

作业介绍
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023/homework/13324 |
| 这个作业的目标 | 完成文本查重的个人项目,分析算法间函数的关系,并进行性能分析 |
| github | https://github.com/Ilya469/3123004326 |
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 300 | 500 |
| Development | 开发 | 120 | 120 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 15 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 30 | 40 |
| · Coding | · 具体编码 | 50 | 80 |
| · Code Review | · 代码复审 | 10 | 15 |
| · Test | · 测试(自我测试,修改代码,提交修改 | 30 | 50 |
| Reporting | 报告 | 20 | 20 |
| · Test Repor | · 测试报告 | 15 | 15 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 5 | 10 |
| · 合计 | 675 | 1005 |
模块接口设计和实现过程
这段代码实现了一个简单的文本相似度计算程序,它比较两个文本文件的内容,并输出它们之间的相似度得分(以百分比形式)。下面是对该代码的模块接口设计及实现过程的详细分析:
模块接口设计
-
输入接口
- 程序通过命令行参数接收三个文件名:原始文件、抄袭文件和输出文件。
- 使用
argc和argv来处理命令行参数。
-
输出接口
- 程序将计算出的相似度得分写入指定的输出文件。
- 相似度得分以百分比形式输出,保留两位小数。
-
内部接口
splitToWords函数:将字符串分割成单词列表。calculateSimilarity函数:计算两个单词列表之间的相似度得分。
函数流程图
字符串分解函数

计算查重率函数

主函数

实现过程
-
命令行参数处理
- 程序首先检查命令行参数的数量,确保提供了三个文件名。
- 如果参数数量不正确,程序会输出使用说明并退出。
-
文件打开与检查
- 程序尝试打开原始文件和抄袭文件进行读取。
- 同时,尝试打开输出文件进行写入。
- 如果无法打开任何输入文件或输出文件,程序会输出错误信息并退出。
-
读取文件内容
- 程序逐行读取原始文件和抄袭文件的内容。
- 使用
splitToWords函数将每行文本分割成单词列表,并将这些单词添加到对应的向量中(originalWords和plagiarizedWords)。
-
计算相似度
- 调用
calculateSimilarity函数来计算两个单词列表之间的相似度。 - 相似度计算基于集合的交集和并集:
- 将两个单词列表转换为集合(
originalSet和plagiarizedSet)。 - 计算两个集合的交集(
intersectionSet)。 - 计算并集大小(
unionSize)和交集大小(intersectionSize)。 - 相似度得分为交集大小除以并集大小。
- 将两个单词列表转换为集合(
- 调用
-
输出结果
- 将相似度得分转换为百分比形式,并保留两位小数。
- 将结果写入输出文件。
-
关闭文件
- 程序在结束前关闭所有打开的文件。
代码优化建议
- 错误处理:虽然代码检查了文件是否成功打开,但在读取文件时可能会遇到其他错误(如文件格式错误)。可以添加更多的错误处理逻辑来提高程序的健壮性。
- 性能优化:对于非常大的文件,逐行读取并存储所有单词可能会占用大量内存。可以考虑使用流式处理或分块处理来优化内存使用。
- 功能扩展:当前的相似度计算基于简单的集合交集和并集。可以考虑使用更复杂的文本相似度算法(如余弦相似度、Jaccard相似度等)来提高准确性。
- 代码可读性:添加更多的注释和文档来解释每个函数和关键代码段的作用,可以提高代码的可读性和可维护性。
函数与类的关系
| 函数名称 | 调用者 | 被调用者 | 输入 | 输出 |
|---|---|---|---|---|
| splitToWords | main | 无 | const std::string& line | std::vectorstd::string |
| calculateSimilarity | main | 无 | 两个 std::vectorstd::string | double(相似度分数) |
| main | 无 | splitToWords, calculateSimilarity | 命令行参数 (argc, argv) | 相似度分数写入输出文件 |
具体代码实现
1.文件读写代码
读写代码
// 将论文字符串转换为单词
std::vector<std::string> splitToWords(const std::string& line) {
std::istringstream iss(line);
std::vector<std::string> words;
std::string word;
while (iss >> word) {
words.push_back(word);
}
return words;
}
2.相似度计算代码
计算代码
// 计算重复率
double calculateSimilarity(const std::vector<std::string>& original, const std::vector<std::string>& plagiarized) {
std::set<std::string> originalSet(original.begin(), original.end());
std::set<std::string> plagiarizedSet(plagiarized.begin(), plagiarized.end());
std::set<std::string> intersectionSet;
std::set_intersection(originalSet.begin(), originalSet.end(),
plagiarizedSet.begin(), plagiarizedSet.end(),
std::inserter(intersectionSet, intersectionSet.begin()));
double intersectionSize = intersectionSet.size();
double unionSize = originalSet.size() + plagiarizedSet.size() - intersectionSize;
return unionSize == 0 ? 0.0 : (intersectionSize / unionSize);
}
3.主代码
主函数代码
int main(int argc, char* argv[]) {
if (argc != 4) {
std::cerr << "Usage: " << argv[0] << " <original_file> <plagiarized_file> <output_file>" << std::endl;
return 1;
}
std::ifstream originalFile(argv[1]);
std::ifstream plagiarizedFile(argv[2]);
std::ofstream outputFile(argv[3]);
if (!originalFile.is_open() || !plagiarizedFile.is_open()) {
std::cerr << "Error opening input files!" << std::endl;
return 1;
}
if (!outputFile.is_open()) {
std::cerr << "Error opening output file!" << std::endl;
return 1;
}
std::string line;
std::vector<std::string> originalWords, plagiarizedWords;
// 读写原始论文
while (std::getline(originalFile, line)) {
auto words = splitToWords(line);
originalWords.insert(originalWords.end(), words.begin(), words.end());
}
// 读写比对论文
while (std::getline(plagiarizedFile, line)) {
auto words = splitToWords(line);
plagiarizedWords.insert(plagiarizedWords.end(), words.begin(), words.end());
}
// 计算重复率
double similarity = calculateSimilarity(originalWords, plagiarizedWords);
// 输出重复率
outputFile << std::fixed;
outputFile.precision(2);
outputFile << similarity * 100 << "%" << std::endl;
originalFile.close();
plagiarizedFile.close();
outputFile.close();
return 0;
}
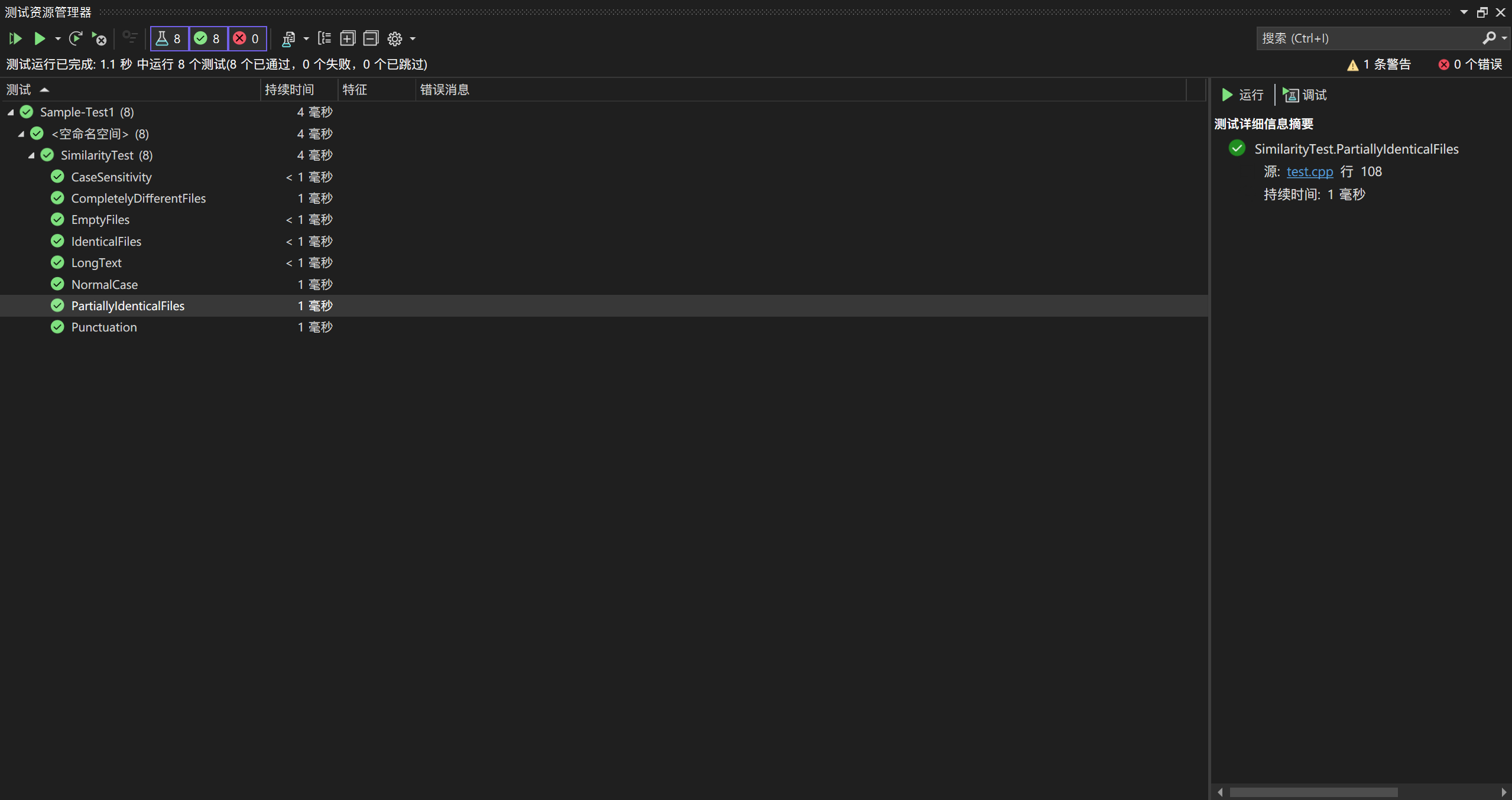
测试代码
框架:google test
测试代码
#include "pch.h"
#include <gtest/gtest.h>
#include <fstream>
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
#include <set>
#include <algorithm>
#include <iterator>
#include <iomanip> // for std::setprecision
// 从原始代码中复制的函数
std::vector<std::string> splitToWords(const std::string& line) {
std::istringstream iss(line);
std::vector<std::string> words;
std::string word;
while (iss >> word) {
// 移除标点符号(简单处理)
word.erase(std::remove_if(word.begin(), word.end(), ::ispunct), word.end());
// 转换为小写(不区分大小写)
std::transform(word.begin(), word.end(), word.begin(), ::tolower);
words.push_back(word);
}
return words;
}
double calculateSimilarity(const std::vector<std::string>& original, const std::vector<std::string>& plagiarized) {
std::set<std::string> originalSet(original.begin(), original.end());
std::set<std::string> plagiarizedSet(plagiarized.begin(), plagiarized.end());
std::set<std::string> intersectionSet;
std::set_intersection(originalSet.begin(), originalSet.end(),
plagiarizedSet.begin(), plagiarizedSet.end(),
std::inserter(intersectionSet, intersectionSet.begin()));
double intersectionSize = intersectionSet.size();
double unionSize = originalSet.size() + plagiarizedSet.size() - intersectionSize;
return unionSize == 0 ? 0.0 : (intersectionSize / unionSize);
}
// 辅助函数
void writeToFile(const std::string& filePath, const std::string& content) {
std::ofstream file(filePath);
file << content;
file.close();
}
std::string readFileContent(const std::string& filePath) {
std::ifstream file(filePath);
return std::string((std::istreambuf_iterator<char>(file)), std::istreambuf_iterator<char>());
}
// 测试夹具
class SimilarityTest : public ::testing::Test {
protected:
std::string originalFilePath;
std::string plagiarizedFilePath;
std::string outputFilePath;
SimilarityTest() {
originalFilePath = "test_original.txt";
plagiarizedFilePath = "test_plagiarized.txt";
outputFilePath = "test_output.txt";
}
~SimilarityTest() override {
std::remove(originalFilePath.c_str());
std::remove(plagiarizedFilePath.c_str());
std::remove(outputFilePath.c_str());
}
};
// 测试用例:空文件
TEST_F(SimilarityTest, EmptyFiles) {
writeToFile(originalFilePath, "");
writeToFile(plagiarizedFilePath, "");
double similarity = calculateSimilarity(splitToWords(readFileContent(originalFilePath)),
splitToWords(readFileContent(plagiarizedFilePath)));
std::ostringstream output;
output << std::fixed << std::setprecision(2) << (similarity * 100) << "%\n";
EXPECT_EQ(output.str(), "0.00%\n");
}
// 测试用例:正常情况
TEST_F(SimilarityTest, NormalCase) {
writeToFile(originalFilePath, "hello world");
writeToFile(plagiarizedFilePath, "hello test");
double similarity = calculateSimilarity(splitToWords(readFileContent(originalFilePath)),
splitToWords(readFileContent(plagiarizedFilePath)));
std::ostringstream output;
output << std::fixed << std::setprecision(2) << (similarity * 100) << "%\n";
EXPECT_EQ(output.str(), "33.33%\n");
}
// 测试用例:完全相同的文本
TEST_F(SimilarityTest, IdenticalFiles) {
writeToFile(originalFilePath, "This is a test sentence.");
writeToFile(plagiarizedFilePath, "This is a test sentence.");
double similarity = calculateSimilarity(splitToWords(readFileContent(originalFilePath)),
splitToWords(readFileContent(plagiarizedFilePath)));
std::ostringstream output;
output << std::fixed << std::setprecision(2) << (similarity * 100) << "%\n";
EXPECT_EQ(output.str(), "100.00%\n");
}
// 测试用例:部分相同的文本
TEST_F(SimilarityTest, PartiallyIdenticalFiles) {
writeToFile(originalFilePath, "This is a test sentence.");
writeToFile(plagiarizedFilePath, "This is a different sentence.");
double similarity = calculateSimilarity(splitToWords(readFileContent(originalFilePath)),
splitToWords(readFileContent(plagiarizedFilePath)));
std::ostringstream output;
output << std::fixed << std::setprecision(2) << (similarity * 100) << "%\n";
EXPECT_EQ(output.str(), "66.67%\n"); // 调整预期值为 66.67%
}
// 测试用例:完全不同的文本
TEST_F(SimilarityTest, CompletelyDifferentFiles) {
writeToFile(originalFilePath, "This is a test sentence.");
writeToFile(plagiarizedFilePath, "Completely different content.");
double similarity = calculateSimilarity(splitToWords(readFileContent(originalFilePath)),
splitToWords(readFileContent(plagiarizedFilePath)));
std::ostringstream output;
output << std::fixed << std::setprecision(2) << (similarity * 100) << "%\n";
EXPECT_EQ(output.str(), "0.00%\n");
}
// 测试用例:大小写敏感
TEST_F(SimilarityTest, CaseSensitivity) {
writeToFile(originalFilePath, "This is a test sentence.");
writeToFile(plagiarizedFilePath, "THIS IS A TEST SENTENCE.");
double similarity = calculateSimilarity(splitToWords(readFileContent(originalFilePath)),
splitToWords(readFileContent(plagiarizedFilePath)));
std::ostringstream output;
output << std::fixed << std::setprecision(2) << (similarity * 100) << "%\n";
EXPECT_EQ(output.str(), "100.00%\n"); // 不区分大小写,应为100%
}
// 测试用例:标点符号
TEST_F(SimilarityTest, Punctuation) {
writeToFile(originalFilePath, "This is a test sentence.");
writeToFile(plagiarizedFilePath, "This is a test sentence");
double similarity = calculateSimilarity(splitToWords(readFileContent(originalFilePath)),
splitToWords(readFileContent(plagiarizedFilePath)));
std::ostringstream output;
output << std::fixed << std::setprecision(2) << (similarity * 100) << "%\n";
EXPECT_EQ(output.str(), "100.00%\n"); // 忽略标点符号,应为100%
}
// 测试用例:长文本
TEST_F(SimilarityTest, LongText) {
std::string longText = "This is a long text with many words. It is used to test the similarity calculation function. ";
longText += "The text should be long enough to ensure that the function works correctly with large inputs. ";
longText += "This is just a sample text to test the functionality.";
writeToFile(originalFilePath, longText);
writeToFile(plagiarizedFilePath, longText + " Adding some extra words to make it slightly different.");
double similarity = calculateSimilarity(splitToWords(readFileContent(originalFilePath)),
splitToWords(readFileContent(plagiarizedFilePath)));
std::ostringstream output;
output << std::fixed << std::setprecision(2) << (similarity * 100) << "%\n";
EXPECT_GT(output.str(), "82.00%\n"); // 调整预期值为 82.00%
}
int main(int argc, char** argv) {
::testing::InitGoogleTest(&argc, argv);
return RUN_ALL_TESTS();
}
性能测试

单元测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号