3.1 spring5源码系列--循环依赖 之 手写代码模拟spring循环依赖
本次博客的目标
1. 手写spring循环依赖的整个过程
2. spring怎么解决循环依赖
3. 为什么要二级缓存和三级缓存
4. spring有没有解决构造函数的循环依赖
5. spring有没有解决多例下的循环依赖.
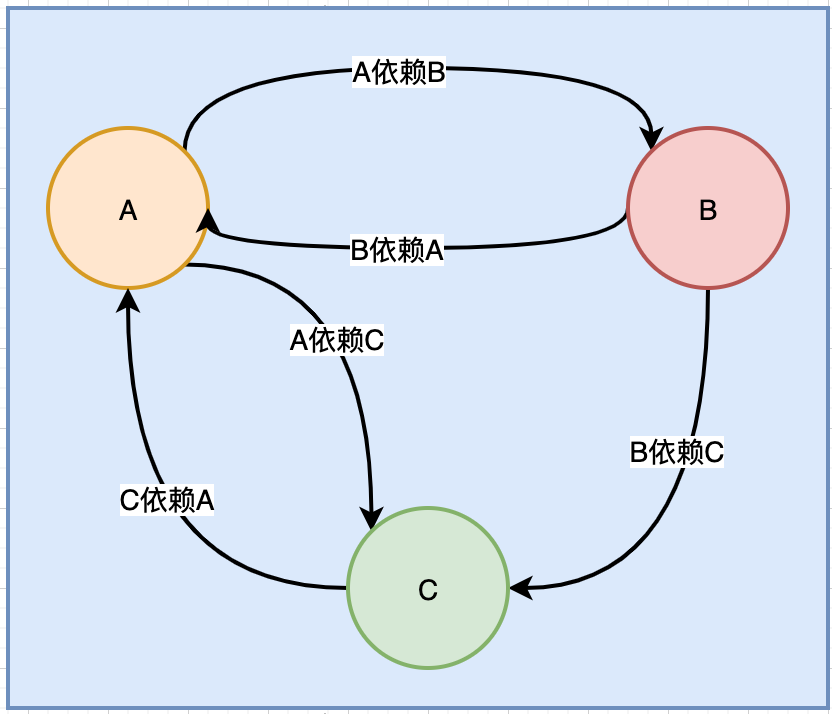
一. 什么是循环依赖?
如下图所示:
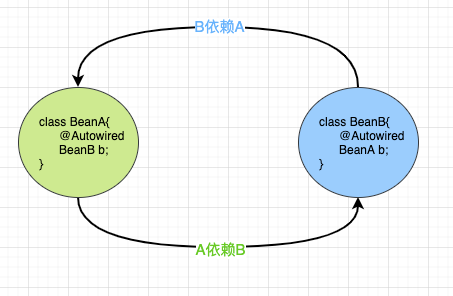
A类依赖了B类, 同时B类有依赖了A类. 这就是循环依赖, 形成了一个闭环
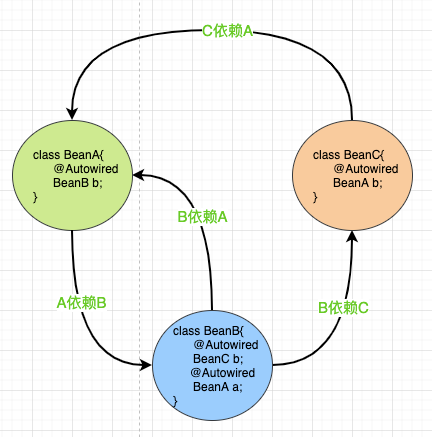
如上图: A依赖了B, B同时依赖了A和C , C依赖了A. 这也是循环依赖. , 形成了一个闭环
那么, 如果出现循环依赖, spring是如何解决循环依赖问题的呢?
二. 模拟循环依赖
2.1 复现循环依赖
我们定义三个类:
1. 新增类InstanceA
package com.lxl.www.circulardependencies; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Scope; import org.springframework.stereotype.Component; @Component @Scope("prototype") public class InstanceA { @Autowired private InstanceB instanceB; public InstanceA() { System.out.println("调用 instanceA的构造函数"); } public InstanceA(InstanceB instanceB) { this.instanceB = instanceB; } public void say(){ System.out.println( "I am A"); } public InstanceB getInstanceB() { return instanceB; } public void setInstanceB(InstanceB instanceB) { this.instanceB = instanceB; } }
这是InstanceA, 里面引用了InstanceB.
2. 新增类instanceB
package com.lxl.www.circulardependencies; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Scope; import org.springframework.stereotype.Component; @Component @Scope("prototype") public class InstanceB { @Autowired private InstanceA instanceA; public InstanceB() { System.out.println("调用 instanceB的构造函数"); } public InstanceA getInstanceA() { return instanceA; } public void setInstanceA(InstanceA instanceA) { this.instanceA = instanceA; } }
这是InstanceB, 在里面有引用了InstanceA
3:模拟spring是如何创建Bean的
这个在前面已经说过了, 首先会加载配置类的后置处理器, 将其解析后放入到beanDefinitionMap中. 然后加载配置类, 也将其解析后放入beanDefinitionMap中. 最后解析配置类. 我们这里直接简化掉前两步, 将两个类放入beanDefinitionMap中. 主要模拟第三步解析配置类. 在解析的过程中, 获取bean的时候会出现循环依赖的问题循环依赖.
第一步: 将两个类放入到beanDefinitionMap中
public class MainStart { private static Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>();
/** * 读取bean定义, 当然在spring中肯定是根据配置 动态扫描注册的 * * InstanceA和InstanceB都有注解@Component, 所以, 在spring扫描读取配置类的时候, 会把他们两个扫描到BeanDefinitionMap中. * 这里, 我们省略这一步, 直接将instanceA和instanceB放到BeanDefinitionMap中. */ public static void loadBeanDefinitions(){ RootBeanDefinition aBeanDefinition = new RootBeanDefinition(InstanceA.class); RootBeanDefinition bBeanDefinition = new RootBeanDefinition(InstanceB.class); beanDefinitionMap.put("instanceA", aBeanDefinition); beanDefinitionMap.put("instanceB", bBeanDefinition); } public static void main(String[] args) throws Exception { // 第一步: 扫描配置类, 读取bean定义 loadBeanDefinitions(); ...... }
上面的代码结构很简单, 再看一下注释应该就能明白了. 这里就是模拟spring将配置类解析放入到beanDefinitionMap的过程.
第二步: 循环创建bean
首先,我们已经知道, 创建bean一共有三个步骤: 实例化, 属性赋值, 初始化.
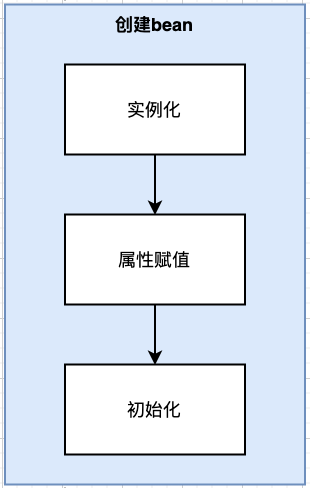
而在属性赋值的时候, 会判断是否引用了其他的Bean, 如果引用了, 那么需要构建此Bean. 下面来看一下代码
/** * 获取bean, 根据beanName获取 */ public static Object getBean(String beanName) throws Exception {/** * 第一步: 实例化 * 我们这里是模拟, 采用反射的方式进行实例化. 调用的也是最简单的无参构造函数 */ RootBeanDefinition beanDefinition = (RootBeanDefinition) beanDefinitionMap.get(beanName); Class<?> beanClass = beanDefinition.getBeanClass(); // 调用无参的构造函数进行实例化 Object instanceBean = beanClass.newInstance(); /** * 第二步: 属性赋值 * instanceA这类类里面有一个属性, InstanceB. 所以, 先拿到 instanceB, 然后在判断属性头上有没有Autowired注解. * 注意: 这里我们只是判断有没有Autowired注解. spring中还会判断有没有@Resource注解. @Resource注解还有两种方式, 一种是name, 一种是type */ Field[] declaredFields = beanClass.getDeclaredFields(); for (Field declaredField: declaredFields) { // 判断每一个属性是否有@Autowired注解 Autowired annotation = declaredField.getAnnotation(Autowired.class); if (annotation != null) { // 设置这个属性是可访问的 declaredField.setAccessible(true); // 那么这个时候还要构建这个属性的bean. /* * 获取属性的名字 * 真实情况, spring这里会判断, 是根据名字, 还是类型, 还是构造函数来获取类. * 我们这里模拟, 所以简单一些, 直接根据名字获取. */ String name = declaredField.getName(); /** * 这样, 在这里我们就拿到了 instanceB 的 bean */ Object fileObject = getBean(name); // 为属性设置类型 declaredField.set(instanceBean, fileObject); } } /** * 第三步: 初始化 * 初始化就是设置类的init-method.这个可以设置也可以不设置. 我们这里就不设置了 */ return instanceBean; }
我们看到如上代码.
第一步: 实例化: 使用反射的方式, 根据beanName查找构建一个实例bean.
第二步: 属性赋值: 判断属性中是否有@Autowired属性, 如果有这个属性, 那么需要构建bean. 我们发现在为InstanceA赋值的时候, 里面引用了InstanceB, 所以去创建InstanceB, 而创建InstanceB的时候, 发现里面又有InstanceA, 于是又去创建A. 然后以此类推,继续判断. 就形成了死循环. 无法走出这个环. 这就是循环依赖
第三步: 初始化: 调用init-method, 这个方法不是必须有, 所以,我们这里不模拟了
看看如下图所示
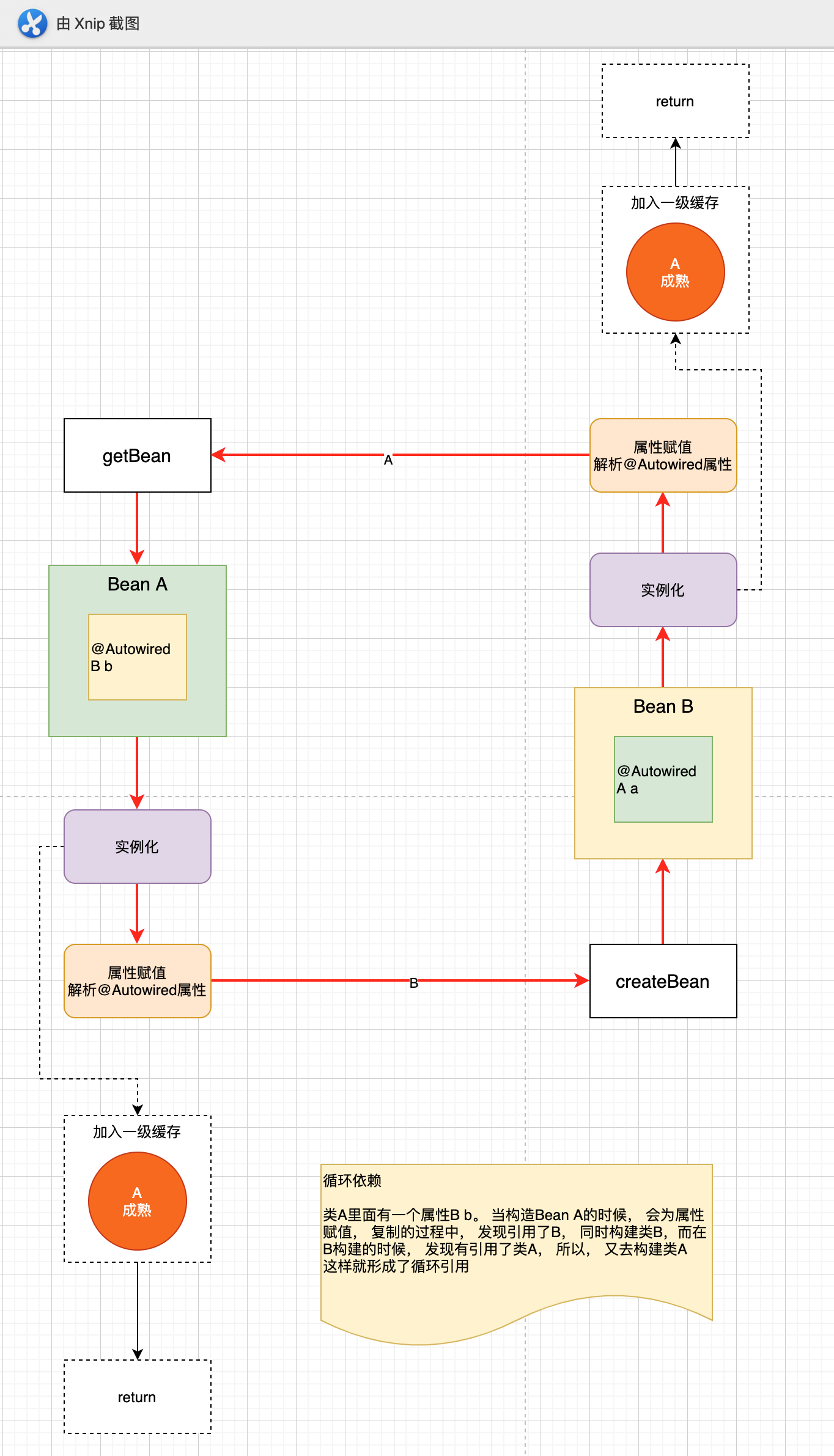
红色部分就形成了循环依赖.
4: 增加一级缓存, 解决循环依赖的问题.
我们知道上面进行了循环依赖了. 其实, 我们的目标很简单, 如果一个类创建过了, 那么就请不要在创建了.
所以, 我们增加一级缓存
// 一级缓存 private static Map<String, Object> singletonObjects = new ConcurrentHashMap<>(); /** * 获取bean, 根据beanName获取 */ public static Object getBean(String beanName) throws Exception { // 增加一个出口. 判断实体类是否已经被加载过了 Object singleton = getSingleton(beanName); if (singleton != null) { return singleton; } /** * 第一步: 实例化 * 我们这里是模拟, 采用反射的方式进行实例化. 调用的也是最简单的无参构造函数 */ RootBeanDefinition beanDefinition = (RootBeanDefinition) beanDefinitionMap.get(beanName); Class<?> beanClass = beanDefinition.getBeanClass(); // 调用无参的构造函数进行实例化 Object instanceBean = beanClass.newInstance(); /** * 第二步: 放入到一级缓存 */ singletonObjects.put(beanName, instanceBean); /** * 第三步: 属性赋值 * instanceA这类类里面有一个属性, InstanceB. 所以, 先拿到 instanceB, 然后在判断属性头上有没有Autowired注解. * 注意: 这里我们只是判断有没有Autowired注解. spring中还会判断有没有@Resource注解. @Resource注解还有两种方式, 一种是name, 一种是type */ Field[] declaredFields = beanClass.getDeclaredFields(); for (Field declaredField: declaredFields) { // 判断每一个属性是否有@Autowired注解 Autowired annotation = declaredField.getAnnotation(Autowired.class); if (annotation != null) { // 设置这个属性是可访问的 declaredField.setAccessible(true); // 那么这个时候还要构建这个属性的bean. /* * 获取属性的名字 * 真实情况, spring这里会判断, 是根据名字, 还是类型, 还是构造函数来获取类. * 我们这里模拟, 所以简单一些, 直接根据名字获取. */ String name = declaredField.getName(); /** * 这样, 在这里我们就拿到了 instanceB 的 bean */ Object fileObject = getBean(name); // 为属性设置类型 declaredField.set(instanceBean, fileObject); } } /** * 第四步: 初始化 * 初始化就是设置类的init-method.这个可以设置也可以不设置. 我们这里就不设置了 */ return instanceBean; }
还是上面的获取bean的流程, 不一样的是, 这里增加了以及缓存. 当我们获取到bean实例以后, 将其放入到缓存中. 下次再需要创建之前, 先去缓存里判断,是否已经有了, 如果没有, 那么再创建.
这样就给创建bean增加了一个出口. 不会循环创建了.
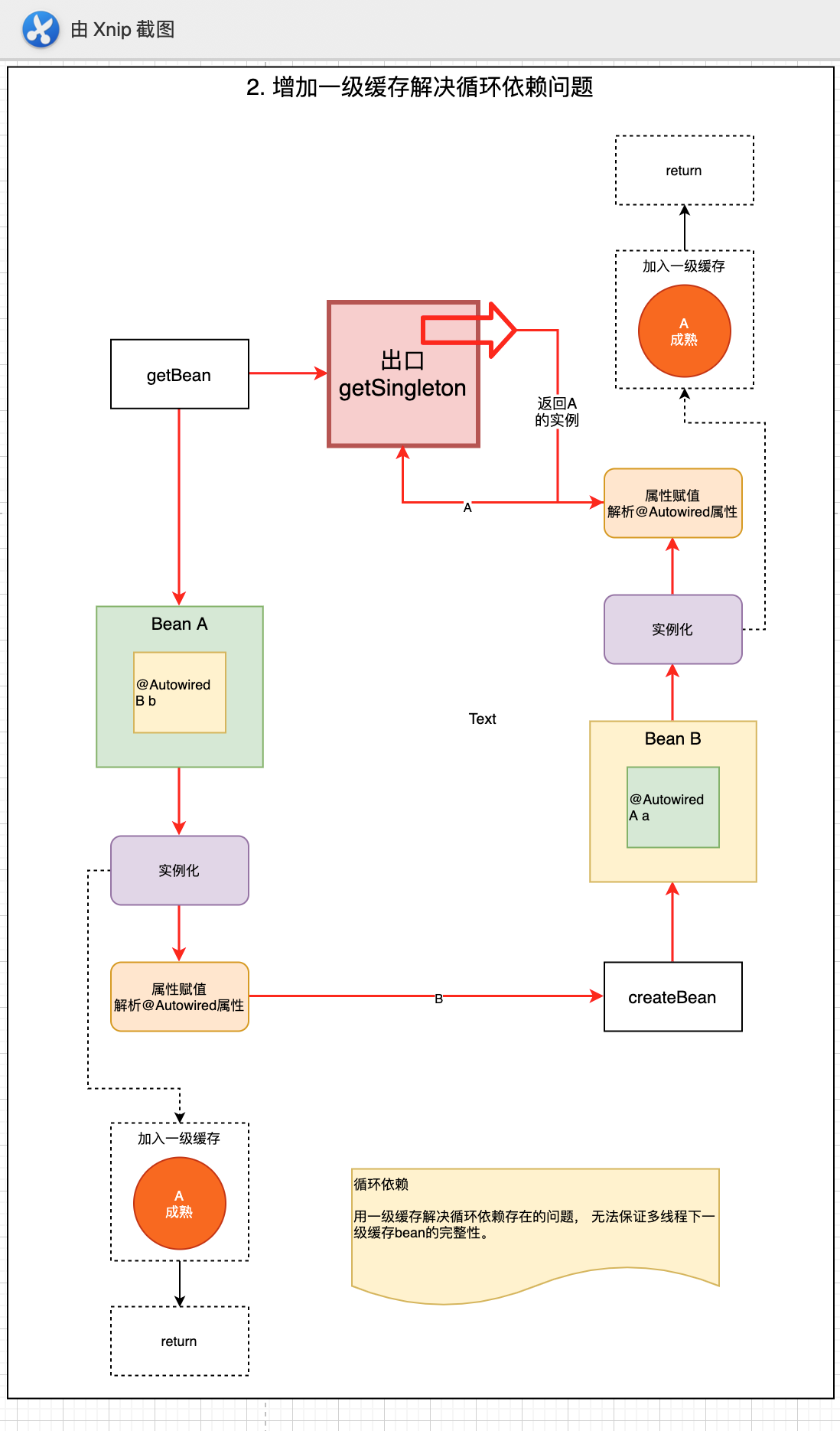
如上图所示, 在@Autowired的时候, 增加了一个出口. 判断即将要创建的类是否已经存在, 如果存在了, 那么就直接返回, 不在创建
虽然使用了一级缓存解决了循环依赖的问题, 但要是在多线程下, 这个依赖可能就会出现问题.
比如: 有两个线程, 同时创建instanceA 和instanceB, instanceA和instanceB都引用了instanceC. 他们同步进行, 都去创建instanceC. 首先A去创建, A在实例化instanceC以后就将其放入到一级缓存了, 这时候, B去一级缓存里拿. 此时拿到的instanceC是不完整的. 后面的属性赋值, 初始化都还没有执行呢. 所以, 我们增加二级缓存来解决这个问题.
5. 增加二级缓存, 区分完整的bean和纯净的bean.
public class MainStart { private static Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(); // 一级缓存 private static Map<String, Object> singletonObjects = new ConcurrentHashMap<>(); // 二级缓存 private static Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(); /** * 读取bean定义, 当然在spring中肯定是根据配置 动态扫描注册的 * * InstanceA和InstanceB都有注解@Component, 所以, 在spring扫描读取配置类的时候, 会把他们两个扫描到BeanDefinitionMap中. * 这里, 我们省略这一步, 直接将instanceA和instanceB放到BeanDefinitionMap中. */ public static void loadBeanDefinitions(){ RootBeanDefinition aBeanDefinition = new RootBeanDefinition(InstanceA.class); RootBeanDefinition bBeanDefinition = new RootBeanDefinition(InstanceB.class); beanDefinitionMap.put("instanceA", aBeanDefinition); beanDefinitionMap.put("instanceB", bBeanDefinition); } public static void main(String[] args) throws Exception { // 第一步: 扫描配置类, 读取bean定义 loadBeanDefinitions(); // 第二步: 循环创建bean for (String key: beanDefinitionMap.keySet()) { // 第一次: key是instanceA, 所以先创建A类 getBean(key); } // 测试: 看是否能执行成功 InstanceA instanceA = (InstanceA) getBean("instanceA"); instanceA.say(); } /** * 获取bean, 根据beanName获取 */ public static Object getBean(String beanName) throws Exception { // 增加一个出口. 判断实体类是否已经被加载过了 Object singleton = getSingleton(beanName); if (singleton != null) { return singleton; } /** * 第一步: 实例化 * 我们这里是模拟, 采用反射的方式进行实例化. 调用的也是最简单的无参构造函数 */ RootBeanDefinition beanDefinition = (RootBeanDefinition) beanDefinitionMap.get(beanName); Class<?> beanClass = beanDefinition.getBeanClass(); // 调用无参的构造函数进行实例化 Object instanceBean = beanClass.newInstance(); /** * 第二步: 放入到二级缓存 */ earlySingletonObjects.put(beanName, instanceBean); /** * 第三步: 属性赋值 * instanceA这类类里面有一个属性, InstanceB. 所以, 先拿到 instanceB, 然后在判断属性头上有没有Autowired注解. * 注意: 这里我们只是判断有没有Autowired注解. spring中还会判断有没有@Resource注解. @Resource注解还有两种方式, 一种是name, 一种是type */ Field[] declaredFields = beanClass.getDeclaredFields(); for (Field declaredField: declaredFields) { // 判断每一个属性是否有@Autowired注解 Autowired annotation = declaredField.getAnnotation(Autowired.class); if (annotation != null) { // 设置这个属性是可访问的 declaredField.setAccessible(true); // 那么这个时候还要构建这个属性的bean. /* * 获取属性的名字 * 真实情况, spring这里会判断, 是根据名字, 还是类型, 还是构造函数来获取类. * 我们这里模拟, 所以简单一些, 直接根据名字获取. */ String name = declaredField.getName(); /** * 这样, 在这里我们就拿到了 instanceB 的 bean */ Object fileObject = getBean(name); // 为属性设置类型 declaredField.set(instanceBean, fileObject); } } /** * 第四步: 初始化 * 初始化就是设置类的init-method.这个可以设置也可以不设置. 我们这里就不设置了 */ /** * 第二步: 放入到一级缓存 */ singletonObjects.put(beanName, instanceBean); return instanceBean; } /** * 判断是否是循环引用的出口. * @param beanName * @return */ private static Object getSingleton(String beanName) { // 先去一级缓存里拿,如果一级缓存没有拿到,去二级缓存里拿 if (singletonObjects.containsKey(beanName)) { return singletonObjects.get(beanName); } else if (earlySingletonObjects.containsKey(beanName)){ return earlySingletonObjects.get(beanName); } else { return null; } } }
如上图所示,增加了一个二级缓存. 首先, 构建出instanceBean以后, 直接将其放入到二级缓存中. 这时只是一个纯净的bean, 里面还没有给属性赋值, 初始化. 在给属性赋值完成, 初始化完成以后, 在将其放入到一级缓存中.
我们判断缓存中是否有某个实例bean的时候, 先去一级缓存中判断是否有完整的bean, 如果没有, 就去二级缓存中判断有没有实例化过这个bean.
总结: 一级缓存和二级缓存的作用
一级缓存: 解决循环依赖的问题
二级缓存: 在创建实例bean和放入到一级缓存之间还有一段间隙. 如果在这之间从一级缓存拿实例, 肯定是返回null的. 为了避免这个问题, 增加了二级缓存.
我们都知道spring中有一级缓存, 二级缓存, 三级缓存. 一级缓存和二级缓存的作用我们知道了, 那么三级缓存有什么用呢?
6. 增加三级缓存
三级缓存有什么作用呢? 这个问题众说纷纭, 有说代理, 有说AOP. 其实AOP的问题可以用二级缓存来解决. 下面就来看看AOP如何用二级缓存解决.
创建AOP动态代理 (不是耦合的, 采用解耦的, 通过BeanPostProcessor bean的后置处理器来创建). 之前讲过, 如下图
在初始化之后, 调用Bean的后置处理器去创建的AOP的动态代理
如上图. 我们在创建bean 的时候, 会有很多Bean的后置处理器BeanPostProcessor. 如果有AOP, 会在什么时候创建呢? 在初始化以后, 调用BeanPostProcessor创建动态代理.
结合上面的代码, 我们想一想, 其实在初始化以后创建动态代理就晚了. 为什么呢? 因为, 如果有循环依赖, 在初始化之后才调用, 那就不是动态代理. 其实我们这时候应该在实例化之后, 放入到二级缓存之前调用
面试题: 在创建bean的时候, 在哪里创建的动态代理, 这个应该怎么回答呢? 很多人会说在初始化之后, 或者在实例化之后. 其实更严谨的说, 有两种情况: 第一种是在初始化之后调用 . 第二种是出现了循环依赖, 会在实例化之后调用
我们上面说的就是第二种情况. 也就是说,正常情况下是在初始化之后调用的, 但是如果有循环依赖, 就要在实例化之后调用了.
下面来看看如何在二级缓存加动态代理.
首先, 我们这里有循环依赖, 所以将动态代理放在实例化之后,
/** * 获取bean, 根据beanName获取 */ public static Object getBean(String beanName) throws Exception { // 增加一个出口. 判断实体类是否已经被加载过了 Object singleton = getSingleton(beanName); if (singleton != null) { return singleton; } /** * 第一步: 实例化 * 我们这里是模拟, 采用反射的方式进行实例化. 调用的也是最简单的无参构造函数 */ RootBeanDefinition beanDefinition = (RootBeanDefinition) beanDefinitionMap.get(beanName); Class<?> beanClass = beanDefinition.getBeanClass(); // 调用无参的构造函数进行实例化 Object instanceBean = beanClass.newInstance(); /** * 创建AOP动态代理 (不是耦合的, 采用解耦的, 通过BeanPostProcessor bean的后置处理器得来的. 之前讲过, * 在初始化之后, 调用Bean的后置处理器去创建的AOP的动态代理 ) */ instanceBean = new JdkProxyBeanPostProcessor().getEarlyBeanReference(instanceBean, "instanceA"); /** * 第二步: 放入到二级缓存 */ earlySingletonObjects.put(beanName, instanceBean); /** * 第三步: 属性赋值 * instanceA这类类里面有一个属性, InstanceB. 所以, 先拿到 instanceB, 然后在判断属性头上有没有Autowired注解. * 注意: 这里我们只是判断有没有Autowired注解. spring中还会判断有没有@Resource注解. @Resource注解还有两种方式, 一种是name, 一种是type */ Field[] declaredFields = beanClass.getDeclaredFields(); for (Field declaredField: declaredFields) { // 判断每一个属性是否有@Autowired注解 Autowired annotation = declaredField.getAnnotation(Autowired.class); if (annotation != null) { // 设置这个属性是可访问的 declaredField.setAccessible(true); // 那么这个时候还要构建这个属性的bean. /* * 获取属性的名字 * 真实情况, spring这里会判断, 是根据名字, 还是类型, 还是构造函数来获取类. * 我们这里模拟, 所以简单一些, 直接根据名字获取. */ String name = declaredField.getName(); /** * 这样, 在这里我们就拿到了 instanceB 的 bean */ Object fileObject = getBean(name); // 为属性设置类型 declaredField.set(instanceBean, fileObject); } } /** * 第四步: 初始化 * 初始化就是设置类的init-method.这个可以设置也可以不设置. 我们这里就不设置了 */ // 正常动态代理创建的时机 /** * 第五步: 放入到一级缓存 */ singletonObjects.put(beanName, instanceBean); return instanceBean; }
这里只是简单模拟了动态代理.
我们知道动态代理有两个地方. 如果是普通类动态代理在初始化之后执行, 如果是循环依赖, 那么动态代理是在实例化之后.
上面在实例化之后创建proxy的代码不完整, 为什么不完整呢, 因为没有判断是否是循环依赖.
我们简单模拟一个动态代理的实现.
public class JdkProxyBeanPostProcessor implements SmartInstantiationAwareBeanPostProcessor { /** * 假设A被切点命中 需要创建代理 @PointCut("execution(* *..InstanceA.*(..))") * @param bean the raw bean instance * @param beanName the name of the bean * @return * @throws BeansException */ @Override public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException { // 假设A被切点命中 需要创建代理 @PointCut("execution(* *..InstanceA.*(..))") /** * 这里, 我们简单直接判断bean是不是InstanceA实例, 如果是, 就创建动态代理. * 这里没有去解析切点, 解析切点是AspectJ做的事. */ if (bean instanceof InstanceA) { JdkDynimcProxy jdkDynimcProxy = new JdkDynimcProxy(bean); return jdkDynimcProxy.getProxy(); } return bean; } }
这里直接判断, 如果bean是InstanceA的实例, 那么就调用bean的动态代理. 动态代理的简单逻辑就是: 解析切面, 然后创建类, 如果类不存在就新增, 如果存在则不在创建, 直接取出来返回.
在来看看动态代理,放在实例化之后. 创建AOP, 但是, 在这里创建AOP动态代理的条件是循环依赖.
问题1: 那么如何判断是循环依赖呢?
二级缓存中bean不是null.
如果一个类在创建的过程中, 会放入到二级缓存, 如果完全创建完了, 会放入到一级缓存, 然后删除二级缓存. 所以, 如果二级缓存中的bean只要存在, 就说明这个类是创建中, 出现了循环依赖.
问题2: 什么时候判断呢?
应该在getSingleton()判断是否是循环依赖的时候判断. 因为这时候我们刚好判断了二级缓存中bean是否为空.
/** * 判断是否是循环引用的出口. * @param beanName * @return */ private static Object getSingleton(String beanName) { // 先去一级缓存里拿,如果一级缓存没有拿到,去二级缓存里拿 if (singletonObjects.containsKey(beanName)) { return singletonObjects.get(beanName); } else if (earlySingletonObjects.containsKey(beanName)){ /** * 第一次创建bean是正常的instanceBean. 他并不是循环依赖. 第二次进来判断, 这个bean已经存在了, 就说明是循环依赖了 * 这时候通过动态代理创建bean. 然后将这个bean在放入到二级缓存中覆盖原来的instanceBean. */ Object obj = new JdkProxyBeanPostProcessor() .getEarlyBeanReference(earlySingletonObjects.get(beanName), beanName); earlySingletonObjects.put(beanName, obj); return earlySingletonObjects.get(beanName); } else { return null; } }
这样我们在循环依赖的时候就完成了AOP的创建. 这是在二级缓存里创建的AOP,
问题3: 那这是不是说就不需要三级缓存了呢?
那么,来找问题. 这里有两个问题:
问题1: 我们发现在创建动态代理的时候, 我们使用的bean的后置处理器JdkProxyBeanPostProcessor.这有点不太符合规则,
因为, spring在getBean()的时候并没有使用Bean的后置处理器, 而是在createBean()的时候才去使用的bean的后置处理器.
问题2: 如果A是AOP, 他一直都是, 最开始创建的时候也应该是. 使用这种方法, 结果是第一次创建出来的bean不是AOP动态代理.
对于第一个问题: 我们希望在实例化的时候创建AOP, 但是具体判断是在getSingleton()方法里判断. 这里通过三级缓存来实现. 三级缓存里面放的是一个接口定义的钩子方法. 方法的执行在后面调用的时候执行.
对于第二个问题: 我们的二级缓存就不能直接保存instanceBean实例了, 增加一个参数, 用来标记当前这个类是一个正在创建中的类. 这样来判断循环依赖.
下面先来看看创建的三个缓存和一个标识
// 一级缓存 private static Map<String, Object> singletonObjects = new ConcurrentHashMap<>(); // 二级缓存: 为了将成熟的bean和纯净的bean分离. 避免读取到不完整的bean. private static Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(); // 三级缓存: private static Map<String, ObjectFactory> singletonFactories = new ConcurrentHashMap<>(); // 循环依赖的标识---当前正在创建的实例bean private static Set<String> singletonsCurrectlyInCreation = new HashSet<>();
然后在来看看循环依赖的出口
/** * 判断是否是循环引用的出口. * @param beanName * @return */ private static Object getSingleton(String beanName) { //先去一级缓存里拿 Object bean = singletonObjects.get(beanName); // 一级缓存中没有, 但是正在创建的bean标识中有, 说明是循环依赖 if (bean == null && singletonsCurrectlyInCreation.contains(beanName)) { bean = earlySingletonObjects.get(beanName); // 如果二级缓存中没有, 就从三级缓存中拿 if (bean == null) { // 从三级缓存中取 ObjectFactory objectFactory = singletonFactories.get(beanName); if (objectFactory != null) { // 这里是真正创建动态代理的地方. Object obj = objectFactory.getObject(); // 然后将其放入到二级缓存中. 因为如果有多次依赖, 就去二级缓存中判断. 已经有了就不在再次创建了 earlySingletonObjects.put(beanName, obj); } } } return bean; }
这里的逻辑是, 先去一级缓存中拿, 一级缓存放的是成熟的bean, 也就是他已经完成了属性赋值和初始化. 如果一级缓存没有, 而正在创建中的类标识是true, 就说明这个类正在创建中, 这是一个循环依赖. 这个时候就去二级缓存中取数据, 二级缓存中的数据是何时放进去的呢, 是后面从三级缓存中创建动态代理后放进去的. 如果二级缓存为空, 说明没有创建过动态代理, 这时候在去三级缓存中拿, 然后创建动态代理. 创建完以后放入二级缓存中, 后面就不用再创建.
完成的代码如下:
package com.lxl.www.circulardependencies; import org.springframework.beans.BeansException; import org.springframework.beans.factory.annotation.Autowire; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.config.BeanDefinition; import org.springframework.beans.factory.support.RootBeanDefinition; import java.lang.reflect.Field; import java.util.HashSet; import java.util.Map; import java.util.Set; import java.util.concurrent.ConcurrentHashMap; public class MainStart { private static Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(); // 一级缓存 private static Map<String, Object> singletonObjects = new ConcurrentHashMap<>(); // 二级缓存: 为了将成熟的bean和纯净的bean分离. 避免读取到不完整的bean. private static Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(); // 三级缓存: private static Map<String, ObjectFactory> singletonFactories = new ConcurrentHashMap<>(); // 循环依赖的标识---当前正在创建的实例bean private static Set<String> singletonsCurrectlyInCreation = new HashSet<>(); /** * 读取bean定义, 当然在spring中肯定是根据配置 动态扫描注册的 * * InstanceA和InstanceB都有注解@Component, 所以, 在spring扫描读取配置类的时候, 会把他们两个扫描到BeanDefinitionMap中. * 这里, 我们省略这一步, 直接将instanceA和instanceB放到BeanDefinitionMap中. */ public static void loadBeanDefinitions(){ RootBeanDefinition aBeanDefinition = new RootBeanDefinition(InstanceA.class); RootBeanDefinition bBeanDefinition = new RootBeanDefinition(InstanceB.class); beanDefinitionMap.put("instanceA", aBeanDefinition); beanDefinitionMap.put("instanceB", bBeanDefinition); } public static void main(String[] args) throws Exception { // 第一步: 扫描配置类, 读取bean定义 loadBeanDefinitions(); // 第二步: 循环创建bean for (String key: beanDefinitionMap.keySet()) { // 第一次: key是instanceA, 所以先创建A类 getBean(key); } // 测试: 看是否能执行成功 InstanceA instanceA = (InstanceA) getBean("instanceA"); instanceA.say(); } /** * 获取bean, 根据beanName获取 */ public static Object getBean(String beanName) throws Exception { // 增加一个出口. 判断实体类是否已经被加载过了 Object singleton = getSingleton(beanName); if (singleton != null) { return singleton; } // 标记bean正在创建 if (!singletonsCurrectlyInCreation.contains(beanName)) { singletonsCurrectlyInCreation.add(beanName); } /** * 第一步: 实例化 * 我们这里是模拟, 采用反射的方式进行实例化. 调用的也是最简单的无参构造函数 */ RootBeanDefinition beanDefinition = (RootBeanDefinition) beanDefinitionMap.get(beanName); Class<?> beanClass = beanDefinition.getBeanClass(); // 调用无参的构造函数进行实例化 Object instanceBean = beanClass.newInstance(); /** * 第二步: 放入到三级缓存 * 每一次createBean都会将其放入到三级缓存中. getObject是一个钩子方法. 在这里不会被调用. * 什么时候被调用呢? * 在getSingleton()从三级缓存中取数据, 调用创建动态代理的时候 */ singletonFactories.put(beanName, new ObjectFactory() { @Override public Object getObject() throws BeansException { return new JdkProxyBeanPostProcessor().getEarlyBeanReference(earlySingletonObjects.get(beanName), beanName); } }); //earlySingletonObjects.put(beanName, instanceBean); /** * 第三步: 属性赋值 * instanceA这类类里面有一个属性, InstanceB. 所以, 先拿到 instanceB, 然后在判断属性头上有没有Autowired注解. * 注意: 这里我们只是判断有没有Autowired注解. spring中还会判断有没有@Resource注解. @Resource注解还有两种方式, 一种是name, 一种是type */ Field[] declaredFields = beanClass.getDeclaredFields(); for (Field declaredField: declaredFields) { // 判断每一个属性是否有@Autowired注解 Autowired annotation = declaredField.getAnnotation(Autowired.class); if (annotation != null) { // 设置这个属性是可访问的 declaredField.setAccessible(true); // 那么这个时候还要构建这个属性的bean. /* * 获取属性的名字 * 真实情况, spring这里会判断, 是根据名字, 还是类型, 还是构造函数来获取类. * 我们这里模拟, 所以简单一些, 直接根据名字获取. */ String name = declaredField.getName(); /** * 这样, 在这里我们就拿到了 instanceB 的 bean */ Object fileObject = getBean(name); // 为属性设置类型 declaredField.set(instanceBean, fileObject); } } /** * 第四步: 初始化 * 初始化就是设置类的init-method.这个可以设置也可以不设置. 我们这里就不设置了 */ /** * 第五步: 放入到一级缓存 * * 在这里二级缓存存的是动态代理, 那么一级缓存肯定也要存动态代理的实例. * 从二级缓存中取出实例, 放入到一级缓存中 */ if (earlySingletonObjects.containsKey(beanName)) { instanceBean = earlySingletonObjects.get(beanName); } singletonObjects.put(beanName, instanceBean); return instanceBean; } /** * 判断是否是循环引用的出口. * @param beanName * @return */ private static Object getSingleton(String beanName) { //先去一级缓存里拿, Object bean = singletonObjects.get(beanName); // 一级缓存中没有, 但是正在创建的bean标识中有, 说明是循环依赖 if (bean == null && singletonsCurrectlyInCreation.contains(beanName)) { bean = earlySingletonObjects.get(beanName); // 如果二级缓存中没有, 就从三级缓存中拿 if (bean == null) { // 从三级缓存中取 ObjectFactory objectFactory = singletonFactories.get(beanName); if (objectFactory != null) { // 这里是真正创建动态代理的地方. Object obj = objectFactory.getObject(); // 然后将其放入到二级缓存中. 因为如果有多次依赖, 就去二级缓存中判断. 已经有了就不在再次创建了 earlySingletonObjects.put(beanName, obj); } } } return bean; } }

下面就我们的代码分析一下:
第一种情况: 没有循环依赖
第二种情况: 有循环依赖
第三种情况: 有多次循环依赖
我们模拟一个循环依赖的场景, 覆盖这三种情况.
用代码表示
类A
package com.lxl.www.circulardependencies; import org.springframework.beans.factory.annotation.Autowired; public class A { @Autowired private B b; @Autowired private C c; }
类B
package com.lxl.www.circulardependencies; import org.springframework.beans.factory.annotation.Autowired; public class B { @Autowired private A a; @Autowired private B b; }
类C
package com.lxl.www.circulardependencies; import org.springframework.beans.factory.annotation.Autowired; public class C { @Autowired private A a; }
其中类A刚好匹配AOP的切面@PointCut("execution(* *..A.*(..))")
下面分析他们的循环依赖关系.
此时beanDefinitionMap中有三个bean定义. 分别是A, B, C
1. 先解析类A, 根据上面的流程.
1) 首先调用getSingleton, 此时一级缓存, 二级缓存都没有, 正在创建标志也是null. 所以, 返回的是null
2) 标记当前类正在创建中
3) 实例化
4) 将A放入到三级缓存, 并定义动态代理的钩子方法
5) 属性赋值. A有两个属性, 分别是B和C. 都带有@Autowired注解, 先解析B.
6) A暂停, 解析B
2. 解析A类的属性类B
1) 首先调用getSingleton, 此时一级缓存, 二级缓存都没有, 正在创建标志也是null. 所以, 返回的是null
2) 标记当前类正在创建中
3) 实例化
4) 将B放入到三级缓存, 并定义动态代理的钩子方法
5) 属性赋值. B有两个属性, 分别是A和C. 都带有@Autowired注解, 先解析A. 在解析C
6) B暂停, 解析A
3. 解析B类的属性A
1) 首先调用getSingleton, 此时一级缓存中这个属性为null, 正在创建中标志位true, 二级缓存为空, 从三级缓存中创建动态代理, 然后判断是否符合动态代理切面要求, A符合. 所以通过动态代理创建A的代理bean放入到二级缓存. 返回实例bean.
2) A此时已经存在了, 所以, 直接返回
4. 解析B类的属性C
1) 首先调用getSingleton, 此时一级缓存, 二级缓存都没有, 正在创建标志也是null. 所以, 返回的是null
2) 标记当前类C正在创建中
3) 实例化
4) 将C放入到三级缓存, 并定义动态代理的钩子方法
5) 属性赋值. C有一个属性, 是A. 带有@Autowired注解, 先解析A
6) C暂停, 解析A
5. 解析C中的属性A
1) 首先调用getSingleton()方法, 此时一级缓存中没有, 标志位为true, 二级缓存中已经有A的动态代理实例了, 所以,直接返回.
2) A此时已经在存在, 直接返回
6. 继续解析B类的属性C
1) 接着第4步往下走
2) 初始化类C
3) 将类C放入到一级缓存中. 放之前去二级缓存中取, 二级缓存中没有. 所以, 这里存的是C通过反射构建的instanceBean
7. 继续解析A类的属性类B
1) 接着第2步往下走
2) 初始化类B
3) 将类B放入到一级缓存中. 放之前去二级缓存中取.二级缓存中没有, 所以, 这里存的是B通过反射构建的instanceBean
4) 构建结束,返回
8. 解析A类的属性类C
1) 首先调用getSingleton()方法, 此时一级缓存中已经有了类C, 所以直接返回
9. 继续解析A类
1) 接着第1步往下走
2) 初始化类A
3) 将A放入到一级缓存中. 放之前判断二级缓存中有没有实例bean, 我们发现有, 所以, 取出来放入到A的一级缓存中.
4) 构建bean结束, 返回
10. 接下来构建beanDefinitionMap中的类B
1) 首先调用getSingleton()方法, 此时一级缓存中已经有了类B, 所以直接返回
11. 接下来构建beanDefinitionMap中的类C
1) 首先调用getSingleton()方法, 此时一级缓存中已经有了类C, 所以直接返回
至此整个构建过程结束.
总结:
再来感受一下三级缓存的作用:
一级缓存: 用来存放成熟的bean. 这个bean如果是切入点, 则是一个动态代理的bean,如果不是切入点, 则是一个普通的类
二级缓存: 用来存放循环依赖过程中创建的动态代理bean.
三级缓存: 用来存放动态代理的钩子方法. 用来在需要构建动态代理类的时候使用.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号