7. 复制k8s Node节点 并重新初始化k8s-nodes2节点 (k8s连载)
为什么会有这样一个操作呢? (备注: 避免采坑的有效方法)
1. 我本人不是运维, 本身不精通运维知识. 在安装k8s集群的过程中,非常痛苦, 出现各种问题, 也花费了大量的时间. 结果, 突然系统崩溃了
2. 我也快崩溃了
3. 所以,后来我聪明了, 在某个阶段, 安装好以后, 我就进行备份, 这样出了问题就可以还原了, 避免每次从头开始
比如:


--------------------------------------
今天要记录的是如何复制node节点

现在有1个node了, 我需要在增加一个node
增加node, 要求hostname不能相同. ip不能相同
方案一:
1. 选中1. 和k8s-master......然后点击复制, 复制成功后, 如下图:
2. 启动服务, 修改hostname
查看主机名
hostname
修改主机名
vi /etc/hostname
然后重启服务
3. 修改固定ip地址
查询当前ip
ip a
发现当前ip和k8s-nodes节点一样, 因为设置了固定ip
修改固定ip
vi /etc/network/interface
修改静态ip为105
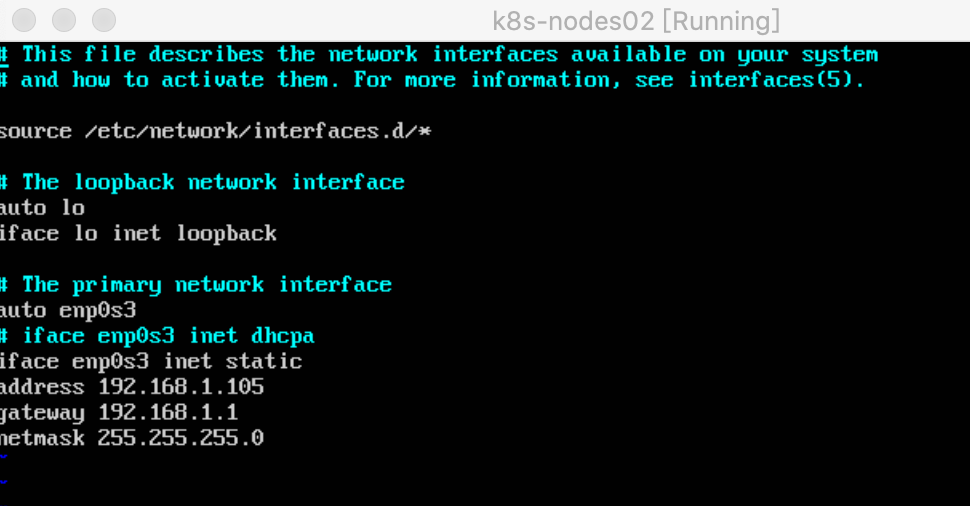
如果没有设置过静态ip, 可以参考我总结的这篇文章: https://www.cnblogs.com/ITPower/p/12806495.html
重启网卡:
sudo service networking restart
4. 重新配置ssh免密登录
ssh登录, 报错
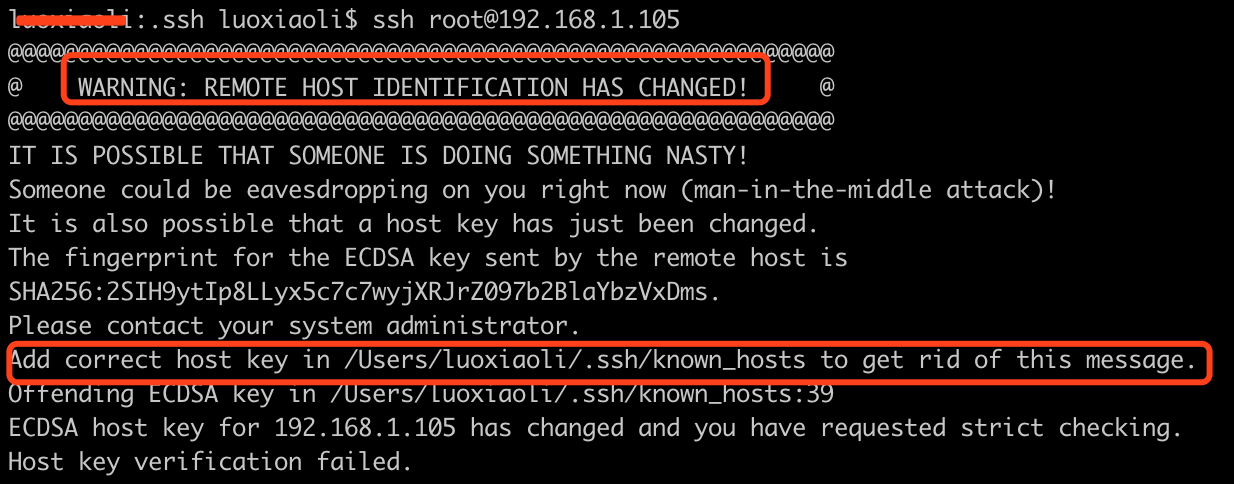
解决方法参考: https://blog.csdn.net/wd2014610/article/details/79945424
删除knows_hosts文件中带有192.168.1.105的秘钥
远程登录, 查看hostanme和ip, 都是对的了
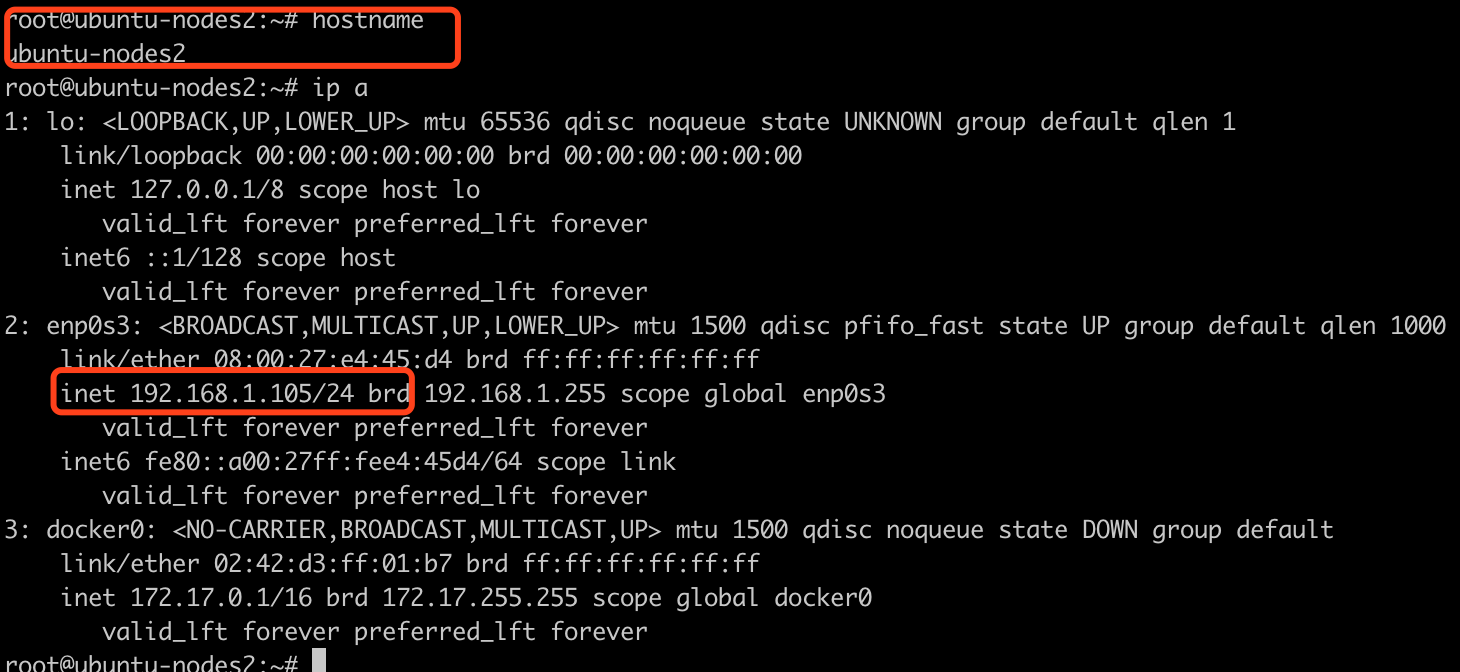
-
解决方法,看错误日志中有一句
Add correct host key in /Users/***/.ssh/known_hosts to get rid of this message.
-
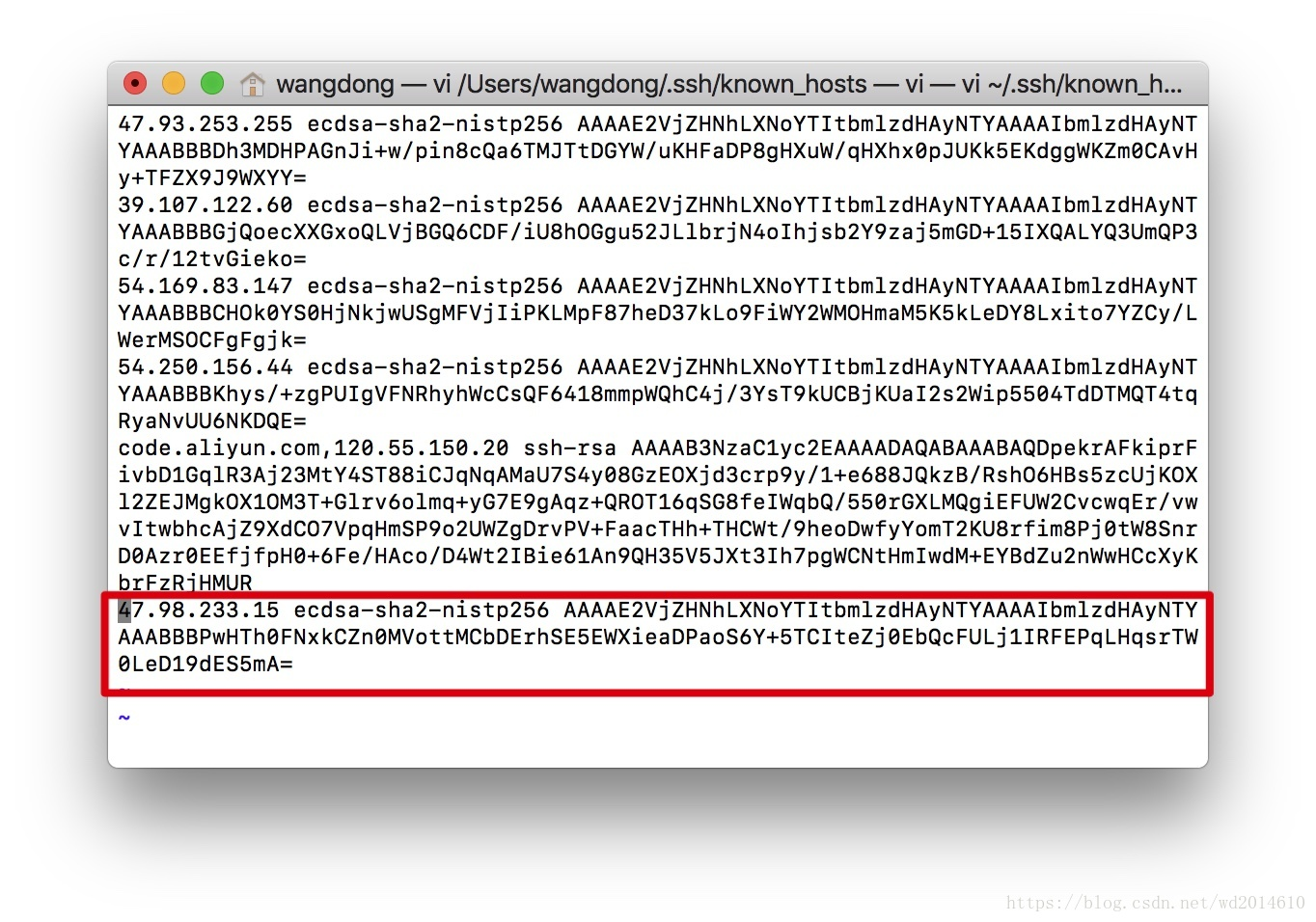
以编辑器的方式进入这个文件
vi /Users/wangdong/.ssh/known_hosts
-
将红线框部分删除掉
![]()
5. 添加k8s节点
在master节点上查看节点状态
kubectl get node

只有两个节点, 刚刚copy的节点没有添加上.
在k8s-nodes2上执行kubeadm reset 可以断开node, 然后重新join
kubeadm reset

然后重新join, join的内容放在https://www.cnblogs.com/ITPower/p/12791615.html里面了
kubeadm join 192.168.1.106:6443 --token vezzap.0w213k8ms11a0v51 \ --discovery-token-ca-cert-hash sha256:4fcac7c487209d7c354351ba6f93110253df4d0440fc68cb23fc4ac0baed4e0c
ERROR1: 初始化报错

没有关闭虚拟内存
关闭虚拟内存, 并永久关闭 swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
ERROR2: 还是有错误

解决方案参考: https://www.jianshu.com/p/f53650a85131
看这个告警[WARNING IsDockerSystemdCheck]
修改或创建/etc/docker/daemon.json,加入下述内容:
{ "exec-opts": ["native.cgroupdriver=systemd"] }
我的文件修改完以后
{ "registry-mirrors": ["https://w52p8twk.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"] }
重启docker
systemctl restart docker
查看修改后的状态
docker info | grep Cgroup
ERROR3: token过期

上面三个是warning, 最后一个是error. 什么意思呢? 应该是master生成的节点过期了. 我们需要重新生成
参考文章: https://www.cnblogs.com/tchua/p/10897980.html
1)关于token失效
master集群初始化后,token24小时后就会失效,如果到了token失效时间,node再加入集群,需要重新生产token:
## 查看token状态 ### TTL值 就是token生于时间 [root@k8s-master ~]# kubeadm token list TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS 5ti5kd.o32bm9lofv6zej94 21h 2019-05-22T11:16:31+08:00 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
## 重新生产token [root@k8s-master ~]# kubeadm token create W0511 05:25:48.747429 31569 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
lb2hib.5kf3zjrzkp8e632w
## 获取--discovery-token-ca-cert-hash值 [root@k8s-master ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \ openssl dgst -sha256 -hex | sed 's/^.* //' 4fcac7c487209d7c354351ba6f93110253df4d0440fc68cb23fc4ac0baed4e0c
## 加入集群命令--在node节点执行 [root@k8s-master ~]# kubeadm join 192.168.1.106:6443 --token vezzap.5kf3zjrzkp8e632w \
--discovery-token-ca-cert-hash sha256:4fcac7c487209d7c354351ba6f93110253df4d0440fc68cb23fc4ac0baed4e0c
注意: 替换两个地方的值
第一个位置替换:lb2hib.5kf3zjrzkp8e632w
第二个位置替换:4fcac7c487209d7c354351ba6f93110253df4d0440fc68cb23fc4ac0baed4e0c
详情请参考我的另一篇文章: https://www.cnblogs.com/ITPower/p/12866713.html
ERROR4 :
error execution phase preflight: couldn't validate the identity of the API Server:
Get https://10.10.0.10:6443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s: net/http:
request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
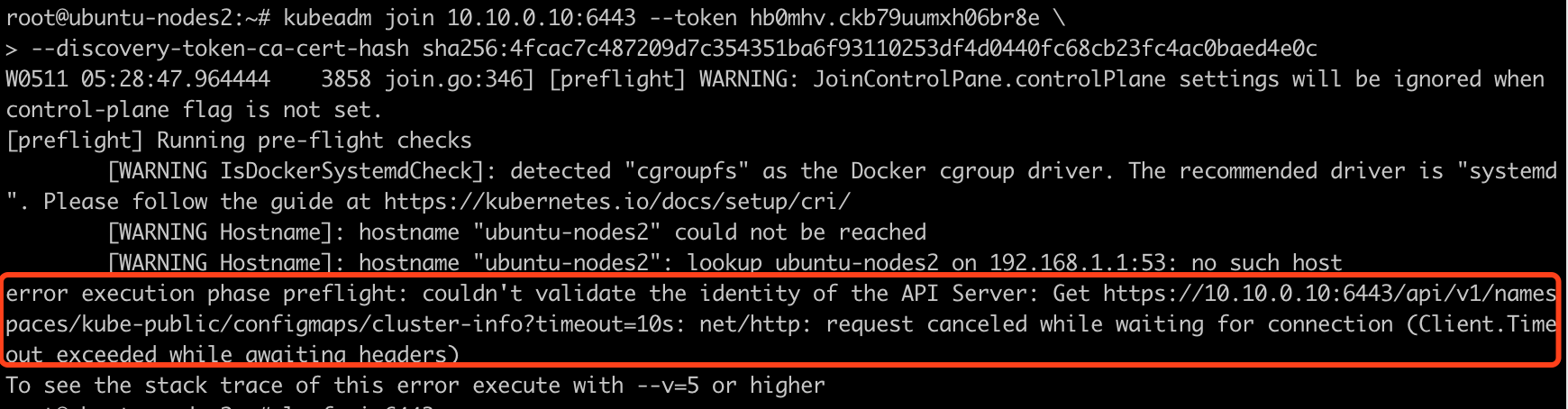
注意三个地方:
1. join的ip地址对不对
2. token设置的对不对
3. hash值设置的对不对.
都对了, 就不会出现这个问题了
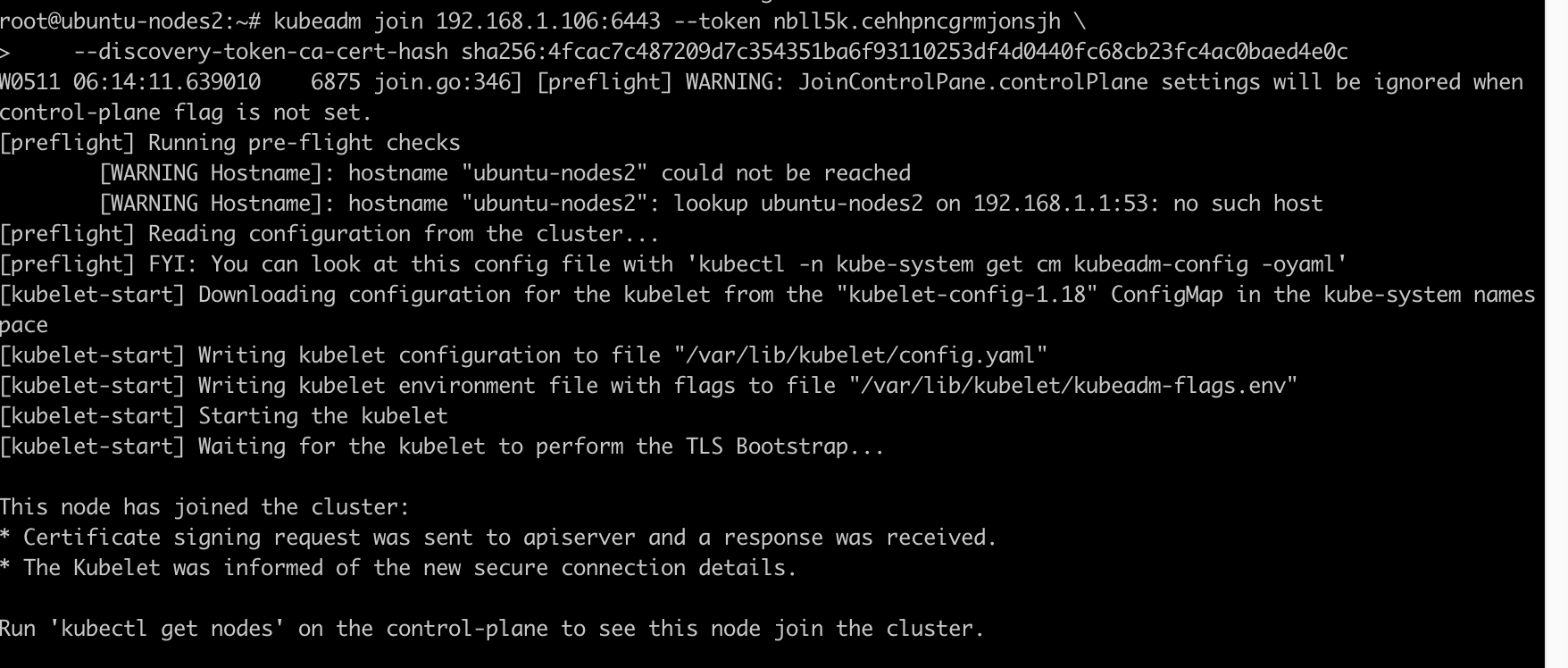
初始化成功的信息
六. 查看k8s节点
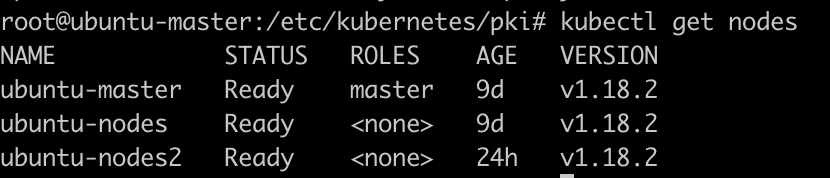
1. 接下来,在master上查看
kubectl get nodes

从时间上可以看出, 最后一个是刚刚添加的.
状态都NotReady
2. 查看pod的状态
kubectl get pods -n kube-system
或
kubectl get pod --all-namespaces -o wide
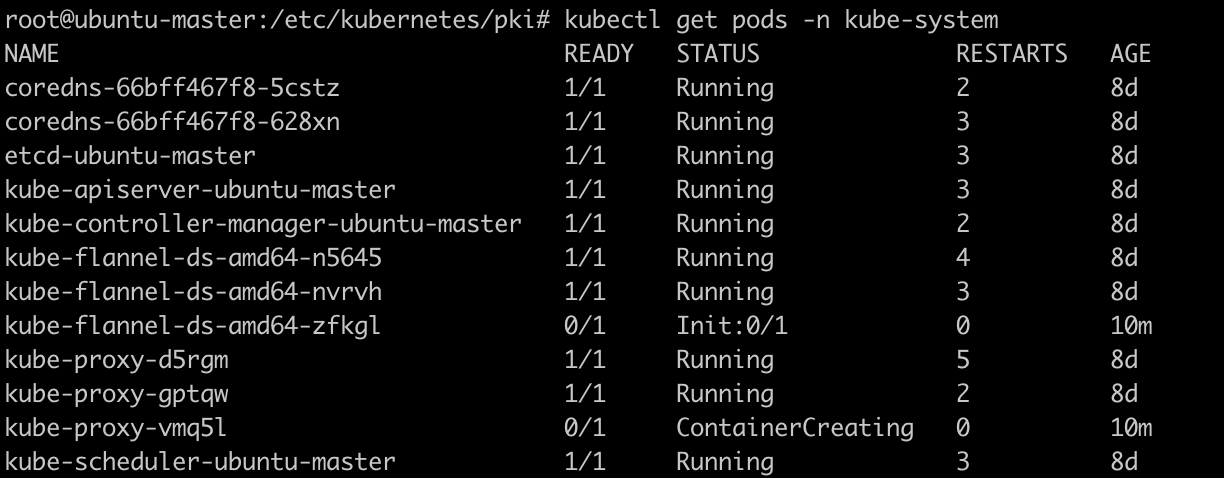
其中有两个是非Running状态
3. 查看pod的状态
kubectl describe pod kube-flannel-ds-amd64-zfkgl -n kube-system

少了pause:3.2镜像
4. 下载pause:3.2镜像
docker pull registry.cn-hangzhou.aliyuncs.com/dva-1024/pause:3.2

5. 修改下载下来的镜像的tag为k8s.gcr.io的
docker tag registry.cn-hangzhou.aliyuncs.com/dva-1024/pause:3.2 k8s.gcr.io/pause:3.2
6. 删除对应的阿里云镜像
docker rmi registry.cn-hangzhou.aliyuncs.com/dva-1024/pause:3.2
docker images可以查看镜像
7. 删除pod节点
kubectl delete pod kube-flannel-ds-amd64-zfkgl -n kube-system
这里的pod节点删除后, 会自动重新加载.
8. 其他节点也有问题, 参考上面7点, 直到所有节点都Running
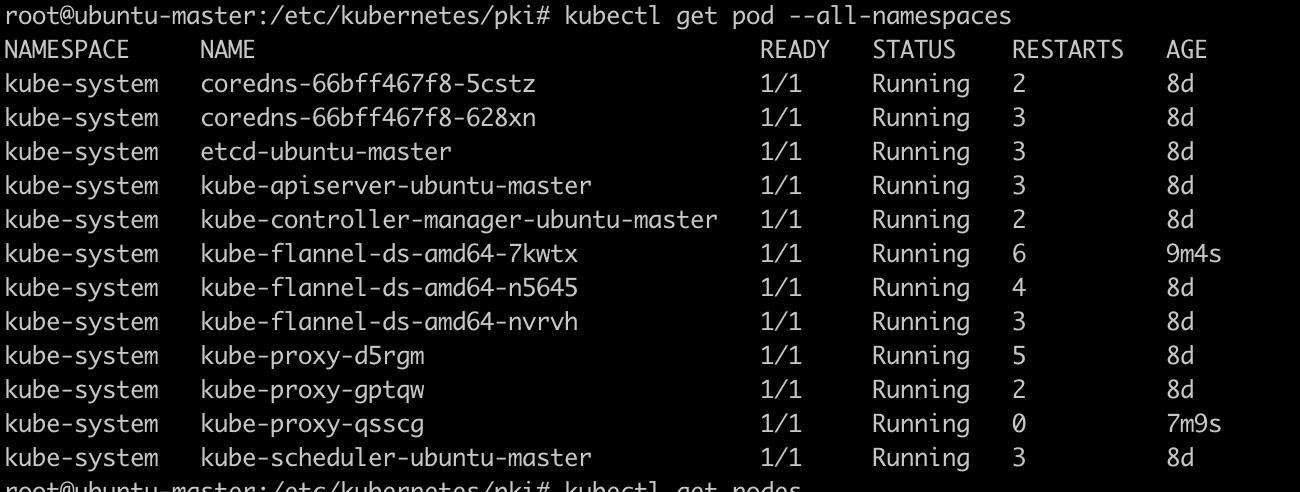
pod都是running, 但是有一个节点是NotReady, 我们查看日志

journalctl -f -u kubelet.service
查看有问题的节点的pod状态
kubectl get pods -n kube-system -owide | grep ubuntu-nodes

都是running, 但为什么nodes节点是notReady呢? 我将node关机了, 再重启, 就好了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号