
NLP机器翻译 02:5分钟带你玩转seq2seq模型(小白友好,持续更新ing....)
本次任务主要是了解什么是基于神经网络的机器翻译,并介绍一个常用于Baseline的模型seq2seq,最后带大家了解如何对模型翻译的结果进行评价
1 引言
NLP(Natrual Language Processing) 自然语言处理其实可以追溯到“模仿游戏”,即图灵测试,自从图灵给予“智能”一个概念之后,图灵测试也成为NLP自然语言处理的一个重要评判标准。自1954年IBM第一个机器翻译系统的完成,到将深度学习融入自然语言的处理当中,再到现在的ChatGPT等大模型,其发展速度与未来景象让人叹为观止。那么今天这篇博客,主要带各位了解认识一下基于神经网络的机器翻译的核心架构Encoder-Decoder,以及经典的seq2seq模型。
2 什么是基于神经网络的机器翻译?
要回答这个问题,我们首先要搞明白,什么是神经网络,为什么机器翻译可以利用神经网络?

如果我们把这个问题抛给ChatGPT,那么我们会得到这么一个高大上的解释(仿生物神经系统),其实朴素一点说被称为神经网络其实就是因为将机器学习中所使用到的模型用图形的方式展示出来,看着像一个网状结构,因此取的这么一个名称。早在80、90年代,人们被这个名词忽悠的团团转,以至于到最后机器学习的名字被搞臭了,这也就引出了之后的深度学习,大家把机器学习的过程,一层一层的叠加这个就叫做deep,取名deep learning~ (以下图片参考李宏毅老师2021年机器学习课件,是不是还真挺像一个神经网络的(doge))
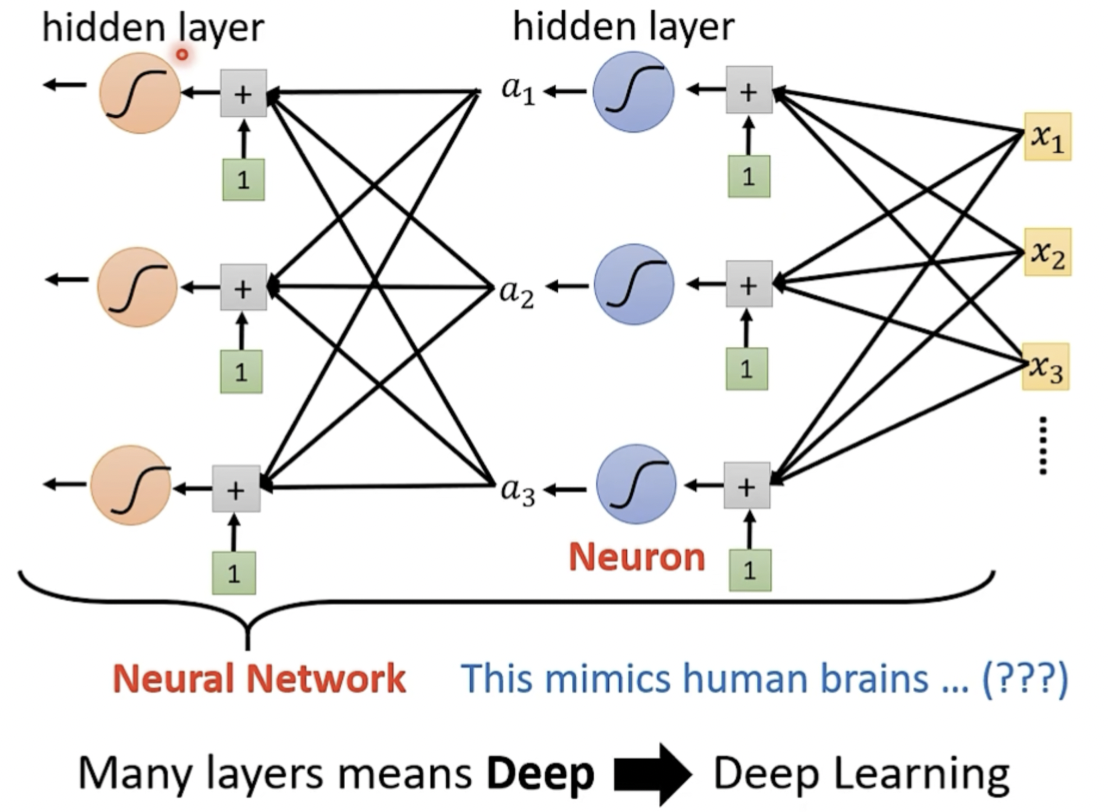
那什么叫基于神经网络的机器翻译呢?很简单就是利用机器学习来训练模型以达到智能翻译的目的呗,那么我们该如何来训练模型呢?
3 神经机器翻译技术流程
- 配置环境:这个不用多说,不管使用Colab还是魔塔,基本环境是要配置好的,各种下载配置如jieba、spacy包等等。
- 数据预处理:这一部分和基础的机器学习过程是差不多的,只不过,我们考虑到要进行机器翻译,并且分析一下我们当前的数据集可以发现,我们还需要另外做的事情:统一大小写、去除拟声词以及文本分割
- 模型训练
- 翻译质量评价:这里先简单的提一下,后续第5部分,会做专门讲解
4 编码器-解码器模型
什么是编码器-解码器框架呢?如果大家学习过计算机网络这门课,那么你们肯定都知道,在开头讲解电路交换的时候,发出的信号需要经过一个编码器再传输到链路上,接收方接受信号时需要通过一个解码器接受信息,其实这里的编码器-解码器模型是同样的道理(下图来自DataWhale学习手册Task02部分),具体内部是如何实现的,这篇博客里不再具体赘述,之后我会开一篇文章专门进行讲述~

这里简单说一下什么是注意力机制,这其实也是一个听上去非常高大上的概念,朴素来说,就是让模型在输出一个值的时候,给每个输入赋予不同的权重,也就是将注意力集中在关键的那几个部分,这部分的会和Encoder-Decoder一起进行详细讲解,需要请自取~
5 翻译质量评价
既然我们在讨论如何评价机器的翻译质量,那么理所当然的我们也应该简单聊一聊,如何评价一篇由人类翻译出的文章。没错,就是我们平时最常听到的三个字“信、达、雅”,目前机器翻译还远远谈不上雅的程度,因此传统观点就重点关注”信“忠诚度又称准确度、”达“流畅度也就是译文在目标语言中是否流畅这两方面。准确度意味着译文应该尽可能忠实于原文内容,不添加、删减或扭曲信息。自动评估时常常采用对比译文和参考翻译之间重合度的方法来进行。流畅度即译文在目标语言中是否自然流畅,符合目标语言的语法、习惯和表达方式。这意味着译文应该读起来像是由目标语言的母语者写的,而不是机器翻译的产物。
当前对于翻译质量的评价主要可以分为两类:自动评价和人工评价。自动评价方法如 BLEU、METEOR、TER 和 ROUGE 由于计算简便、适用于大规模评估而广泛应用,但也存在忽略语义和句子结构的问题。人工评价方法则能够综合考虑翻译的语义和语言质量,但成本较高且主观性强。在实际应用中,通常会结合多种评价方法,以获得更全面的评估结果。
6 总结
当前LLM发展如火如荼,未来NLP能如何发展?是否能达到“雅”的地步,让我们拭目以待...
本人初学,如有错误,期待您在评论区的指正,我会及时更新修改

 浙公网安备 33010602011771号
浙公网安备 33010602011771号