移动机器人相机模型:从相机移动到二维图像
如果只是希望获取图像上的一些信息(例如特征提取、拟合等),那么我们不会对三维空间中相机的位置有所要求。但如果希望通过二维的图像去理解三维空间中摄像机的信息,或者是图像中物体在三维空间中的信息,那么就不得不考虑成像过程中三维变化为二维时的具体过程。而摄像机模型就是三维到二维的一种映射。本文简要总结了单目相机的成像过程,以便于读者将相机模型作为一种基础的工具理解更深层次的内容。
本文通过讲解三维世界坐标系下某一点是如何被映射到二维图像上的一点的完整流程来讲解,以下为整体流程:
(世界坐标系——相机坐标系——成像平面坐标系——图像坐标系)
下面对这四个坐标系作出一个简要的介绍:
- 世界坐标系
P_w:通常是三维空间中人为选择的一个参考坐标系。单位为物理单位,例如m。 - 相机坐标系
P_c:三维空间中,通常以摄像机的光心作为原点,光轴作为z轴的一个坐标系。可以通过世界坐标系的平移和旋转来获得。单位为物理单位,例如m。 - 成像平面坐标系
P:通过相机模型映射得到的一个二维坐标系。单位为物理单位,例如m。 - 图像坐标系
P_uv:通过所成像转换获得的在计算机内部可以存储的矩阵图像上的坐标系。单位为像素。
1. World -> Camera
假如摄像头固定不动,那么世界坐标系和相机坐标系可以直接重合。但如果我们要把摄像头放在一个能够移动的机器人身上,那么就有必要令一个固定的坐标系和一个跟着机器人走的相机坐标系。
如果上述这句话你不太理解,那就说明你确实有必要阅读这篇文章,等到阅读结束后再回过头来思考这个问题。而现在,你只需要知道,我们在这里考虑的是后面这种情况,即摄像头置于移动机器人上。
作为一个移动机器人,它必然有所处位置坐标和一个朝向,我们把机器人的位置和朝向称为位姿。如果它还没开始运动,我们不妨将该位置作为世界坐标系原点,而相机朝向作为Z轴:
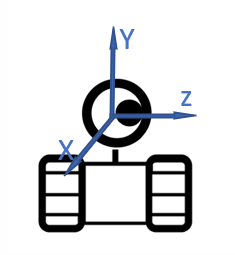
机器人在空间中会进行移动和转向,于是我们可以按照同样方式定义一个跟随着机器人进行移动的坐标系,称为相机坐标系。
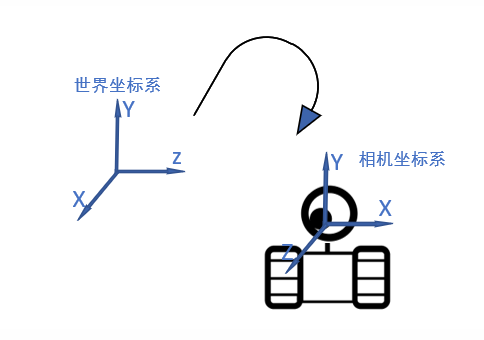
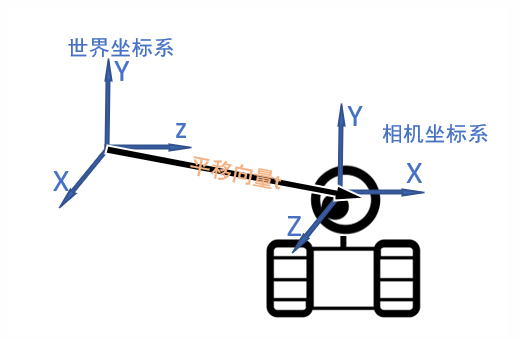
为了表示出这种移动和转向,我们需要知道机器人相对于原来位置移动了多少,旋转了多少。
很自然的,我们可以通过当前机器人在世界坐标系下的坐标,来表示机器人是如何从世界坐标系原点移动到当前位置。于是把该坐标,称为平移向量:
而对于旋转,通常使用旋转矩阵R进行描述。对于如何理解旋转矩阵,我这里推荐看台大的机器人学视频P4(通过列空间变换和投影的方式去理解)。我这里直接使用单位正交基的方式进行描述,意思是一致的。总之,下式表示是在A看来B坐标系的姿态,或者可以把在B坐标系下的坐标表示通过左乘下列R转换成A坐标系下的坐标表示。
也就是说,旋转矩阵R除了表示在A看来B坐标系的姿态,也可以用来转换空间中某一点的坐标表示(而这正是我们的相机模型最需要的)。即有:
此外在机器人学中比较重要的一点是,R能够用来描述物体的旋转。例如下式就表示的是在A坐标系下点1通过一个R旋转至点2。
回到我们的机器人上来。假定现在机器人在世界坐标系初始位置时看到了一点 P_W,然后经过一次旋转和平移,此时看到了同一个点,坐标为 P_C。通过上面的定义,我们能够很自然的得到一个等式:
我们通常把这里的 R和 t称为相机的外参。
为了矩阵运算上的便利,上式同时也可以表现成下面这样(注意使用的是齐次坐标的形式):
常将中间由R和t组成的矩阵写作变换矩阵T,于是可以表示成下列形式:
此式子即为世界坐标系转换为相机坐标系的变换式。它揭示了两个很简单的道理:1. 知道 R_cw和 t_cw,那就能够将点在两个坐标系下进行转换。2. 如果知道多个点在两个坐标系下的坐标表示,那就可以求解获得 R_cw和 t_cw。
2. Camera -> Retinal
好了,现在我们已经能够知道如何把世界坐标系下的点转换成相机坐标系下的点了,现在我们要考虑的是三位空间下的点是如何转换到二维平面上。此刻我们考虑的几何模型才是真正的相机模型。
相机模型通常会考虑两种:针孔模型和透镜模型。
一般来说,考虑针孔模型就够了,因为透镜模型不过是将针孔模型的焦距f进行修改。
首先先考虑针孔模型(图源):
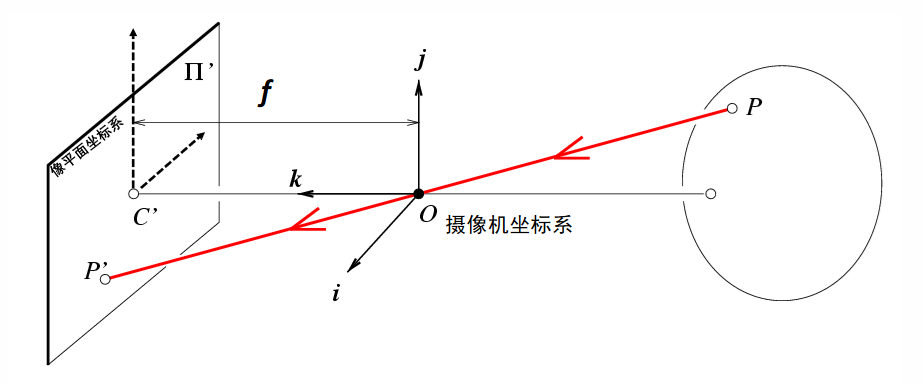
如上图所示,针孔模型可以简单看作,位于三维空间中的某一点P经过相机坐标系的中心点O映射至像平面坐标系上的P'的一个过程。于是乎,我们可以把这一模型视作一个相似三角形模型:
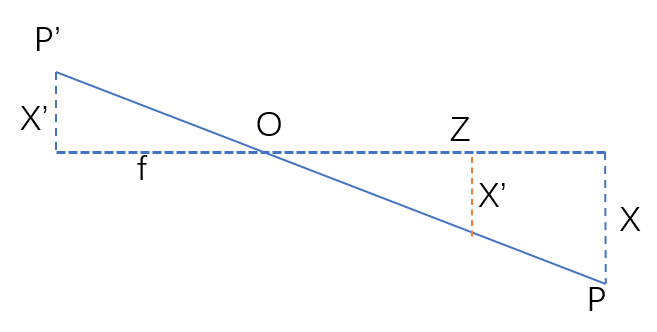
很容易看出来左边X成像是倒的,对于坐标系来说这样的倒会引入负号,因此我们在O点右侧也画一个X‘,这样就能消除这个负号。而对于引入的橙色X’所在平面,我们称为归一化成像平面。于是成像过程就有如下式子:
3. Retinal -> Pixel
由上面的推导,我们很清楚,它们都是在物理层面进行转换的,因此单位都是m。而真正拿到我们手中的是一张张由像素点构成的矩阵图像。因此在成像平面坐标系到图像坐标系还需要进行采样和量化。而同时我们也清楚,图像坐标的原点通常在图像左上角,x轴朝向图像右边,y轴竖直向下。而成像平面坐标系的原点则是在像的中间。因此要把成像平面坐标系转换至像素坐标系,需要进行一次缩放和原点平移。
因此,成像平面坐标系的坐标P’到像素坐标[u,v]有如下关系:
至此,我们已经完成了每一个局部过程的推导。但是,我们不可能每次都这样一次一次进行部分运算,如果我们希望直接把相机坐标系下的点转换到像素坐标系下,该怎么转换?又或者,我们希望从世界坐标系下的点开始转换呢?下面就会对这样的过程进行讲解。
Camera -> Pixel
在上面,我们已经获得了 Camera -> Retinal和 Retinal -> Pixel的式子,因此可以将 X',Y'消去(即把1和2带入3和4),得到下列式子:
通常地,我们会令 f_x = af和f_y = bf(这是由于a的单位为pixel/m,而f的单位为m,相乘从而将量纲统一到pixel):
将上式化作矩阵形式:
通常我们会将中间的3*3矩阵作为内参矩阵K,我们很清楚,前面的f是固定的,a是采样过程固定的,因此f_x也是固定的,也就是说内参矩阵K也是从出厂开始就是固定的:
5式通常又可以写作下列形式:
World -> Pixel
由于我们的机器人的运动,导致相机也不断在运动,因此我们可以把0式代入到6式中:
至此,我们已经完成了整个过程的推导。

