2022软工K班第二次博客作业
 呼噜呼噜
ik的第二次作业_爬取疫情相关数据并可视化
呼噜呼噜
ik的第二次作业_爬取疫情相关数据并可视化
一、PSP表格
2.1 在开始实现程序之前,在附录提供的PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。(3')
| PSP2.1 | Personal Software Process Stages | 预估耗时(小时) |
|---|---|---|
| Planning | 计划 | 4 |
| · Estimate | · 估计这个任务需要多少时间 | 1 |
| Development | 开发 | 182 |
| · Analysis | · 需求分析 (包括学习新技术) | 72 |
| · Design Spec | · 生成设计文档 | 4 |
| · Design Review | · 设计复审 | 2 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 8 |
| · Design | · 具体设计 | 6 |
| · Coding | · 具体编码 | 48 |
| · Code Review | · 代码复审 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 |
| Reporting | 报告 | 12 |
| · Test Repor | · 测试报告 | 10 |
| · Size Measurement | · 计算工作量 | 1 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 |
| 合计 | 196 |
2.2 在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块上实际花费的时间。(3')
| PSP2.1 | Personal Software Process Stages | 实际耗时(小时) |
|---|---|---|
| Planning | 计划 | 4 |
| · Estimate | · 估计这个任务需要多少时间 | 1 |
| Development | 开发 | 56 |
| · Analysis | · 需求分析 (包括学习新技术) | 10 |
| · Design Spec | · 生成设计文档 | 1 |
| · Design Review | · 设计复审 | 1 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 |
| · Design | · 具体设计 | 4 |
| · Coding | · 具体编码 | 20 |
| · Code Review | · 代码复审 | 6 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 10 |
| Reporting | 报告 | 7 |
| · Test Repor | · 测试报告 | 2 |
| · Size Measurement | · 计算工作量 | 1 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 2 |
| 合计 | 63 |
二、任务要求的实现
3.1 项目设计与技术栈。从阅读完题目到完成作业,这一次的任务被你拆分成了几个环节?你分别通过什么渠道、使用什么方式方法完成了各个环节?列出你完成本次任务所使用的技术栈。(5')
我拆成了三个部分:爬取页面、处理数据、绘制图表。
爬取页面方面,上bilibili看网课学习爬虫的基本知识,懂得基本的库、函数如何运用于项目的实现。然后开始动手实践,在实际运用中找到bug后查找资料消除bug。
处理数据方面,也是通过看网课的方式了解了基本的库和函数的运用,了解了python切割数据的三个工具:正则表达式、BeautyfuleSoup和Xpath。由于爬取网站数据并非完全的规范,最终选择了最基本的正则表达式来完成爬取到的文本的切割。
绘制图表方面,绘制表格就查找资料,学习到相关操作后再进行动手尝试;绘制柱状图和地图方面,由于大一的寒假有接触过echarts,并且运用它来实现了作业的b站up主粉丝可视化,通过这次软工作业我再去了解到了pyecharts这个更轻量级的工具,方便进行可视化的操作,因此对于柱状图和地图的制作我都运用了pyecharts来完成。
上网查了查技术栈的定义,感觉完成本次任务所使用的技术栈只有python和html。
3.2 爬虫与数据处理。说明业务逻辑,简述代码的设计过程(例如可介绍有几个类,几个函数,他们之间的关系),并对关键的函数或算法进行说明。(20')
分析任务,将任务分成三个部分:爬取页面、处理数据、绘制图表。
总共有五个“大”函数,他们之间的联系是:combine函数将一级页面(疫情通报的总页面)的各页(下方点击页码可跳转的页面)进行判断并传输给parse_html函数,parse_html函数将各个二级页面的网址传输给for_each函数进行爬取,爬取之后的文件传输给get_pic函数进行数据处理、图标绘制。
以下是详细说明:
-
combine(home_url, page_int):通过修改参数 '_?' 获得一级页面各页的网址并传递.
- 通过分析一级页面各页的url得知,都满足'http://www.nhc.gov.cn/xcs/yqtb/list_gzbd{}.shtml' 的格式,{ }内为‘_X’(X为数字)。照此规律进行一级页面各页url的传输。
-
parse_html(home_url):输入主页面url,调用请求函数,获取一级页面内的标签带有的二级页面网址。
- 通过分析页面得知,二级页面的网址存放在'.list > ul > li > a'标签中,因此运用BeautyfuleSoup中的select函数将其定位后提取出来进行处理。
- 分析网址得知,在该地址[10]~[13]的字符为该页面疫情情况所对应的年份。用一个循环将其提取出来存放到全局变量yearNumber中,用于之后对年份的判断。
- 将各个二级页面的网址传输给for_each(url)函数进行处理。
-
for_each(url):输入url进行网页的爬取,将页面text格式文件传给get_pic进行地图绘制。
# 最基本的requests爬虫样式 response = requests.get(url=url, headers=headers) page_text = response.text get_pic(page_text) -
get_pic(page_text):输入需要处理的html文本,处理数据、获得相应所需的文本、表格、柱状图、地图展示的函数。
- 主要运用正则表达式对数据进行切割。先通过观察句子特征,对所需句子进行切割。例如对本土病例的切割时:
pattern = re.compile('本土病例.+?),含') # 利用正则表达式将新增本土病例的所需部分提取出来。 result = pattern.findall(p) if not result: pattern = re.compile('本土病例.+?),含') # 利用正则表达式对特殊情况进行处理。 result = pattern.findall(p) if not result: pattern = re.compile('本土病例.+?);无') # 利用正则表达式对特殊情况进行处理。 result = pattern.findall(p) # );无 if not result: pattern = re.compile('本土病例.+?)。无新') # 利用正则表达式对特殊情况进行处理。 result = pattern.findall(p) # );无 if not result: pattern = re.compile('本土病例.+?);') # 利用正则表达式对特殊情况进行处理。 result = pattern.findall(p)- 再运用‘省份+(?!市)(?!区).+?例’的正则表达式,将数据剥离出来后,再以int的形式进行存储。
local = [] for i in province: pattern = re.compile(i + '(?!市)(?!区).+?例') # 用省份并排除市、区来进行正则匹配。 result = pattern.findall(a) temp = re.findall("\d+\.?\d*", str(result)) # 将字符串中的数字进行提取。 local.append(temp) localSee = [] # 用于绘制新增本土病例表格、柱状图、地图的list。 for i in local: x = ' '.join(list(filter(str.isdigit, str(i)))) # 抽取字符串中的数字(以字符串形式进行存储)。 x = ''.join(x.split()) localSee.append(x)- 之后根据作图所需的格式,对列表中的数据进行diy,进行Excel、柱状图、地图的制作。
还有三个“小”函数:
- get_html1(home_url):得到html格式页面的函数,并将html返回(用于parse_html)。
- def create_china_map():用于地图的绘制。
- def get_all_data_excel(name, type_list, in_a_word_list):用于各个汇总表格的绘制。
3.3 数据统计接口部分的性能改进。记录在数据统计接口的性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(例如可通过VS 2019/JProfiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(6')
运用自带的cProfile的函数来对性能进行分析。以test_module.func()为示例函数的原理如下。
import cProfile
import test_module
cProfile.run('test_module.func()')
可得如下的结果输出。
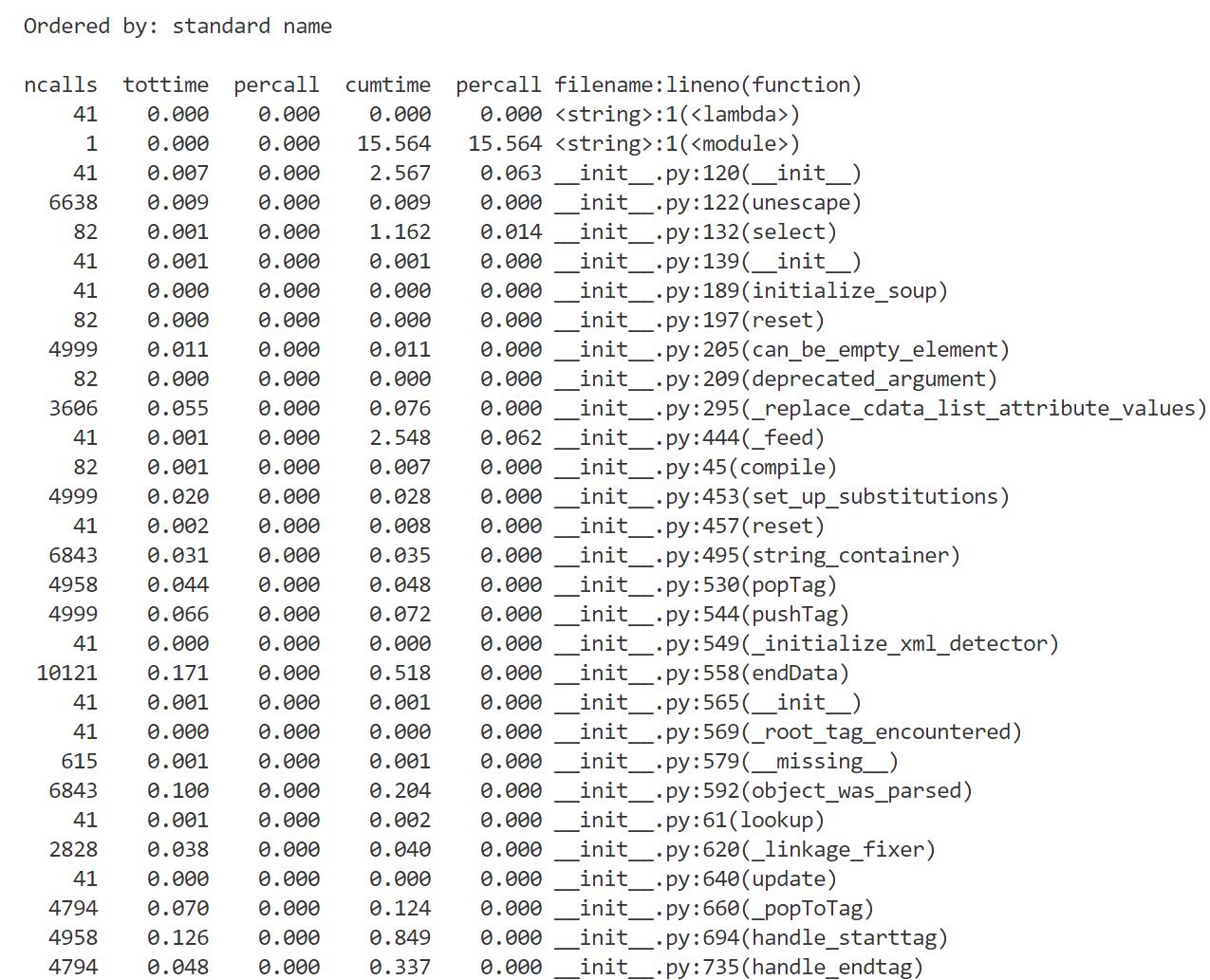
通过查找资料,认识到其中各个参数分别表示:ncalls:调用次数;tottime:在给定函数中花费的总时间(不包括调用子函数的时间);percalltottime:除以ncalls的商;cumtime:是在这个函数和所有子函数中花费的累积时间(从调用到退出);percall:是cumtime除以原始调用次数的商;filename:lineno(function):提供每个函数的各自信息。
通过分别对比分析得出,三个“大”函数(除了combine之外的“大”函数)的消耗从大到小排序:for_each > get_pic > parse_html。
3.4 每日热点的实现思路。简要介绍实现该功能的算法原理,可给出必要的步骤流程图、数学公式推导和核心代码实现,并简要谈谈所采用算法的优缺点与可能的改进方案。(6')
对于单独的一个省份进行检测,当疫情相关人数超过100时,flag持续自增1,如果大于等于6天则标记为热点,小于100例之后flag转为0,将省份、日期以及持续天数write到文本中。
再通过对记录的的数据分析发现,2022年,上海新增本土病例严重后过后两个月后的暑假,海南便开始本土病例的增加。找到相关数据进行绘制折线图如下。
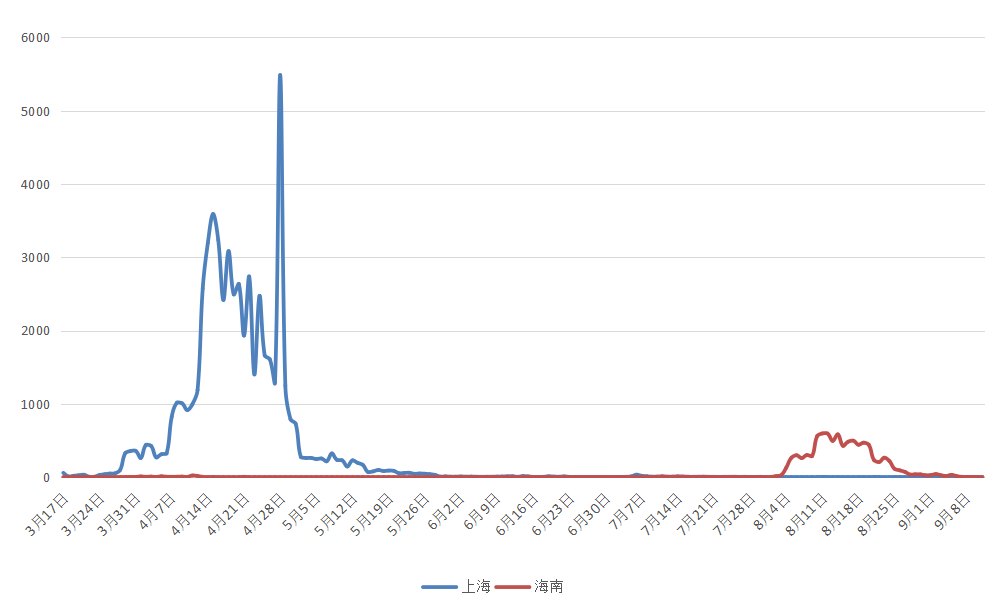
因此查找相关信息,果真查到了相关的新闻。

3.5 数据可视化界面的展示。在博客中介绍数据可视化界面的组件和设计的思路。(15')
① 文本与表格
在程序内会在当前目录创建如下四个文件夹,并且根据爬取到的数据进行绘表制图,将文件都存入四个对应的文件夹。
文本部分,即为各个二级页面的文本内容;表格部分,分为分表格和总表格部分。分表格即为每一天情况的表格,总表格则为它们根据省份进行的汇总。
以新增本土病例为例,制作成的总表格如下。
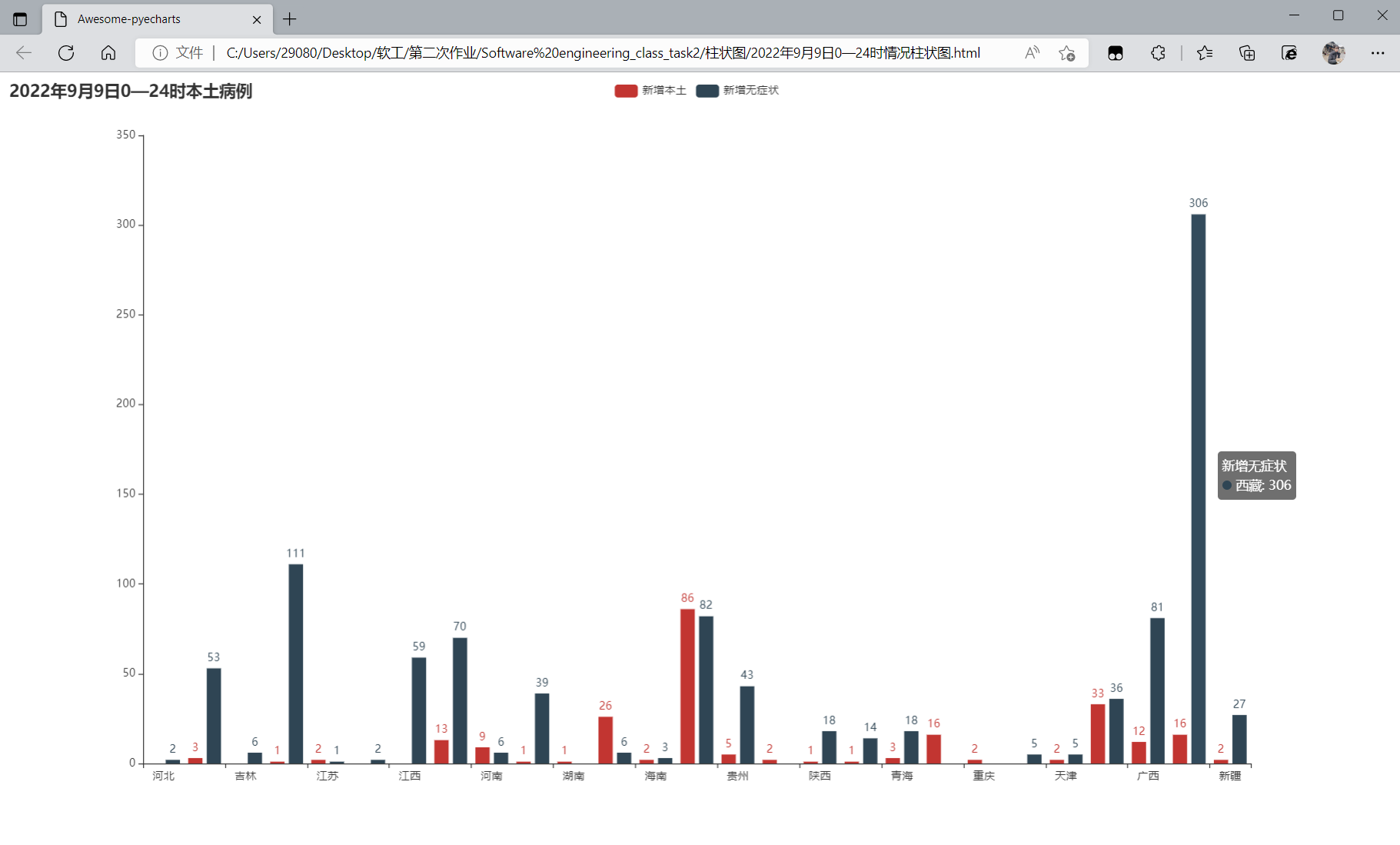
② 柱状图与地图表示
生成的柱状图如图所示,记录了当日有新增本土病例或新增无症状感染者的情况。
生成的地图展示如图所示,同样记录了当日有新增本土病例或新增无症状感染者的情况。
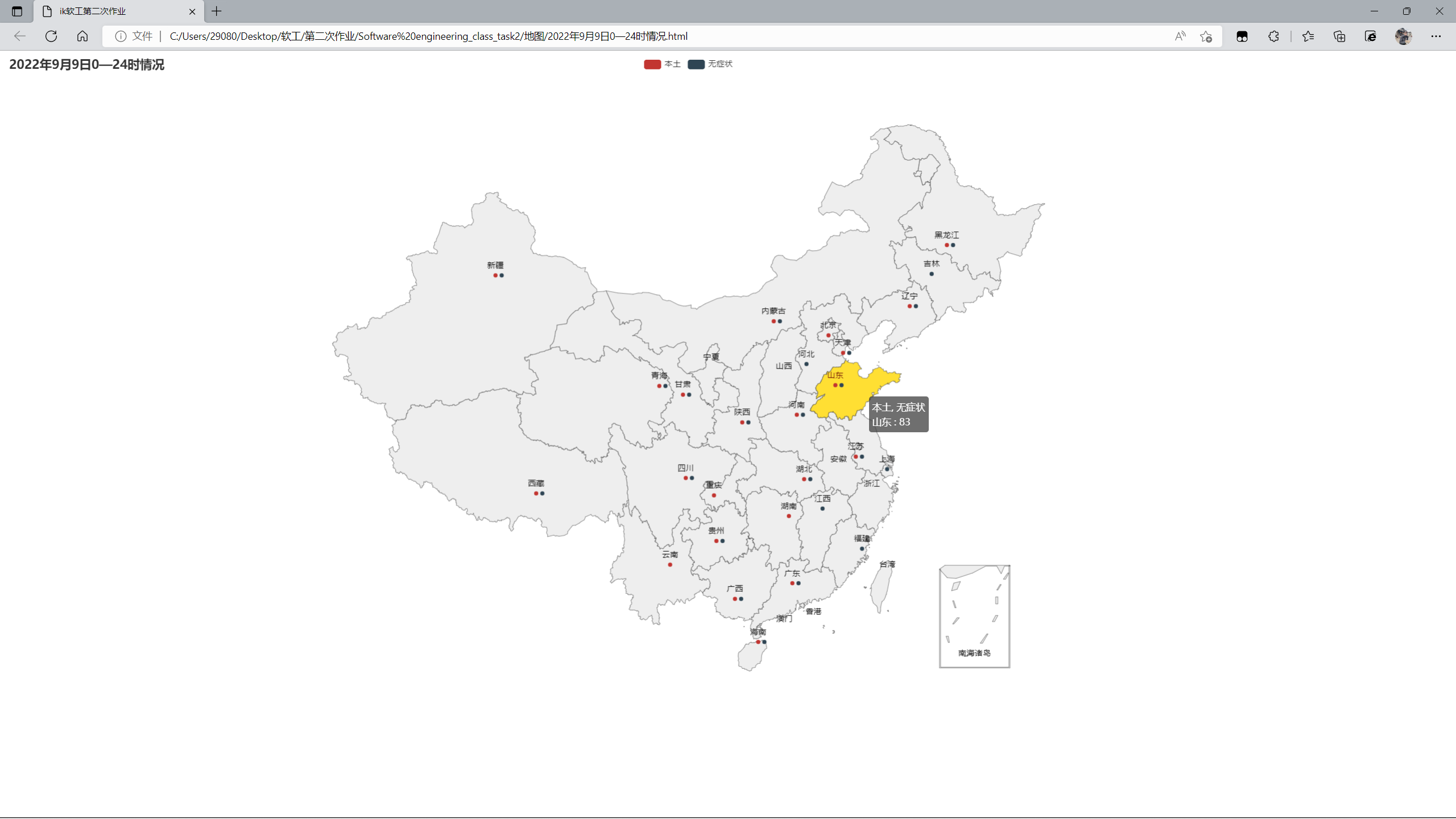
悬停可查看对应人数,默认为本土+无症状人数。可以点击上方的红色和墨绿色色块来选择看新增本土病例或者新增无症状感染者人数。
三、心得体会
4.1 在这儿写下你完成本次作业的心得体会,当然,如果你还有想表达的东西但在上面两个板块没有体现,也可以写在这儿~(10')
跌跌撞撞终于是完成了这项作业,卫健委的反爬、文本格式的不一致都带来了大大小小的问题。所幸的是我的UA、Referer和Cookie很是具有伪装性,仅需较为简单的伪装就能绕过反爬。我的舍友的UA和Cookie就受到了重重阻拦,最终反反爬也是让他心力憔悴。我较为幸运的同时却也差了一点点的技术锻炼。
这次的作业还是有所缺憾的:
- 因为一开始并没有过多进行整体的规划,导致后面写什么函数都是临时起意,把所有的函数和步骤都堆积到一个文件里面,并没有分开来实现不同的功能。虽然也能跑,但是如果一个环节不稳定,其他环节也是会受影响;
- 可视化方面一开始没有朝着动态大屏进行努力,直接绘制柱状图、地图对数据的处理让其数据错综复杂,从而很难带进绘制动态大屏所需的参数格式,积重难返之下时间也来到了周四,周四到周日要进行一个比赛的相关工作,因此也就把动态大屏搁置了,有点可惜。
- 深度学习并不成功,对于需求并未提炼出理想的特征值判定,从而没有样本来完成机器学习。并且对于这方面的研究并不深刻,导致代码编写无法顺利进行。今后需要多多研读这方面的书籍,了解一下各个算法的运用环境以及原理,从而更好地掌握这方面的知识。
最大的感触就是,一开始并未作一个总体的规划,导致到之后出现走一步看一步的情况,使得一个文件鱼龙混杂,并没有按照文件进行步骤的拆分。这点也让我吸取教训,在今后的编程活动中要先制定一个总体规划再进行代码的编写,所有的临时起意都可能会为之后埋下伏笔。
聊了这么多悲伤的,欣喜肯定也是有的:解决了刚开始爬取数据频频报错412,看着运行框中的不断输出的快乐;真真正正从基础课开始听懂爬虫的收获的喜悦;以及和舍友们哀嚎但仍旧继续打代码的莫名乐趣……
就这样奇奇妙妙地,第二次作业结束了。带着一点刚学会的新知,走向下一段旅途。
以上就是ik的第一次作业🌙

 浙公网安备 33010602011771号
浙公网安备 33010602011771号