第十三章 go实现分布式网络爬虫---单机版爬虫
-
爬虫的分类

网络爬虫分为两类
1. 通用爬虫: 类似于baidu, google. 他们会把大量的数据挖下来, 保存到自己的服务器上. 用户打开跳转的时候, 其实先是跳转到他们自己的服务器.
2. 聚焦爬虫: 其实就是有目标的爬虫, 比如我只需要内容信息. 那我就只爬取内容信息.
通常我们使用的爬虫都是聚焦爬虫
-
项目总体结构
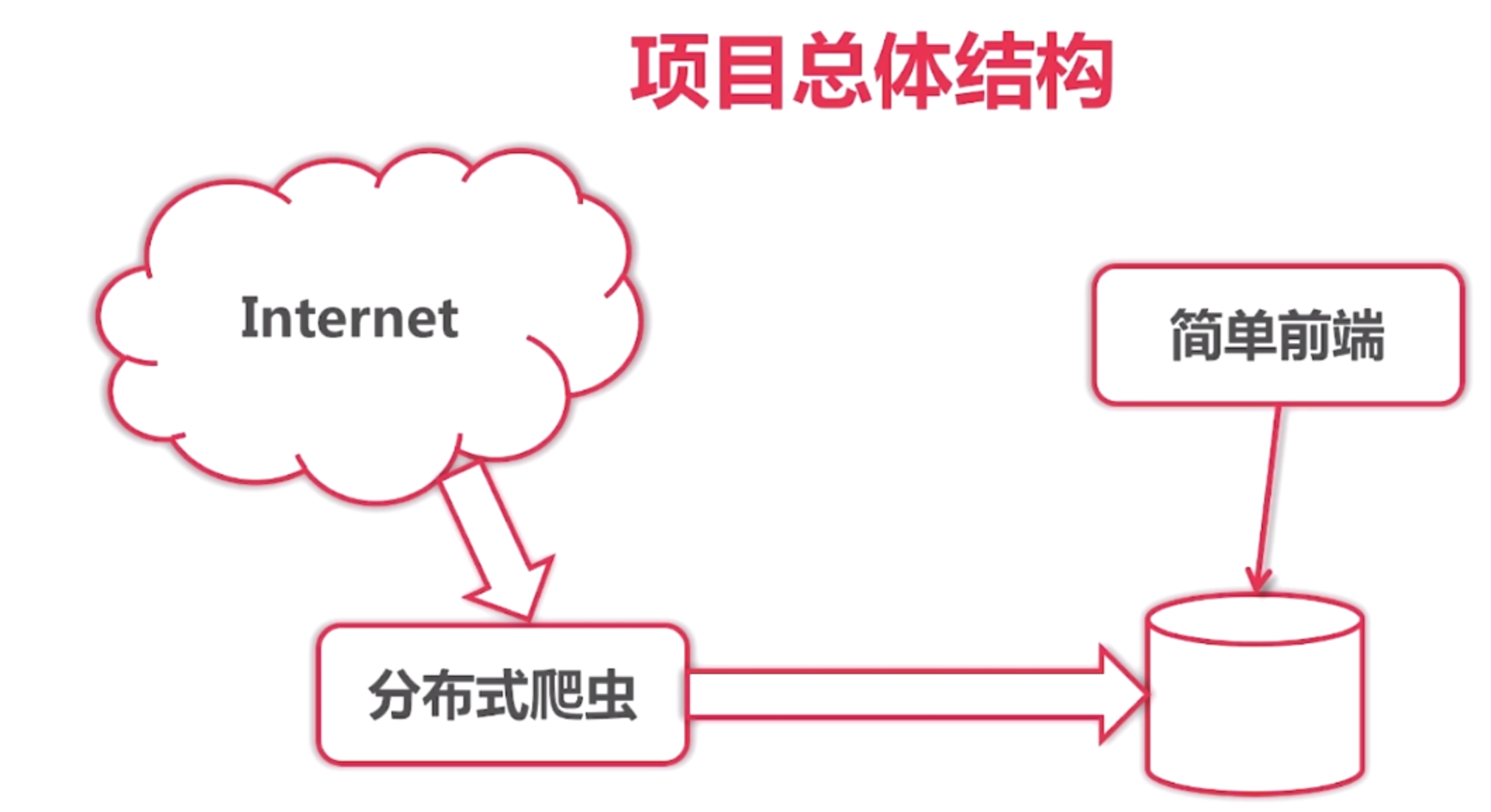
爬虫的思想很简单.
1. 写一段程序, 从网络上把数据抓下来
2. 保存到我们的数据库中
3. 写一个前端页面, 展示数据
-
go语言的爬虫库/框架

以上是go语言中已经you封装好的爬虫库或者框架, 但我们写爬虫的目的是为了学习. 所以.....不使用框架了
-
本课程的爬虫项目

1. 不用已有的爬虫库和框架
2. 数据库使用ElasticSearch
3. 页面展示使用标准库的http
这个练习的目的,就是使用go基础.之所以选择爬虫,是因为爬虫有一定的复杂性
-
爬虫的主题

哈哈, 要是还没有女盆友, 又不想花钱的童鞋, 可以自己学习一下爬虫技术
-
如何发现用户

1. 通过http://www.zhenai.com/zhenghun页面进入. 这是一个地址列表页. 你想要找的那个她(他)是哪个城市的
2. 在用户的详情页, 有推荐--猜你喜欢
-
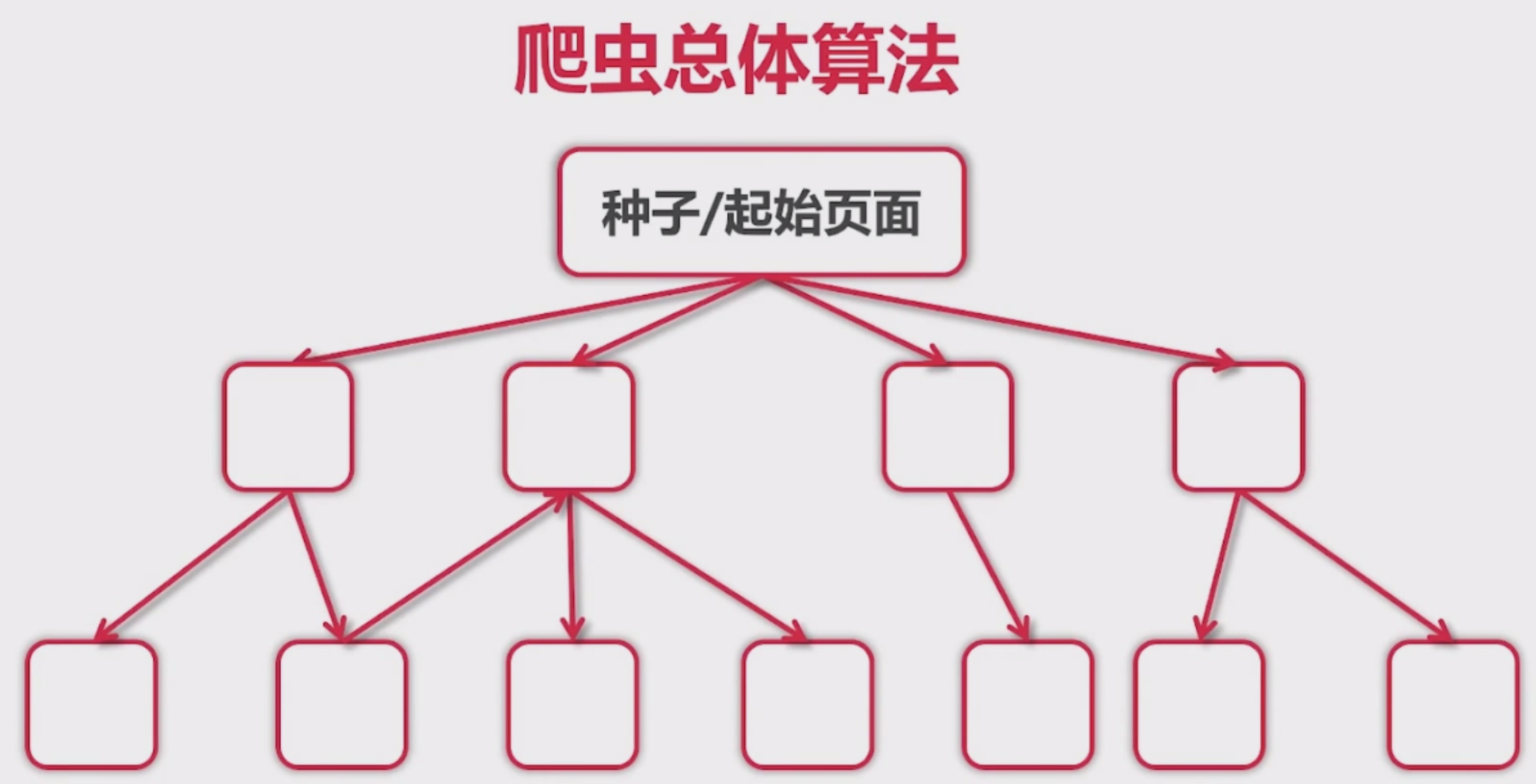
爬虫总体算法
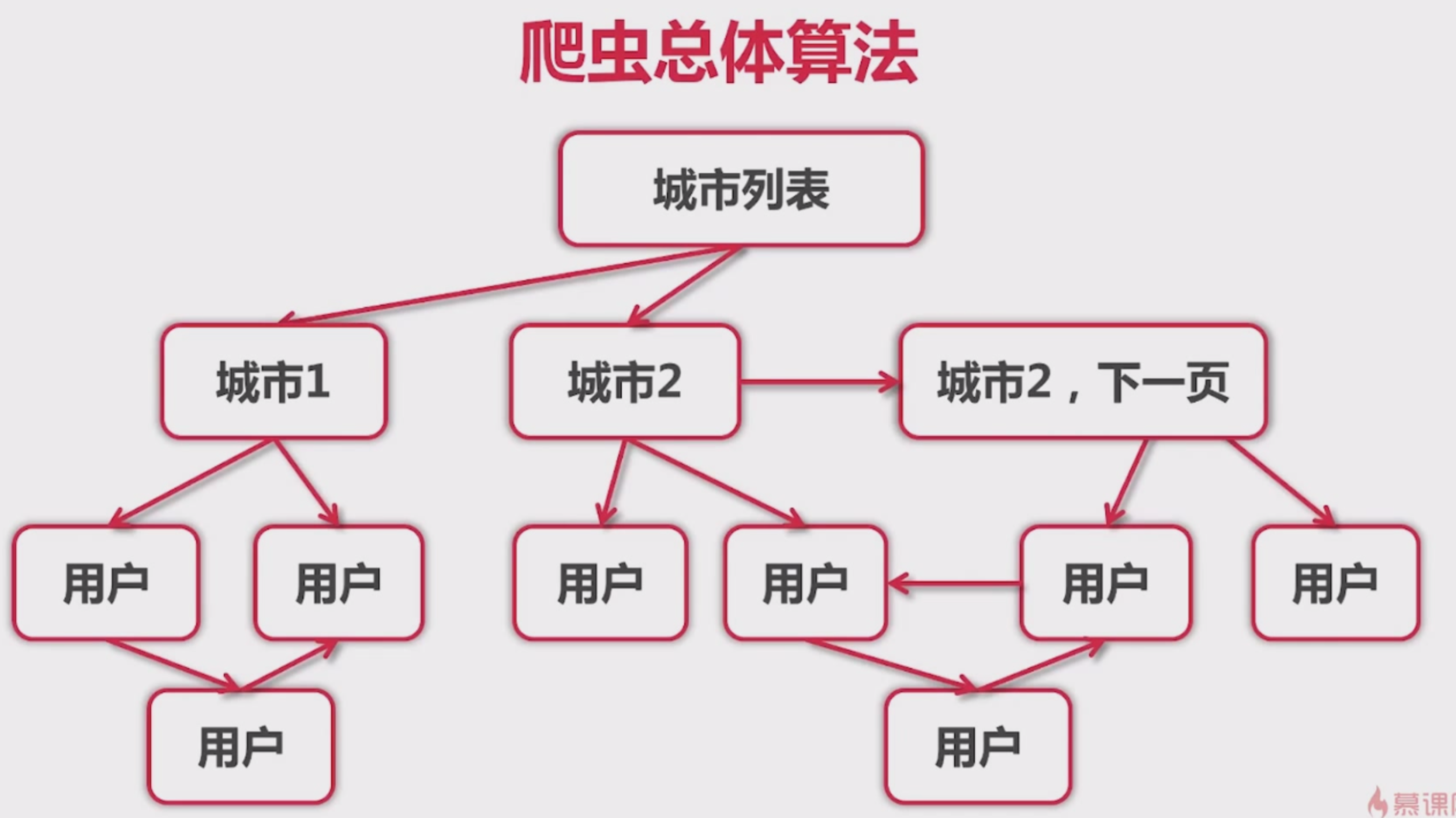
1. 城市列表, 找到一个城市
2. 城市下面有用户列表. 点击某一个用户, 进去查看用户的详情信息
3. 用户详情页右侧有猜你喜欢, 链接到一个新的用户详情页
需要注意的是, 用户推荐, 会出现重复推荐的情况. 第一个页面推荐了张三, 从上三进来推荐了李四. 从李四进来有推荐到第一个页面了. 这就形成了死循环, 重复推荐
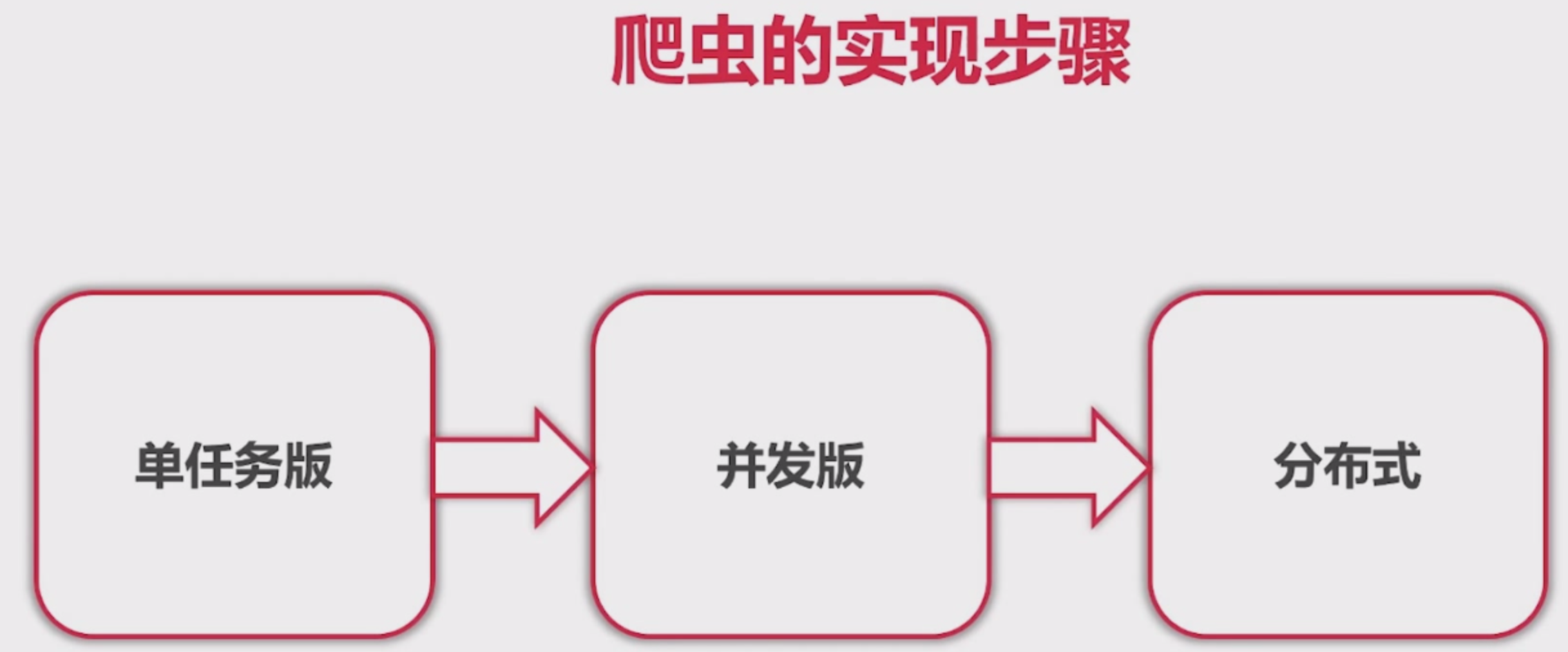
我们完成爬虫, 分为三个阶段
1. 单机版. 将所有功能在一个引用里完成
2. 并发版. 有多个连接同时访问, 这里使用了go的协程
3. 分布式. 多并发演进就是分布式了. 削峰, 减少服务器的压力.
下面开始项目阶段
项目
一. 单任务版网络爬虫
目标: 抓取珍爱网中的用户信息.
1. 抓取用户所在的城市列表信息
2. 抓取某一个城市的某一个人的基本信息, 把信息存到我们自己的数据库中
分析:
1. 通过url获取网站数据. 拿到我们想要的地址,以及点击地址跳转的url. 把地址信息保存到数据库. 数据量预估300
2. 通过url循环获取用户列表. 拿到页面详情url, 在获取用户详情信息. 把用户信息保存到数据库. 数据量会比较大. 一个城市如果有10000个人注册了, 那么就有300w的数据量.
3. 所以, 数据库选择的是elasticSearch
-------------------
抓取城市列表页, 也就是目标把这个页面中我们要的内容抓取下来.
其实就两个内容, 1. 城市名称, 2. 点击城市名称跳转的url

第一步: 抓取页面内容
package main import ( "fmt" "io/ioutil" "net/http" "regexp" ) func main() { // 第一步, 通过url抓取页面 resp, err := http.Get("http://www.zhenai.com/zhenghun") if err != nil { panic(err) } defer resp.Body.Close() if resp.StatusCode != http.StatusOK { return } // 读取出来body的所有内容 all, err := ioutil.ReadAll(resp.Body) if err != nil { panic(err) } //fmt.Printf("%s\n", all) printCityList(all) }
第二步: 正则表达式, 提取城市名称和跳转的url
package main import ( "fmt" "io/ioutil" "net/http" "regexp" ) func main() { // 第一步, 通过url抓取页面 resp, err := http.Get("http://www.zhenai.com/zhenghun") if err != nil { panic(err) } defer resp.Body.Close() if resp.StatusCode != http.StatusOK { return } // 读取出来body的所有内容 all, err := ioutil.ReadAll(resp.Body) if err != nil { panic(err) } //fmt.Printf("%s\n", all) printCityList(all) } /** * 正则表达式提取城市名称和跳转的url */ func printCityList(content []byte) { re := regexp.MustCompile(`<a href="(http://www.zhenai.com/zhenghun/[a-z1-9]+)" data-v-5e16505f>([^<]+)</a>`) all := re.FindAllSubmatch(content, -1) for _, line := range all { fmt.Printf("city: %s, url: %s\n", line[2], line[1]) } }
结果如下:
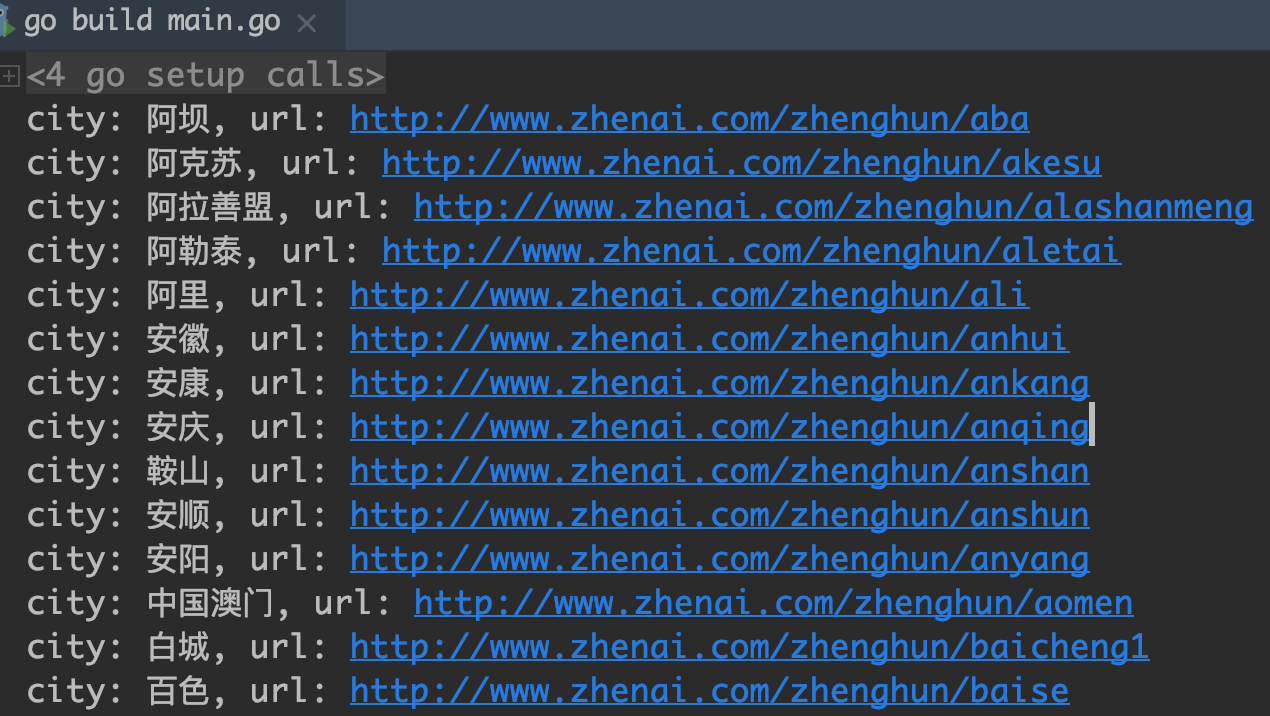
这样第一个页面就抓取完成了. 第二个和第三个页面可以了类似处理. 但这样不好, 我们需要把结构进行抽象提取. 形成一个通用的模块
再来分析我们的单机版爬虫项目
项目结构---共有三层结构:
- 城市列表解析器: 用来解析城市列表
- 城市解析器: 用来解析某一个城市的页面内容, 城市里是用户列表和分页
- 用户解析器: 从城市页面点击用户进入到用户的详情页, 解析用户的详情信息
解析器抽象
既然都是解析器, 那么我们就把解析器抽象出来.
每一个解析器, 都有输入参数和输出参数
输入参数: 通过url抓取的网页内容.
输出参数: Request{URL, Parse}列表, Item列表
为什么输出的第一个参数是Request{URL, Parse}列表呢?
- 城市列表解析器, 我们获取到城市名称和url, 点解url, 要进入的是城市解析器. 所以这里的解析器应该是城市解析器.
- 城市解析器. 我们进入城市以后, 会获取用户的姓名和用户详情页的url. 所以这里的解析器, 应该传的是用户解析器.
- 用户解析器. 用来解析用户的信息. 保存入库
项目架构
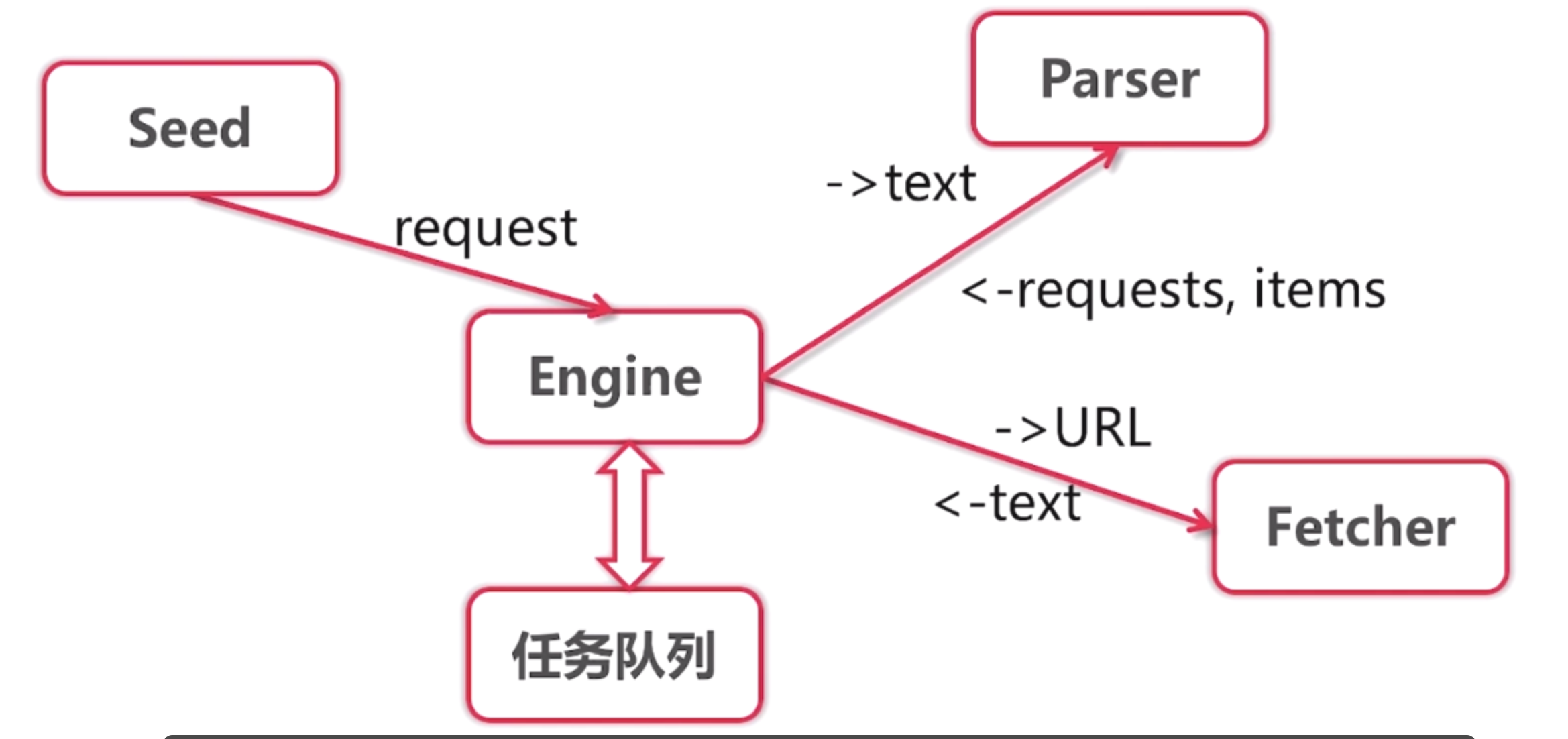
1. 有一个或多个种子页面, 发情请求到处理引擎. 引擎不是马上就对任务进行处理的. 他首先吧种子页面添加到队列里去
2. 处理引擎从队列中取出要处理的url, 交给提取器提取页面内容. 然后将页面内容返回
3. 将页面内容进行解析, 返回的是Request{URL, Parse}列表和 Items列表
4. 我们将Request添加到任务队列中. 然后下一次依然从任务队列中取出一条记录. 这样就循环往复下去了
5. 队列什么时候结束呢? 有可能不会结束, 比如循环推荐, 也可能可以结束.
这样,结构都有了, 入参出参也定义好了, 接下来就是编码实现
我们先来改写上面的抓取城市列表
项目结构
1. 有一个提取器
2. 有一个解析器. 解析器里应该有三种类型的解析器
3. 有一个引擎来触发操作
4. 有一个main方法入口
第一步: Fetcher--提取器
package fetcher import ( "fmt" "io/ioutil" "net/http" ) // 抓取器 func Fetch(url string) ([]byte, error) { // 第一步, 通过url抓取页面 client := http.Client{} request, err := http.NewRequest("GET", url, nil) request.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36") resp, err := client.Do(request) //resp, err := http.Get(url) if err != nil { return nil, fmt.Errorf("http get error :%s", err) } defer resp.Body.Close() if resp.StatusCode != http.StatusOK { return nil, fmt.Errorf("http get error errCode:%d", http.StatusOK) } // 读取出来body的所有内容 return ioutil.ReadAll(resp.Body) }
第二步: 有一个城市解析器
package parser import ( "aaa/crawler/zhenai/engine" "regexp" ) const cityListRegexp = `<a[^href]*href="(http://www.zhenai.com/zhenghun/[a-z1-9]+)"[^>]*>([^<]+)</a>` func ParseCityList(content []byte) (engine.ParseResult) { re := regexp.MustCompile(cityListRegexp) all := re.FindAllSubmatch(content, -1) pr := engine.ParseResult{} count := 1 for _, line := range all { req := engine.Request{ Url:string(line[1]), ParseFun: ParseCity, } pr.Req = append(pr.Req, req) pr.Items = append(pr.Items, "City: " + string(line[2])) count -- if count <=0 { break } } return pr }
第三步:定义引擎需要使用的结构体
package engine type Request struct { Url string ParseFun func(content []byte) ParseResult } type ParseResult struct { Req []Request Items []interface{} } func NilParse(content []byte) ParseResult{ return ParseResult{} }
第四步: 抽象出引擎
package engine import ( "aaa/crawler/fetcher" "fmt" "github.com/astaxie/beego/logs" ) func Run(seeds ...Request) { var que []Request for _, seed := range seeds { que = append(que, seed) } for len(que) > 0 { cur := que[0] que = que[1:] logs.Info("fetch url:", cur.Url) cont, e := fetcher.Fetch(cur.Url) if e != nil { logs.Info("解析页面异常 url:", cur.Url) continue } resultParse := cur.ParseFun(cont) que = append(que, resultParse.Req...) for _, item := range resultParse.Items { fmt.Printf("内容项: %s \n", item) } } }
第五步: 定义程序入口
package main import ( "aaa/crawler/zhenai/engine" "aaa/crawler/zhenai/parser" ) func main() { req := engine.Request{ Url:"http://www.zhenai.com/zhenghun", ParseFun: parser.ParseCityList, } engine.Run(req) }
第六步: 城市解析器
package parser import ( "aaa/crawler/zhenai/engine" "regexp" ) const cityRe = `<a[^href]*href="(http://album.zhenai.com/u/[0-9]+)"[^>]*>([^<]+)</a>` func ParseCity(content []byte) engine.ParseResult{ cityRegexp:= regexp.MustCompile(cityRe) subs := cityRegexp.FindAllSubmatch(content, -1) pr := engine.ParseResult{} for _, sub := range subs { name := string(sub[2]) // 获取用户的详细地址 re := engine.Request{ Url:string(sub[1]), // 注意, 这里定义了一个函数来传递, 这样可以吧name也传递过去 ParseFun: func(content []byte) engine.ParseResult { return ParseUser(content, name) }, } pr.Req = append(pr.Req, re) pr.Items = append(pr.Items, "Name: " + string(sub[2])) } return pr }
城市解析器和城市列表解析器基本类似. 返回的数据是request和用户名
第七步: 用户解析器
package parser import ( "aaa/crawler/zhenai/engine" "aaa/crawler/zhenai/model" "regexp" "strconv" "strings" ) // 个人基本信息 const userRegexp = `<div[^class]*class="m-btn purple"[^>]*>([^<]+)</div>` // 个人隐私信息 const userPrivateRegexp = `<div data-v-8b1eac0c="" class="m-btn pink">([^<]+)</div>` // 择偶条件 const userPartRegexp = `<div data-v-8b1eac0c="" class="m-btn">([^<]+)</div>` func ParseUser(content []byte, name string) engine.ParseResult { pro := model.Profile{} pro.Name = name // 获取用户的年龄 userCompile := regexp.MustCompile(userRegexp) usermatch := userCompile.FindAllSubmatch(content, -1) pr := engine.ParseResult{} for i, userInfo := range usermatch { text := string(userInfo[1]) if i == 0 { pro.Marry = text continue } if strings.Contains(text, "岁") { age, _ := strconv.Atoi(strings.Split(text, "岁")[0]) pro.Age = age continue } if strings.Contains(text, "座") { pro.Xingzuo = text continue } if strings.Contains(text, "cm") { height, _ := strconv.Atoi(strings.Split(text, "cm")[0]) pro.Height = height continue } if strings.Contains(text, "kg") { weight, _ := strconv.Atoi(strings.Split(text, "kg")[0]) pro.Weight = weight continue } if strings.Contains(text, "工作地:") { salary := strings.Split(text, "工作地:")[1] pro.Salary = salary continue } if strings.Contains(text, "月收入:") { salary := strings.Split(text, "月收入:")[1] pro.Salary = salary continue } if i == 7 { pro.Occuption = text continue } if i == 8 { pro.Education = text continue } } pr.Items = append(pr.Items, pro) return pr }
看一下抓取的效果吧
抓取的城市列表

抓取的某个城市的用户列表

具体某个人的详细信息
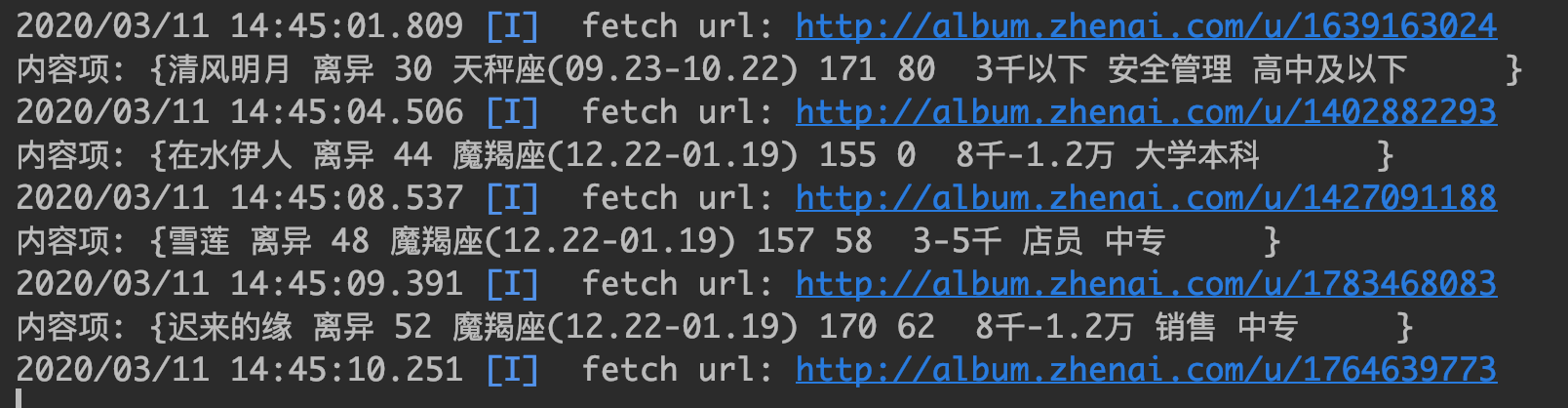
至此, 完成了单机版爬虫. 再来回顾一下.
做完了感觉, 这个爬虫其实很简单, 之前用java都实现过.只不过这次是用go实现的
- 有一个种子页面, 从这个页面进来, 会获取到源源不断的用户信息
- 遇到一个403的问题. 需要使用自定义的http请求, 设置header 的User-agent,否则服务器请求被拒绝
- 使用函数式编程. 函数的特点就是灵活. 灵活多变. 想怎么封装都行. 这里是在cityParse解析出user信息的时候,使用了函数式编程.把用户名传递过去了
二. 并发版网络爬虫
三. 分布式网络爬虫


 浙公网安备 33010602011771号
浙公网安备 33010602011771号