
第十一章 运用广度优先搜索走迷宫
先普及一下, 什么是广度优先搜索
广度优先搜索类似于树的层次遍历。从图中的某一顶点出发,遍历每一个顶点时,依次遍历其所有的邻接点,然后再从这些邻接点出发,同样依次访问它们的邻接点。按照此过程,直到图中所有被访问过的顶点的邻接点都被访问到。
最后还需要做的操作就是查看图中是否存在尚未被访问的顶点,若有,则以该顶点为起始点,重复上述遍历的过程。
广度优先遍历图的方式,是以一种类似波纹扩散的方式进行的,不断放大辐射半径,进而覆盖整张图。
一. 理解广度优先算法
我们要实现的是广度优先算法走迷宫
比如,我们有一个下面这样的迷宫

这个迷宫是6行5列
其中0代表可以走的路, 1代表一堵墙. 我们把墙标上言责, 就如右图所示. 其中(0,0)是起点, (6, 5)是终点.
我们要做的是, 从起点走到终点最近的路径.
这个例子是抛转隐喻, 介绍广度优先算法, 广度优先算法的应用很广泛, 所以, 先来看看规律
1. 分析如何进行广度优先探索
第一步, 我们先明确起点. 这个起点有上下左右四个方向可以探索. 我们按照顺时针顺序探索, 上 左 下 右
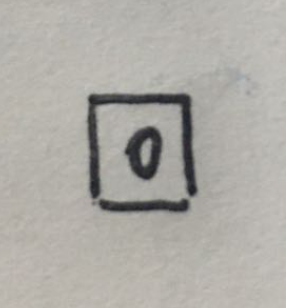
第二步: 起始位置向外探索, 有4个方向.

如上图红色标出的位置. 也就是起始位置可以向外探索的路径有4个. 上 左 下 右
我们再来继续探索.
第三步: 再次明确探索方向是 上 左 下 右
第四步: 探索上方的红1, 上方的红1可以向外探索的路径有3个

第五步: 探索左侧红1, 左侧红1 有两条路径向外探索,
为什么是两个呢? 本来是有3个, 但上面的路径已经被上面的红1探索过了, 所以, 不重复探索的原则, 左侧红1 向外扩展的路径有2条

第六步: 下面的红1 向外探索的路径有2条

第七步: 右侧的红1向外探索的路径, 如上图可见, 只剩下1条了

第二轮探索, 得到的探索结果是:
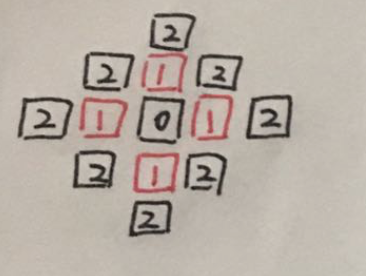
经过第二轮探索, 一共探索出了8条路径, 也就是8个黑2
接下来进行第三轮探索. 顺序依然是顺时针方向,
1. 第一个2向外探索的路径有3条
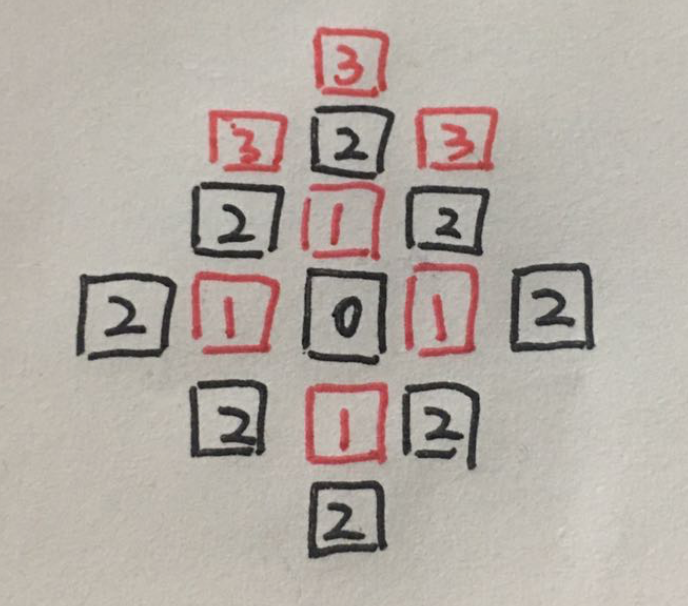
2. 第二个黑2向外探索的路径只有1条
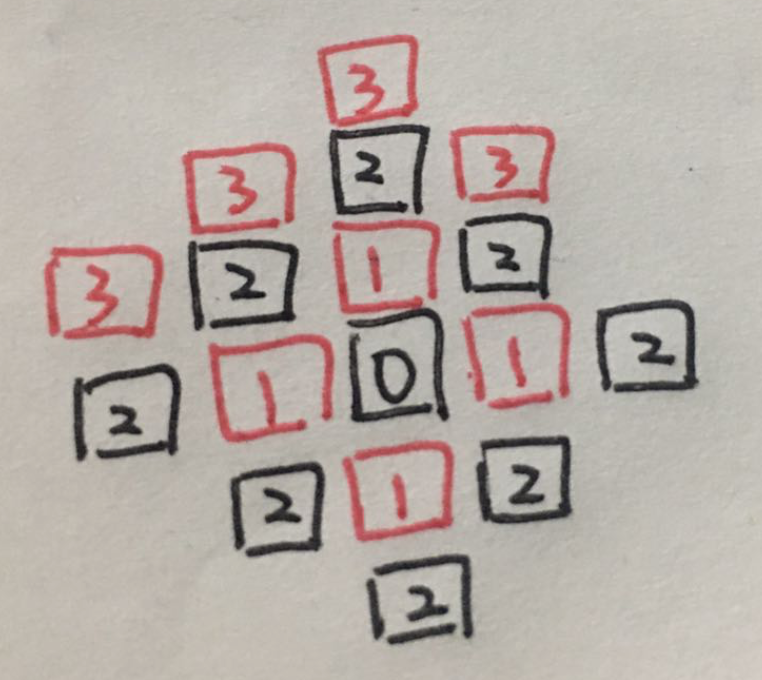
3. 第三个黑2向外探索的路径有2条

4. 第四个黑2向外探索的路径有1条

5. 第五个黑2 向外探索的路径有两条

6. 第六个黑2向外探索的路径有1条

7. 第七个黑2向外探索的路径有两条

8. 第8个黑2向外探索的路径为0条. 已经没有路径. 所以不再向外探索
通过第三轮向外探索, 我们探索出来了12条路径.
这是有的节点可以向外探索3条路径,有的可以向外探索2条路径, 有的向外探索1条路径, 有的没有路径可以向外探索了.
总结:
通过上面的例子, 我们可以看到每个节点的3中状态. 我们来分析一下, 有哪三种状态.
刚开始, 只有一个其实位置0. 这个0是已知的, 还没有开始向外探索. 外面还有好多等待探索的节点. 所以,此时的0, 是已经发现还未探索的节点
当0开始向外探索, 探索到4个1, 这时候0就变成了已经发现且已经探索的节点. 二1变成了一经发现还未探索的节点. 其实此时外面还有3, 4, 5 这些还未被发现未被探索的节点.
我们通过分析, 广度优先算法还有一个特点, 那就是循环遍历, 第一轮的红1都探索完了, 在进行黑2的探索, 不会说红1探索出来一个, 还没有全部完成,就继续向外探索.
总结规律如下:
1. 节点有三种状态
a. 已经发现还未探索的节点
b. 已经发现并且已经探索的节点
c. 还未发现且未探索的节点
2. 阶段探索的顺序
按照每一轮全部探索完,在探索下一轮, 这样就形成了一个队列, 我们把已经发现还未探索的节点放到队列里
接下来我们开始探索了.
首先, 我们知道迷宫的起始位置, (0,0)点. 当前我们站在起始位置(0,0), 那么这个起点就是已经发现还未探索的节点.
我们定义一个队列来存放已经发现但还未探索的节点
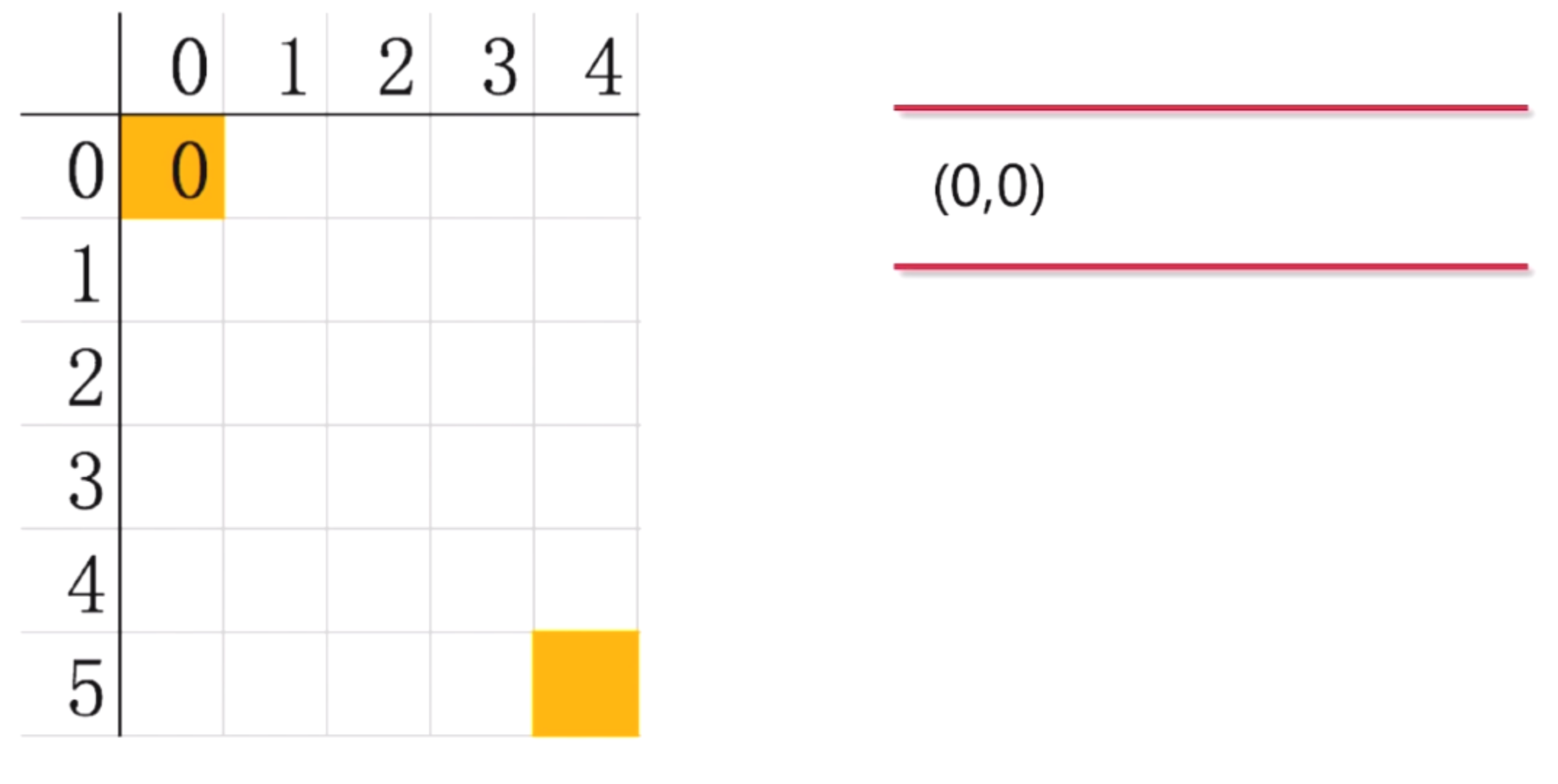
第二步: 从队列中取出节点(0,0), 开始下一步探索.我们看看迷宫最终的样子
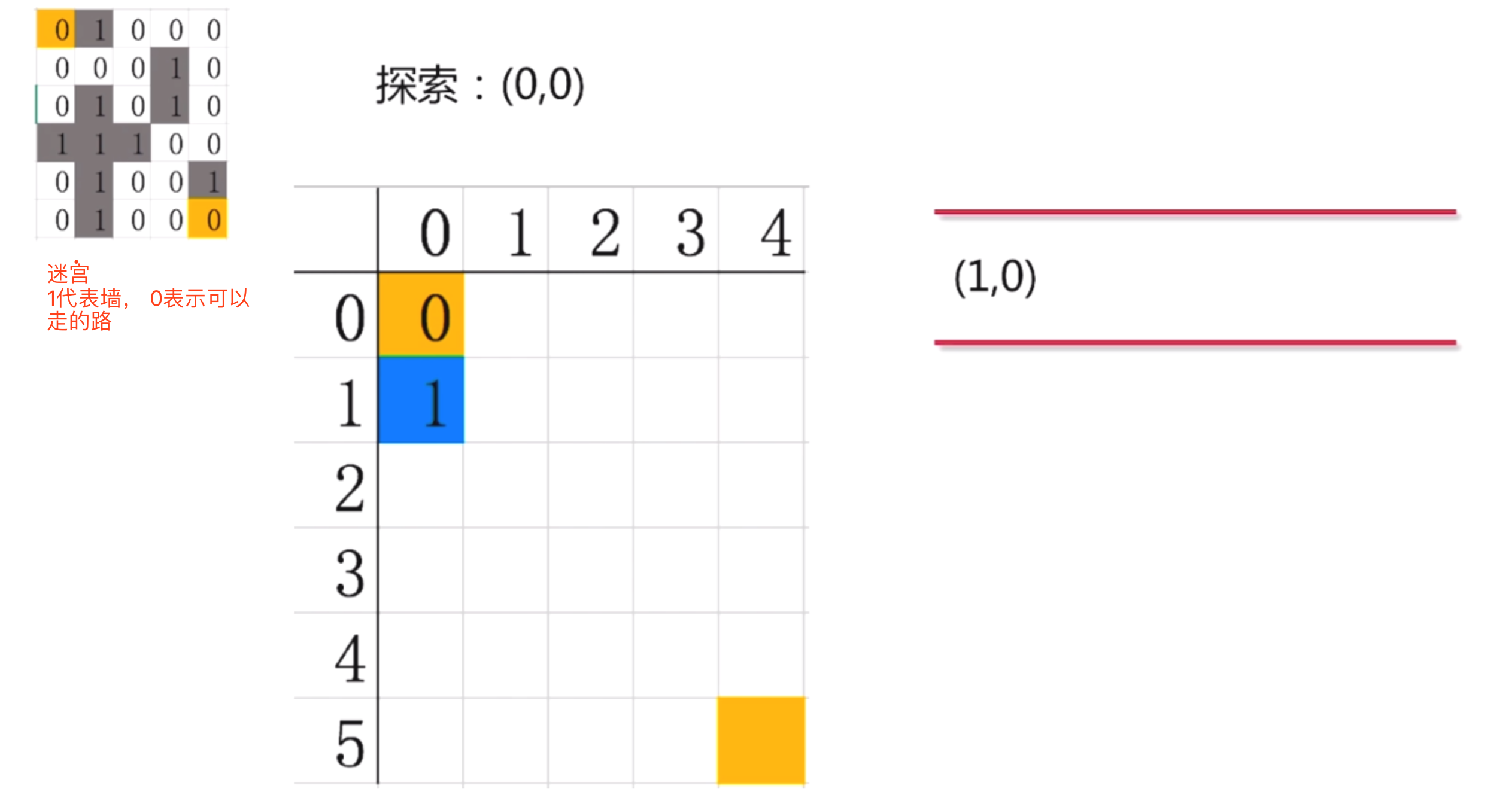
我们看到(0,0)只能向下走, 他的右边是一堵墙, 走不了. 上面,左面也不能走. 所以, 探索出来的路径只有一个(1,0), 吧(1,0)放入到队列中
第三步: 我们在从队列中把(1,0)取出来进行探索, 这时队列就空了.
对照迷宫, (1,0)可以向下走, 可以向右走. 不能向上和向左. 因此, (1,0)探索出来两条路, (2,0) 和(1,1), 把这两个点放入到队列中
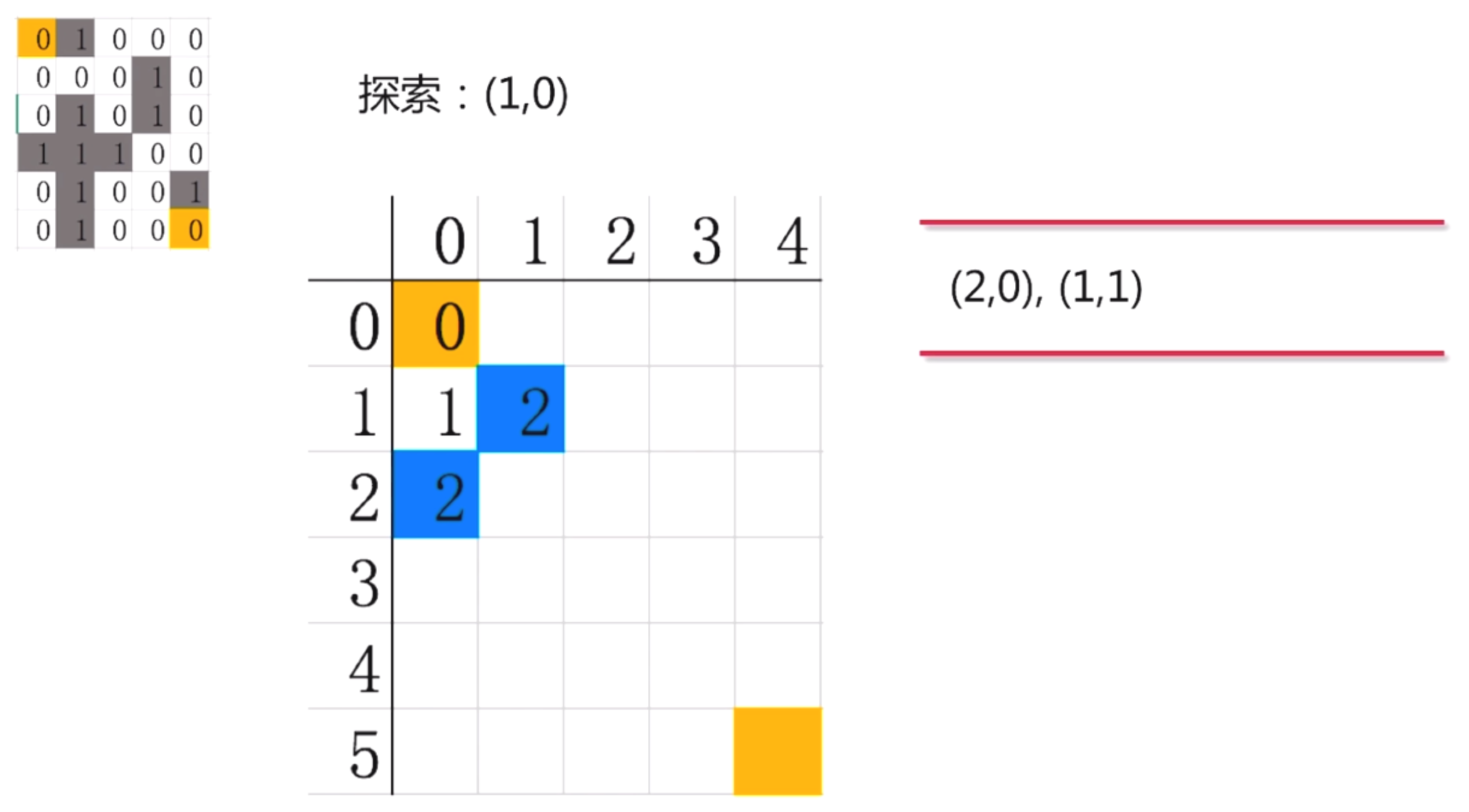
第四步: 接下来我们来探索(2,0)这个点, 对照迷宫, 我没发现(2,0)这个点下和右都是墙, 左不能走, 上就走回去了也不可以. 所以, (2,0)是个死路, 探索出来的路径是0
第五步: 继续探索(1,1), 对照迷宫, (1,1)只能向右探索到(1,2) , 因此我们把(1,2)放入队列中

第六步:对(1,2)继续探索, 发现有两条路径可以走(2,2)和(0,2), 然后, 将这两个点放到队列中
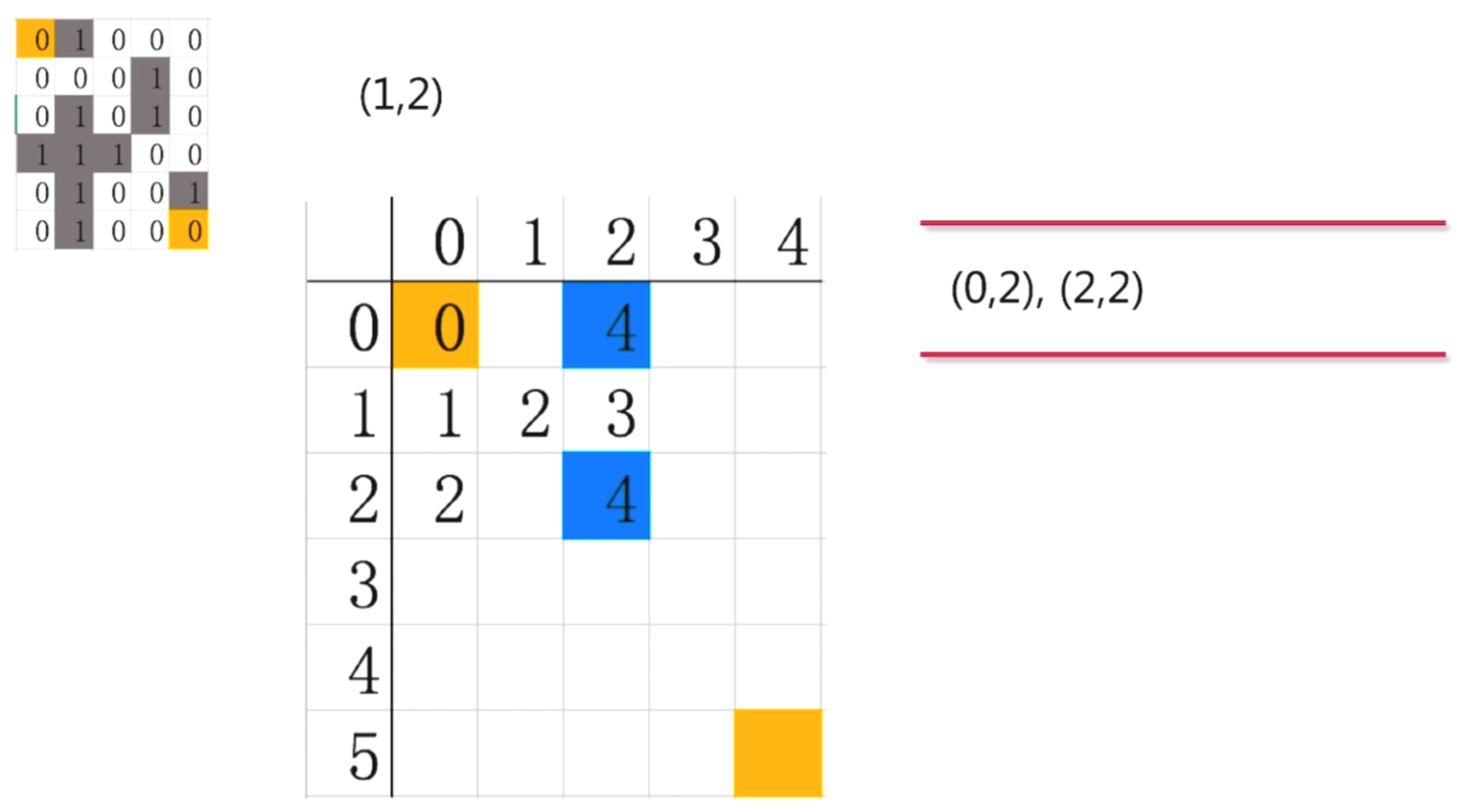
第七步: 接下来继续这样探索下去, 一直走一直走, 走到最后就是这样的
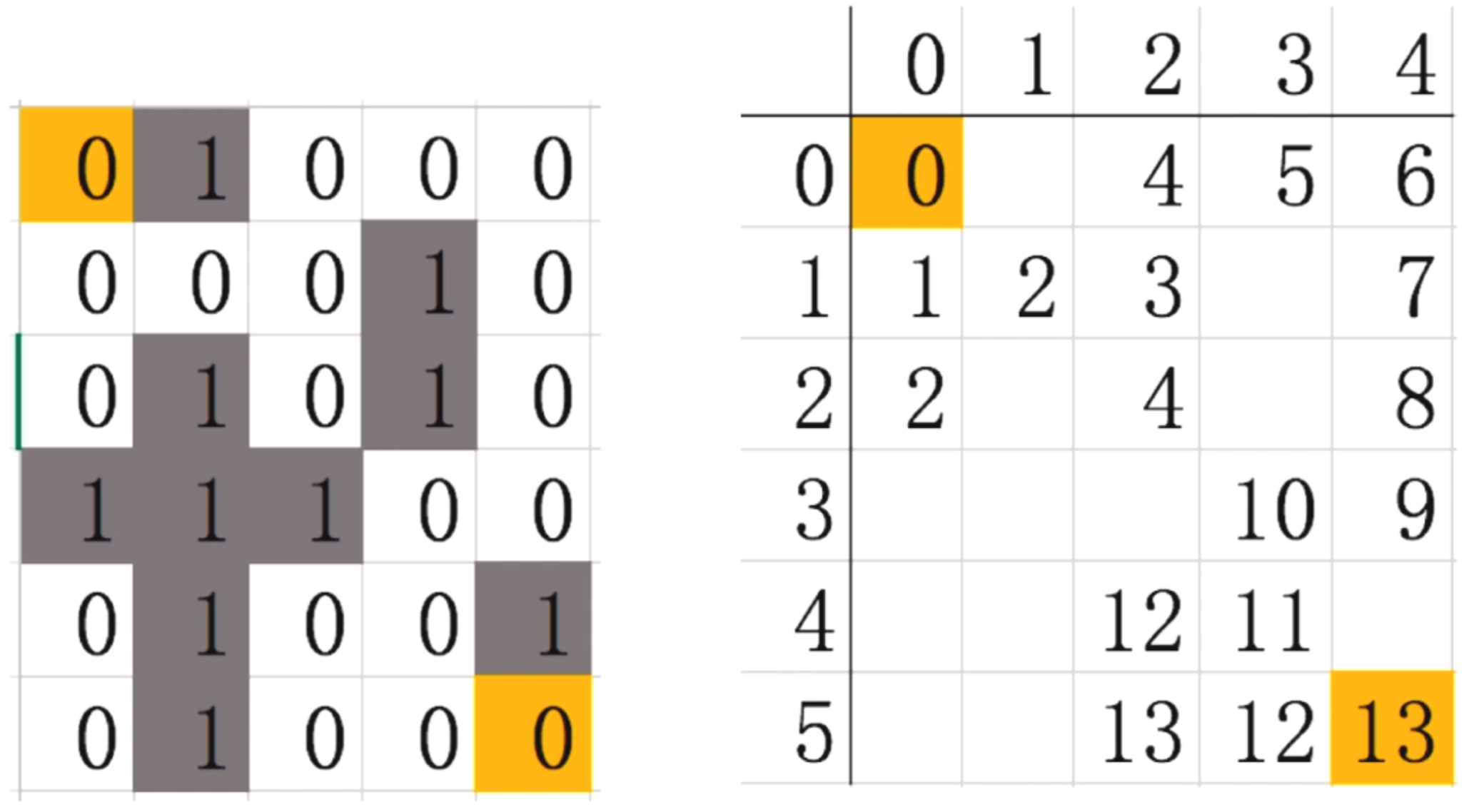
那我们要怎么来判断路径呢? 倒过来走, 从13开始, 上一个数12, 只有一个, 12上面只有一个数是11, 只有一个, 一次类推, 一直找到1, 找到0.
第八步: 广度优先算法, 什么时候结束呢? 两种情况
第一种: 走到最后13的位置
第二种: 死路, 走到一个位置, 不能再走了. 如何判断呢?队列中没有可探索的点了, 探索结束
我们来总结一下:
1. 从(0,0)点开始, 将已经发现还未探索的点, 放入到队列中.
2. 从队列中取出已经发现还未探索的节点, 进行探索, 探索的方式是, 像四周探索, 然后把新发现还未探索的节点从队列中取出来.
3. 如何判断呢? 如果当前是一堵墙, 也就是他的value=0, 那么探索失败. 向左探索的时候, 如果左边是(0,*)探索失败. 向上探索的时候, 如果上面是(*,0)探索失败; 像右面探索的时候, 碰到边(*,4)探索失败. 向下探索, 碰到(5,*)探索失败. 也就是, 横向坐标的范围是 0<=x<=4, 纵坐标是 0<=y<=5
4. 已经探索过的节点不要重复探索
代码分析:
1. 队列可以用一个数组来实现. 先进先出
2. 点用二维数据来表示. 但是go中的二维数组的含义是一位数组里的值又是一个数组.比如[][]int, 他是一个一维数组[]int, 里面的值又是一个一维数组.[]int.
那么用在这里就是, 纵坐标表示有6行, 那么他是一个[6]int, 横坐标表示每行里面又是一个数组, 每行有6个元素[5]int, 所以, 这就是一个[6][5]int 有6行5列的数组.
二. 代码实现广度优先算法走迷宫
第一步: step代表从start开始, 走了多少步走到目标点, 最后的路径是通过这个创建出来的, 最后从后往前推就可以算出最短路径 第二步: 定义一个队列, 用来保存已经发现还未探索的点, 队列里的初始值是(0,0)点 第三步: 开始走迷宫, 走迷宫退出的条件有两个 1. 走到终点, 退出 2. 队列中没有元素, 退出 第四步: 判断坐标是否符合探索的要求 1. maze at next is 0 2. and setp at next is 0, 如果step的值不是0 ,说明曾经到过这个点了, 不能重复走 3. next != start 处理特殊点, (0,0)点 第五步: 已经找到这个点了, 计算当前的步数, 并加入队列中
package main import ( "fmt" "os" ) func readFile(filename string) [][]int{ // 定义一个行和列,用来接收迷宫是几行几列的数组 var row, col int file, e := os.Open(filename) if e != nil { panic("error") } defer file.Close() fmt.Fscan(file, &row, &col) // 定义一个数组 // 注意: 定义数组的时候, 我们只要传入几行就可以了. // 二维数组的含义, 其实质是一个一维数组, 一维数组里每一个元素又是一个数组 maze := make([][]int, row) for i := 0; i < len(maze); i++ { maze[i] = make([]int, col) for j := 0; j < len(maze[i]); j++ { fmt.Fscan(file, &maze[i][j]) } } return maze } type point struct { i, j int } // 当前节点, 向四个方向探索后的节点 // 这里使用的是返回新的节点的方式, 不修改原来的节点. 所以使用的是值拷贝,而不是传地址 func (p point) add(dir point) point{ return point{p.i + dir.i, p.j + dir.j } } // 获取某个点的坐标值 // 同时判断这个点有没有越界, 返回的是这个值是否有效 // return 第一个参数表示返回的值是否是1, 是1表示撞墙了 // 第二个参数表示返回的值是否不越界, 不越界返回true, 越界,返回false 就和你 func (p point) at(grid [][]int) (int, bool) { if p.i < 0 || p.i >= len(grid) { return 0, false } if p.j <0 || p.j >= len(grid[0]) { return 0, false } return grid[p.i][p.j], true } // 定义要探索的方向, 上下左右四个方向 var dirs = []point { point{-1, 0}, point{0, -1}, point{1, 0}, point{0, 1}, } // 走迷宫 func walk(maze [][]int, start, end point) [][]int { // 第一步: step代表从start开始, 走了多少步走到目标点, 最后的路径是通过这个创建出来的, 最后从后往前推就可以算出最短路径 // 2. 通step还可以知道哪些点是到过的, 哪些点是没到过的 step := make([][]int, len(maze)) for i := range step { // 定义每一行有多少列, 这样就定义了一个和迷宫一样的二维数组 step[i] = make([]int, len(maze[i])) } // 第二步: 定义一个队列, 用来保存已经发现还未探索的点, 队列里的初始值是(0,0)点 Que := []point{start} // 第三步: 开始走迷宫, 走迷宫退出的条件有两个 // 1. 走到终点, 退出 // 2. 队列中没有元素, 退出 for len(Que) > 0 { // 开始探索, 依次取出队列中, 已经发现还未探索的元素 // cur 表示当前要探索的节点 cur := Que[0] // 然后从头拿掉第一个元素 Que = Que[1:] // 如果这个点是终点, 就不向下探索了 if cur == end { break } // 当前节点怎么探索呢? 要往上下左右四个方向去探索 for _, dir := range dirs { // 探索下一个节点, 这里获取下一个节点的坐标. 当前节点+方向 next := cur.add(dir) // 判断坐标是否符合探索的要求 // 1. maze at next is 0 // 2. and setp at next is 0, 如果step的值不是0 ,说明曾经到过这个点了, 不能重复走 // 3. next != start 处理特殊点, (0,0)点 // 探索这个点是否是墙 val, ok := next.at(maze) if !ok || val == 1 { continue } // 探索这个点是否已经走过 val, ok = next.at(step) if val != 0 || !ok { continue } // 走到起始点了, 返回 if next == start { continue } // 已经找到这个点了, 计算当前的步数 curval, _ := cur.at(step) // 当前这一步的步数 step[next.i][next.j] = curval + 1 // 下一步是当前步数+1 Que = append(Que, next) // 将下一步节点放入到队列中 } } return step } func main() { maze := readFile("maze/maze.in") steps := walk(maze, point{0, 0}, point{len(maze) - 1, len(maze[0]) - 1}) // len(maze)-1, len[maze[0]]-1 是终点 // 0,0是起始点 for _, row := range steps { for _, val := range row { fmt.Printf("%3d", val) } fmt.Println() } }
--------------------------
参考资料:
1. https://www.cnblogs.com/mrf1209/p/10021966.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号