mysql的MVCC机制
一、undo log版本链
我们在执行update,insert,delete的时候会生成undo log日志,以防止回滚使用。
一条sql执行,会生成一条undo log日志:
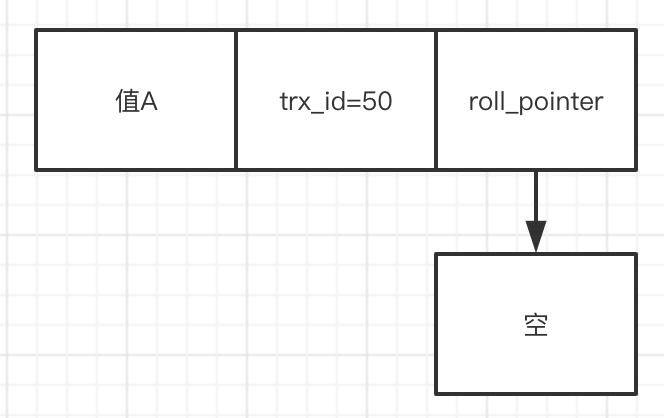
其中trx_id就是执行这条sql的事务id,roll_pointer指向对同一个值修改的undo log日志,因为当前没有,就指向一个空对象。
又有一个sql对这个数据进行修改,事务id为51,值改为B:
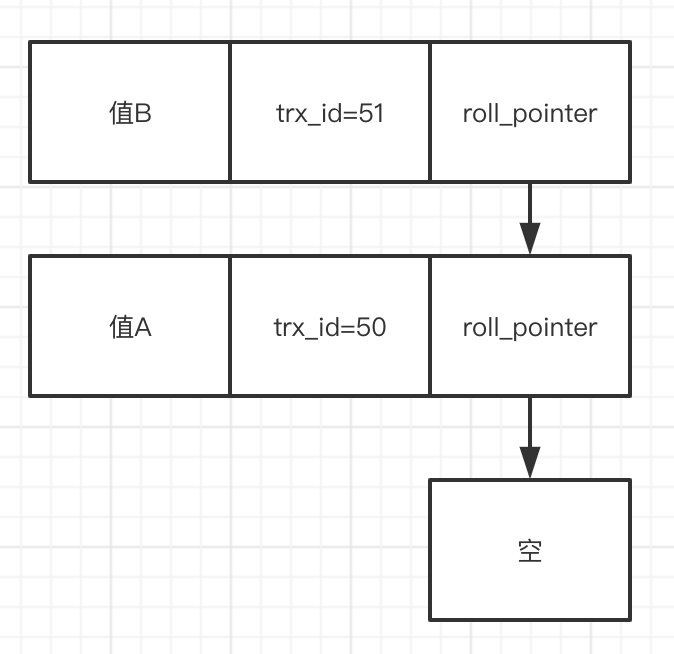
对同一条数据进行修改,通过roll_pointer连起来,就形成了undo log版本链。
二、ReadView机制
执行一个事务的时候生成一个ReadView,ReadView包括:
1.m_ids:还未提交的事务id
2.min_trx_id:m_ids中最小的事务id
3.max_trx_id:mysql生成的下一个事务id
4.creator_trx_id:当前事务id,也就是创建这个Read View的事务id
比如现在有事务A,事务B对数据进行修改,事务A生成的Read View:
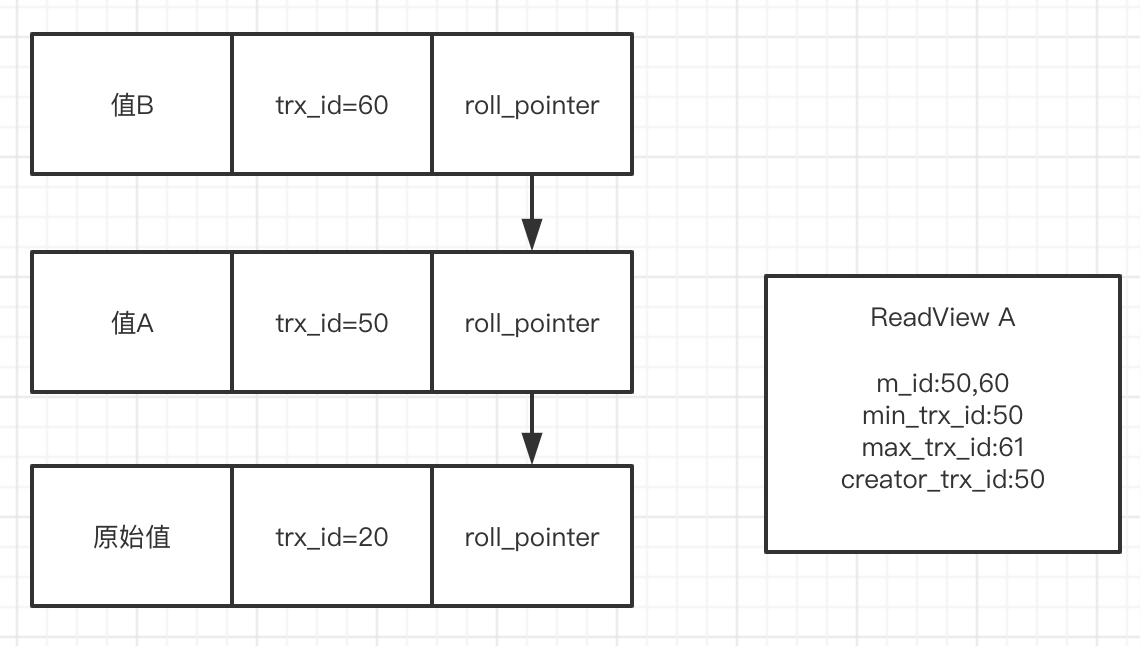
三、mysql的RR级别实现原理
那么mysql的MVCC机制如何基于undo log版本链和ReadView来实现呢?
我们看看mysql默认的RR级别,解决了脏读、不可重复读、幻读等问题:
脏读:事务B开启,undo log生成一条日志。此时事务A来查询,值为B的这条undo log,trx_id为60,比事务A中ReadView的creator_trx_id:50要大,说明在事务A开启前执行的,查一下m_ids果然在这个集合里面,说明这个事务和事务A同时进行的,继续向下走。下一条日志的trx_id为50,就是自己事务的id可以查询,返回值A。这就解决了脏读的问题。
不可重复读:在事务B开启前,事务A查询到的值为A。提交后,事务A查询到的值还是A,解决了不可重复读的问题。
幻读:比如执行一条sql:select count(*) where id>10;
事务A刚开始查询时,满足条件的只有3条。事务B此时插入一条数据,id为6。事务A来查询,id>10的数据,发现复合查询条件的有2条,一条为原始3条,一条为事务B提交后的4条。事务A比较trx_id比事务B的小,而且在m_ids中,所以返回的是原始数据那条还是3。这就解决了幻读的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号