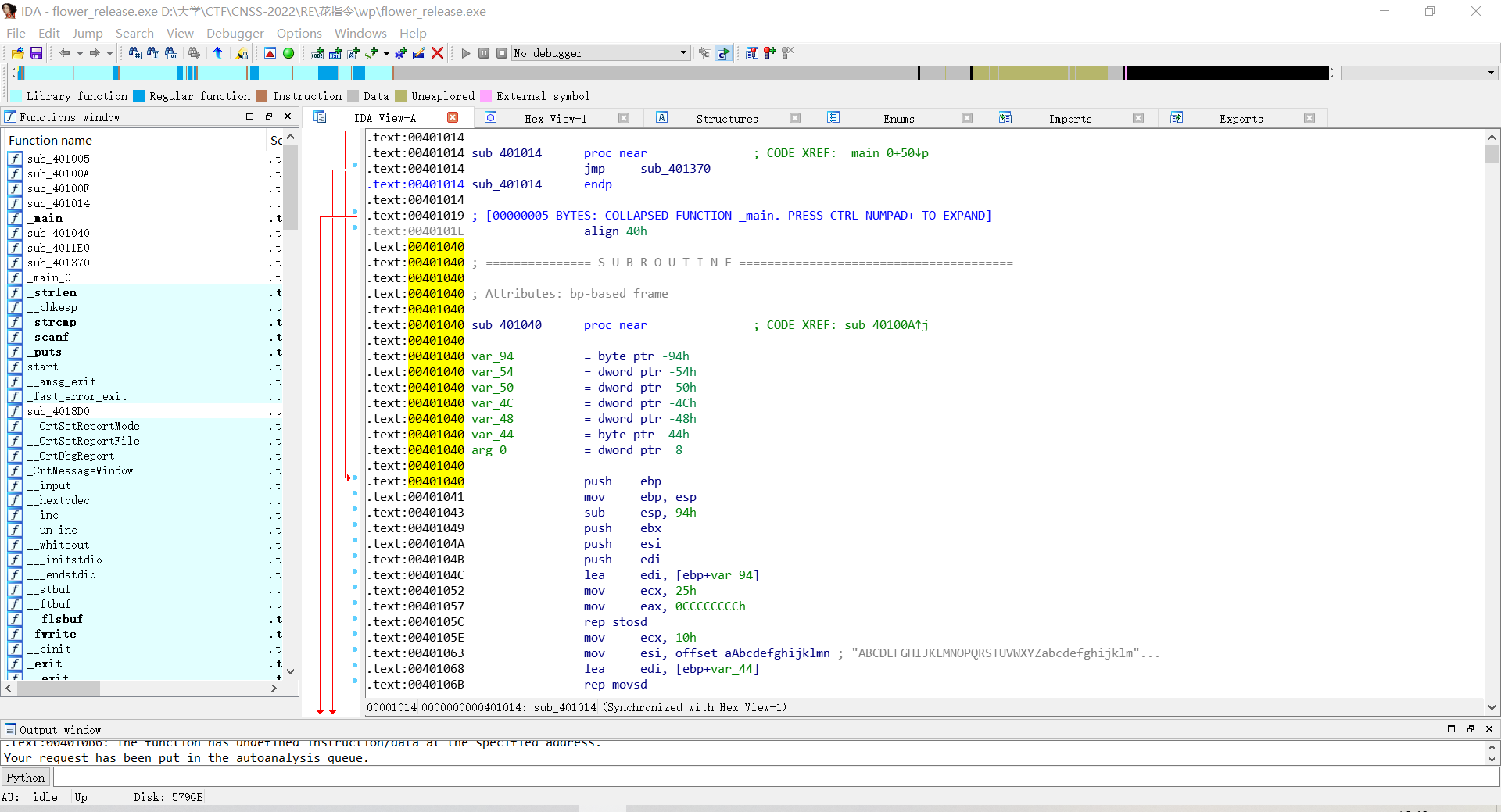
这段函数的花指令就被成功绕过了。
然后看下一个函数
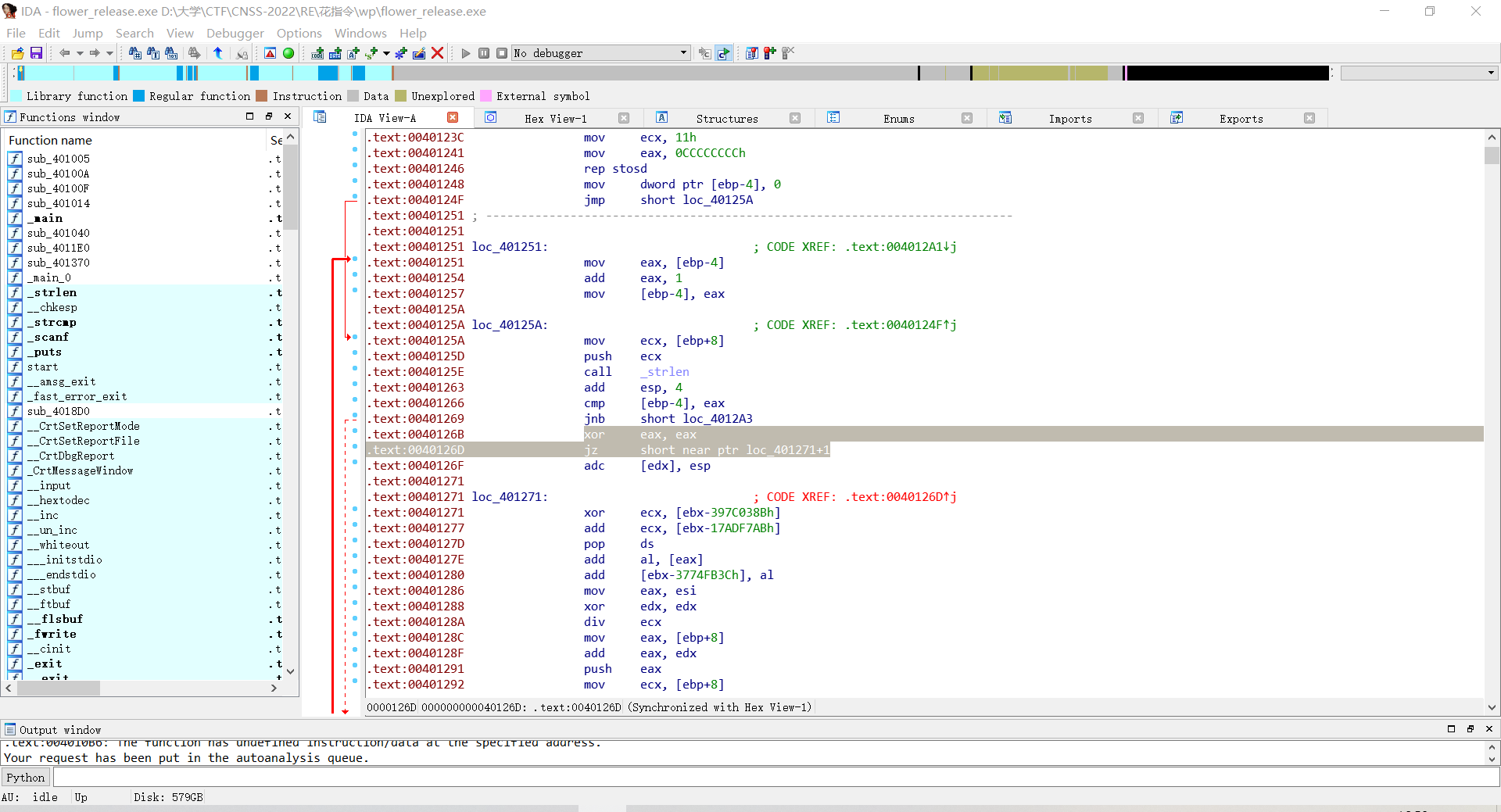
也进行类似的操作,绕过花指令之后按F5反汇编。
(草,复现了半天发现这是32位的,开成了64位IDA。截图就不换了,反正一样)
然后把函数逆向就行
暴力脚本如下(一开始想用Z3解,但不知道为什么跑不了)
#include <bits/stdc++.h>
using namespace std;
char Y[] = "Jew/PwcnwJJsCMMM1qyPZE5iHshiOF";
char v7[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789}{";
int main()
{
char tp;
for (int i = 29; i >= 0; --i)
{
tp = Y[i];
Y[i] = Y[(i + 9) % 30];
Y[(i + 9) % 30] = tp;
}
for (int i = 29; i >= 0; --i)
{
tp = Y[i];
Y[i] = Y[(i + 3) % 30];
Y[(i + 3) % 30] = tp;
}
// printf("%s\n", Y);
for (int i = 29; i >= 0; --i)
{
if (Y[i] == 47)
Y[i] = 123;
if (Y[i] == 43)
Y[i] = 125;
}
// printf("%s\n", Y);
for (int i = 29; i >= 0; --i)
{
for (int j = 0; j < 64; ++j)
{
if (Y[i] == v7[(j + (i >> 1) * 2 * i) % 64])
{
Y[i] = v7[j];
break;
}
}
}
printf("%s", Y);
return 0;
}
flag:
cnss{Fl0w3rC0de1sRe41llyC0oOl}
❤ [Middle] Shino 的心跳大冒险
hint:
听说这道题有很多种方法,但我只会改配置
step:
玩游戏

发现CNSS娘在说flag之前会跑到对话框前面
浏览游戏文件
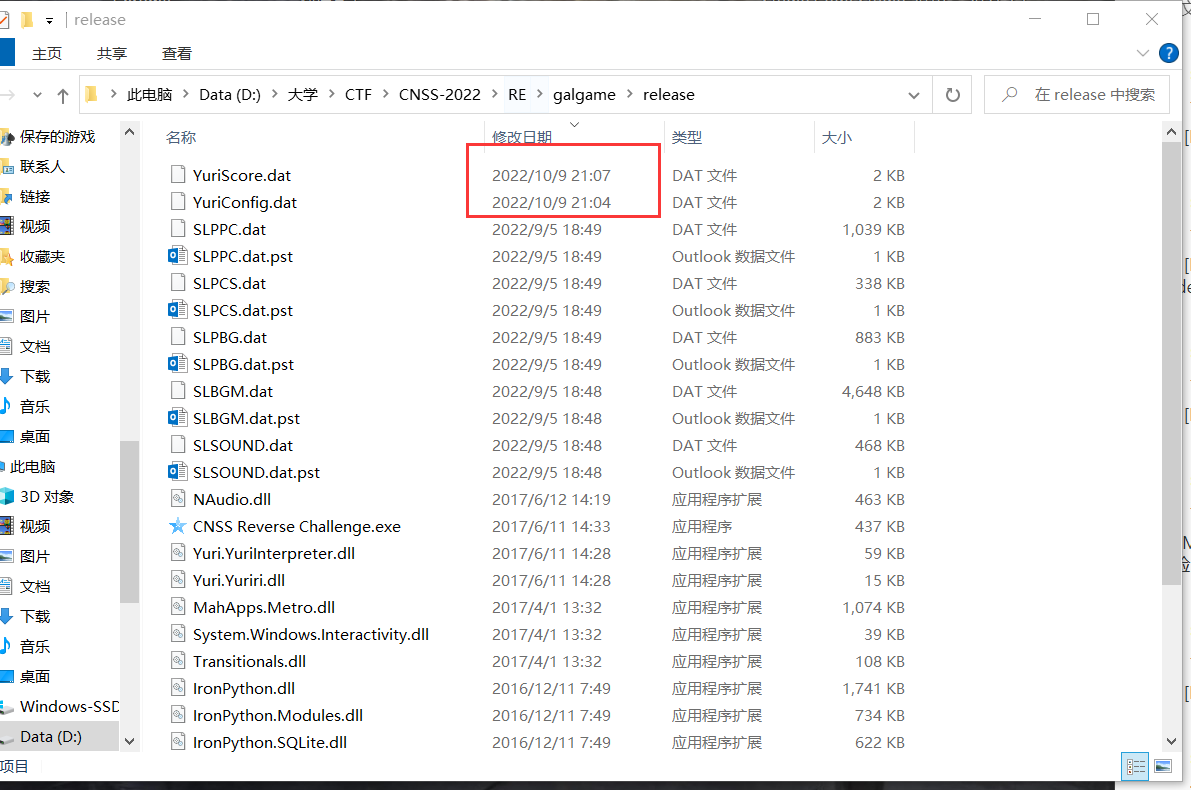
注意到有两个配置日期特别近,说明是近期修改的
点开config配置文件
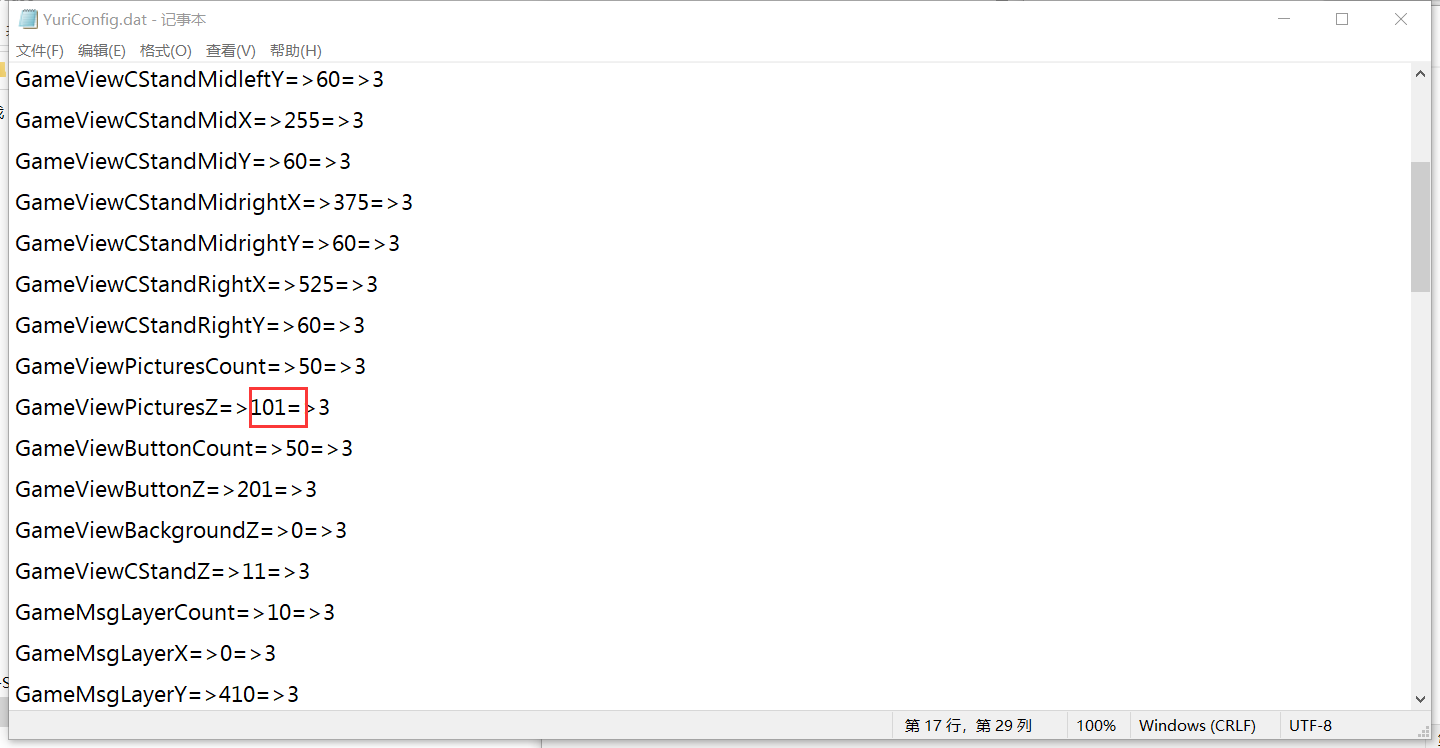
(试错很多次后)
猜测这个“GameViewPictureZ”是图片的z轴坐标(即覆盖顺序)
把101修改成1
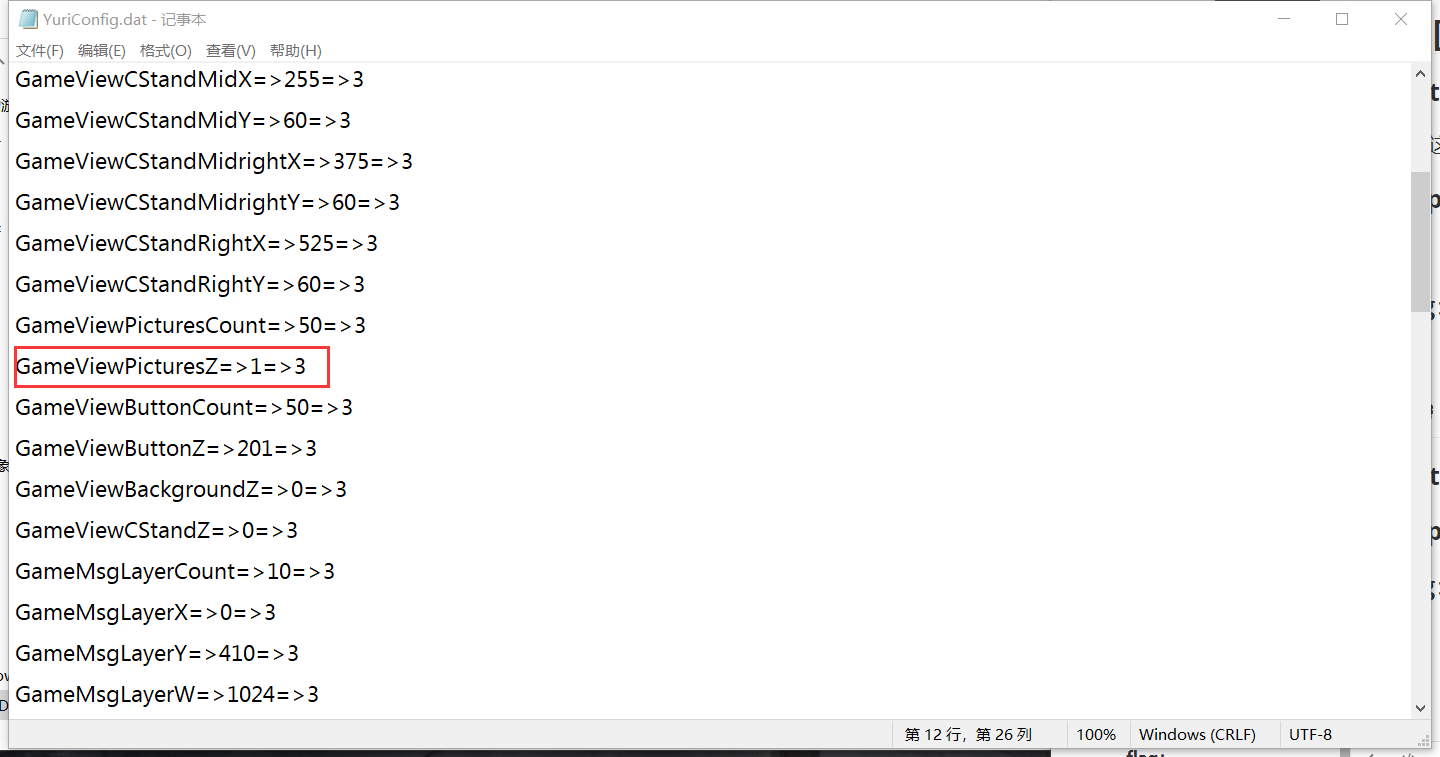
保存配置,重新打开游戏,CNSS娘就不会跑到对话框前面了。

flag:
cnss{Fl0w3rC0de1sRe41llyC0oOl}
🦠 [Easy?] Baby XOR?
hint:
try catch异常处理;
2DES加密与meet in the middle攻击;
png图片格式
step:
根据 hint 1再动手实验得知,IDA 直接 F5 会错误地解析 try catch 的代码,于是看框图
首先这里是第一个干扰,直接 F5 时会有一个带xor运算的循环,看流程图发现如果能正确读入文件,这个循环压根进不去
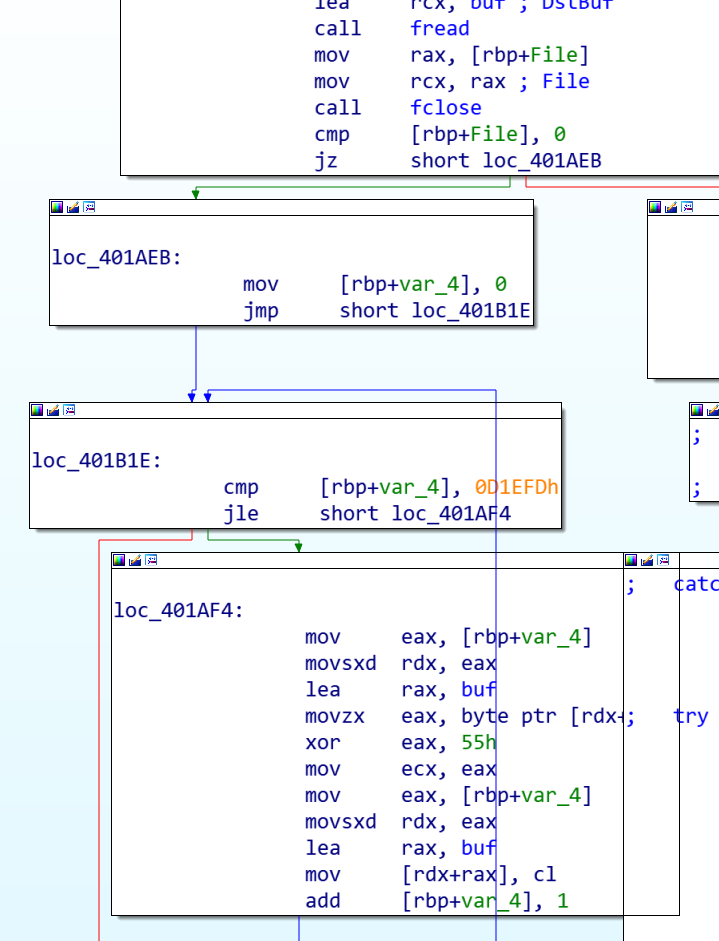
接着是这一段 try catch,和正常的 try catch 代码对比发现,这里的 try catch 直接 throw 了(也可能是上面的 if 判断是源代码里的try catch?)总之try catch没起到什么筛选效果,只干扰了IDA
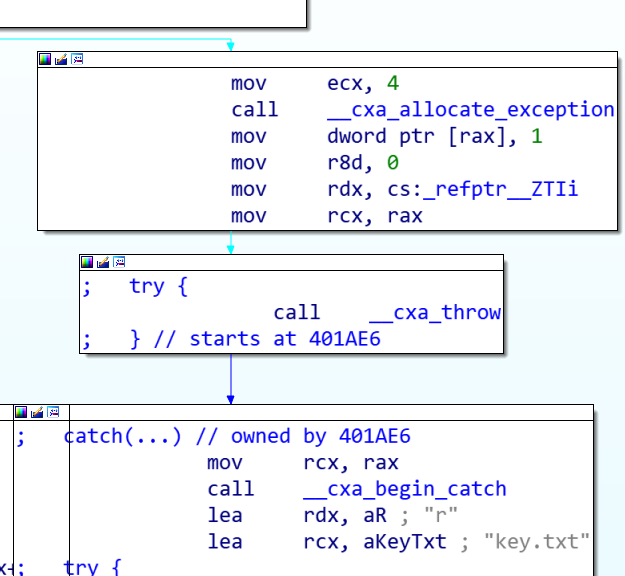
然后程序从 key.txt 读入四个数作为 key 进行第一次加密,再往下看还有第二个一模一样的加密,二者仅有密钥不同。和 hint 2 中提到的 2des 加密对应上了。
接下来分析加密函数
仔细看会发现是经典的 rc4 加密,还加了一些奇奇怪怪的干扰吓唬人(bushi
Enc 函数把异或结果存在 tmp 里,Enc 后面 f5 出来的代码非常混乱,但可以推测这段代码是根据 tmp 对 buf 产生改动。

尝试对这段汇编逆向未果,于是打开动调看这段代码运行前后的差别。注意 buff 存的是 buf 的地址,所以要跳转到 buff 位置的值(也就是 buf 的地址)而不是 buff 本身的地址。结果发现是直接把 tmp 里的数挨个赋值给 buf ?!
enc 执行后 tmp 里的值
这一段执行后 buf 的值
结论:encode 函数在层层干扰之后其实是裸的 rc4 加密
根据 hint3 得知png格式的图片有特定格式,至少已知前8个字节是明文。加密用的是 2des,可以用meet in the middle 攻击。方法是暴力枚举第一次加密的密钥,把明文的所有可能的加密结果和用到的密钥存在map里。然后再暴力枚举第二次的密钥,把已知明文对应的密文进行解密,接着把解密结果扔到map里找是否存在。如果存在说明找到了合法的第一次的密钥。rc4 加密和解密是一样的。找密钥的脚本如下
#include <bits/stdc++.h>
#define ull unsigned long long
#define uchar unsigned char
#define uint unsigned int
using namespace std;
unsigned char op[] =
{
0x89, 0x50, 0x4E, 0x47, 0x0D, 0x0A, 0x1A, 0x0A};
unsigned char ed[] =
{
0x1B, 0xBE, 0x9F, 0xEA, 0x45, 0xEC, 0x6B, 0x6D};
void rc4_init(unsigned char *s, unsigned char *key, unsigned long Len)
{
int i = 0, j = 0;
char k[256] = {0};
unsigned char tmp = 0;
for (i = 0; i < 256; i++)
{
s[i] = i;
k[i] = key[i % Len];
}
for (i = 0; i < 256; i++)
{
j = (j + s[i] + k[i]) % 256;
tmp = s[i];
s[i] = s[j]; //交换s[i]和s[j]
s[j] = tmp;
}
}
/*加解密*/
void rc4_crypt(unsigned char *s, unsigned char *nkey, unsigned long Len)
{
int i = 0, j = 0, t = 0;
unsigned long k = 0;
unsigned char tmp;
for (k = 0; k < Len; k++)
{
i = (i + 1) % 256;
j = (j + s[i]) % 256;
tmp = s[i];
s[i] = s[j]; //交换s[x]和s[y]
s[j] = tmp;
t = (s[i] + s[j]) % 256;
nkey[k] = s[t];
}
}
ull check(uchar *key, uchar *used)
{
uchar sbox[256], nkey[256];
memset(sbox, 0, sizeof(sbox));
rc4_init(sbox, key, 4);
rc4_crypt(sbox, nkey, 256);
ull ret = 0;
for (int i = 0; i < 8; i++)
{
ret = ((ret << 8) | (used[i] ^ nkey[i]));
}
return ret;
}
unordered_map<ull, uint> mp;
int main()
{
for (int i = 0; i < 8; i++)
{
ed[i] -= 17;
}
uchar a[4] = {0};
for (a[0] = 0; a[0] < 81; a[0]++)
{
for (a[1] = 0; a[1] < 81; a[1]++)
{
for (a[2] = 0; a[2] < 81; a[2]++)
{
for (a[3] = 0; a[3] < 81; a[3]++)
{
ull ans = check(a, op);
mp[ans] = *((uint *)(&a));
}
}
}
}
uchar b[4] = {0};
for (b[0] = 0; b[0] < 81; b[0]++)
{
for (b[1] = 0; b[1] < 81; b[1]++)
{
for (b[2] = 0; b[2] < 81; b[2]++)
{
for (b[3] = 0; b[3] < 81; b[3]++)
{
ull ans = check(b, ed);
if (mp.find(ans) != mp.end())
{
puts("OK");
uint tmp = mp[ans];
for (int i = 0; i <= 3; i++)
{
printf("%d ", (int)(tmp & 255));
tmp>>=8;
}
for (int j = 0; j <= 3; j++)
{
printf("%d ", (int)b[j]);
}
puts("");
}
}
}
}
}
return 0;
}
再把原图还原出来
#include <bits/stdc++.h>
#define tot 0xD1EFE
#define ull unsigned long long
#define uchar unsigned char
#define uint unsigned int
using namespace std;
char buf[0xD1EFE + 500];
void rc4_init(unsigned char *s, unsigned char *key, unsigned long Len)
{
int i = 0, j = 0;
char k[256] = {0};
unsigned char tmp = 0;
for (i = 0; i < 256; i++)
{
s[i] = i;
k[i] = key[i % Len];
}
for (i = 0; i < 256; i++)
{
j = (j + s[i] + k[i]) % 256;
tmp = s[i];
s[i] = s[j]; //交换s[i]和s[j]
s[j] = tmp;
}
}
/*加解密*/
void rc4_crypt(unsigned char *s, unsigned char *nkey, unsigned long Len)
{
int i = 0, j = 0, t = 0;
unsigned long k = 0;
unsigned char tmp;
for (k = 0; k < Len; k++)
{
i = (i + 1) % 256;
j = (j + s[i]) % 256;
tmp = s[i];
s[i] = s[j]; //交换s[x]和s[y]
s[j] = tmp;
t = (s[i] + s[j]) % 256;
nkey[k] = s[t];
}
}
ull getans(uchar *key)
{
uchar sbox[256], nkey[256];
memset(sbox, 0, sizeof(sbox));
rc4_init(sbox, key, 4);
rc4_crypt(sbox, nkey, 256);
ull ret = 0;
for (int i = 0; i < tot; i += 256)
{
for (int j = 0; j < 256; j++)
buf[i + j] ^= nkey[j];
}
return ret;
}
int main()
{
FILE* Filein = fopen("setu.png", "rb");
fseek(Filein, 0, 0);
fread(buf, 0xD1EFE, 1, Filein);
fclose(Filein);
for (int j = 0; j <= 0xD1EFD; ++j)
buf[j] -= 17;
uchar key1[4] = {35, 31, 34, 69};
getans(key1);
uchar key2[4] = {25, 6, 19, 63};
getans(key2);
FILE* Fileout = fopen("setu_decoded.png", "wb");
fwrite(buf, 0xD1EFE, 1, Fileout);
fclose(Fileout);
return 0;
}
然后这个题就做完了,flag 把关键部位挡上差评
flag:
cnss{Re4a1_Fu1_St4ck_CtfER_1s_cl3r}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架