传统的编程是:
程序开始→代码块A→代码块B→代码块C→...→程序结束
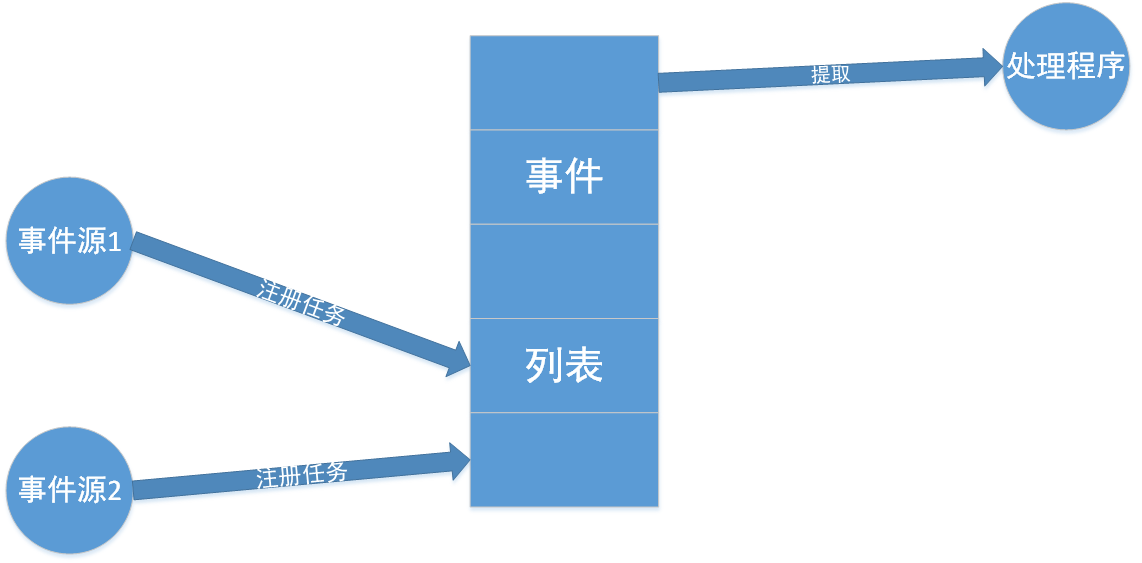
事件驱动模型是:(提高效率的表现)
程序开始→初始化→等待
事件驱动模型,在程序开始(启动)之后,就开始等待,等待被触发的事件。当然,在传统的编程当中也有等待的情况,比如应用input(),此时程序会等待输入的数据。
![]()
传统型——程序员知道在哪里输入或用户被强制输入数据。
事件驱动模型——等待是未知的,程序或系统不知道何时是个头,而一旦触发,则立即作出反应。
1. 每收到一个请求,创建一个新的进程,来处理该请求。
2. 每收到一个请求,创建一个新的线程,来处理该请求。
3. 每收到一个请求,放入一格事件列表,让主进程通过非阻塞I/O方式来处理请求。(事件驱动模型)
1. CPU资源浪费。
2. 如果是堵塞,我们需要扫描很多事件,但由于堵塞,其他的事件就扫描不到。
3. 如果一个循环需要扫描的设备较多,则响应时间就会大大增加。
- I/O多路复用——在实现事件驱动的情况下I/O的自动阻塞的切换。
- I/O的一些种类:
1. 同步I/O:
2. 异步I/O:
用户进程发起read操作后,立刻就可以开始处理,从内核的角度看,当收到一个read操作后,它会立刻返回,不会阻塞用户进程。
当内核数据准备完毕之后,就将数据拷贝到用户内存中去,再然后发送一个信号发往用户进程。
3. 阻塞I/O:
用户进程调用recvfrom,kernel就开始了I/O的第一个阶段:准备数据。当数据在传输过程当中时,这个时候kernel就处于等待状态。用户进程此时会将整个进程阻塞。
当kernel准备好数据之后,则会将数据从kernel中拷贝到用户内存,然后kernel返回结束,用户进程再结束阻塞。
特点:在I/O执行的两个阶段都被阻塞了。
4. 非阻塞I/O:
当用户进程发送read操作时,如果kernel中的数据还没有准备好,用户进程不会被block,此时会立即返回给用户一个ERROR。
从用户的角度看,自己不会被阻塞,会直接得到一个返回结果ERROR,就知道kernel没有给自己准备好有关的数据。用户可以再次
发送read操作,一旦kernel准备好了数据,且内核收到了用户进程的操作,此时会将数据直接拷贝到用户内存中去。
特点:需要一直主动询问。
优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
缺点:任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
5. 缓存I/O:
缓存I/O又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。
缺点:数据在传输过程中,需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销非常大。
1. 对于32位操作系统来说,它的寻址空间(虚拟存储空间)是4G(2^32);对于64位操作系统来说,它的寻址空间是8G。
2. 操作系统的核心是内核,可以访问受保护的内存空间,也有访问底层硬件的权限。
3. 为了保证用户进程不能直接操作内核,所以讲虚拟存储空间划分为两部分,一部分是用户空间,另一部分是内核空间。
4. 在Linux操作系统中,将最高为的1G字节(0xC0000000-0xFFFFFFFF)给内核使用;而将较低的3G字节(0x00000000-0xBFFFFFFF),给用户进程使用。
1. 概念:为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程并执行。
2. 较为浪费资源。
1. 概念:正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。
2. 进程自身主动行为,进入阻塞状态,不占用CPU资源。
1. 概念:计算机科学的一个术语,是一个用于表述指向文件的引用的抽象化概念。
2. 适用于Unix、Linux。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号