Fork/Join框架与Java8 Stream API 之并行流的速度比较
Fork/Join 框架有特定的ExecutorService和线程池构成。ExecutorService可以运行任务,并且这个任务会被分解成较小的任务,它们从线程池中被fork(被不同的线程执行)出来,在join(即它的所有的子任务都完成了)之前会一直等待。
Fork/Join 使用了任务窃取来最小化线程的征用和开销。线程池中的每条工作线程都有自己的双端工作队列并且会将新任务放到这个队列中去。它从队列的头部读取任务。如果队列是空的,工作线程就尝试从另外一个队列的末尾获取一个任务。窃取操作不会很频繁,因为工作线程会采用后进先出的顺序将任务放入它们的队列中,同时工作项的规模会随着问题分割成子问题而变小。你一开始把任务交给一个中心的工作线程,之后它会继续将这个任务分解成更小的任务。最终所有的工作线程都只会设计很少量的同步操作。
Stream介绍(引)
Stream 作为 Java 8 的一大亮点,它与 java.io 包里的 InputStream 和 OutputStream 是完全不同的概念。它也不同于 StAX 对 XML 解析的 Stream,也不是 Amazon Kinesis 对大数据实时处理的 Stream。Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言+多核时代综合影响的产物。
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。
所以说,实际上Stream并行流实际上就是一个帮你fork/join 后的API,为了验证效率,我编写了一个对1000_000个数进行排序的程序
import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.RecursiveAction; import java.util.stream.Collectors; import java.util.stream.IntStream; import java.util.stream.Stream; public class ParallelMergeSort { public static void main(String[] args) { final int SIZE = 10000000; int[] list1 = new int[SIZE]; int[] list2 = new int[SIZE]; Integer[] list3 = new Integer[SIZE]; for (int i = 0; i < list1.length; i++) { list1[i] = list2[i] = (int)(Math.random() * 10000000); list3[i] = list1[i]; } long startTime = System.currentTimeMillis(); parallelMergeSort(list1); long endTime = System.currentTimeMillis(); System.out.println("Parallel time with " + Runtime.getRuntime().availableProcessors() + " processors is " + (endTime - startTime) + " milliseconds"); startTime = System.currentTimeMillis(); MergeSort.mergeSort(list2); endTime = System.currentTimeMillis(); System.out.println("Sequent time is " + (endTime - startTime) + " milliseconds"); List<Integer> tmp = new ArrayList<Integer>(); Collections.addAll(tmp, list3); startTime = System.currentTimeMillis(); IntStream tmp1 = tmp.stream().parallel().mapToInt(Integer::intValue).sorted(); endTime = System.currentTimeMillis(); System.out.println("ParallelStream time is " + (endTime - startTime) + " milliseconds"); tmp1.limit(100).forEachOrdered(System.out::println); /* for(int i = 0; i < 100; i++) { System.out.println(tmp2.get(i)); }*/ } public static void parallelMergeSort(int[] list) { RecursiveAction mainTask = new SortTask(list); ForkJoinPool pool = new ForkJoinPool(); pool.invoke(mainTask); } public static class SortTask extends RecursiveAction{ /** * */ private static final long serialVersionUID = 1L; private final int THRESHOLD = 500; private int[] list; SortTask(int[] list){ this.list = list; } @Override protected void compute() { if (list.length < THRESHOLD) java.util.Arrays.sort(list); else { //Obtain the first half int[] firstHalf = new int[list.length / 2]; System.arraycopy(list, 0, firstHalf, 0, list.length / 2); //Obtain the second half int secondHalfLength = list.length - list.length / 2; int[] secondHalf = new int[secondHalfLength]; System.arraycopy(list, list.length /2, secondHalf, 0, secondHalfLength); //Recursively sort the two halves invokeAll(new SortTask(firstHalf), new SortTask(secondHalf)); //Merge firstHalf with second MergeSort.merge(firstHalf, secondHalf, list); } } } public static class MergeSort { /** The method for sorting the numbers */ public static void mergeSort(int[] list) { if (list.length > 1) { // Merge sort the first half int[] firstHalf = new int[list.length / 2]; System.arraycopy(list, 0, firstHalf, 0, list.length / 2); mergeSort(firstHalf); // Merge sort the second half int secondHalfLength = list.length - list.length / 2; int[] secondHalf = new int[secondHalfLength]; System.arraycopy(list, list.length / 2, secondHalf, 0, secondHalfLength); mergeSort(secondHalf); // Merge firstHalf with secondHalf into list merge(firstHalf, secondHalf, list); } } /** Merge two sorted lists */ public static void merge(int[] list1, int[] list2, int[] temp) { int current1 = 0; // Current index in list1 int current2 = 0; // Current index in list2 int current3 = 0; // Current index in temp while (current1 < list1.length && current2 < list2.length) { if (list1[current1] < list2[current2]) temp[current3++] = list1[current1++]; else temp[current3++] = list2[current2++]; } while (current1 < list1.length) temp[current3++] = list1[current1++]; while (current2 < list2.length) temp[current3++] = list2[current2++]; } } }
代码可以看到,利用三种方法,对随机生成的 int 数据排序
第一种是自己编写的fork/join利用二分法排序
第二种是单线程下的二分法排序
第三种是并行流的排序
为了验证并行流是否排序正确,输出流前100个数
结果如图:
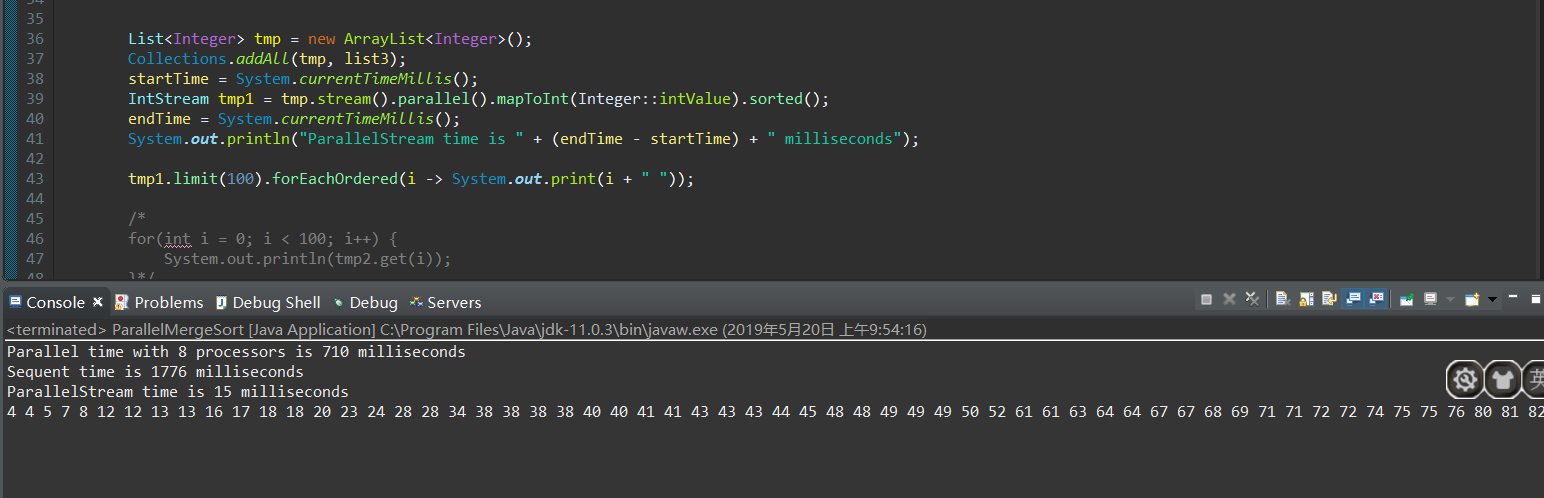
但是这是为没有收集器的情况,并行流很快的完成并且得到IntStream,加上收集器后:
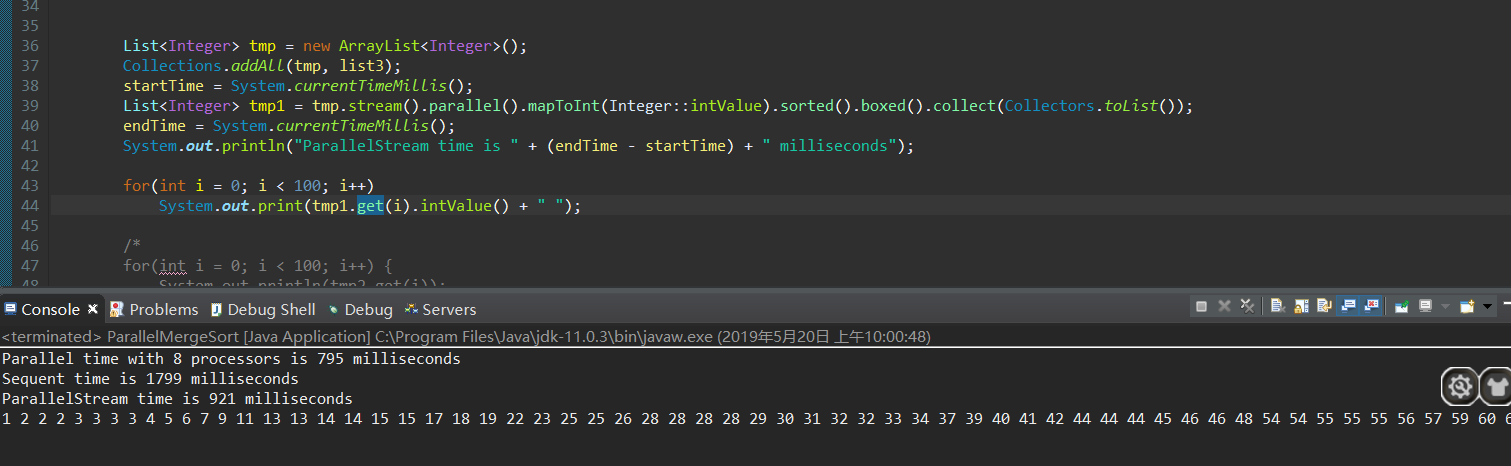
可以看出,排序很快完成,在最后的类型转换上花费了大量的时间,
而根据Stream 的介绍,实验fork/join方法完成的时间应该不会与并行流差距太大,实际上,实验中编写的代码在fork分解阶段和join阶段花费了大量时间,远不如直接使用API快速
但是如果正确使用fork/join框架的话也不会很慢
但是相比单线程已经远远提升了效率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号