完全分布式搭建及脚本启动
一.完全分布式的搭建
先准备2台虚拟机:
1) 将原来搭建伪分布式的那台虚拟机克隆一台:https://www.cnblogs.com/IT_CH/p/12336594.html
2) 对克隆的机器做修改如下几个配置
(1)修改克隆机器的IP地址

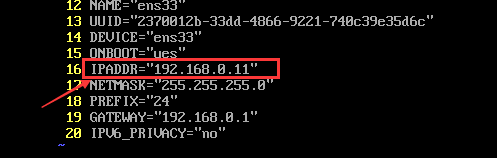
修改完之后记得重启网络:systemctl restart network

测试:ping www.baidu.com 【如果可以ping通,就可以通过xshell操作该虚拟机】
(2)修改克隆机的主机名

修改完不会立即生效,需要reboot重启虚拟机才能生效【修改完IP主机映射再重启】
(3)修改克隆机的ip与主机的映射


可以直接在后面添加即可,不用将原机器的IP主机映射删除
修改完之后重启:reboot
开始搭建完全分布式
完全分布式的目标就是实现扩容
如何扩容:就是将很多台机器加入到一个集群中,共享硬件资源和软件资源
NameNode:只能有一台【用来做管理】是用来记录每个文件的存放位置
DataNode:可以有任意多台 是用来存放真实的数据的
(1)先将克隆机的dfs文件夹全部清空
原因:克隆的时候,两台机器的dfs数据是完全一样的,要把克隆的那个节点的dfs文件夹清空
dfs文件夹的目录:cd /opt/software/hadoop-2.7.7/tmp/dfs/
将该文件夹下的数据清空:rm -rf *

(2)要做从节点的映射【从节点为克隆的机器】
在第一台机器上添加从节点的IP地址映射:vim /etc/hosts

(3)机器之间做ssh免密
配置免密过程:
1) 给所有主机生成公钥和私钥
ssh-keygen 生成密钥对
2) 将公钥拷贝给其他主机
ssh-copy-id hdp02 【一次只能拷贝一台主机】
测试:ssh hdp02【成功则表示免密配置成功】
(4)修改hdfs-site.xfs配置文件【两台机器都修改】

19 <configuration> 20 <property> 21 <name>dfs.replication</name> 22 <value>3</value> 23 </property> 24 </configuration>
(5)将从节点添加到slaves配置文件中

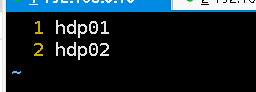
查看是否搭建成功
启动测试:start-dfs.sh【在主节点启动,从节点也会跟着启动DataNode】
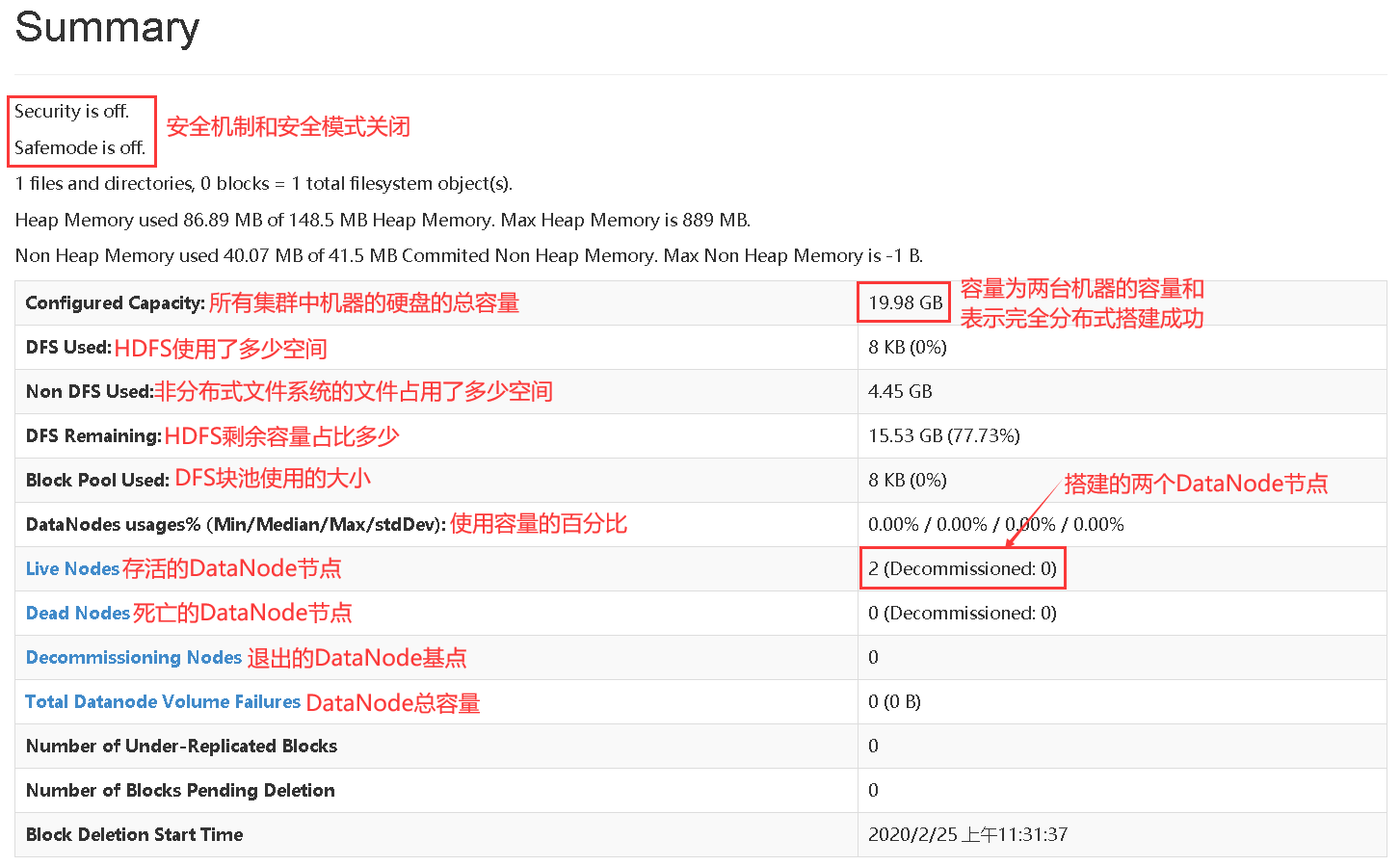

······启动过程中可能会遇到的问题······
查看日志:cd /opt/software/hadoop-2.7.7/logs【在该目录下查看日志文件】
1.如果主节点的DataNode或者NameNode启动不起来

解决办法:1) 先将主节点的dfs文件夹下的东西清空
2) 然后重新格式化:hadoop namenode -format
2.如果从节点的DataNode启动不起来,也出现了和主节点一样的问题
解决办法:只需要将从节点dfs文件夹下的东西重新全部清空即可
二.sbin下的脚本启动
(1)start-all.sh/stop-all.sh
启动/停止所有(5个)的软件【NameNode,DataNode,secondarynamenode,nodemanager,resourcesmanager】
(2)start-dfs.sh/stop-dfs.sh
一次性启动/停止3个软件【NameNode,DataNode,secondarymanager】
(3)start-yarn.sh/stop-yarn.sh【MapReduce使用】
一次性启动/停止2个软件【nodemanager,resourcesmanager】
(4)hadoop-daemon.sh start XXX
只想启动/停止其中某一个软件【NameNode,DataNode,secondarymanager】
(5)yarn-daemon.sh start XXX
只想启动/停止其中某一个软件【nodemanager,resourcesmanager】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号