
在现场发现自己负责程序中数据加载很慢,于是将对应的SQL拿出来放到达梦客户端执行,发现一天中的大部分时间都很慢,只有在早上9点多左右的时候会比较快,快的时候在一秒之内,慢的时候有时达到十几分钟,甚至直接报错,如下图1所示:

图1
对应的SQL该加的索引也都有,数据表也根据月份进行了分区,何况在执行快的时候在0.6秒左右也还可以,于是想是不是其它原因导致执行变慢了,于是有了以下的探索。
通过V$SESSIONS视图查询找对该SQL的sess_id:
select sess_id,sql_text
from V$SESSIONS
where state = 'ACTIVE';
找出对应SQL的sess_id后,在V$SQL_STAT视图(语句级资源监控)查询该SQL语句的执行监控情况,SQL语句如下:
select S.*
from V$SQL_STAT S
WHERE S.SESSID = '139454492043355';
结果如下图2所示:

图2
IO_WAIT_TIME即I/O等待时间是857846毫秒,14分钟多,也就是说SQL执行中的时间基本上都浪费在I/O等待中了。
这是从视图监控方面得出的结论,接下来连接DM服务器查询服务器的性能。
通过iostat -d -x -k 1 10 命令查询(查询磁盘使用情况的详细信息,以KB为单位,每秒刷新一次,共刷新10次),截图部分如下图3所示:

图3
输出信息的含义如果有兴趣大家可以在网上进行查询,以下主要介绍avgqu-sz、await、svctm、%util四个指标:
avgqu-sz:平均未完成的IO请求数量,即平均意义上的请求队列长度。
await: 每一个IO请求的处理的平均时间(单位是毫秒)。此处理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
svctm :表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长, 系统上运行的应用程序将变慢。
%util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.6秒在处理IO,而0.4秒闲置,那么该设备的%util = 0.6/1 = 60%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
通过以上两个方面可基本判定磁盘I/O等待时间过长,设备已经接近满负荷运行了,此时与与SQL优化已经没多大关系了。
接下来看达梦库服务的内存占用情况与服务器的内存剩余情况,如下图4和图5所示:


图4
由上图4可以看出DM服务占用的CPU使用率是138%,内存使用率是76.1%,占用的内存大小为25076020KB即将近24G。
接下来通过top -H -p 20589(达梦服务PID号)来进行查询。
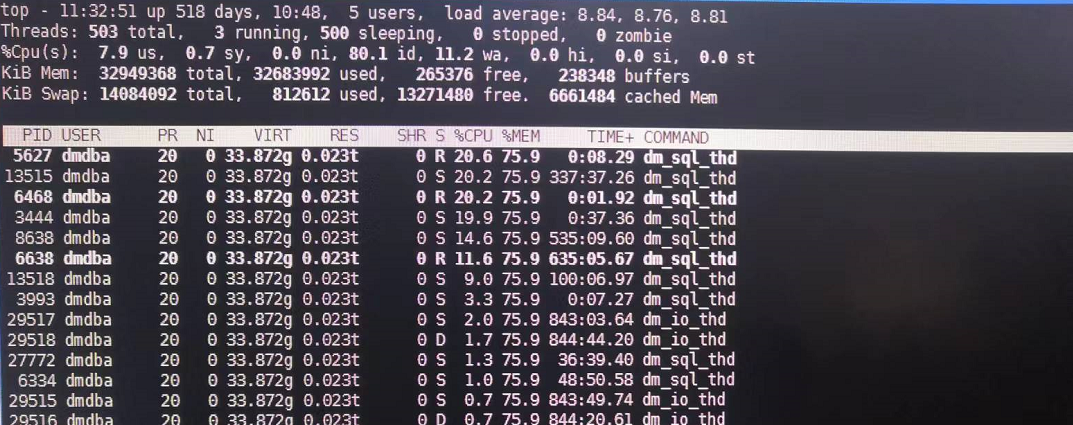
图5
由上图5可以看出服务器的物理内存共约32G,大部分已被使用,只剩下两百多兆的物理内存空间空闲。
接下来看看达梦性能监视工具monitor.exe的监视情况,如下图6和图7所示:
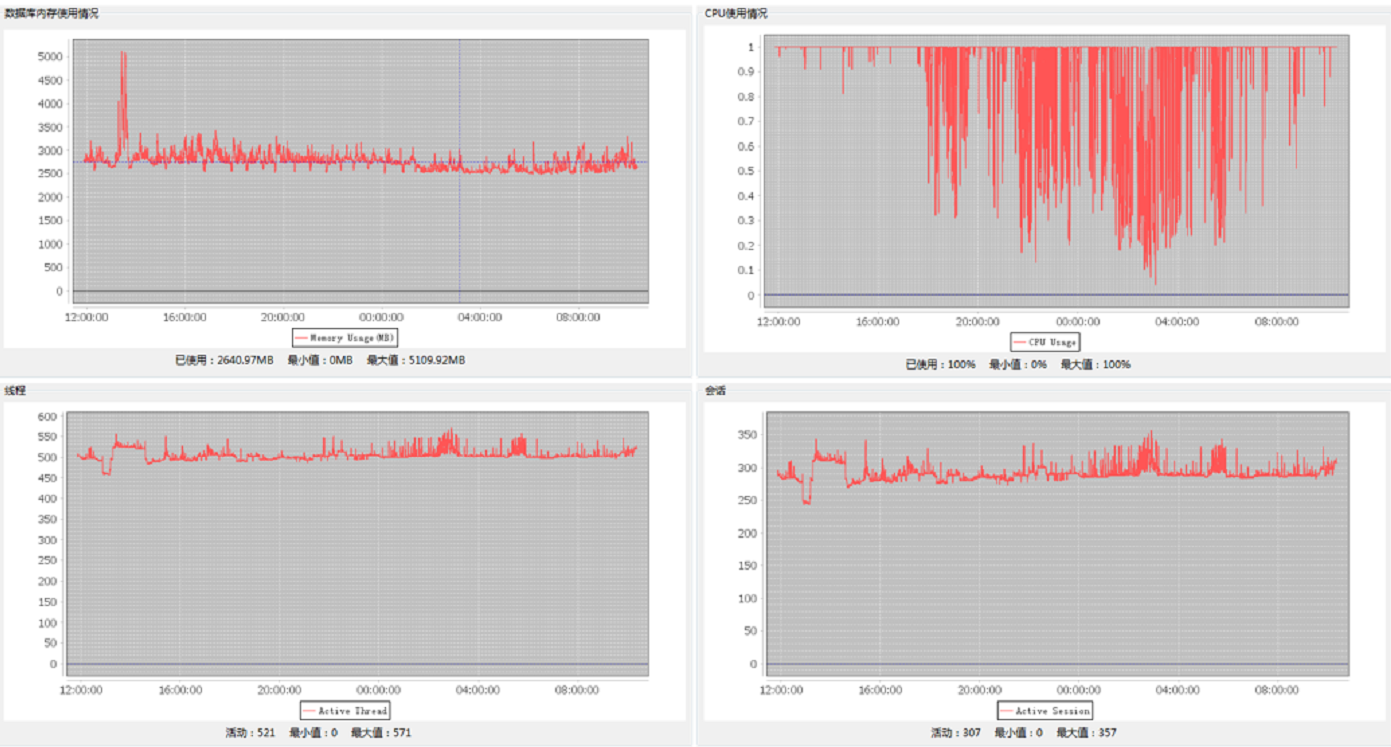
图6
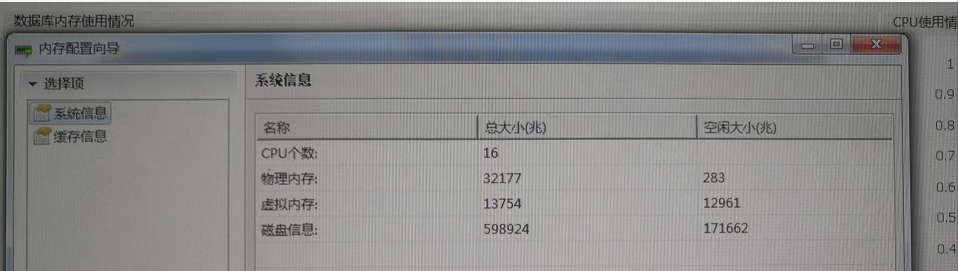
图7
由上图6中的第二张图可以看出CPU经常属于满荷负载状态,从图7的内存配置向导对话框中可以看出数据库服务器的物理内存空闲的只剩下283兆;从图6第一张图看数据库内存的使用大约2G多一些,这点和根据从V$MEM_POOL(显示所有的内存池信息)查询进行侧面验证,SQL如下所示:
SELECT SUM(total_size) as totalS,sum(data_size) as data_sizeS,count(1) as countS
FROM V$MEM_POOL
执行结果如下图8所示:
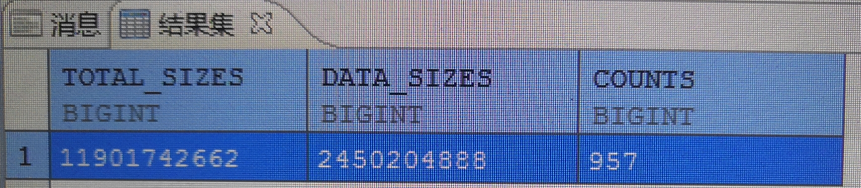
图8
其中TOTAL_SIZE字段为当前总大小,以字节为单位;DATA_SIZE为当前分配出去的数据占用大小,以字节为单位.DATA_SIZES值大约为2G多,两者相差不大。
通过以上的分析可以得出该SQL慢的原因主要是设备已经满负荷运行,I/O等待时间过长所导致。此处一方面的解决办法是加大内存或建立集群进行主从同步,读写分离,更重要的是要查找占用内存过大的SQL,对其进行优化,毕竟内存的扩充是有尽头的,不可能无限制扩充,读写分离也只是减轻了一部分负担,随着服务运行时间的日积月累,这种问题还会继续出现!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号