第一次个人作业总结
第一次写要求稍微精细、代码量稍高的程序,过程比较痛苦,这是相对于我们平时贫瘠的编码经验而言,我相信这个需求和代码量对于实际工业级工程来说简直九牛一毛。
受限于各种因素,开始的时候较晚,实际上27日才有实质性的进展,后期处理较为匆忙。
以下是对此次作业的概述。
一、需求分析和结构设计
需求分析
1、基本功能:统计字符、单词、行数量,单词频率。
拓展功能:统计词组频率 。
(注:单词判定存在格式要求)
2、输入为文件名/文件夹名,输出为文本文件result.txt。
格式:
characters: number
words: number
lines: number
"word": number(word按照字典【ASCII】排列、且为文件中真实单词格式)
3、可处理多个文件。
4、可以判断并遍历文件夹。
程序结构
语言使用C/C++,但由于面向对象方法不甚熟悉,且本次作业使用面向过程更容易思考,仍采用面向过程的编程思想。
单词和词组频率统计采用STL中的map容器,之所以为何不用大数据量下查找效率更好的unordered_map容器,是因为map中元素默认按照关键字升序排列的特性,在词频和词组统计中非常有用。
过程:
1、输入文件名->根据文件名确定文件、判断文件类型。
若为文件夹,判断是否为空,若为空,输出错误信息;若非空,递归遍历文件夹。
遍历文件夹时,对源文件进行2中的统计,跳过非源文件。
若为文件,判断是否为源文件,若是,则执行2;若否,输出错误信息。
2、统计对应文件中的字符、单词、行数和单词频率
3、在文件中输出统计结果(*字典排序)
(统计结果存储于结构体result中)
结构如下(这是实际编码后修改过的结构):
//result structure type //存放结果的结构体 typedef struct{ //基础统计结果 int charaNum; int wordNum; int lineNum; //词频统计所需的两个map容器 map<string,int> dict; map<string,int> transdict; //词组统计所需的两个map容器 map<string,int> phrase; map<string,int> transphrase; } //declarations //读取单个文件,调用具体统计函数 void fileRead(string p, fileProp *result); //文件夹的遍历 void folderTraverse(string p, fileProp *result); void DFS(string p, fileProp *result); //各种判断(是否为有效文件/有效目录/符合要求的单词) bool isSourceFile(string p); bool isValidDir(string p); bool isWord(char *ch); //具体统计函数 long charaStat(string p); long lineStat(string p); long wordStat(string p, fileProp *result); void phraseStat(string p,fileProp *result); map<string,int> mapProc(map<string,int> dict,map<string,int> transdict); //结果输出 void resultPrint(fileProp *result);
二、PSP表格
| PSP2.1 | 任务内容 | 计划完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Estimate | 估算 | 20 | 20 |
| Analysis | 需求分析 | 20 | 20 |
| Design Spec | 设计文档 | 30 | 40 |
| Design Spec | 设计文档 | - | - |
| Coding Standard | 代码规范 | 10 | 10 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 300 | 480 |
| Code Review | 代码复审 | - | - |
| Test | 测试 | 120 | 300 |
| Record Time Spent | 记录用时 | - | - |
| Test Report | 测试报告 | 120 | 120 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem | 总结改进 | 180 | 180 |
| Summary | 合计 | 880 | 1250 |
三、部分程序实现描述
1、判断是否为单词和判断单词是否为同一个
定义除字母和数字之外的字符为“分隔符”,使用infile.get(c)+while循环,每次循环读入一个字符,并将字符置入字符数组,遇到分隔符停止。
根据题目要求逐字符判断字符数组是否符合要求即可。
判断单词是否相同,使用两个字符数组,分段比较:
1、对于字母部分,每个字符位分别比较两个字符数组成员的大小写形式,如wordA[0]和wordB[0],两者的大小写形式比较ASCII码,共有四种情况(aa,aA,AA,Aa),只要有一种情况下两者相符,即相同。
2、比较第一个非字母至字符数组尾部的字符,若两者在这个部分都只有数字,则是同一个单词,若出现字母且不同,则不是同一个单词。
3、以上两部分分别返回bool型,做与运算(&&)即可。
2、连续文本中词组的统计
采用infile.get(c)+两个字符数组的方式统计连续的文本中词组的频率。我将用图片辅助说明具体方法。
字符数组名为setA和setB,循环的开始,读入两个“字符段”,此处的字符段并不一定是单词,而是只要遇到分隔符即停止,置入数组中。

判断setA和setB是不是单词,返回两个bool型,仅当两个bool型均为true时,将setA和setB组合后存入map容器。
此后不论刚才的bool型结果如何,均向后读一个单词,并且置入位置靠近文件头的那一个数组,在此处表现为setA移动到了“of”处。

重复以上的判断过程,注意,此次判断结束后,要再次向后读一个单词,将靠近文件头的数组移向后方。
如图,这次操作后,两个数组的相对位置回复到了循环开始时的状态。循环体的结尾必须回到这个状态,才能进行下一次循环。
这个方案优点是非常简单直观,缺点是循环体内容非常多,而且整个方案时间复杂度在O(n²)左右,效率很低。
3、如何解决按照字典输出的问题
作业要求中要求按照频率输出前十的单词和词组,且每个单词输出其在字典(ASCII)中排在前面的形式。
按照频率排序非常简单,使用vector存储map中的二元对,再利用sort排序,最终输出vector中的二元对即可。
但是怎样保证这个单词是字典优先的形式呢?
这是个麻烦,我能想到的方案是统计时即比较读取的单词和已经存在的单词的形式和在字典中的优先度,如果是同一个单词且优先度高,则替换已存储的单词为新读取的单词。但是这个方案在读取的同时进行比较,操作有些复杂,对于我来说,使用这样的方案很可能逻辑上漏洞百出。
于是我将读取和比较分离,考虑了一种新的方案。同样以图片辅助说明。
使用两个map容器,dict和transdict。
每次读取一个单词,将其原型存入dict,然后将该单词的非字母部分去掉,再使用algorithm头文件中的transform将单词转换为全小写或全大写(此后简称为phrTransform操作,可以专门写一个phrTransform函数),存入transdict。
我们知道,map容器中默认按照关键字升序排列,假如某个文件中只有200个不同形式的“THAT"单词,那么读取结束后,两个map容器的元素应该是这样子的:

然后我们进行比较,定义map作为返回值的函数:
map<string,int> mapProc( map<string,int> dict , map<string,int> transdict )
其作用如下:
1、逐个比较,每次读取dict中的一个单词,比如“THat”,进行phrTransform操作得到关键字“that”,在transdict中查询这个关键字(一定可以查到),得到对应的value(也就是单词出现次数),然后将dict中该单词对应的value修改为transdict中对应的频率。也就是说,循环结束后,在dict中,定义上相同而原型不同的所有"THAT",会具有相同的value,且这个value为定义上这个单词在文件中的出现次数。如图:
2、去重。经过上操作后的dict是不能用于直接输出结果的,这样直接输出,在用sort排序后,会优先输出具有同样value的所有"THAT"(输出所有形式的同一个单词,具有相同的出现次数)。
因此我们要去掉不需要输出的“THAT"。这就是我为什么要用map而不是unordered_map的原因,map中,默认关键字是按照升序排列的,因此dict中出现的第一个"THAT"就是我们想要输出的”THAT"的形式,去重的时候不需要再考虑保留哪一个,直接保留第一个就可以。
利用erase函数循环删除具有同样value值的二元组即可,这里每次循环开头需要保存迭代器的当前位置,删除后退回,最后留下来的就是我们需要的dict,可以排列后直接输出。如图:
mapProc代码如下,phrTransform仅涉及字符串操作,此处就不贴出来。
map<string, int> mapProc(map<string, int> transdict, map<string, int> dict) { string tmp; int cmp; int wordFreq; map<string, int>::iterator it; map<string, int>::iterator tmpit; for (it = dict.begin(); it != dict.end(); it++) { tmp = it->first; phrTransform(tmp); wordFreq = transdict.find(tmp)->second; it->second = wordFreq; } //compare for (it = dict.begin(); it != dict.end(); it++) { tmpit = it; cmp = it->second; it++; for (it; it != ict.end(); it++) { if ((it->second) == cmp) dict.erase(it); } it = tmpit; } //delete return dict;
对于词组频率的统计同样可以采用这个方案。
这个方案的优点同样是直观、便于理解,缺点是对于需要申请辅助map,这会占用相当多的内存。我认为这个方案是可行的,但内存管理不当似乎会使程序在操作大的文件过程中抛出std::bad_alloc异常。
四、测试结果与问题
严格实现词组的统计后,可以对较小的文件夹和文件进行统计和输出,但对于测试样例newsample,在map的使用过程中,会抛出std::bad_alloc的异常,异常位置指向map或者vector的系统文件,并且程序停止运行,由于对STL了解不足,网络也搜索不到相关信息,这个问题到最后也没有解决。因此,为了使我提交的代码能够正常运行,我将将有关词组统计的代码全部用注释掉了。
此处也仅仅放出对newsample的字符、单词、行数和单词频率的统计状况。
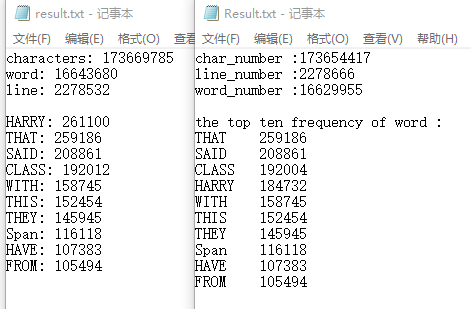
前三行的统计数量略有不同,行数和单词的差异我认为可以接受,字符差异则略大。
除了HARRY莫名跳到26w,以及CLASS多出8个以外,可以看到其他的词频统计都是正常的。
五、程序性能分析
由于直到DDL前不久还在进行代码的修改,而且还没能修改到正常的地步。因此具体性能分析是代码提交以后所完成的了,对优化已经没有什么意义,但是借这个机会,学习利用VS进行简单的性能分析也不错。
Release模式下,对样例newsample进行测试,需要3分左右的时间,debug模式下运行时间以十倍基数增长,在15分钟左右。对比其他同学的时间,可以说性能比较低。
使用性能探查器看一下是否有优化的空间。
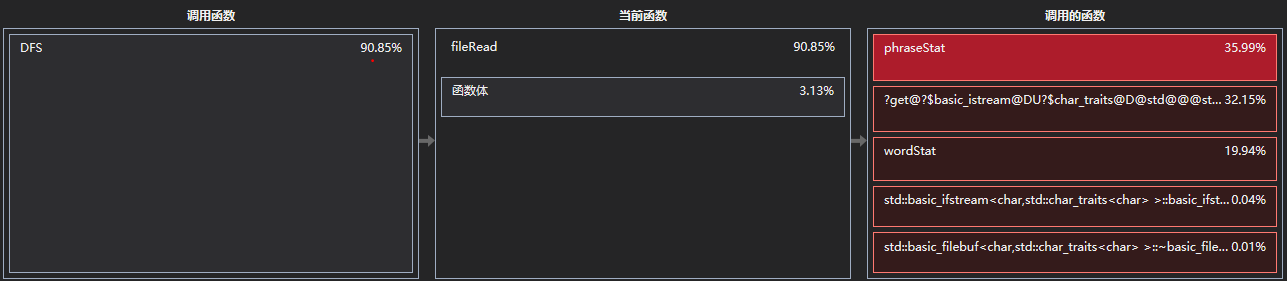
打开函数详细信息页面,依次打开占用时间最多的函数,到DFS遍历文件夹一层。可以看到主要占用CPU时间的是fileRead函数(功能是统计一个文件的所有参数),现在再看也许把读文件和统计放到递归遍历文件夹中是一个非常不明智的决定。
打开fileRead,发现耗时最多的则是phraseStat(词组统计)、basic_istream::get和wordStat三个函数。
basic_istream::get函数占用32.15%是可以理解的。除了读取文件内容和统计中的get操作以外,我所有的函数传入的参数都是文件名而不是文件指针,每进行一次统计,都要析取文件名的字符串并打开文件。
phraseStat和wordStat占用非独占时间相差了16%,这说明我的词组统计方案效率实在非常低(将词组统计功能屏蔽后测试时间降到了一分钟),这一点在说明统计方案的时候也有说明。
因此目前想到的可用的优化点和方案如下:
1、遍历文件夹方面:读取文件名存储至某一文件或指针数组,再另行统一统计,应该会使性能有所提高。
2、函数参数方面:将传入参数改为文件指针,可以减少析取文件名的次数。
3、设计更好的统计算法。
六、总结反思、经验与目标
总结与反思
这次编程过程对于我来说是比较辛苦的,而且结果也不算好。可以看出我编程经验太过缺乏,而且平时编程仅限于学校课程作业,许多实际开发中常用的技能和知识都没有了解。但是了解了自己这些缺陷,我也就知道了自己应该改进的方向,希望在之后的编程任务中能够表现的更好,弥补这次发挥不佳的损失。
经验
经验是指在编程方面获得的经验(大多是失败的惨痛教训TAT),这些经验可以活用于以后的工作当中。
1、在实际开发过程中,需求分析和技术选型之后,如果发现在工作中需要遇到自己非常生疏的知识,应该先花专门的时间去了解相关代码操作和注意事项。
不能像初学一门技术一样,用实战来学习,这就和医生拿着医学书籍做手术没什么两样。
实际上我这次作业中就这样做了,一开始的目的是节省时间,但是开始编程却陷入了无所适从的状态,每个模块都有没有掌握的知识,不知道从哪开始。而且在使用这些技术的时候往往错漏百出,特别是某些技术需要内存管理,如果没有事先了解过,很容易编出“屯屯屯屯屯,烫烫烫烫烫”的程序。
最糟的是,因为胡乱用不熟悉的东西,有可能会出现非常罕见,不知道如何定位,也不知道如何处理的异常(比如:异常发生后进程自动退出,VS报错报在了某个你没有接触过的系统文件里面,异常发生的内存代号在调试映射文件(map文件)里不存在,知乎、CSDN、stackoverflow上也找不到有效的解决方案和错误原因)。这在接近DDL时几乎是毁灭性的打击。
2、如果不是再熟悉不过的算法,就不要一拍脑袋就开始写。即使想到了一个感觉非常巧妙的算法,一定要事先思考其可行性,思考每一个细节实现是否困难,修改起来是否困难,等等。
而且思路清晰再开始写代码,阻力会小很多,不会因为纠结细节浪费时间。
把一大段代码推倒重写很浪费时间,作出这个决定之前的心理斗争更浪费时间。
3、不要写紧耦合的程序!!!!!
紧耦合可能可以实现某些便利或者巧妙的功能,但是如果不是必要的话,还是写便于维护的代码吧!对于我目前的水平,绝大多数情况下,紧耦合会导致维护和修改时灾难性的连环Bug。
比如这次试图用同学提出的ifdef的方式来做平台移植,在我的代码耦合度较高的情况下,ifdef会导致大量的未定义标识符、声明和具体实现不一致等错误,更尴尬的是,某些错误的解决方式还互相冲突,产生新的BUG,这种情况逼着我修改了大量的代码。
4、不要一味追求巧妙、快捷、一蹴而就,最基础最麻烦的代码换来的往往是最正确的答案。一切优化,都在程序能够正常跑出结果后进行。
目标
这次作业的过程让我知道了工程中哪些技术非常实用,接下来将优先学习:
C++和STL(这次使用了map,vector,algorithm,utility,但是实际上对它们没什么实质上的了解)
C++中文件和文件夹的操作
linux编程和维护(linux系统)
面向对象思想

 浙公网安备 33010602011771号
浙公网安备 33010602011771号