零拷贝

一、问题
传统的Linux io操作,直接与io交互的话,首先得寻址,这个寻址是个很耗时的过程。为了减少与磁盘的io,加了一个page cache层,也就是os cache。如果page cache有的话就不需要到磁盘里找了,直接返回,这个速度就很快了。如果没有再到磁盘里查询,进行读写。那么一次io的操作就是:

1.从磁盘文件中拷贝到内核中的页缓存。这步是DMA copy的,发生第一次copy。
2.从页缓存拷贝到用户空间缓存里,也就是应用程序对应的内存空间里。这步是CPU copy的,发生第二次copy,而且从内核态切换到用户态,发生了第一次切换。
3.从用户空间缓存拷贝到socket缓存区。这步是CPU copy的,发生第三次copy,从用户态切换到内核态,又发生了一次切换。
4.从socket缓冲区拷贝到网络中。这步是DMA copy的,发生第四次copy。
可以看到一共发生了4次拷贝,其中cpu 参与了两次拷贝,而且用户态和内核态也发生了多次上下文切换,非常的耗cpu资源。
二、定义
为了避免拷贝对cpu的压力,我们可以通过减少不必要的拷贝来进行优化。所谓的零拷贝,并不是不发生一次拷贝,而是减少不必要的拷贝去进行优化。
三、方法
1.mmap
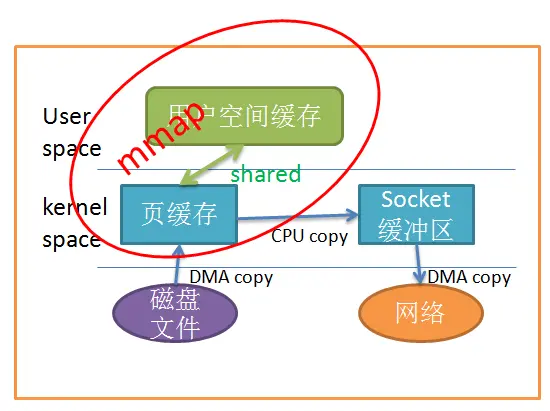
应用程序调用mmap,从磁盘文件DMA copy到页缓存中,用户空间缓存与页缓存共享这部分内存,所以就不需要从页缓存拷贝到用户空间中了。然后直接通过CPU copy到Socket缓冲区中,再DMA copy到网络中。可以发现,少了一次CPU copy, 而且没有了用户态和内核态的上下文切换了。
2.sendfile
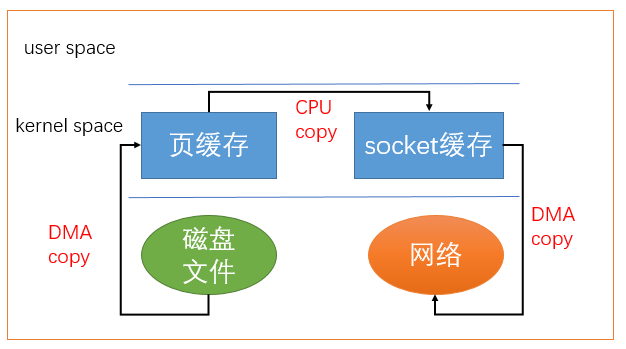
Linux从2.1版内核开始引入了sendfile,直接从页缓存拷贝到socket缓存中。
#include<sys/sendfile.h> ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)
从out_fd到in_fd传输数据,但是页缓存到socket缓存还是发生了一次CPU copy的,这步不是必要的,也可以进行优化。
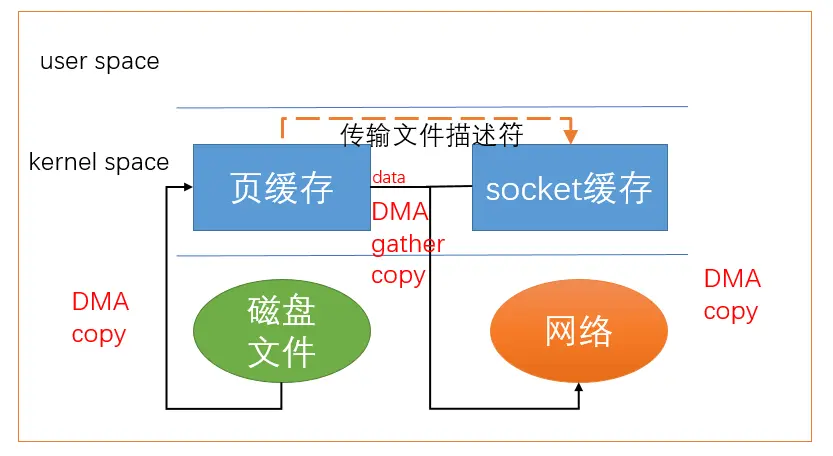
sendfile通过DMA 引擎进行优化,只是将将文件描述符传输给socket缓存,数据直接从页缓存发送到网络中。
缺点:只适用与将文件拷贝到套接字上。
3.splice
Linux在2.6.17版本引入splice系统调用,用于在两个文件描述符中移动数据:
#define _GNU_SOURCE /* See feature_test_macros(7) */ #include <fcntl.h> ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
缺点:至少有一个文件描述符为管道。
参考文档:https://mp.weixin.qq.com/s/7IT10kFfg8bxchaN_n-GEg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号