
Tesseract-OCR下载安装
原文转自:https://blog.csdn.net/weixin_51571728/article/details/120384909
一、简介
Tesseract是一个 由HP实验室开发 由Google维护的开源的光学字符识别(OCR)引擎,可以在 Apache 2.0 许可下获得。它可以直接使用,或者(对于程序员)使用 API 从图像中提取输入,包括手写的或打印的文本。
与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;
训练的大致流程:安装jTessBoxEditor -> 获取样本文件 -> Merge样本文件 –> 生成BOX文件 -> 定义字符配置文件 -> 字符矫正 -> 执行批处理文件 -> 将生成的 traineddata 放 入tessdata 中。
如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
二、下载
以下是关于Tesseract的常用网址
下载地址:https://digi.bib.uni-mannheim.de/tesseract/
官方网站:https://github.com/tesseract-ocr/tesseract
官方文档:https://github.com/tesseract-ocr/tessdoc
语言包地址:https://github.com/tesseract-ocr/tessdata
注意事项:
1.尽量不要下载dev(开发中的版本),alpha(内部测试版,一般不向外部发布,会有很多Bug),beta(公测版本,即针对所有用户公开的测试版本)等版本。
2.建议下载最新稳定版本(最新版本可以直接下语言包,老版本会报错):
| tesseract-ocr-w64-setup-v5.1.0.20220510.exe | 2022-05-10 18:59 | 51M |
2.许可协议
三、安装
1.开始安装
3.选择要安装的用户
4.选择附带要安装的语言包
此后会在安装过程中会自动从服务器下载该语言包。(勾选需要下载的语言包,一般只有中文chi_sim和chi_sim_vert即可)
(最新v5.1版可以直接勾选下载语言包,老版本可能无法勾选下载语言包或者下载失败,本教程后续会介绍如何拓展语言包。)
5.设置安装目的地址,后续设置环境变量Path时需要用到,这里假设为“D:\App\tesseract”。
6.选择要创建程序快捷方式的启动菜单文件夹,一般默认即可
7.完成安装
四、设置环境变量
1.设置环境变量
进入环境变量中,在path中新建tesseract的安装路径使用win+r弹出“运行”命令框,输入sysdm.cpl打开系统属性。
2.在“高级”中打开“环境变量”
3.在“系统变量”中找到“Path",双击进入
4.加入安装过程中设置的地址, 安装目录地址D:\App\tesseract 即为Path值。
5. 配置语言包路径环境变量TESSDATA_PREFIX
在环境变量中,新建环境变量TESSDATA_PREFIX,设置环境变量值为安装目录下的tessdata。
6. 查看环境变量是否设置成功
在cmd打开,执行分别执行 echo %Path%和 echo %TESSDATA_PREFIX%查看是否设置成功。
如果检验,也可以通过一次性设置环境变量 set TESSDATA_PREFIX=D:\App\tesseract再验证。
7. 如果设置不生效可以重启电脑再检查
五、安装检验及语言包拓展
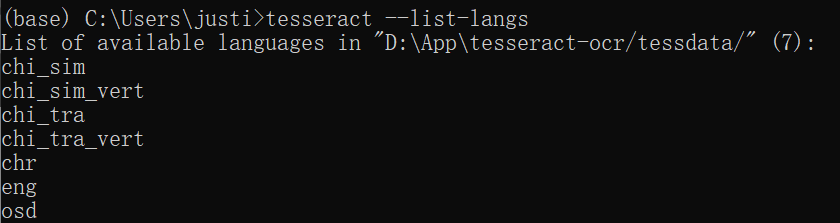
1.查看是否安装成功
打开cmd,输入tesseract -v回车,若显示版本号即为安装成功。
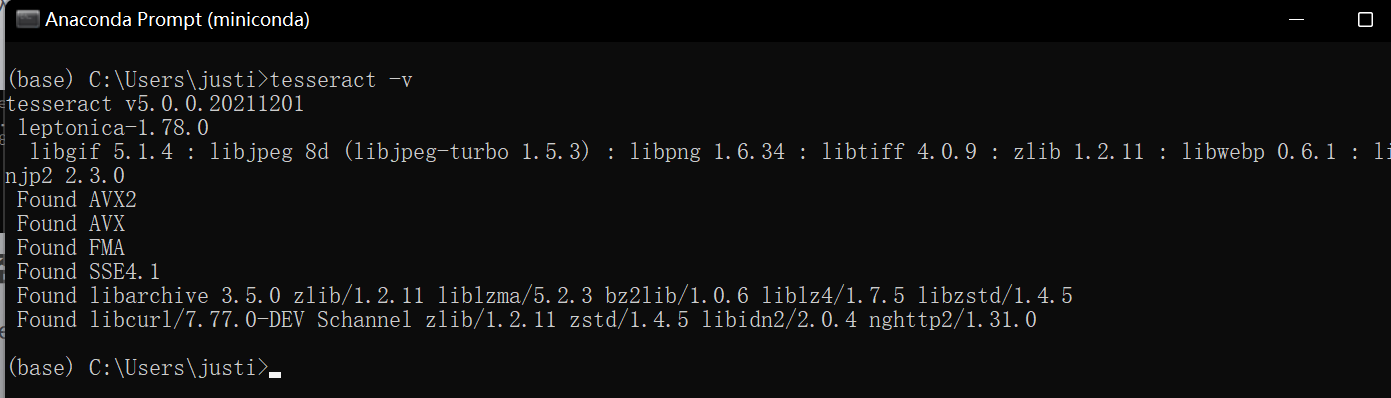
2.查看已经安装的语言
在cmd中输入tesseract --list-langs回车,若显示版本号即为安装成功。

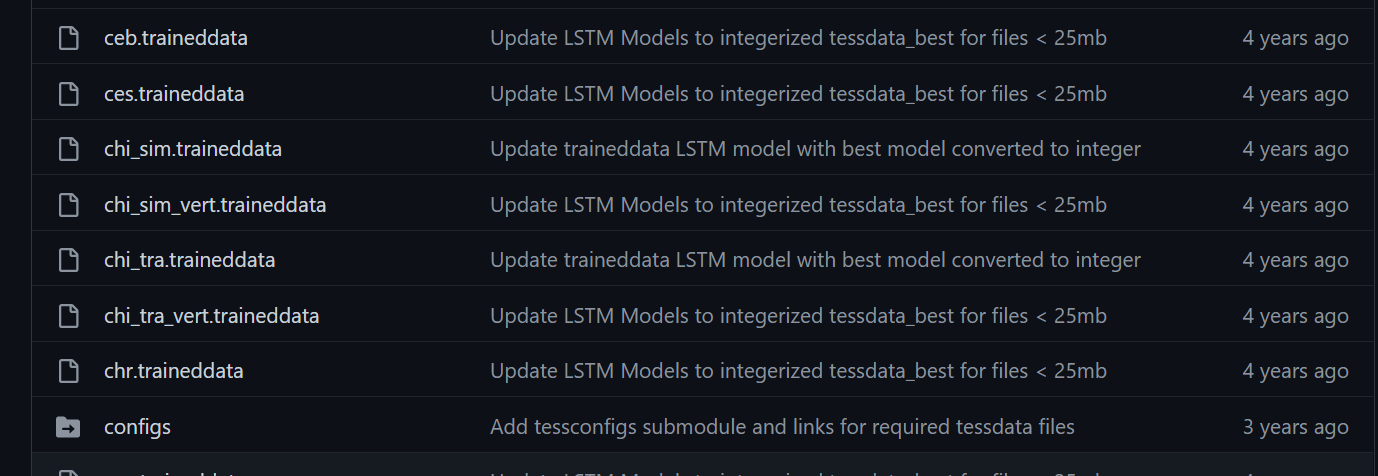
3.拓展语言包
在下载步骤中找到语言包地址的链接,下载所需要的的语言包,如图
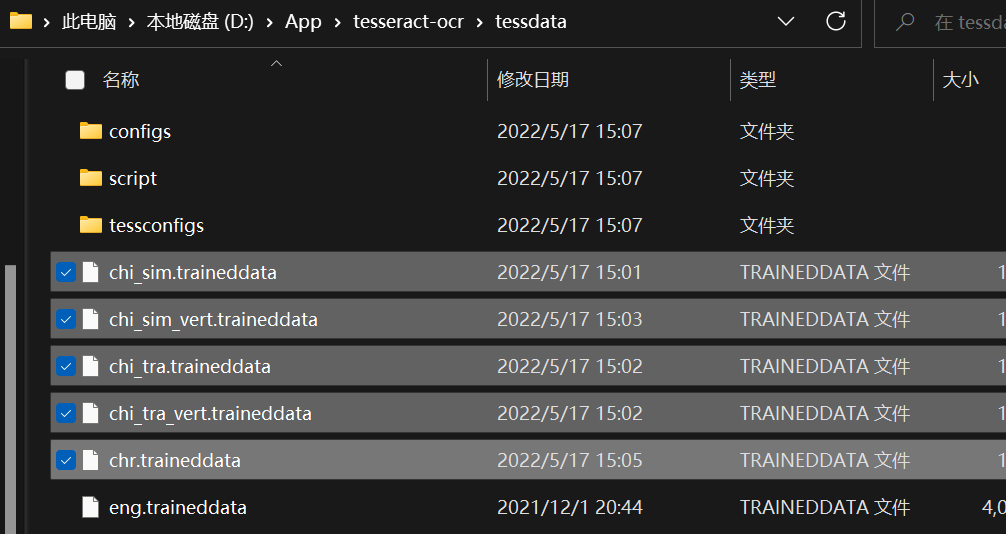
下载后将该包直接放在程序安装目录的tessdata文件夹中里面即可,如图
注意:使用手动下载的语言包在验证时,出现TESSDATA_PREFIX路径设置失败问题,但实际是已经设置;
用安装时自动下载语言包没出现这个问题。
六、Python实例运用
1.测试样图
命令行中直接接口任务, tesseract 图片 存储文本 -l 语言
如:tesseract 4.png result -l chi_sim

2.测试代码
import pytesseract from PIL import Image def demo(): # 打开要识别的图片 image = Image.open("4.png") # 使用pytesseract调用image_to_string方法进行识别,传入要识别的图片,lang='chi_sim'是设置为中文识别, text = pytesseract.image_to_string(image, lang='chi_sim') #输入所识别的文字 print(text) if __name__ == '__main__': demo()
