1.操作系统底层工作的基本原理
一. 计算机的五大组成部分
1. 控制器(Control):
2. 运算器(Datapath):
3. 存储器(Memory):
4. 输入(Input system):
5. 输出(Output system):
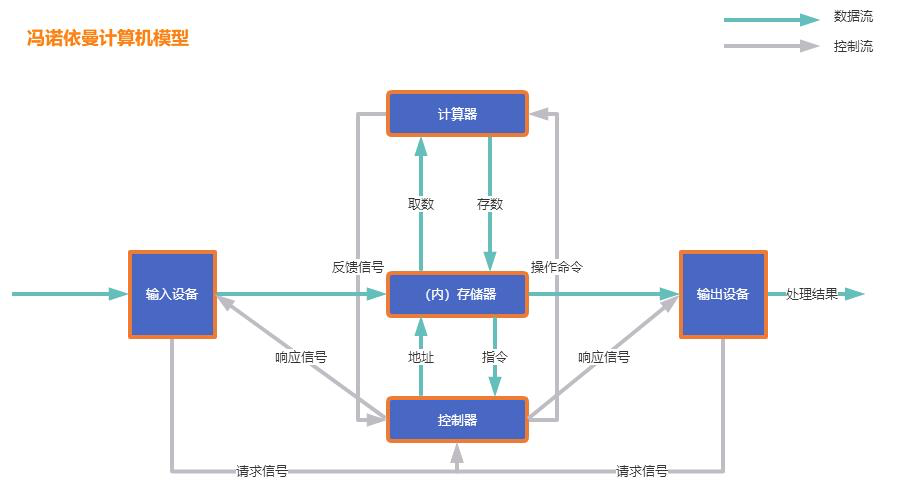
输入设备和输出设备是如何工作的呢?
在电路板里,尤其是在cpu包含了大量的电路, 电路是根据电流的高低压进行判断, 根据电流的开/关不同, 会影响电信号的强度, 这样就会导致两种以结果, 一种是关闭了,还是没关闭. 关闭了是0, 没关闭是1. 所以为什么cpu只认0和1, 也是因为这个原因.
其实电路板, 我们都可以自制. 如何自制呢?
其实就是在一块板子上, 镀了一层铜膜, 然后设计电路, 在一类特殊类型的纸上设计, 设计好了以后, 把纸贴到镀了铜的电路板上去. 纸上有我们设计好的电路, 然后把这个板子丢到化学反应池里, 然后没有贴特殊纸的地方将会发生化学反应,把没有贴到线路的铜膜擦掉
上面的模型是一个理论的抽象简化模型,它的具体应用就是现代计算机当中的硬件结构设计:
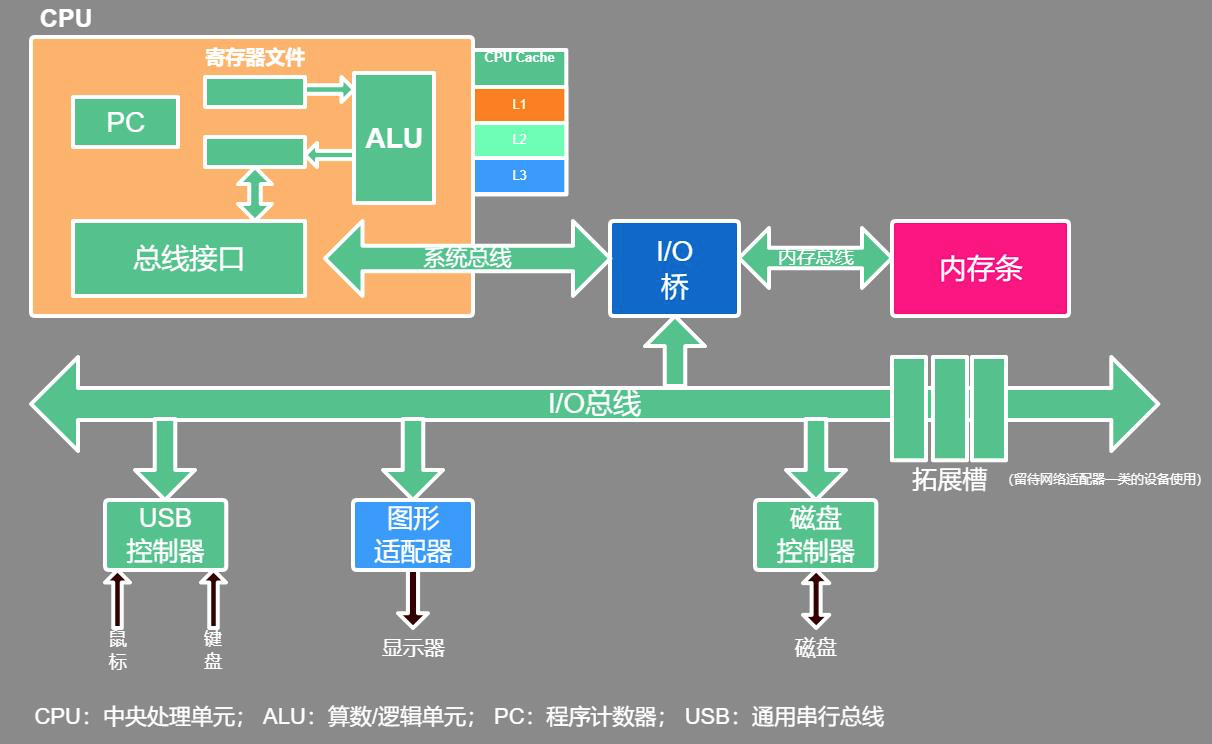
现代计算机的构成主要有
- CPU
- 主板
- 内存条
- 硬盘
- 电源
一台电脑中, 上面这五个就是核心设备了,有了这5个,一台计算机就可以工作了.显卡,键盘,鼠标,网卡,都可以没有
cpu是非常重要的, 对于cpu我们需要重点了解两个方面的内容
1. cpu是如何工作的.
2. cpu是如何和内存进行通讯的.
计算机主板上有很多的插槽,其中一部分是放cpu的,另一部分是放内存条的. 那么cpu和内存条怎么通信呢?
cpu和内存条都是插在主板上的,他们并不在一块. 那么他们想要通信, 就要通过信道, 信道, 我们又可以叫做内存总线, 系统总线, IO总线. 他们是通过总线进行通讯的
二. CPU
2.1 CPU内部结构
cpu的内部构造很复杂, 主要有3个单元.
-
控制单元
- 运算单元
-
数据单元
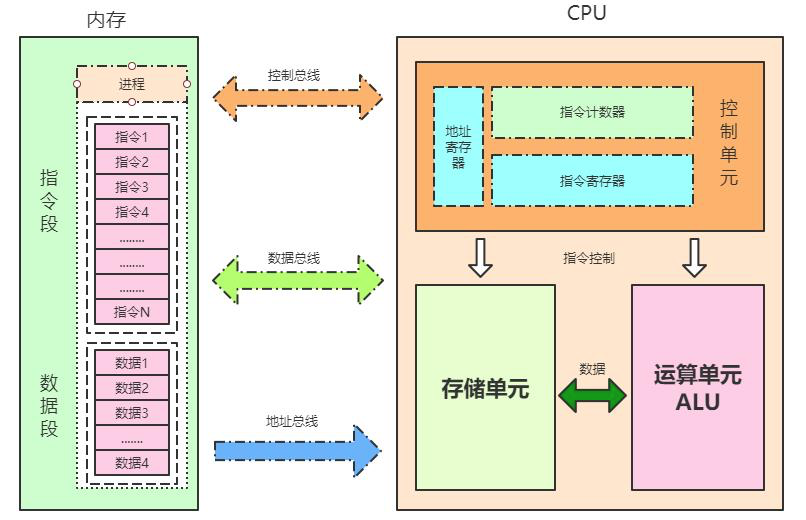
最直接操作计算机的是什么语言? 是汇编语言
2.1.1 控制单元
2.1.2运算单元
2.1.3 存储单元
2.2 CPU缓存结构
cpu对于计算机, 就像我们人的大脑.
常见的为三级缓存结构
-
L1 Cache,分为数据缓存和指令缓存,逻辑核独占
-
L2 Cache,物理核独占,逻辑核共享
-
L3 Cache,所有物理核共享
2.2.1 cpu为什么需要缓存呢?
根据摩尔定律, cpu的性能, 大概每过18个月, 性能就会翻一番. cpu从90年代到2020年, 经过了20多年的发展, 现在基本上进入了性能过剩的时代.
但是内存,经过了很多年的发展, 却没有什么摩尔定律, 我们知道内存从原来的DDR2 发展到 DDR3, 有发展到DDR4, 到现在的DDR5, 其实这个变化并没有那么大
所以就造成了失衡的问题. 内存的速度远远跟不上CPU的速度了, 而每一次计算CPU都要去内存里拿数据, 这样太耗费时间了. 所以, 为了解决这个问题, CPU增加了多级缓存. 增加多级缓存目的就是为了减少与内存的交互
2.2.2来看一下我们使用的计算机
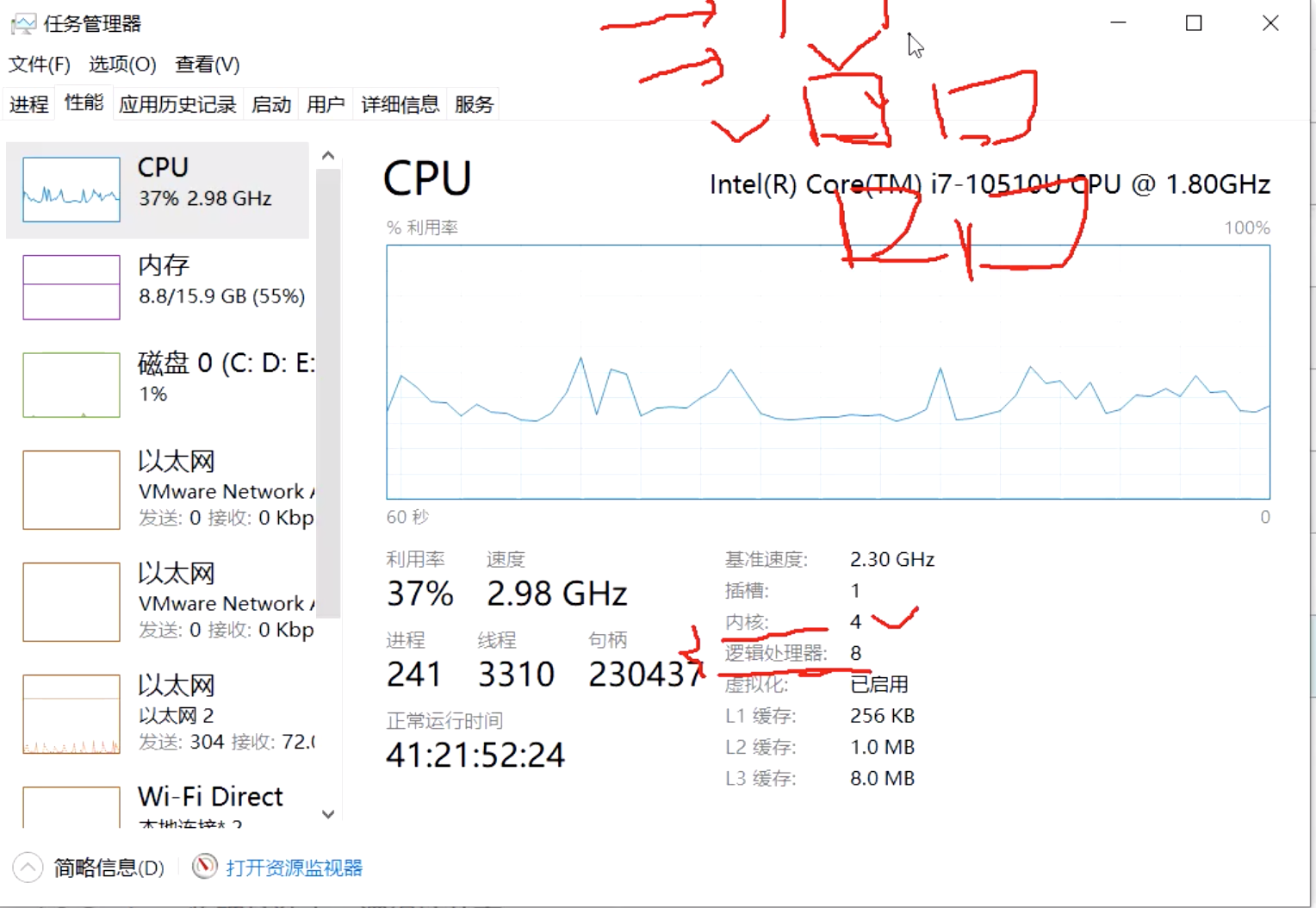
看看这个计算机的基本信息, 此计算机有一个CPU. 那么这一个和我们之前说的1核,2核是一回事么? 不是一回事
.根据计算能力, 一台电脑可以安装一个或多个CPU, CPU越多, 计算的速度相应的也会越快, 每个CPU可以有一核或者多核
问题: 现在有一个线程, 运行在4个cpu上, 和运行在有一个cpu, 但这个cpu有四个核, 哪一个更快呢?显然收前者处理更快. 相应的性价比却低很多.
如上图, 还有内核和虚拟处理器, 一个是4, 一个是8. 这里虚拟处理器的含义是: 原来4核四线程, 那么每个容器可以执行一个线程. 这里虚拟化是指原来一个cpu内核只能跑一个线程, 现在可以跑两个线程了.
2.2.3 CPU的三级缓存
还是看上图, CPU有三级缓存, L1缓存 256kb, L2缓存 1.0MB L3缓存 8.0M L1 < L2 < L3.
L1离CPU是最近的, 离得越近速度越快. M < L3 < L2 < L1 < 寄存器. 数据拷贝的过程是, 从内存拷贝到L3, 在拷贝到L2, 在拷贝到L1, 再拷贝到寄存器.
CPU操作的数据只会去寄存器里面存或者取. 寄存器是每一个cpu独有的. 这个寄存器只能被当前的cpu访问到, 不能被其他cpu访问
2.2.4 三级缓存和cpu有什么关系呢?
- L3是CPU内核共享的, 就是说被当前这个CPU的所有内核共享.
现在有两个CPU, CPU2能不能访问到CPU1的L3缓存呢?
答案是: 不能. 不能跨CPU访问别人的缓存
- L1和L2是每个CPU上各内核独享的.
- 一个内核只有一个L1和一个L2, 在图中我们看到L1有两个, 是因为L1有两个功能, 一个是用来存储指令, 另一个是用来存储数据的. L1只有一个, 只是根据功能将其分为两个部分.
- L1缓存分为两种, 一种用来存储指令, 另一种用来存储数据.
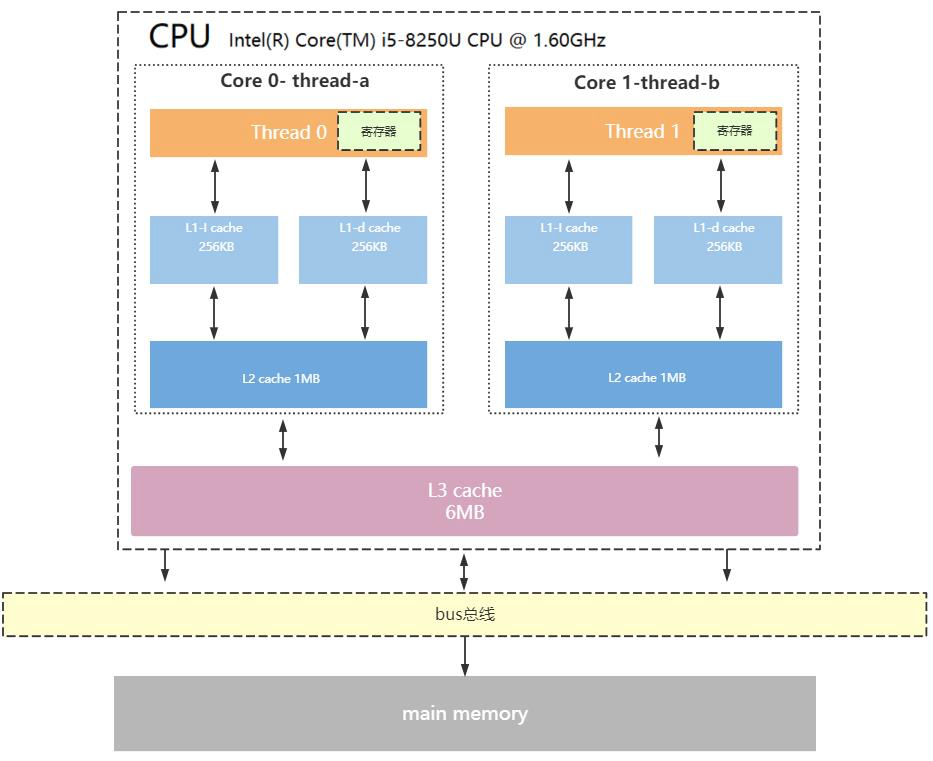
现在大多数计算机的架构都是如上图, 最底下是内存, 然后有一条总线连接cpu和内存条
2.2.5 我们能看到L3缓存有6M, 那么这6M没有一个划分么? 就是一块空间么?
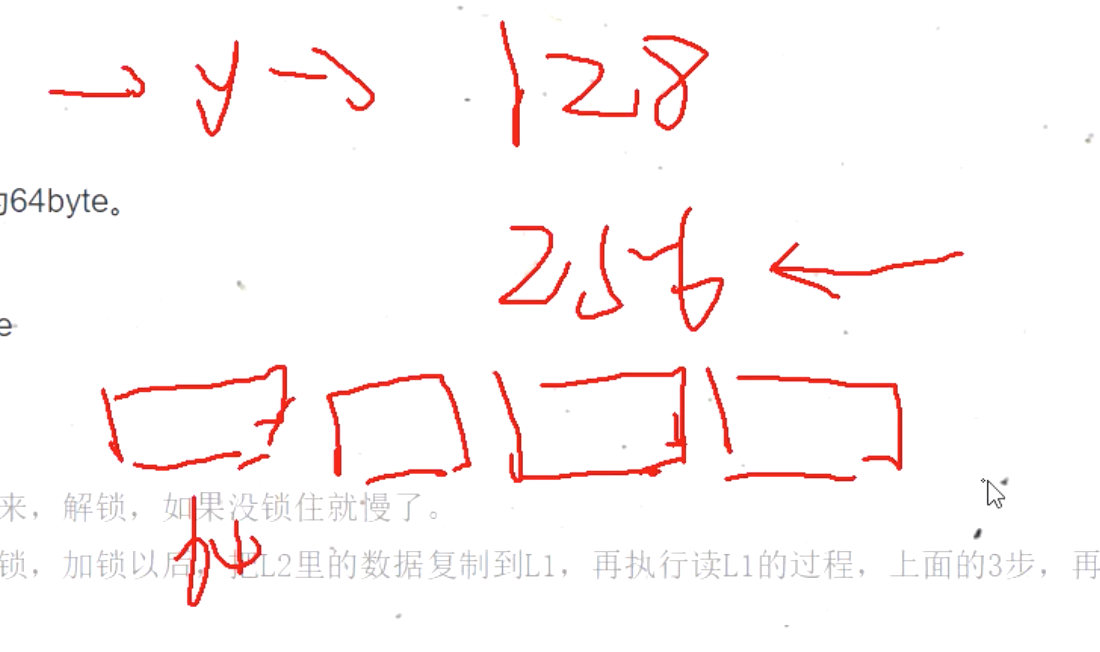
不是的. 缓存也有一个最小的存储单元, 这个最小的存储单元叫做"缓存行" , 通常, 缓存行的大小是64byte, 市面上的cpu基本都是这么大. 那我有一个6M的缓存, 他有多少缓存行呢? 6 * 1024k * 1024b/64.缓存行是什么意思呢?它是CPU缓存中, 最小的空间存储单位, 叫cacheline.
2.2.6 寄存器
2.2.7 缓存行的使用
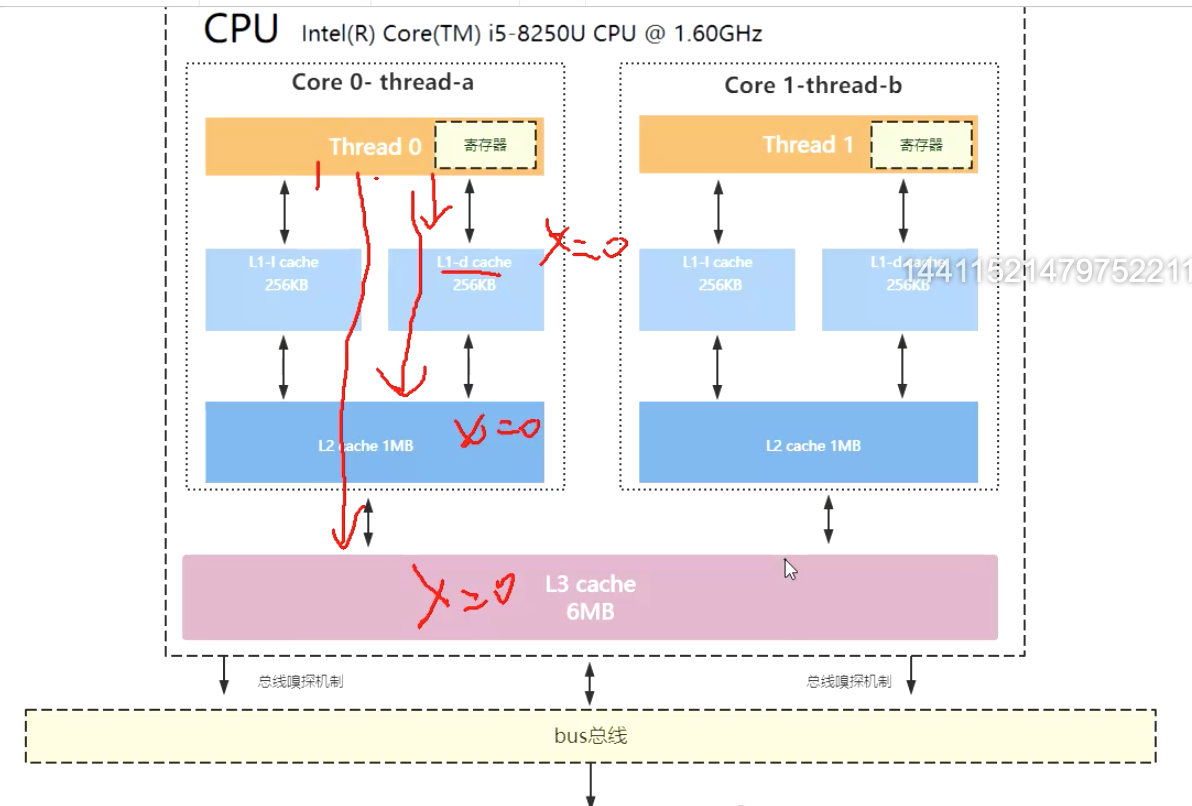
现在cpu要开始计算了, 他需要获取一个x参数, 首先, 他会去L1 一级缓存获取, 一级缓存没有, 再去二级缓存拿, 二级缓存没有再去三级缓存拿, 三级缓存也没有再去内存里找.
在内存找到了x=0, 然后将其拷贝到L3缓存中, 在拷贝到L2缓存, 在拷贝到L1缓存中. 然后在读到寄存器里面去,供cpu使用
如果变量都拷贝到缓存里, 很快就会满了, 最先满的就是L1(他最小嘛) 然后, 他就有一个高淘汰的风险. 因为要腾出地方来给其他变量使用.
加入这个时候,L1中x=0变量被淘汰了, 当cpu需要计算的时候怎么办呢? 没关系, 因为寄存器里面已经有了x=0. 假如寄存器也淘汰了, 怎么办呢? 他去L1也取不到, 那就去L2取, 如果L2也淘汰了,就去L3,总之, 他可以现在3级缓存中取数据, 不用立刻就去内存中取.
2.2.8 CPU读取存储器数据的过程
1、CPU要取寄存器X的值,只需要一步:直接读取。
2、CPU要取L1 cache的某个值,需要1-3步(或者更多):把cache行锁住,把某个数据拿来,解锁,如果没锁住就慢了。
3、CPU要取L2 cache的某个值,先要到L1 cache里取,L1当中不存在,在L2里,L2开始加锁,加锁以后,把L2里的数据复制到L1,再执行读L1的过程,上面的3步,再解锁。
4、CPU取L3 cache的也是一样,只不过先由L3复制到L2,从L2复制到L1,从L1到CPU。
5、CPU取内存则最复杂:通知内存控制器占用总线带宽,通知内存加锁,发起内存读请求,等待回应,回应数据保存到L3(如果没有就到L2),再从L3/2到L1,再从L1到CPU,之后解除总线锁定。
2.2.9 CPU为何要有高速缓存
CPU在摩尔定律的指导下以每18个月翻一番的速度在发展,然而内存和硬盘的发展速度远远不及CPU。这就造成了高性能能的内存和硬盘价格及其昂贵。然而CPU的高度运算需要高速的数据。为了解决这个问题,CPU厂商在CPU中内置了少量的高速缓存以解决I\O速度和CPU运算速度之间的不匹配问题。
在CPU访问存储设备时,无论是存取数据抑或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理。
-
时间局部性(Temporal Locality)
如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。比如循环、递归、方法的反复调用等。
-
空间局部性(Spatial Locality):
如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。比如顺序执行的代码、连续创建的两个对象、数组等。
2.2.9.1 什么是空间局部性原则呢?
我们都知道CPU和内存的交互是很慢的, 所以增加了3级缓存, 那好不容易交互一次, 费了很大劲就取了一个x=0, 是不是很浪费, 所以, CPU在和内存交互的时候, 不是只去x=0, 而是把x变量周边的变量都会取回来. 比如y=1, z=2, n=3. CPU会一次性将这些数据都copy一份到3级缓存里去.
为什么这样做呢?
如果一个变量被引用, 那么将来他附近的变量也会被引用, 因此, cpu会一次性将这些变量全部加载到cpu的缓存中.
如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。比如顺序执行的代码、连续创建的两个对象、数组等。
举个空间局部性原则例子:
package com.alibaba.nacos.test; /** * Description * <p> * </p> * DATE 2020/8/22. * * @author guolujie. */ public class TestSpace { private static Integer RUNS = 10; private static Integer DIMENSION_1 = 1024*1024; private static Integer DIMENSION_2 = 6; private static long[][] longs; public static void main(String[] args) { longs = new long[DIMENSION_1][DIMENSION_2]; for (int i = 0; i < DIMENSION_1; i ++) { for (int j = 0; j < DIMENSION_2; j ++) { longs[i][j] = 1l; } } System.out.println("构建二维数组完毕"); long sum = 0; long beginTime = System.currentTimeMillis(); for(int m = 0; m < RUNS; m ++) { for (int i = 0; i < DIMENSION_1; i++) { for (int j = 0; j < DIMENSION_2; j++) { sum += longs[i][j]; } } } System.out.println("sum1:" + sum); System.out.println("耗时:" + (System.currentTimeMillis() - beginTime)); sum = 0; beginTime = System.currentTimeMillis(); for (int m = 0; m < RUNS; m ++) { for (int i = 0; i < DIMENSION_2; i++) { for (int j = 0; j < DIMENSION_1; j++) { sum += longs[j][i]; } } } System.out.println("sum:" + sum); System.out.println("耗时:" + (System.currentTimeMillis() - beginTime)); } }
执行结果
构建二维数组完毕 sum1:62914560 耗时:179 sum:62914560 耗时:334
我们发现, 同样是遍历二维数组, 但是先遍历哪一个, 得到的结论是不一样的. 为什么会这样呢?
这就是因为空间性原则.
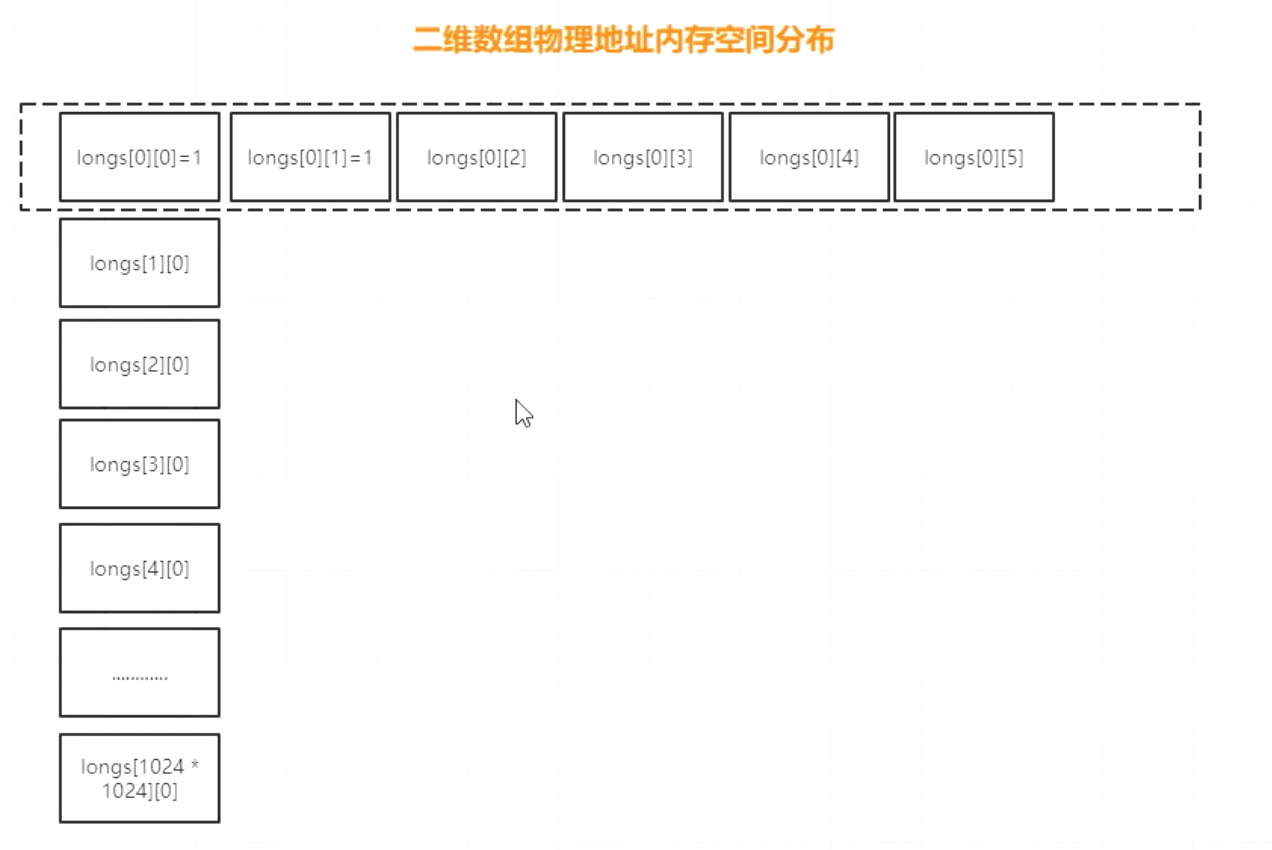
数组一共有1024*1024行, 每一行有6个元素. 这6个元素是连接在一块的. 如果我们先遍历DIMESION_1, 那么, 就是每次循环进行6个数据相加, CPU在读取数据的时候, 因为每一行的6个元素是挨着的, 所以, 根据空间局部性原则, 会一次从内存读取这6个数据, 放入L3缓存中
而如果先遍历EIMESION_2, 也就是每次循环进行1024*1024个数据相加, 但是, 这1024*1024个数据内存分配上是不连续的, 所以, 根据空间局部性原则, 每次只能读取1个数据, 放入L3缓存中
那么对比两次循环, CPU和内存一共交互了多少次呢?
第一个: 交互了1024*1024次
第二个: 交互了1024*1024*6次
所以,第二个耗时比第一个要多.
2.2.9.2 时间局部性原则
什么时间局部性原则呢? 下面举个例子
X = 1 Y = 2 Z = X + Y a = 3 b = 4 c = a + b + X
通常来说, CPU在执行代码的时候, 大多数情况下是按照时间的顺序来执行的(也有不按时间顺序执行的可能), 当CPU执行到X = 1, 并将其放入缓存, 后面执行完 Z = X + Y以后, 会删除掉X么?
他不会立刻就删除, 因为他认为, 后面还有可能会使用到变量X, 这就是时间局部性原则
如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。比如循环、递归、方法的反复调用等。
2.2.10 带有高速缓存的CPU执行计算的流程
-
1. 程序以及数据被加载到主内存
- 2. 指令和数据被加载到CPU的高速缓存
- 3. CPU执行指令,把结果写到高速缓存
- 4. 高速缓存中的数据写回主内存
3. 操作系统内存管理
我们经常听到线程运行的时候, 有线程的上下文切换, 运行状态的切换. 运行状态有分为:内核态和用户态.
通常我们的计算机是64位的, 内存大小在8G及以上.
32位的操作系统, 可用的内存空间是2的32次方. 寻址空间是0 - 2的32次方. 大约是4G.
从操作系统的层面, 对4G的内存做了一个分离, 分离成两个部分, 一个是用户空间, 一个是内核空间
3.1 执行空间保护
操作系统有用户空间与内核空间两个概念,目的也是为了做到程序运行安全隔离与稳定,以32位操作系统4G大小的内存空间为例
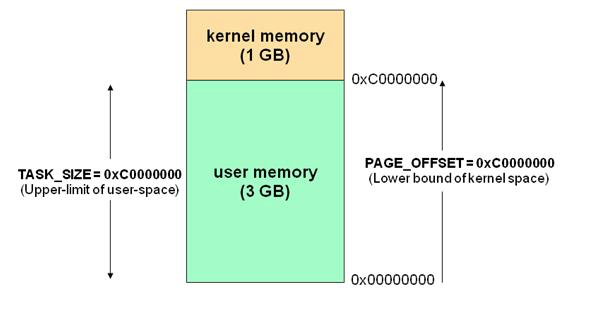
如下图, 4G的空间, 其中有1G是内核空间, 有 3G是用户空间.
- 用户空间: 通常, 我们的JVM, 360浏览器, 各种APP都是运行在用户空间的
- 内核空间: 操作系统是运行在内核空间的.
操作系统跑起来的时候, 就对内存进行了划分和隔离
3.1.1 用户空间和内存空间, 与用户态和内存态有什么区别呢? 他们之间为什么要做隔离呢?
我们将内存划分为内存空间和用户空间, 很大一部分是为了保护用户的操作系统. 什么意思呢?
就拿360浏览器来说, 一会报出一个病毒, 一会报出一个什么什么被劫持了, 很恐怖. 360这款软件能访问什么呢? 他只能访问用户空间, 而不能访问内核空间.
想想一下, 如果360访问了内核空间会怎么样呢? 当我支付宝付款的时候, 其使用的内存被360劫持了, 系统时钟不知道什么时候被360给修改了. 这是不是很恐怖的一件事?
所以, 在CPU里面, 做了一个安全等级的划分.
3.1.2 CPU运行安全等级
Inter将CPU划分为4个级别, 处在不同的安全级别, 能发出不同的安全指令.
CPU有4个运行级别,分别为:
- ring0
- ring1
- ring2
- ring3
其中ring0是安全级别最高的,他就是通常所讲的内核态, CPU处在内核态下, 可以对操作系统执行任何权限级别的操作, 比如:修改内存, 刷磁盘.
通常, CPU都是运行在ring3级别下, 用户态.
那么ring1和ring2有没有用呢?
到目前为止, Linux与Windows只用到了两种级别: ring0、ring3. 其中: 操作系统内部内部程序指令通常运行在ring0级别,操作系统以外的第三方程序运行在ring3级别,第三方程序如果要调用操作系统内部函数功能,由于运行安全级别不够,必须切换CPU运行状态,从ring3切换到ring0,然后执行系统函数,
说到这里, 我们来说说JVM创建线程
JVM创建线程, 归根究底是操作系统去创建的, JVM要调用操作系统的库, 这个库叫做PThread, 而这个库是由操作系统去管理的.
JVM要想调用操作系统的PThread库, 不是轻松就调用的, 结合ring0和ring3我们来分析一下
我们知道JVM是运行在ring3, 用户态. 而操作系统是运行在ring0, 内核态. 这时候JVM要想访问操作系统的库, 就要从ring3用户态切换到ring0内核态.
当JVM从用户态进入到内核态以后, JVM就原来的用户态就不再有了, 而是转移到了内核空间里面. 也就是原来的用户空间的堆栈就都没有了.
所以,我们的一个线程或者进程, 不只有一个堆栈, 而是有两个. 一个在用户态下, 一个在内核态下.
也就是说, 当线程创建出来以后, 都是运行在用户空间的,一旦线程需要阻塞, 或者说要杀死, 那这个时候就要切换了, 从用户态陷入到内核态去, 把原来的堆栈丢了
这就是CPU状态状态的切换
这回就明白为什么JVM创建线程,线程阻塞唤醒是重型操作了,因为CPU要切换运行状态。
下面我大概梳理一下JVM创建线程CPU的工作过程
Linux为内核代码和数据结构预留了几个页框,这些页永远不会被转出到磁盘上。从
0x00000000 到 0xc0000000(PAGE_OFFSET) 的线性地址可由用户代码 和 内核代码进行引用(即用户空间)。从0xc0000000(PAGE_OFFSET)到 0xFFFFFFFFF的线性地址只能由内核代码进行访问(即内核空间)。内核代码及其数据结构都必须位于这 1 GB的地址空间中,但是对于此地址空间而言,更大的消费者是物理地址的虚拟映射。
这意味着在 4 GB 的内存空间中,只有 3 GB 可以用于用户应用程序。进程与线程只能运行在用户方式(usermode)或内核方式(kernelmode)下。用户程序运行在用户方式下,而系统调用运行在内核方式下。在这两种方式下所用的堆栈不一样:用户方式下用的是一般的堆栈(用户空间的堆栈),而内核方式下用的是固定大小的堆栈(内核空间的对战,一般为一个内存页的大小),即每个进程与线程其实有两个堆栈,分别运行与用户态与内核态。
3.2 线程模型
内核线程模型
用户线程模型
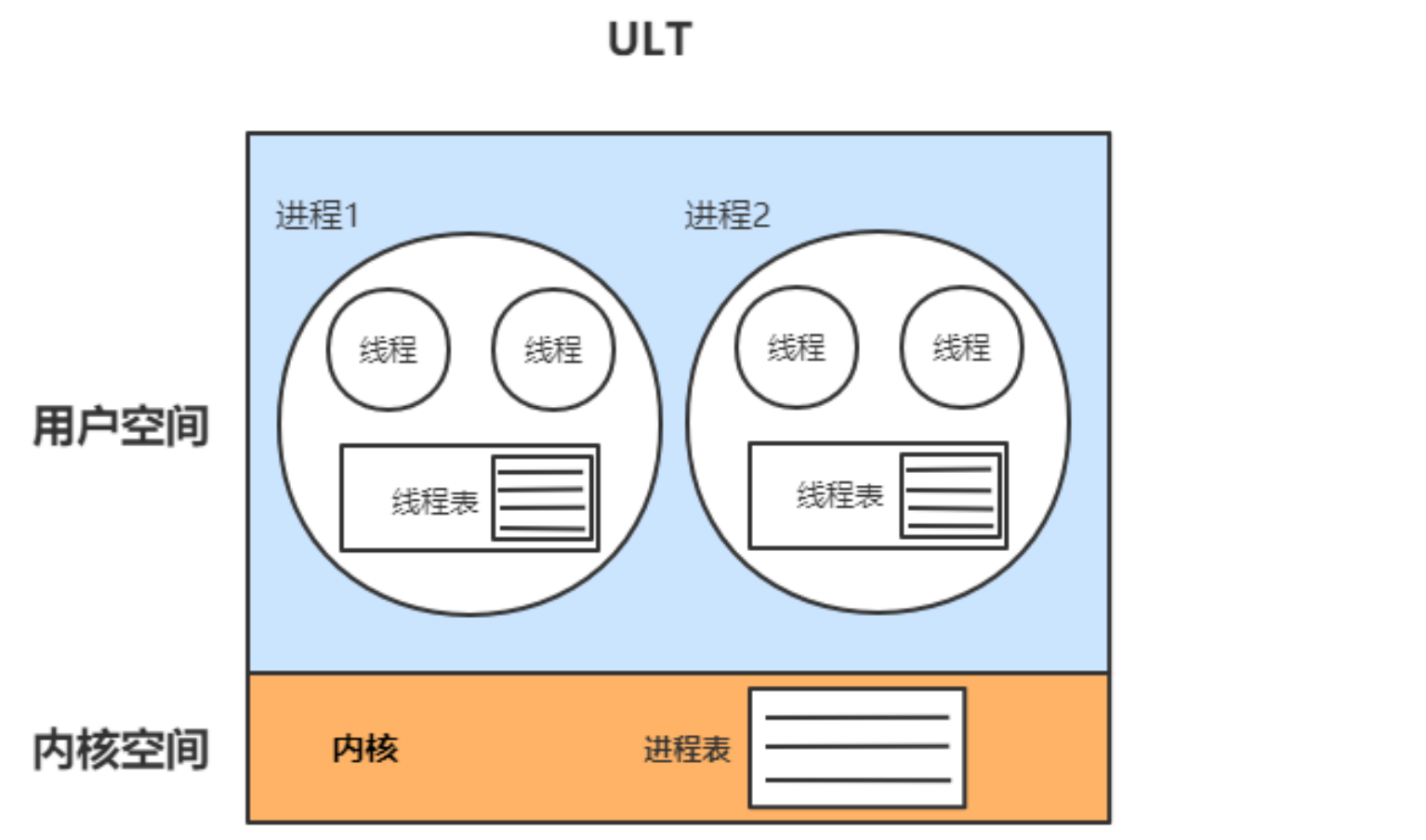
用户线程(ULT):用户程序实现,不依赖操作系统核心,应用提供创建、同步、调度和管理线程的函数来控制用户线程。不需要用户态/内核态切换,速度快。内核对ULT无感知,线程阻塞则进程(包括它的所有线程)阻塞。
思考一下,jvm是采用的哪一种线程模型?
java线程的创建, 肯定会被操作系统感知到. 下面我们来操作模拟一下, 创建200个线程,启动程序, 线程立刻增加200.
4. 线程的上下文切换
4.1 进程与线程
什么是进程?
现代操作系统在运行一个程序时,会为其创建一个进程;例如,启动一个Java程序,操作系统就会创建一个Java进程。进程是OS(操作系统)资源分配的最小单位。什么是线程?
线程是OS(操作系统)调度CPU的最小单元,也叫轻量级进程(Light Weight Process),在一个进程里可以创建多个线程,这些线程都拥有各自的计数器、堆栈和局部变量等属性,并且能够访问共享的内存变量。CPU在这些线程上高速切换,让使用者感觉到这些线程在同时执行,即并发的概念,相似的概念还有并行!
4.2 线程上下文切换过程:

cpu是采用时间片的方式, 在线程执行的时候, 他会给大家分配时间周期, 比如: 现在有两个线程T1和T2, 在调度的时候先分配时间, T1是是50ns, T是10ns. cpu先执行T1, T1的时钟周期到了以后, 就会把T1运行的中间状态保存起来, 再去执行T2, T2的时钟周期运行完了以后, 在把T2的时间状态保存起来, 然后再去执行T1. 如此循环往复.
cpu是采用时间片的方式, 在轮询的时候, 上一个线程还没有执行完, 就会把中间结果保存起来, 在执行下一个线程. 这就是线程的上下文切换.
数据保存在TSS(Task State Segament)程序任务状态段. 专门保存程序上下文的任务状态区间.
虚拟机指令集架构
虚拟机指令集架构主要分两种:
1、栈指令集架构
2、寄存器指令集架构
关于指令集架构的wiki详细说明:
https://zh.wikipedia.org/wiki/%E6%8C%87%E4%BB%A4%E9%9B%86%E6%9E%B6%E6%A7%8B
栈指令集架构
1. 设计和实现更简单,适用于资源受限的系统;
2. 避开了寄存器的分配难题:使用零地址指令方式分配;
3. 指令流中的指令大部分是零地址指令,其执行过程依赖与操作栈,指令集更小,编译器容易实现;
4. 不需要硬件支持,可移植性更好,更好实现跨平台。
寄存器指令集架构
1. 典型的应用是x86的二进制指令集:比如传统的PC以及Android的Davlik虚拟机。
2. 指令集架构则完全依赖硬件,可移植性差。
3. 性能优秀和执行更高效。
4. 花费更少的指令去完成一项操作。
5. 在大部分情况下,基于寄存器架构的指令集往往都以一地址指令、二地址指令和三地址指令为主,而基于栈式架构的指令集却是以零地址指令为主。
比如:
A = 1; B = 2; C = A + B;
如果是寄存器指令集架构: 直接将A和B丢给cpu, 告诉cpu去执行相加, cpu就做了加法操作, 返回返回, 这个操作简单高效, 这就是寄存器指令集架构的运算方式
栈指令集架构: 同样是上面的操作, 栈指令集架构, 不会直接讲A和B丢给CPU, 而是先把A push到内存区域里去, 每个内存都有个线程栈, 也就是先把A push到线程栈里面, 每个线程栈还有局部变量表, 把A=0从线程栈里弹出来, 放入到局部变量表里. 接着, 在栈里面在压入B = 1, 然后再把b=1弹出放入局部变量表里, 最后面在执行 0 + 1 这个操作
上面每次入栈和出栈是谁干的? 是cpu干的, 在cpu来看, 从线程栈到局部变量表就是一个数据的拷贝过程.
Java符合典型的栈指令集架构特征,像Python、Go都属于这种架构。课上将给大家剖析整个栈指令集架构执行链路过程。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号