SQLSERVER大批量数据快速导入Redis
目的
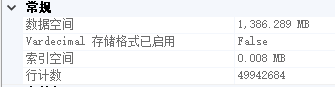
把单表近5千万的某单个字段导入到Redis,作为一个list存储。
方案一: 使用sqlcmd工具(sqlserver自带),直接生成命令在Redis-cli中执行。
方案一. 使用sqlcmd把打印结果输出在文本中,然后用redis-cli逐行执行文本中的命令。
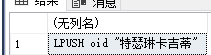
redis写入list的命令。
LPUSH openids xxxx
- 用sqlserver拼接处这个结果
SET NOCOUNT ON;
SELECT 'LPUSH openids ' +'"' + openID +'"'
FROM [dbo].[table1]
- 使用sqlcmd,推送到redis-cli执行
# -S:服务器地址,-U:账号名 -P:密码 -d:数据库 -h:列标题之间打印的行数
sqlcmd -S . -U sa -P xxxx -d DataImport -h -1 -i d:\openid.sql | redis-cli -h 192.168.xx.xx -a xxxx -p 6379
结论
- 能勉强成功。
- 导入速度慢,大概2w/s ~ 3w/s。远低于Redis的写入理想值。
- 容易出错,如果value中含有意外字符,会导致命令执行失败,结束任务。
- 别用这个方法。
官网支撑:
Redis is a TCP server using the client-server model and what is called a Request/Response protocol.
This means that usually a request is accomplished with the following steps:
The client sends a query to the server, and reads from the socket, usually in a blocking way, for the server response.
The server processes the command and sends the response back to the client.
方案二: 使用sqlcmd工具(sqlserver自带),直接生成redis协议在Redis-cli中执行。(可以直接看这个方案)
使用sqlserver直接生成协议命令
--*3:由三个参数组成:LPUSH,key,value。
--$5: 'LPUSH'的字符串长度。
--$7: 'openids'的字符串长度。
--$n: {value}的长度
--char(13): /r
--char(10): /n
SET NOCOUNT ON;
SELECT '*3'+char(13)+CHAR(10) + '$5'+char(13)+CHAR(10) + 'LPUSH'+char(13)+CHAR(10) + '$7'+char(13)+CHAR(10)
+ 'openids'+char(13)+CHAR(10) +'$'+ CAST(DATALENGTH(openID) as varchar(255)) +char(13)+CHAR(10)+openID+char(13)+CHAR(10)
FROM [dbo].[table1]
# --pipe 使用管道模式
sqlcmd -S . -U sa -P xxxx -d DataImport -h -1 -i d:\openid.sql | redis-cli -h 192.168.xx.xx -a xxxx -p 6379 --pipe
执行效果:

(为什么只有2660万条呢?因为我分两次运行了)

结论:
- 不会受value的影响,中断运行。
- 运行速度快,差不多13w/s。接近理想值。
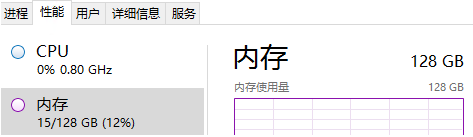
- 亲测,第一次在写入2800万的时候,我的128G内存撑不住了,Redis直接崩了。所以,我选择rownumber() over()从中断的地方,继续写入。
官网支撑:
Using a normal Redis client to perform mass insertion is not a good idea for a few reasons: the naive approach of sending one command after the other is slow because you have to pay for the round trip time for every command. It is possible to use pipelining, but for mass insertion of many records you need to write new commands while you read replies at the same time to make sure you are inserting as fast as possible.
Only a small percentage of clients support non-blocking I/O, and not all the clients are able to parse the replies in an efficient way in order to maximize throughput. For all this reasons the preferred way to mass import data into Redis is to generate a text file containing the Redis protocol, in raw format, in order to call the commands needed to insert the required data.
附:
# sqlcmd导出到文本
sqlcmd -S . -U sa -P xxx -d DataImport -h -1 -i d:\openid.sql > d:\tt.txt
# 从文本推到redis-cli执行。
type protocol-commands.txt | redis-cli -h 192.168.xx.xx -a xxxx -p 6379 --pipe
把redis的正常命令转成协议格式的批处理脚本
亲测,近5千万数据的文本,是动都动不了。
while read CMD; do
# each command begins with *{number arguments in command}\r\nW
XS=($CMD); printf "*${#XS[@]}\r\n"WWW
# for each argument, we append ${length}\r\n{argument}\r\n
for X in $CMD; do printf "\$${#X}\r\n$X\r\n"; done
done < origin-commands.txt
协议样本:
*3
$5
LPUSH
$3
arr
$4
AAAA
*3
$5
LPUSH
$3
arr
$4
BBBB

 浙公网安备 33010602011771号
浙公网安备 33010602011771号