python数据分析学习(7)数据清洗与准备(1)
关于文件的读写方面先放一下,接下来介绍数据清洗方面的知识。有时候数据对于特定的任务来说格式并不正确,需要转化为更加适合的数据形式。这里介绍数据清洗的有关基础知识,本篇博客先介绍如何处理缺失值。
一:处理缺失值
缺失数据在很多数据分析应用中都出现过,对于数值型数据,pandas使用浮点值NaN来表示缺失值。可以用isnull()对一直数组逐元素进行操作,返回布尔型判断结果,返回缺失值,而notnull相反。
在pandas中,用R语言中的编程惯例,将缺失值成为NA(not available),表示不存在的数据或者是不可观察的数据。而python内建的None值在对象数组也被当作NA处理。
可以用fillna填充缺失的数据,或使用'ffill'和'bfill'插值方法。
1. 过滤缺失值
用dropna过滤缺失值是非常常见的,它会返回Series中所有的非空数据及其索引值,和data[data.notnull()]是等价的。如下:

当处理DataFrame时,会复杂一点,dropna默认情况下会删除包含缺失值的行:
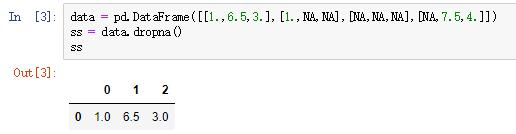
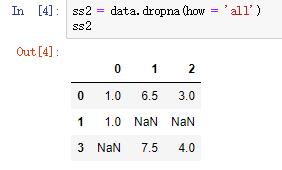
当传入参数how='all'时,将删除所有值均为NA的行:
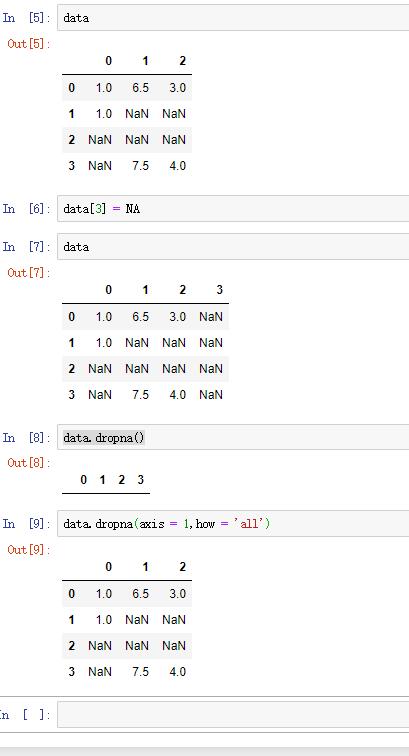
想要用同样的方法删除列,传入参数axis=1即可:
过滤DataFrame的行的相关方法往往涉及时间序列数据,可以用thresh参数保留包含一定数量的观察值的行,如下:

二:补全缺失值
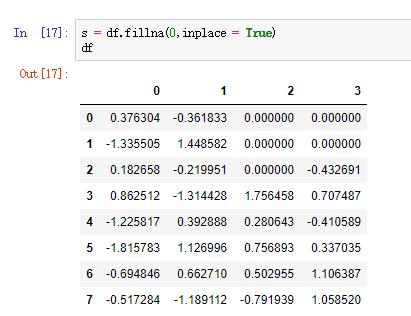
有时候需要用多种方法补全缺失值,而不是过滤缺失值,因为会丢弃其他数据。在大多数情况下,主要用fillna方法来补全缺失。里面可以用一个常数来替代缺失值。如下:

在调用fillna时使用字典,可以为不同列设定不同的填充值。

fillna返回的是一个新对象,但也可以修改已经存在的对象,用参数inplace=True即可。
还可以用method='fill'参数,但是用的少,这里就不说明了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号