Hadoop的安装与配置(伪分布式)
0.环境准备(准备一台空白的虚拟机)

1.对上传的软件做管理(规划)
cd /opt目录下:mkdir insytall software test other
/opt/install 上传用
/opt/software 安装用(解压后的)
/opt/other 其他软件
/opt/test 测试

2.开始Hadoop软件的安装(准备JDK和Hadoop包)
······hadoop的下载地址:hadoop.apache.org
将JDK和Hadoop上传到install中(rz上传,如果没有该命令,先要安装lrzsz用于上传)

3.安装JDK
解压JDK:tar -zxvf jdk-8u144-linux-x64.tar.gz
重命名JDK:mv jdk1.8.0_144/ jdk1.8
将解压后的文件移动到/opt/software中:mv jdk1.8 ../software/
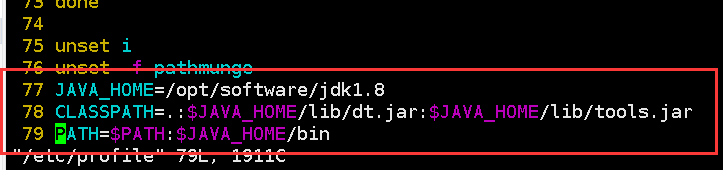
将JDK配置到环境变量中去:vim /etc/profile
要让修改后的配置文件生效:source /etc/profile (为了重新加载某个配置文件)
验证是否安装成功:javac -version 或 java -version 或 echo $PATH
4.解压Hadoop并配置到环境变量中
解压hadoop:tar -zxvf hadoop-2.7.7.tar.gz
将解压后的文件移动到/opt/software中:mv hadoop-2.7.7 ../software/
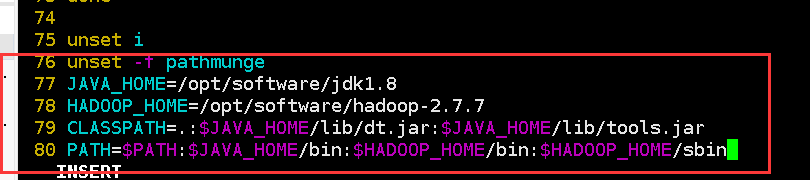
将Hadoop配置到环境变量中去:vim /etc/profile
要让修改后的配置文件生效:source /etc/profile
验证:echo $PATH
5.修改Hadoop的6个配置文件
配置文件位置:cd /opt/software/hadoop-2.7.7/etc/hadoop/
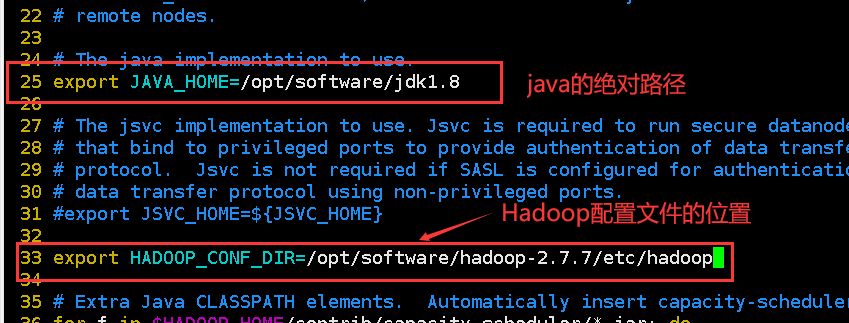
5.1.修改hadoop-env.sh
5.2.修改core-site.xml
19 <configuration> 20 <property> 21 <name>fs.defaultFS</name> 22 <value>hdfs://hdp01:9000</value> #hdp01是主机名 23 </property> 24 <property> 25 <name>hadoop.tmp.dir</name> 26 <value>/opt/software/hadoop-2.7.7/tmp</value> 27 </property> 28 </configuration>
5.3.修改hdfs-site.xml
19 <configuration> 20 <property> 21 <name>dfs.replication</name> 22 <value>1</value> 23 </property> 24 </configuration>
5.4.修改mapred-site.xml(没有该配置文件:cp mapred-site.xml.template mapred-site.xml)
19 <configuration> 20 <property> 21 <name>mapreduce.framework.name</name> 22 <value>yarn</value> 23 </property> 24 </configuration>
5.5.修改yarm-site.xml
15 <configuration> 16 <property> 17 <name>yarn.resourcemanager.hostname</name> 18 <value>hdp01</value> #hdp01是主机名 19 </property> 20 <property> 21 <name>yarn.nodemanager.aux-services</name> 22 <value>mapreduce_shuffle</value> 23 </property> 24 </configuration>
5.6.修改slaves
hdp01
slaves是一个普通的文件,只需要加上一个主机名即可 【前提必须是要先做好主机和IP的映射】
6.格式化文件系统
hadoop namenode -format(因为配置了环境变量,所有可以在任何地方使用)
出现如下即表示格式化成功

7.在启动服务之前还需要配置一个免密
ssh-keygen 先生成一个公钥
ssh-copy-id hdp01 将公钥拷贝给自己
8.开始运行服务器(文件系统服务器必须要启动才能存放)
start-all.sh 开启服务
stop-all.sh 关闭服务
如何证明是否启动成功:jps【java/bin里面的命令 会检测当前的进程中哪些是java进程】
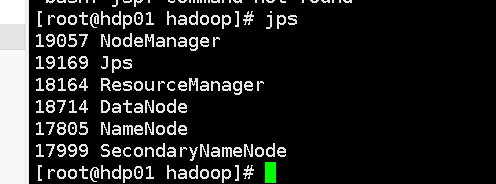
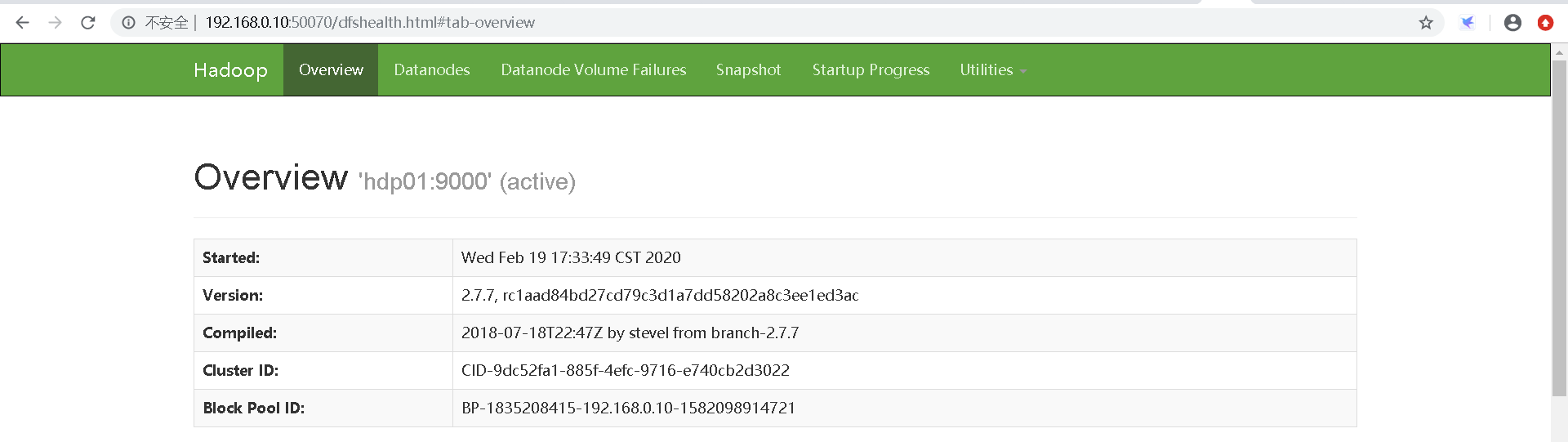
NameNode web工程 端口号:50070
DataNode web工程 端口号:50075
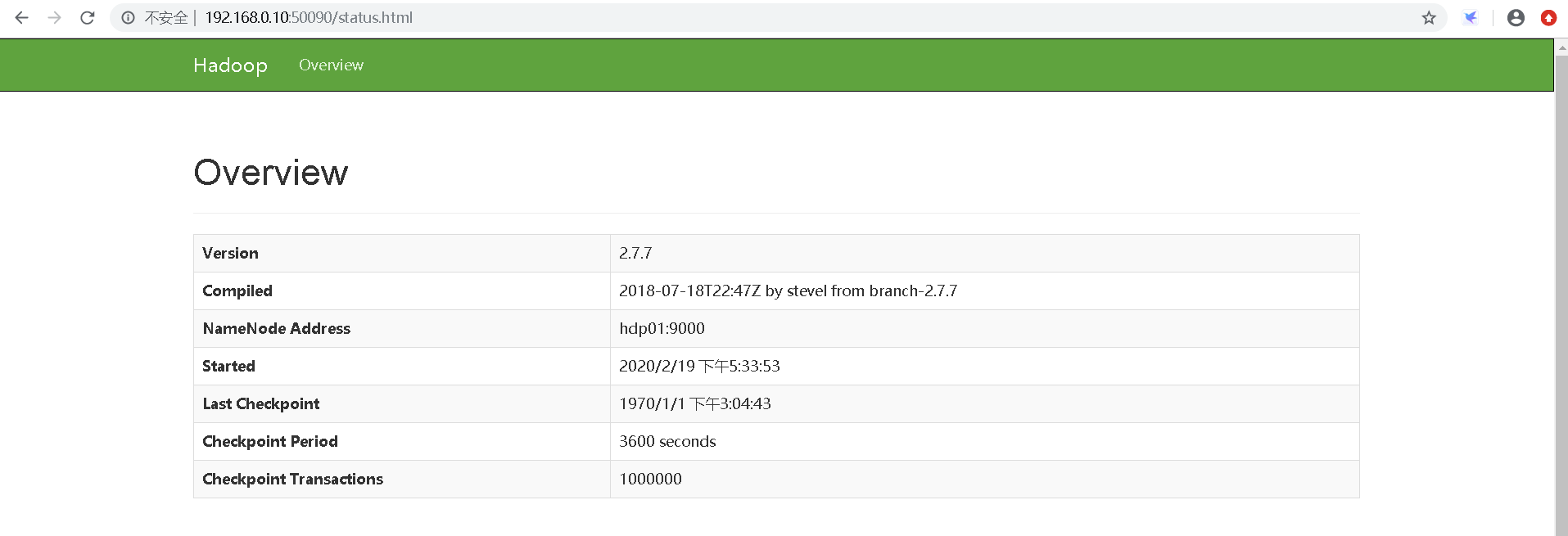
SecondaryNameNode web工程 端口号:50090
ResourceManager web工程 端口号:8088
NodeManager



 浙公网安备 33010602011771号
浙公网安备 33010602011771号