1. 开始Kubernetes: k8s
目录内容:
1. 发展经历
2. 知识图谱
3. 组件说明
本节目标: 要求会画bolg系统和kubernetes系统的架构图, 并且知道架构每一部分的作用.
一、发展经历
对于云计算来说, 他会有一些发展标准
1. Infrastructure as a Service : 简称IAAS, 基础设施及服务. 国内典型的厂家是阿里云. 国际最大的厂商是AWS.
2. platform as a Service: 简称PAAS, 平台及服务.
3. Software as a Service: 简称SSAS, 软件设施及服务.
比如: 我想用office套件, 不在需要像以前一下,需要1小时的安装, 我只需要通过b/s结构, 也就是浏览器端访问到他的网页即可. 完成office的文件的创建,修改
下面来详细说说PAAS, 平台及服务.
新浪有一个老的平台SAA, 以前是用户可以免费申请这样一个平台, 运行代码项目, 比如java, php等.
比如: 有一个用户, 申请了一个SAA服务的平台. 然后新浪的运维在后台看到这个订单, 开始部署环境. 这时候, 运维特别苦逼. 来一个单子, 部署一套环境.
后来有了一些自动部署的运维工具, 让部署自动化所谓的环境的创建, 可以能是java的环境, 可能是php的环境. 直到后来, docker股份有限公司开发了docker. 这个公司主要就是做PAAS平台的. docker在他们公司的主要地位就是自动的构建这些环境的封装体. Docker成了PAAS下一代的标准. 随之也会带来一些问题.
在传统的服务中, 在一台物理机上, 运行多个tomcat, 多个数据库, 组成一个大的集群. 这是没有问题的, 但是一旦容器化以后, 就有问题了.
假设: 有6台物理机, 让这6台物理机组成一个集群. 比如一台nginx, 3台tomcat, 2台mysql. 他们之间访问的方式是ip+端口号, 进行联通.
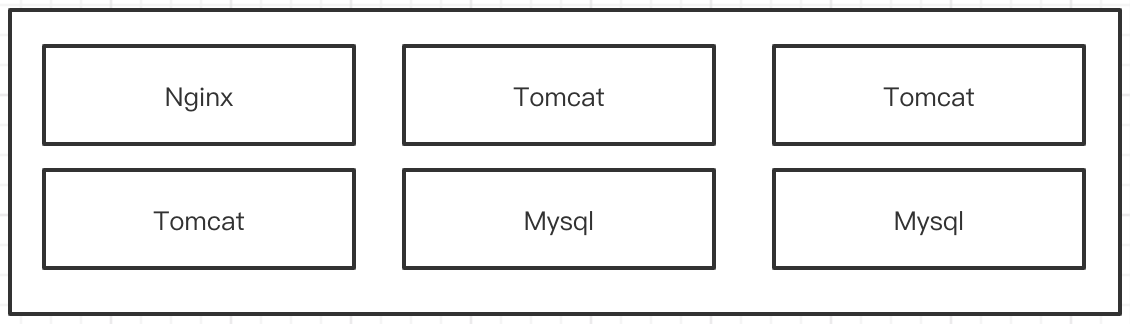
但是使用容器以后, 我们就发现,他们之间的映射关系就比较困难了. 比如, 将nginx安装在docker上. 首先要将docker中nginx的端口号映射到物理机上, tomcat需要吧8080映射到主机的8080. mysql也是. 而且一台服务器不可能只安装1个tomcat, 还会有很多其他的应用, 然后每台机器都会映射很多端口. 这样越来越多, 太杂,太乱了. 于是衍生出了新的产品. 这个产品叫资源管理器.
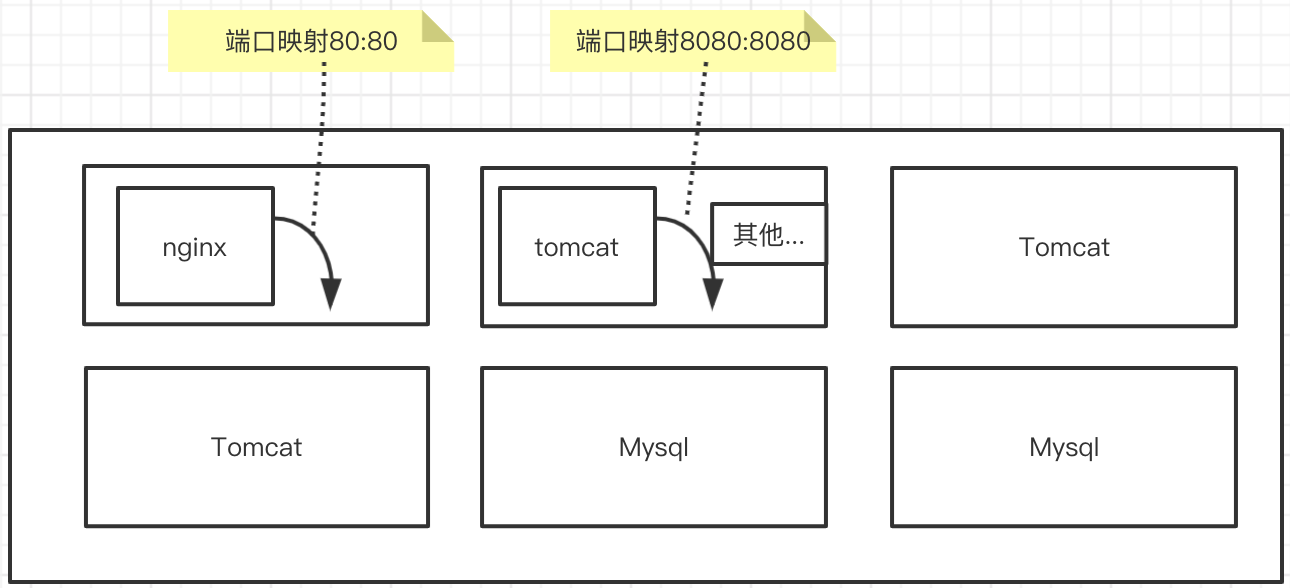
那么资源管理器又经过了哪些过程呢?
1. Apache 的mesos: mesos是apache下开源的分布式管理框架, 由加州大学的伯克利分校开发出来的. 2019年5月, 弃用mesos, 全部改为k8s.
2. docker swarm: 设置docker的母公司诞生的一款资源管理器. docker和swarm已经组成了一个体系的功能. 这个东西很轻量, 只消耗几十M的资源, 对于集群管理来说, 消耗几十M是非常小的, 通常都是要几十G的. 他这么好,为什么不用他呢? 根本原因, 还是相对于k8s来说, swarm的功能还太少了. 比如我想实现一个滚动更新和回滚等操作. 在swarm里实现是非常困难的. 我们需要手工定义这个流程, 太费事. 2019年7月 阿里云宣布 Docker swarm 剔除
3. kubernetes: google, 在10年就已经进行容器化基础架构管理了. 系统的名字叫borg(伯格系统), 当时很多人都想要这套系统, 但是google不差钱, 不卖. 后来随着docker的盛行, 市场都开始研究资源管理器. 这是google站出来说话了. 他让其内部工程师, 使用go语言, 重新翻写了borg系统. 就是现在的k8s. 成为了当前的标准.
kubernetes的特点:
1. 轻量级: go语言开发, 运行效率高, 消耗资源少.
2. 开源: 能够被推广的主要原因
3. 弹性伸缩: 公司运行个几年就上市了, 资源不够用了, 从5台--->一下升级到10台. 我们还可以由主节点将某些节点调度剥离出去, 有原来的8台缩减为5台. 可以释放资源, 减少资金消耗
4. 负载均衡: kubernetes已经实现了模块之间的负载均衡, 不需要我们在使用调度器实现. 由kubernetes本机进行. 并且, kubernetes采用了最近版本的负载均衡框架IPVS. IPVS是我们国内开发的, 是国人的骄傲, 在负载均衡界也是老大, no1.
二. 知识图谱
了解, 都有哪些知识点 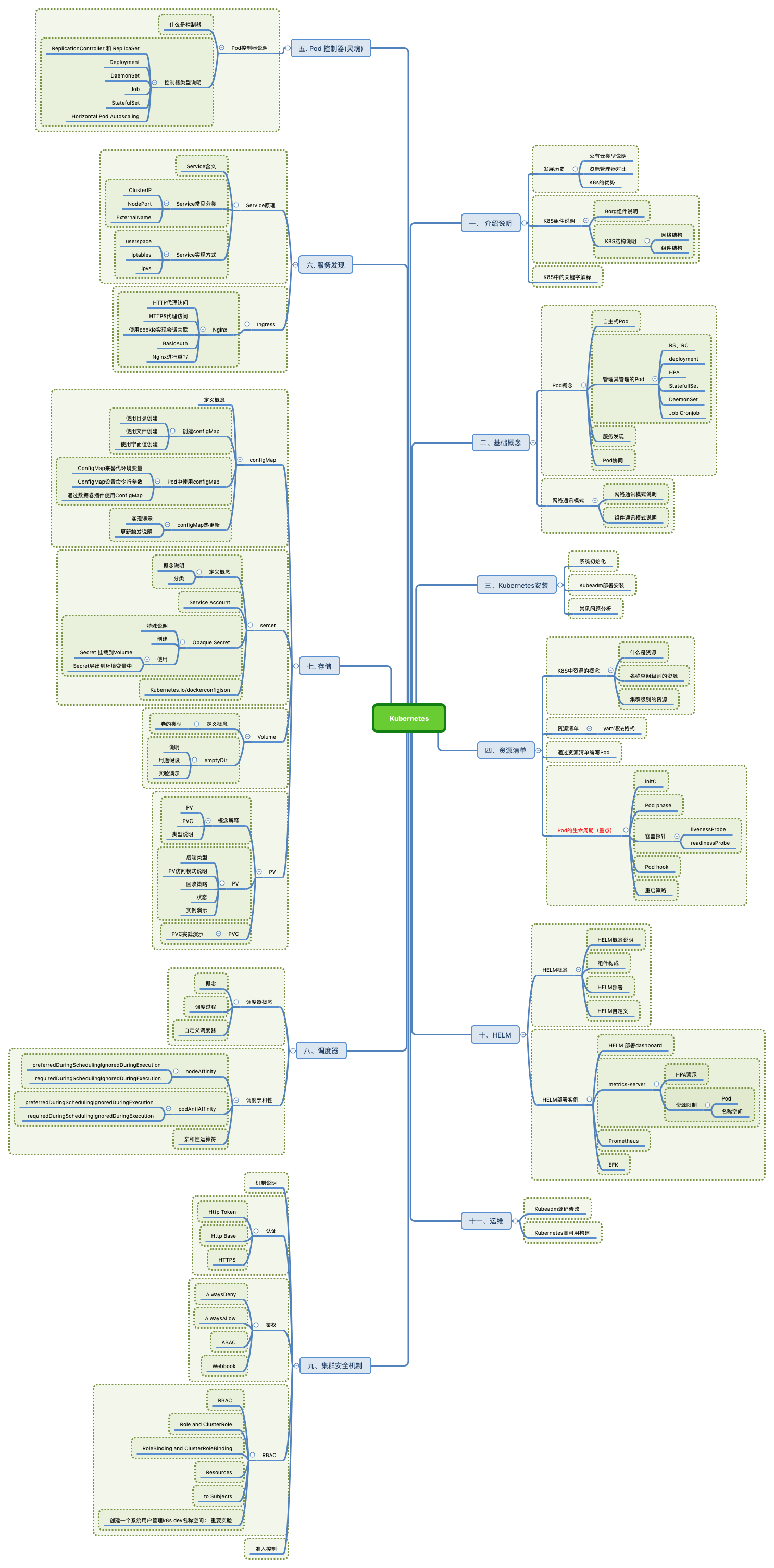
三. 组件说明
本节目标: 要求会画bolg系统和kubernetes系统的架构图, 并且知道架构每一部分的作用.
Kubernetes的前身是borg系统. 所以,我们先来看borg系统的架构
3.1 Borg系统的系统架构
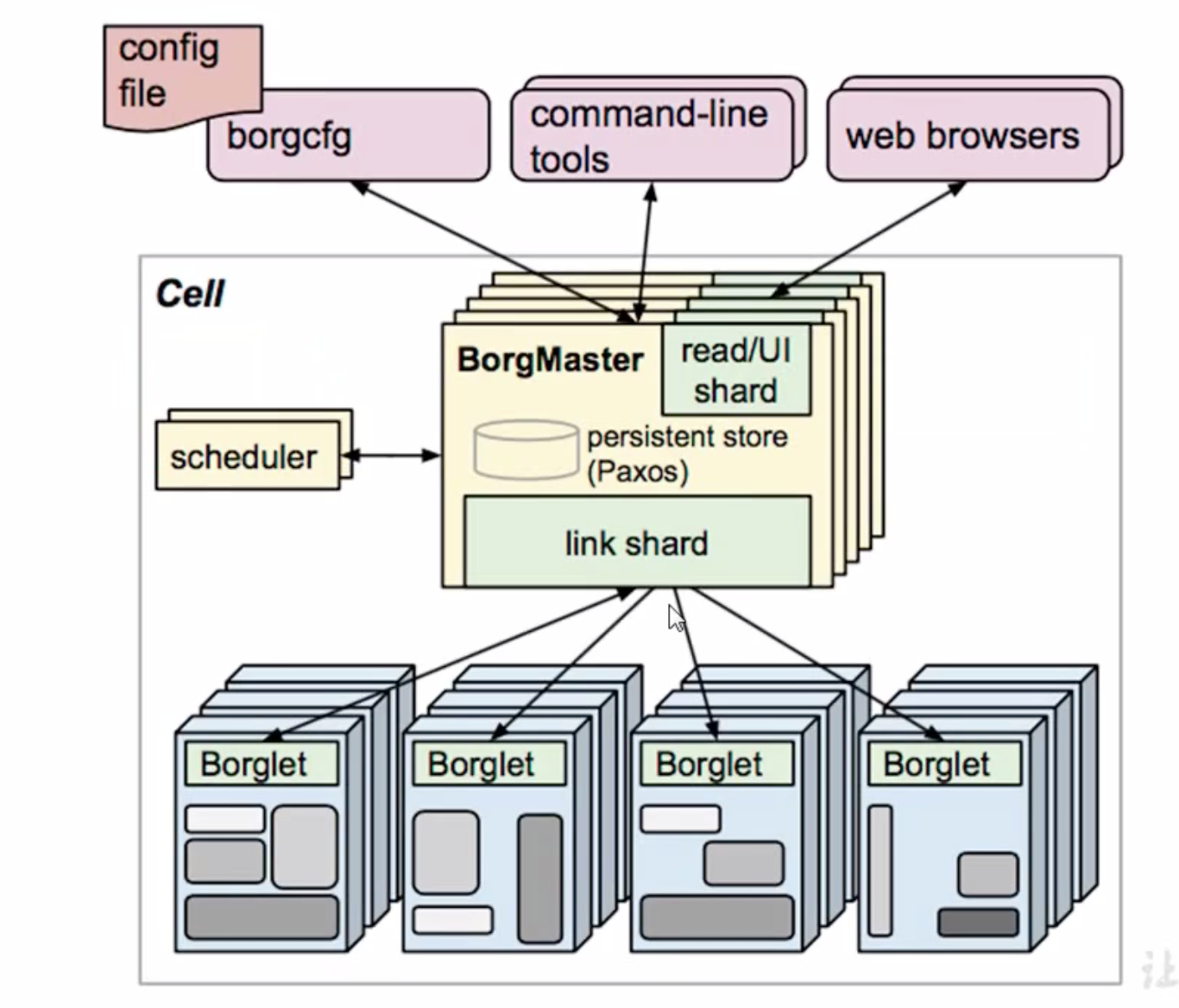
1. 首先可以看到, 这里有两大块: BorgMaster和Borglet.
- BorgMaster: 负责请求的分发 , 是整个集群的大脑. BorgMaster为了避免单节点故障, 所以, 会有很多副本, 通常副本数都是奇数3, 5, 7, 9.....方便选举.
- Borglet: 真正工作的系统是Borglet, Borglet会提供一些计算能力.
2. 访问BorgMaster有三种方式
- web browsers: 浏览器
- command-line tools: 命令行
- config file: 文件
在Kubernetes里面也会有这三种调度管理的方式.
请求通过三种方式到达BorgMaster系统以后, master会对请求进行分发, 分发给不同的Borglet进行处理. 比如, 有活来了, 领导要把活分给不同的小伙伴, 那么怎么分呢? 就有一个scheduler调度器.
由调度器来决定将任务分配给哪一个Borglet来做. 这里调度去Scheduler并不直接给Borglet分配工作, 而是, 将任务写入到数据库Paxos, 进行持久化存储起来. Paxos是谷歌的键值对数据库. Borglet会监听Paxos数据库, 看看是不是有我的任务来了. 如果来了, 那就消费.
以上是borg系统的架构, Kubernetes和borg是类似的, 下面来看Kubernetes架构
3.2 Kubernetes架构

这是k8s的架构图. 主要分为两大部分: 中间包含三个绿色包的是master服务器. 下面是node节点.
-
Master: master中有哪些东西
- scheduler: 任务调度器, 负责调度任务, 选择合适的节点执行任务. 任务来了, 还是通过scheduler进行任务调度分发至不同的node. 在Borg系统中, scheduler是将任务写入到Paxos系统中, 而这里不同的是, scheduler会将任务交给api server, 由api server将任务写入到etcd, 也就是说scheduler不会直接和etcd交互
- replication controller: 简称rc, 控制器, 用来维护副本的期望数目. 举个例子, 我想让容器运行几个副本, 就是由rc来控制的. 一旦副本数不符合我们的期望值, rc就要改写副本数或者申请到我们的期望值. 也就是创建对应的Pod或者删除对应的Pod
- api server: 所有服务访问的统一入口. 就是一起访问的入口. 从上图可以看出. Master中scheduler需要和api server交互, rc要和api server交互, kubectl(客户端)也要和api sever交互, web UI也要和api server交互, etcd也要和api server交互. apiserver是非常繁忙的.
-
etcd: 键值对数据库, 存储K8s集群的所有重要信息(持久化). etcd就类似于在Borg系统中的Paxos键值对数据库. 在Kubernetes集群中起到的了持久化的作用. 对于etcd有两点说明:
- etcd官方将其定位为一个可信赖的分布式键值存储服务, 它能够为整个分布式集群存储一些关键数据, 协助分布式集群的正常运转.
- etcd的版本

etcd现在有两个版本, v2和v3版本, v2版本将数据保存到内存, v3版本将数据保存到数据库. 正常我们都选择使用v3版本, 但Kubernetes v1.11版本之前使用的是v2版本.
-
- etcd内部架构图

-
-
- http Server: 这里采用的是使用http进行构建的c/s服务, k8s也是采用的http协议进行c/s服务的开发. 为什么要这么做呢? 因为http天生支持一系列的操作. 例如: get ,post, put, delete, 授权认证等. 所以, 没有必要再去采用标准的tcp协议. 开发一系列的认证流程, 所以, 直接采用http协议即可.
- Raft是读写的信息, 所有的读写信息都被存在Raft里面, 而且, 为了防止这些信息出现损坏, 他还有一个WAL预写日志
- WAL: 预写日志, 如果要对数据进行更改, 那么先写入一条日志, 然后定时的对日志进行完整的备份. 也就是完整+临时. 比如: 我先备份一个大版本, 备份以后, 还会有1个子版本, 两个子版本....., 然后将这些版本再次进行一个完整备份,把它变成一个大版本. 这样做的好处, 我们不能始终进行完整备份, 因为消耗的数据量太大. 为什么还要在一定时间内进行完整的备份呢?防止增量备份太多, 还原的时候太费事. 并且, Raft还会实时的把这些数据和日志存入到本地磁盘进行持久化.
- Store: 试试把WAL中的日志和数据, 写入磁盘进行持久化.
-
- Node节点: 从图中可以看出, Node节点包含三个组件 ,kubelet, kube proxy, 以及container. 也就是说我们在node节点需要安装三个软件: kebelet, kebu proxy, docker

-
- kubelet的作用: 直接跟容器交互, 实现容器的生命周期管理. 他会和CRI, C是容器, R是runtime, I是interface. CRI就是docker的操作形式. kubelet会和docker交互, 创建需要的容器. kubelet会维持Pod的生命周期.
- kube proxy的作用: 负责写入规则至IPTABLES, IPVS实现服务映射访问. 之前说过svc, 可以进行负载操作, 负责的操作就是通过kube proxy完成的. 怎么实现Pod与Pod之间的访问, 以及负载均衡. 默认操作是操作防火墙, 去实现Pod的映射. 新版本还支持IPVS.
其他重要的插件
- COREDNS: 可以为集群中的SVC创建一个域名IP对应的关系解析. 也就是说,我们在集群中访问其他Pod的时候, 完全不需要通过Pod的ip地址, 通过CoreDns给他生成的域名去实现访问. 他是集群中的重要重要组件, 也是实现负载均衡的其中一项功能.
- DASHBOARD: 给K8S集群提供一个 B/S结构访问体系.
- Ingress Controller: 官方只为我们实现了四层代理. Ingress可以实现七层代理, 也就是可以根据组件名和域名进行负载均衡.
- Federation: 提供一个可以跨集群中心多K8s统一集群管理功能.
- Prometheus(普罗米修斯): 提供K8S集群的监控能力.
- ELK: 提供k8s集群日志统一接入平台


 浙公网安备 33010602011771号
浙公网安备 33010602011771号