一个基于Scrapy框架的pixiv爬虫
源码 https://github.com/vicety/Pixiv-Crawler,功能什么的都在这里介绍了
说几个重要的部分吧
登录部分
困扰我最久的部分,网上找的其他pixiv爬虫的登录方式大多已经不再适用或者根本就没打算登录……
首先,登录时显然要提交FormData,一开始我请求的是 https://accounts.pixiv.net/login?lang=zh 这个页面
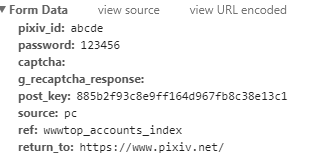
这个postkey可以发现和网页代码中的这个部分(下图)中是一样的,但是用这个postKey是登录不上去的,结果见下图


登录可以成功(收到异常登录邮件),但无论你访问什么页面,它都会无限重定向回这个页面,一开始以为是header填得不完整,可是怎么改都不对
后来发现request请求 http://www.pixiv.net 得到的页面中也有一个postKey(不太明白上一个postKey的含义,难道是特意骗我们一下……)

改用这个,成功登录,剩下应该不是什么问题了
日榜部分
对于日榜的获取(虽然还没有写进去)也值得提一下,日榜的展现是下拉到底端自动获取下一页式的,分析网络请求,发现这一条的链接应该指向的就是下一页,并且去除后面的&tt=96a6bd8c731d3a46a9388f1e8cd90edf也是一样可以访问的

我们进入链接,发现是一个json文件,对于我们来说其实更加易于处理
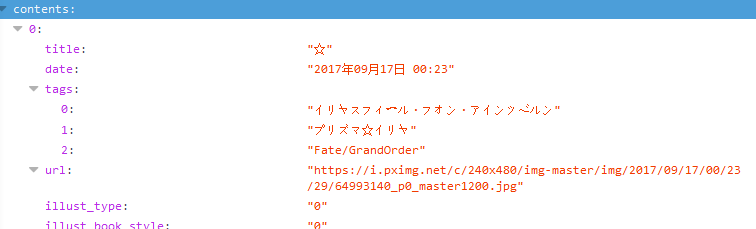
另外说一下,这里推荐Chrome浏览器的JSONView插件,自动解析JSON成方便看的模式,火狐似乎自带这个功能
import json js = json.loads(response.text) url = js["content"]["0"]["url”]
可以使用类似这样的代码方便地读取json文件
另外注意load和loads函数的区别,loads用于处理字符串而load用于处理文件,对于将文件或是字符串转为json则有dump和dumps函数,就像下面这个例子
import json data = { 'a': '123', 'b': True, 'c': None, 'd': 456, } with open("test.json", 'w') as f: json.dump(data, f) # test.json 内容 # {"a": "123", "b": true, "c": null, "d": 456}
搜索部分
在完成按tag搜索的部分时发现,图片div的class都是这种奇怪的格式,尽管在我的电脑上搜索了其他几个tag这些class的名字都是一样的,但是看这种class的名字就有种莫名的不安啊……可能在换个环境class也是会动态变化的
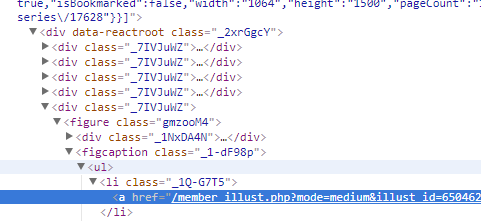
另外发现网页中的这个部分data-items的结构就是json,于是剩下的部分又变得方便很多了
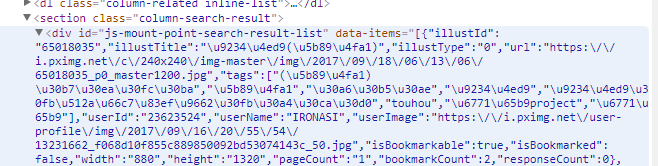
图片获取
在pipeline中获取图片时header中一定要记得带referer,否则会触发p站的防盗链机制,返回403
重要的部分差不多就这些,其他按scrapy的套路走就行
最后,本来想做个GUI的,尝试用pyqt5,发现分离GUI线程和爬虫线程好像挺难解决的,两个线程间用signal通信也很困难,毕竟临时学的qypt,解决不了也正常,于是放弃做GUI的打算……
渣代码,轻喷,欢迎交流指教

 浙公网安备 33010602011771号
浙公网安备 33010602011771号