.NET遍历二维数组-先行/先列哪个更快?
上周在.NET性能优化群里面有一个很有意思的讨论,讨论的问题如下所示:
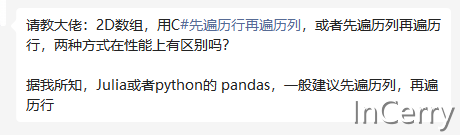
请教大佬:2D数组,用C#先遍历行再遍历列,或者先遍历列再遍历行,两种方式在性能上有区别吗?
据我所知,Julia或者python的 pandas,一般建议先遍历列,再遍历行
在群里面引发了很多大佬的讨论,总的来说观点分为以下三种:
- 应该不会有什么差别
- 先遍历列会比先遍历行更快
- 先遍历行会比先遍历列更快
看了群里面激烈的讨论,刚好今天有时间,我们就来看看真实情况是怎么样的?实践出真知,我们编写一个Benchmark一测便知。
测试
在下面的代码中,我们创建了一个 ArrayBenchmark 类,它包含了两个方法:RowFirst 和 ColumnFirst。这两个方法分别代表了先行后列和先列后行两种遍历方式。每次测试时,数组的大小将使用参数(Size)设置。在 Main 方法中,我们调用 BenchmarkRunner.Run 方法来运行测试。
using System;
using System.Diagnostics;
using BenchmarkDotNet.Attributes;
namespace TwoDimensionalArrayBenchmark
{
public class ArrayBenchmark
{
private int[,] _array;
[Params(1000, 2000, 4000, 8000, 16000)]
public int Size { get; set; }
[GlobalSetup]
public void Setup()
{
_array = new int[Size, Size];
var rnd = new Random();
for (int i = 0; i < Size; i++)
{
for (int j = 0; j < Size; j++)
{
_array[i, j] = rnd.Next();
}
}
}
[Benchmark]
public int RowFirst()
{
// 先遍历一整行
int sum = 0;
for (int i = 0; i < Size; i++)
{
for (int j = 0; j < Size; j++)
{
sum += _array[i, j];
}
}
return sum;
}
[Benchmark]
public int ColumnFirst()
{
// 先遍历一整列
int sum = 0;
for (int j = 0; j < Size; j++)
{
for (int i = 0; i < Size; i++)
{
sum += _array[i, j];
}
}
return sum;
}
}
class Program
{
static void Main(string[] args)
{
var summary = BenchmarkDotNet.Running.BenchmarkRunner.Run<ArrayBenchmark>();
Console.ReadKey();
}
}
}
得出的结果如下所示,从结果中我们可以看到,在.NET7.0中先遍历行远远快于先遍历列,随着数据量的增大有着近10倍的差距:

关于为什么先行后列的性能比先列后行高,猜测主要有以下两个原因:
-
CPU 缓存层次结构:当遍历二维数组时,先行后列方式更适合利用 CPU 的缓存层次结构。每次访问二维数组中的一行数据时,这一整行的数据都可以从 L1/L2/L3 缓存中读取,这样就可以大大提高数据读取的效率。
-
内存布局:二维数组的内存布局可能是按行存储的,也就是说一整行的数据在内存中是连续的。因此,先行后列的方式更容易利用内存的连续性,使数据读取更加顺畅。
我们可以通过简单的代码来验证一下.NET中二维数组的存储格式,使用Unsafe.AsPointer可以获取引用对象的指针,然后将其强转为long类型即可获得它的地址。
下面使用的是先行后列的遍历方式:
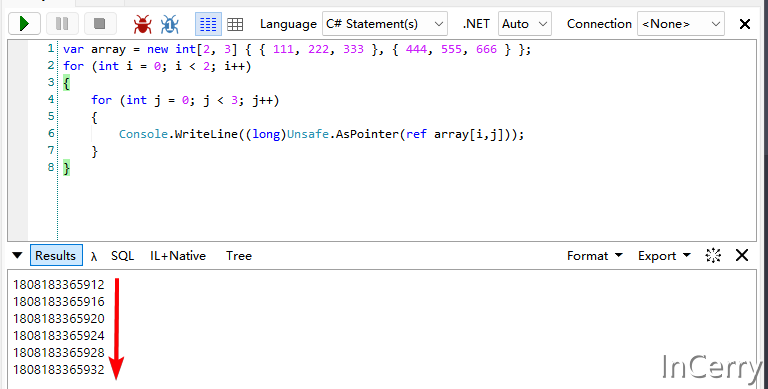
由于一个int类型占用4字节的空间,所以我们可以发现在使用先行后列的方式时刚好就是顺序顺序递增的。
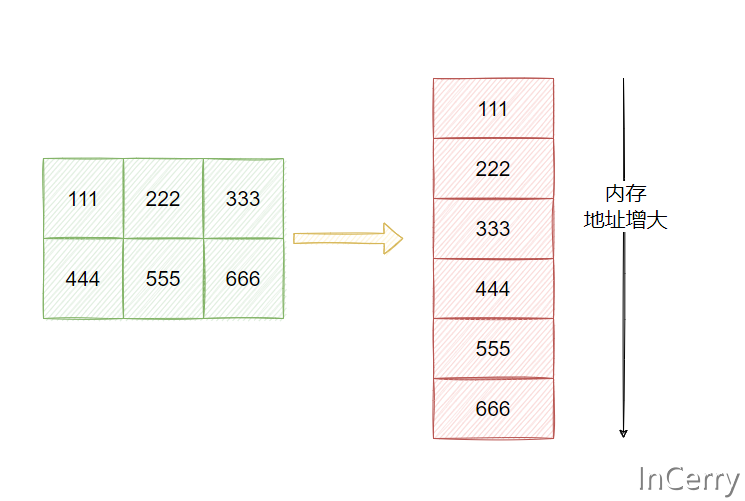
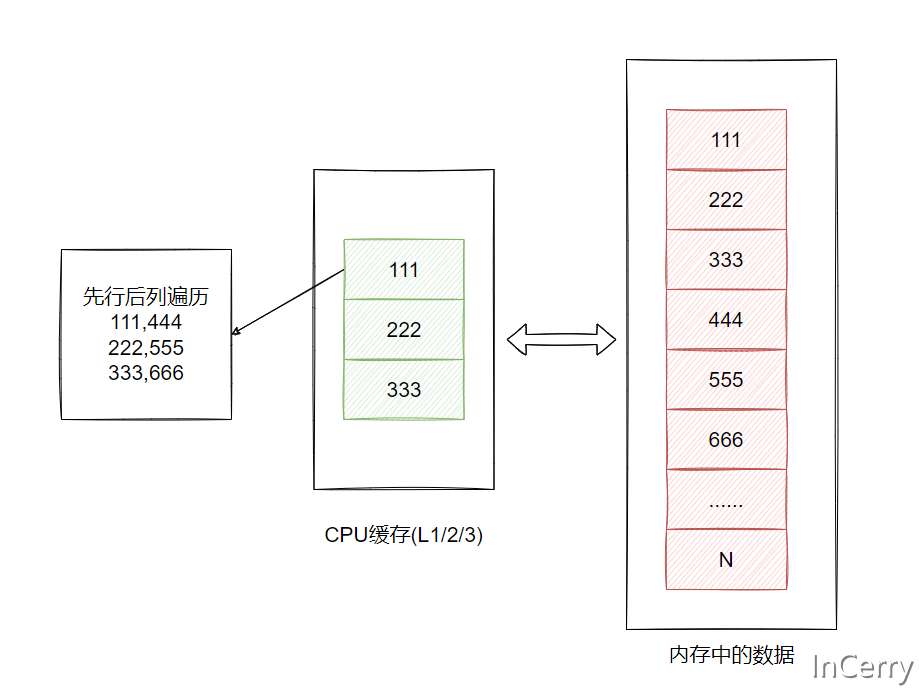
也就是说C#在逻辑上虽然是二维数组,实际上存储是按每一行连续存储的,如下图所示:
CPU的缓存也是按照这个顺序进行缓存的,所以当我们先行后列遍历的时候整行数据都可能在CPU缓存中,可以最大化的利用好CPU缓存。
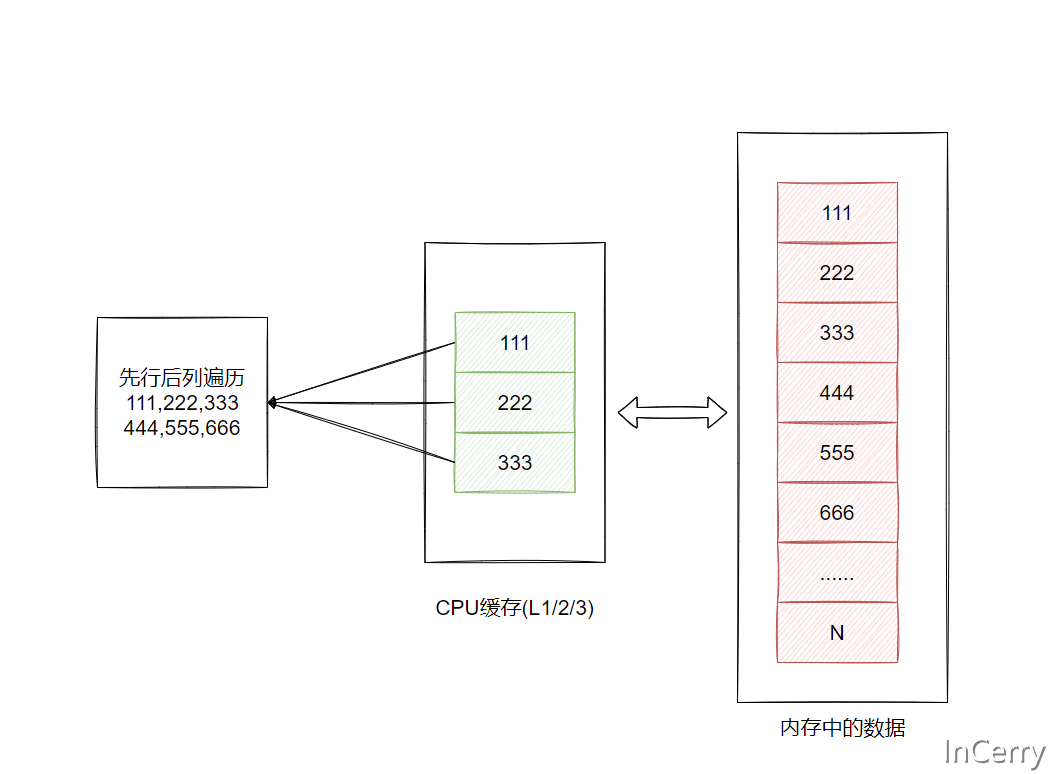
如果按照先列后行的遍历,那么对缓存就很不友好,需要多次从内存中读取数据。
总结
这就是本文的全部了,目前看来在C# .NET中遍历二维数组是先行快于先列,不过这也不是绝对的事情,因为在编译器和即时编译器中,是可以自动的去做一些优化,让程序更快的访问数据。比如在群里大佬们比较了在VC中的差异,结果是发现DEBUG模式确实行快于列,但是Release两者差别几乎可以忽略不计,当然这不在本文的讨论范围中。
.NET性能优化交流群
相信大家在开发中经常会遇到一些性能问题,苦于没有有效的工具去发现性能瓶颈,或者是发现瓶颈以后不知道该如何优化。之前一直有读者朋友询问有没有技术交流群,但是由于各种原因一直都没创建,现在很高兴的在这里宣布,我创建了一个专门交流.NET性能优化经验的群组,主题包括但不限于:
- 如何找到.NET性能瓶颈,如使用APM、dotnet tools等工具
- .NET框架底层原理的实现,如垃圾回收器、JIT等等
- 如何编写高性能的.NET代码,哪些地方存在性能陷阱
希望能有更多志同道合朋友加入,分享一些工作中遇到的.NET性能问题和宝贵的性能分析优化经验。目前一群已满,现在开放二群。
如果提示已经达到200人,可以加我微信,我拉你进群: ls1075
另外也创建了QQ群,群号: 687779078,欢迎大家加入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号