
模块的导入以及软件目录规范
-
模块(Module)
-
定义:具有Python函数和状态语句并且能够实现一定功能的文件
-
三种来源:(1)Python自带的的内置模块,(2) 别人写的模块,(3) 自己写的模块
-
四种表现形式:(1)使用python编写的py文件,(2)已被编译为共享库或者是dll的C或C++拓展,(3)把一系列模块组织到一起的文件夹,(4)使用C编写并连接到python的内置模块
-
为什么要是用模块:首先使用别人事先写好的模块有利于我们提高开发效率,少做无用功,其次当我们进行一个比较大的项目的开发时,不可能只在一个py文件中写项目,肯定要在多个文件中构建项目框架,在各个文件中需要调用到其他文件的函数,此时就需要将公共的方法写成模块,一起调用过去即可。
-
最后,在模块的使用中,我们一定要分清哪一个是执行文件,哪一个是被导入文件
-
导入模块的内存机制(import module)
![]()
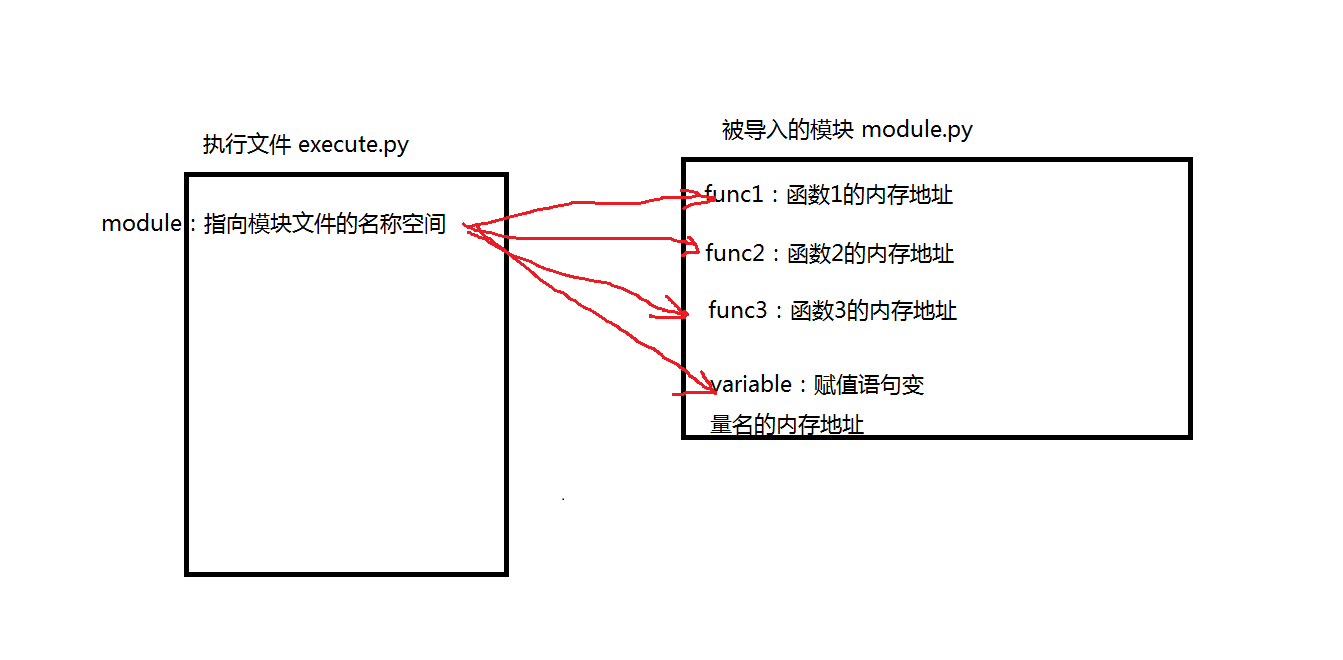
- 步骤:首先先是通过Pycharm运行执行文件,在内存中开辟出一块空间,随后通过import module导入模块时,模块文件同时开辟出另一块内存空间,运行模块中的代码将产生的函数名变量名与输出的值存放在module.py的名称空间中,随后在执行文件的名称空间产生一个指向模块名称空间的名字。
-
通过模块文件名.名字来访问模块文件名称空间中的名字*******
-
from 模块文件名 import 函数名变量名
-
from md1 import * # 一次性将md1模块中的名字全部加载过来 不推荐使用 并且你根本不知道到底有哪些名字可以用
并且__all__方法可以限制导入执行文件的拿到名字的个数'__all__ = ['函数名1','函数名2','变量名']',除这些名字之外的名字都不会在执行文件中输出,在模块中使用此方法,不是执行文件。
-
__name__方法
-
def index1(): print('index1') def index2(): print('index2') print(__name__) # 输出 __main__ # 当文件被当做执行文件执行的时候__name__打印的结果是__main__ # 当文件被当做模块导入的时候__name__打印的结果是模块名(没有后缀) if __name__ == '__main__': index1() # 输出index1 index2()
-
绝对导入和相对导入
-
绝对导入: 绝对导入是指需要以执行文件所在的sys.path的路径开始查找,其中执行文件导入的模块也都要以执行文件所在目录为起始目录开始查找,查不到就会报ImportError。 绝对导入的优点就是层次清晰,执行文件和其他模块写法都统一, 缺点就是其他模块导入要总是根据执行文件所在处来导入,很麻烦,且文件位置变动导入就会出错。 相对导入: 相对导入是指相对于被导入模块本身所在的文件夹目录为起始点开始查找,以.表示当前目录,.. 表示上层目录 ...表示上上层目录,依次类推。 它的优点就是导入简单,只要和导入的其他模块的相对位置不变,就不会报错。缺点就是没有绝对导入清晰,且不能作为执行文件,只能作为被导入模块。 -
软件开发规范
- 软件开发中,由于程序规模大,集成效率高,各种功能的模块文件多的原因,为了方便之后的维护和开发,因此发明了一套默认的软件开发的规范,来约束不同模块文件的存放。
-
bin目录 ——————存放着执行函数的代码项目启动文件 core目录 ————— 存放着项目的核心逻辑文件 conf目录 ————— 存放着项目的配置文件 lib目录 —————— 存放着项目的所用到的公共功能 log目录 —————— 存放着项目的日志文件 db目录 —————— 存放着项目的数据库文件 readme目录 ———— 存放着 项目的介绍项目

 浙公网安备 33010602011771号
浙公网安备 33010602011771号