项目展示$\alpha$
| 项目 | 内容 |
|---|---|
| 课程:北航-2020-春-软件工程 | 博客园班级博客 |
| 要求 | 强制转会与项目展示 |
| 我们在这个课程的目标是 | 提升团队管理及合作能力,开发一项满意的工程项目 |
| 这个作业在哪个具体方面帮助我们实现目标 | 展示项目并总结 |
VisualPytorch发布地址如下:
http://114.115.148.27/static (华为1核1G服务器,未备案)
http://39.97.209.22/static (阿里云1核2G服务器,已备案,可直接通过 http://visualpytorch.top/static 访问)
一、成员简介
个人介绍详见:团队介绍和采访
| “假”相 | 姓名(博客园) | 成员简介 | 角色定位 |
|---|---|---|---|
 |
孙Y | 管控项目进度、成员任务分配、贡献分计算、项目部署、会议组织、项目分享、博客撰写等多种任务。 | PM/后端开发者/项目部署者/博客撰写者 |
 |
钟RH | 提出许多新颖的idea,推动前端部分进度。进行项目的部署并修复了很多bug。 | 前端负责人/项目部署者 |
 |
吴F | 查找了前端模板,实现了模型搭建模块的主要逻辑。 | 前端开发者 |
 |
苏HX | 实现了模型保存及帮助文档的前端逻辑。 | 前端开发者 |
 |
陈CW | 撰写了详细的帮助文档,设计了前后端对接的json接口,推动后端部分进度。 | 后端负责人/文档撰写者 |
 |
许TL | 4月中旬加入团队,在后端进行部分辅助工作。 | 后端开发者 |
二、软件工程
1. 团队概述
- 团队项目的目标:提升团队合作能力,了解工程开发流程,开发一项满意的工程项目
- 预期的典型用户: 学生,deep learning初学者
- 预期的功能描述:继承了上一届的VisualPytorch,宏观架构基本一致。在上一届实现拖拽生成模型代码并提供打包下载、用户登录、访问量统计的基础上,添加更多的网络层,支持封装、经典模型、模型共享等功能,让小白也能亲手实现图像分类、图像分割等功能。具体内容见:功能设计
- 预期的用户数量:alpha阶段注册100人,生成模型数300个
- 团队的产品如何满足了用户的需求:deep learning初学者由于对pytorch不够熟悉,不知道各个网络层以及全局数据的参数应该怎么选择,在看了帮助文档中对他所需参数的大致介绍后,配置出了自己的模型,并生成了代码,成功运行。
2. 事后回顾
-
看到目标用户使用产品的过程和评价,见
用户反馈&bug
-
事先定义的目标达到了么:模型生成数(332)达到了,但注册人数(64)还差一点,可能有以下原因:
- 项目还不足够吸引人:没有满足面向用户的需求,之前预定的封装功能还没有实现
- 使用起来还不方便
- 网站的安全机制,加载速度不尽人意
- 宣传力度还不够
-
团队的成员如何分工协作的?有什么经验教训?
分为前端和后端两部分,由PM进行协调工作。互相之间可能存在误解,因为需求不是非常明确。
-
团队是如何进行项目管理的?
通过github平台每人一个功能分支。
-
团队如何平衡 时间/质量/资源 争取如期完成任务的?
实际上并没有完全按照需求完成任务。由于时间不足,开发仅有两个星期,同时免费版Jsplumb不支持,
网络层封装这一功能还是没有实现,因此在此基础上的经典模型也不能实现。转而实现了扩展更多的静态参数(如损失函数、优化器等)及模型保存。
3. 测试
-
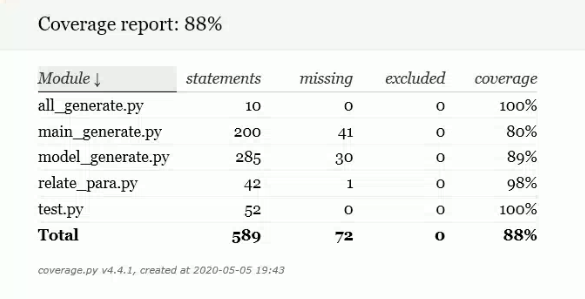
测试用例数目,代码覆盖率数目
-
前后端结合:4个数据集对应的经典模型,从搭建到代码跑通得到正确率结果
-
后端:使用Anaconda的coverage库进行后端覆盖率测试,19个样例(9个测试网络层,9个测试静态参数),总体覆盖率达到88%
-
-
运行测试用例得到代码覆盖率的视频录像
4. 文档与规范
-
代码规范在哪里?NAG小组代码规范
-
齐全的文档在哪里?
- 前后端接口文档:alpha前后端接口文档(一) alpha前后端接口文档(二)
- 使用帮助文档:帮助文档 帮助文档2
- rest api文档:Visual Pytorch
-
有些项目是在原来的基础上改进的,那么我们团队的软件工程项目质量有什么样的提高?
在前端设计与后端编译上有明显的提高。
- 后端:新增了6类网络层,并对原有的网络层参数进行扩充。同时新增多种静态参数(如损失函数、优化器等)
- 前端:对原有页面进行了改进设计,并新增了多个页面,根据后端新增内容添加模型创建页面内容。
- 测试方面,原有项目仅对后端用户注册登录模块进行了自动化测试,本项目则对后端一系列方法进行了自动化测试,大大提升了代码覆盖率。
-
原来的项目有些代码混乱,没有注释,没有详细的文档,你们的项目是如何更好解决这个问题的?明年的同学继续开发这个项目,会不会出现类似的抱怨?如果一个新学生在一台新机器上想编译并运行你的项目, 请问能顺利完成么?有什么样的文档能指导新学生?
- 事实上原有项目留下了详细的接口设计文档,但是仍有大量的框架学习与代码阅读任务。
- 前后端均学习Django/DjangoRestfulFrameWork,后端重点在于修改Json并根据Json输出对应代码,前端重点学习了JS/CSS/HTML/JQuery/Jsplumb等知识,通过修改Bootstrap模板解决了设计问题,通过与后端交流Json传输格式解决了新增网络问题。
- 明年的同学做增量开发时也会面临大量的框架学习与代码阅读任务,其对应的时间投入很难降低(即使我们已经有了详细的前后端接口文档)。
- 编译运行较为简单,根据ReadMe进行实现即可。
5. 需求分析
-
对于项目的目标用户是一般学生的项目, 你们如何找到学生做需求分析?他们给你什么样的反馈?
在需求分析中,我们以组内分析为主,不过也通过询问、调查等方式做了一些需求分析,比如将项目推广给同学时,会收集他们对项目的反馈信息。例如,有同学在使用后反映在项目生成的代码loss有点高,以及网站反应速度不够快的问题,我们将在以后的版本中进行相应调整。
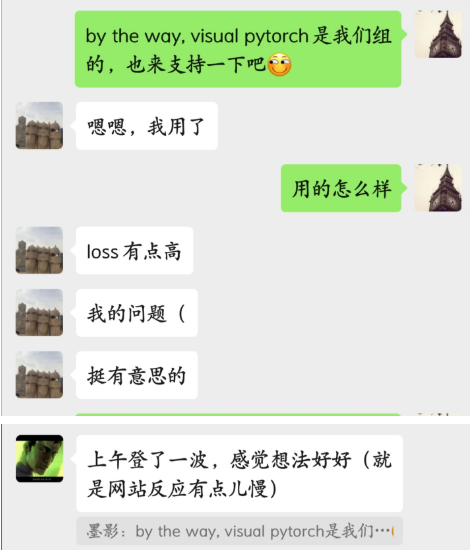
除此之外,我们的项目还提供了问题反馈界面,用户可以直接在项目中反馈相关问题,包括有关用户需求方面的问题。不过,目前还未收到有效的反馈信息。
在接下来的版本中,我们会结合现有项目,做更为深入的需求分析。
-
所有的项目都会收集到用户的数据,请问你们对这类数据做了什么样的分析,这些分析如何验证或推翻了原来的假设?这些数据如何帮助项目改进软件工程的质量?
我们的项目中,共搜集了历史访问量、注册用户数和生成模型数三个数据。
我们分析了访问量的情况,感觉访问量并不如我们的预期,可能是由于我们的宣传力度不够大,也可能是由于对可视化神经网络模型的兴趣没那么高,也可能是生成的代码性能不理想等其他原因。注册用户数和生成模型数也是类似的结论。
三、项目进展
1. 团队项目的实际进展:
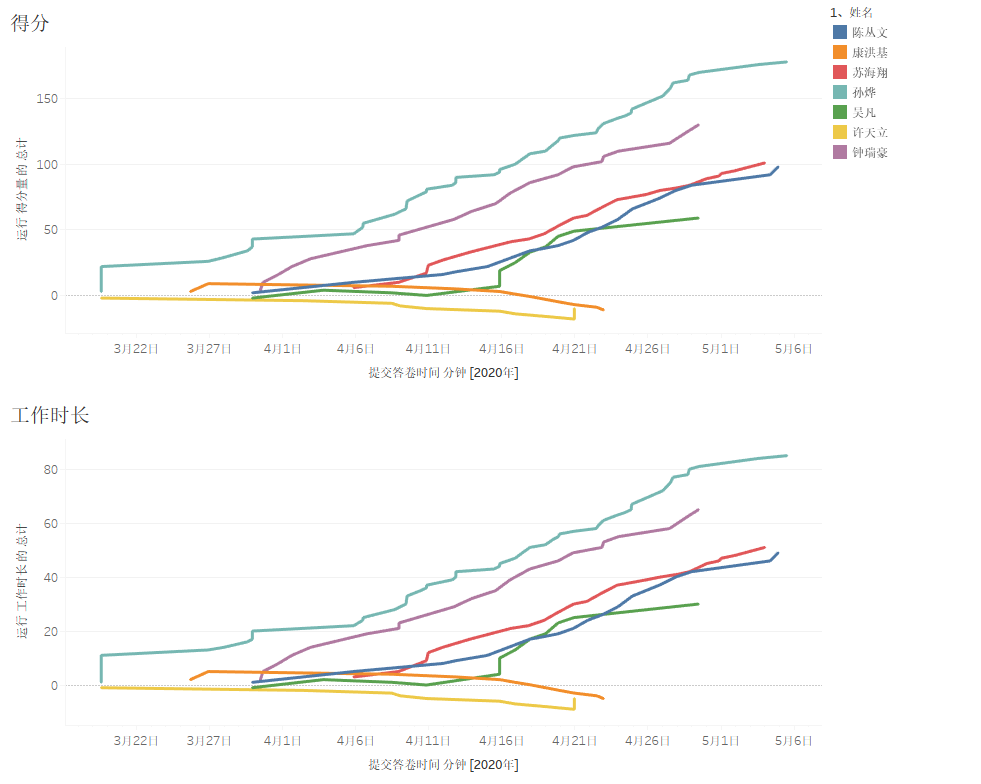
使用了工作记录代替燃尽图,因为其信息含量更大,更能反映小组成员的工作。
2. 发布的功能:
详见发布声明α
3. 在哪里发布了软件, 用户反馈的截屏
菜市场、同学群、博客

四、团队成员在Alpha阶段的角色和具体贡献
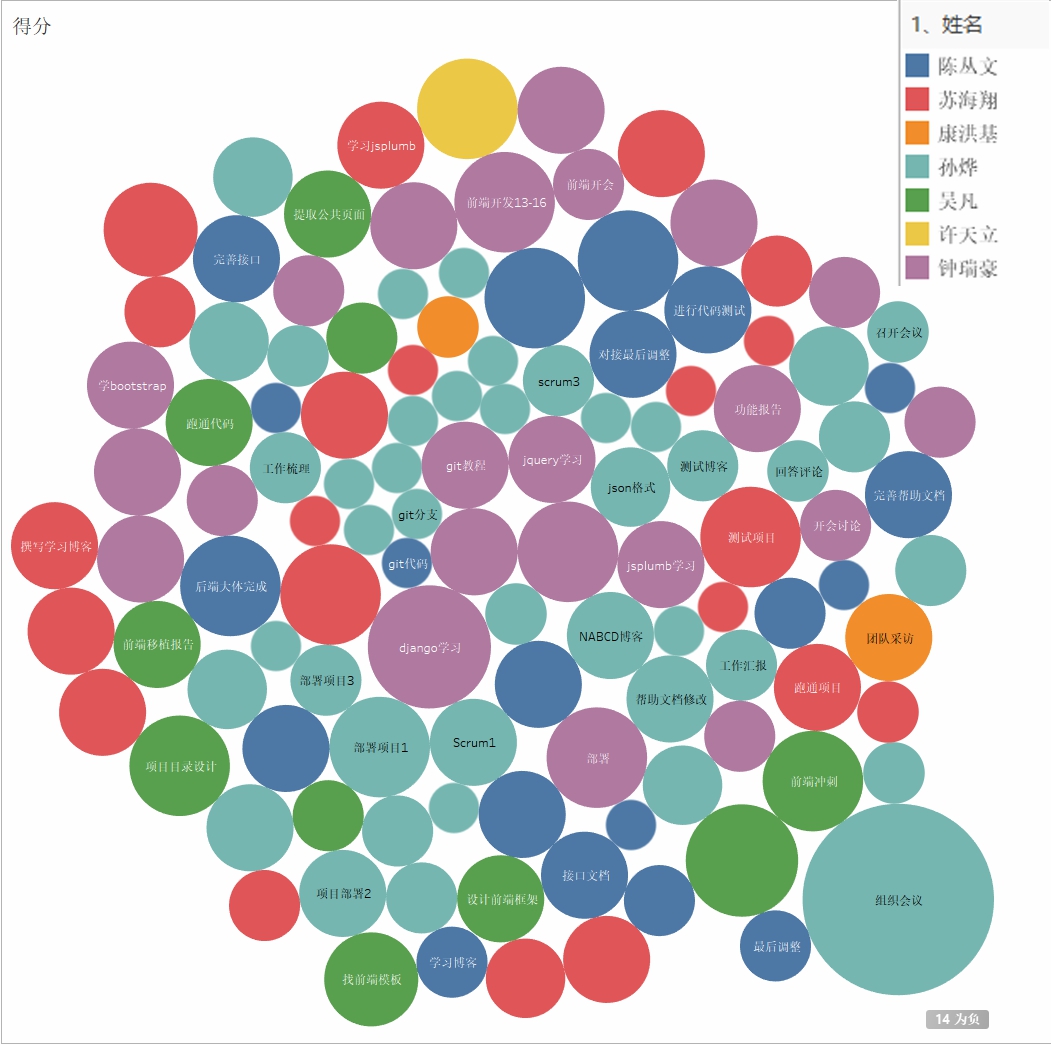
1. 工作记录概览:
2. 互评
0:孙烨;1:钟瑞豪;2:吴凡;3:许天立;4:康洪基;5:陈从文;6:苏海翔
评分规则详见:团队贡献分分配规则
按照团队贡献分=300*(0.7*softmax(工作记录分+50)+0.3*互评分)得到以下结果:
| 名字 | 角色 | 工作记录分 | 互评分 | 团队贡献分 |
|---|---|---|---|---|
| 孙烨 | PM | 178 | 0.15976067589741974 | 68 |
| 钟瑞豪 | 前端Dev | 130 | 0.15553176387411125 | 58 |
| 吴凡 | 前端Dev | 69 | 0.15702927958866533 | 45 |
| 苏海翔 | 前端Test | 101 | 0.1547674682579001 | 52 |
| 陈从文 | 后端Dev | 98 | 0.15643689451435042 | 52 |
| 许天立 | 后端Test | 0 | 0.12225508130759383 | 25 |
五、特色功能
所做软件最有特色的功能是什么,请着重介绍一下。活的用户如何从你的软件中获益的,请现场展示。见 VisualPytorch
| 页面 | 功能描述 | 页面展示 |
|---|---|---|
| 登录界面 | 1、用户的注册功能 2、用户的登录功能 |
 |
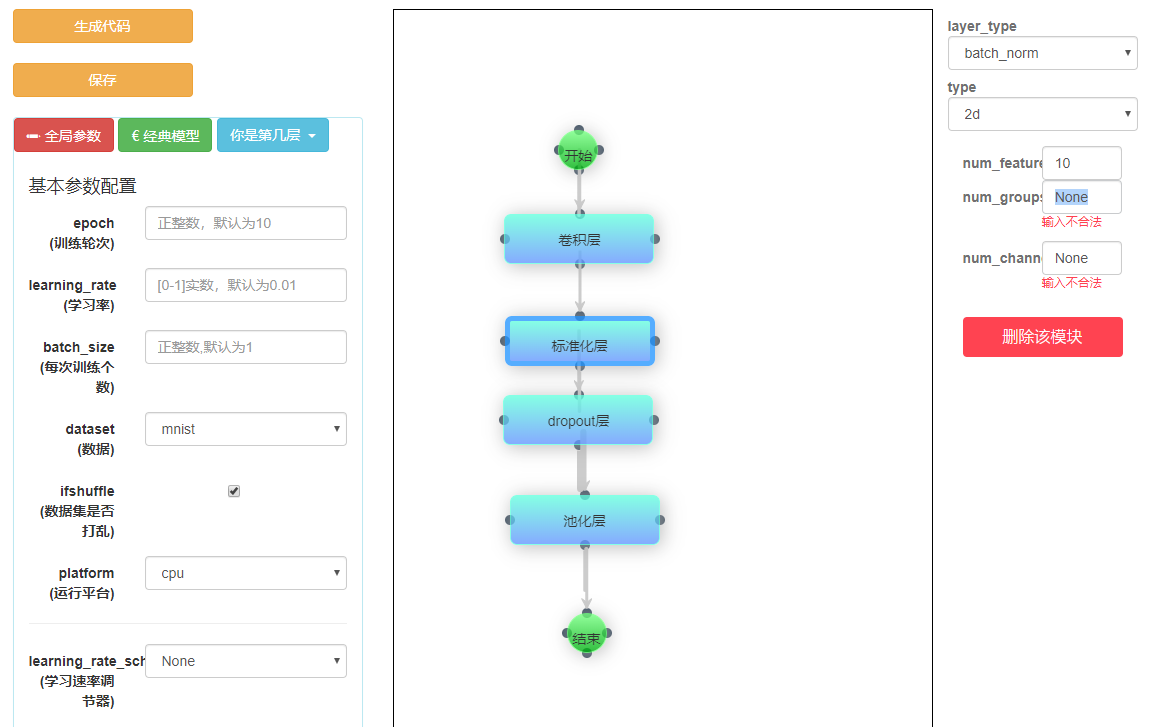
| 框架构建 | 1、个性化构建自己的框架 2、能够保存为自己的个性化构建 3、能够实现参数调整 |
 |
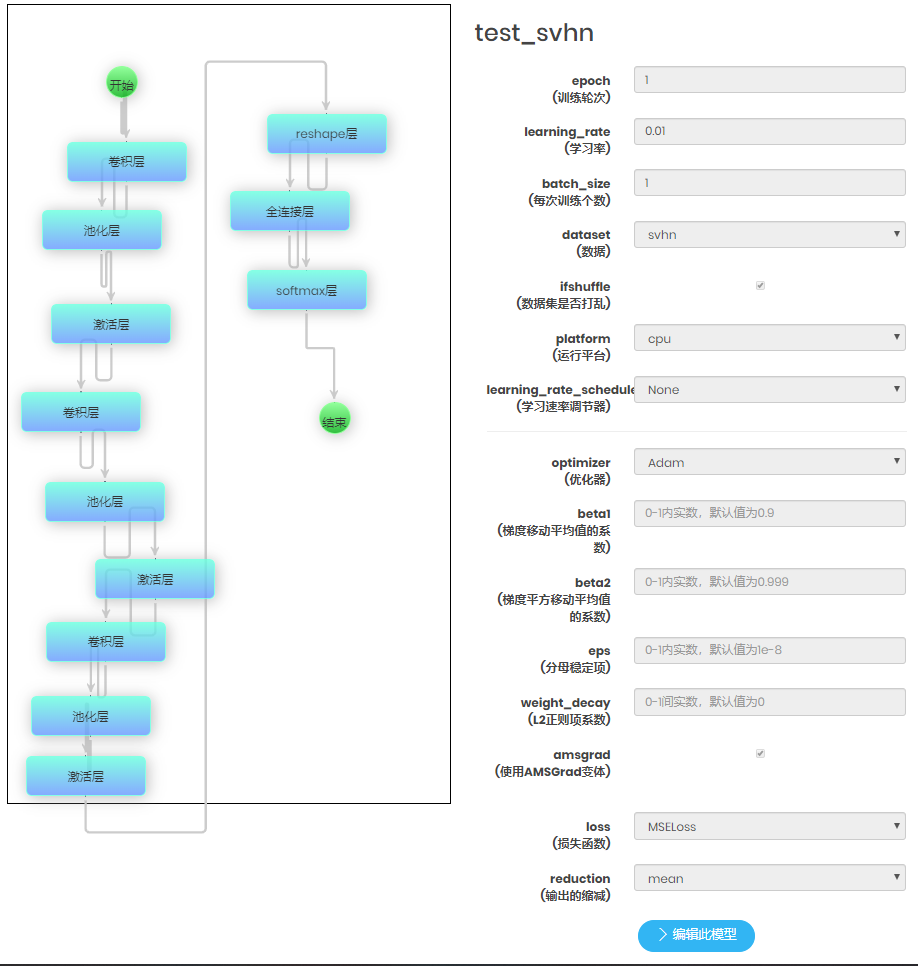
| 模型管理 | 1、模型的删除功能 2、模型的查看 3、导出代码 |
 |
| 代码生成 | 1、根据所选框架生成特定代码 |  |
| 问题反馈 | 1、可以向后台反馈存在的bug 2、可以看到之前反馈问题的应答 |
 |
| 用户统计 | 1、统计网站ip的访问次数,记录用户使用人数 |  |
| 关于我们 | 1、罗列有制作团队的具体信息,可以发邮件进行询问 |  |
| 帮助文档 | 1、动图展示操作方式 2、对模型参数的文档 | 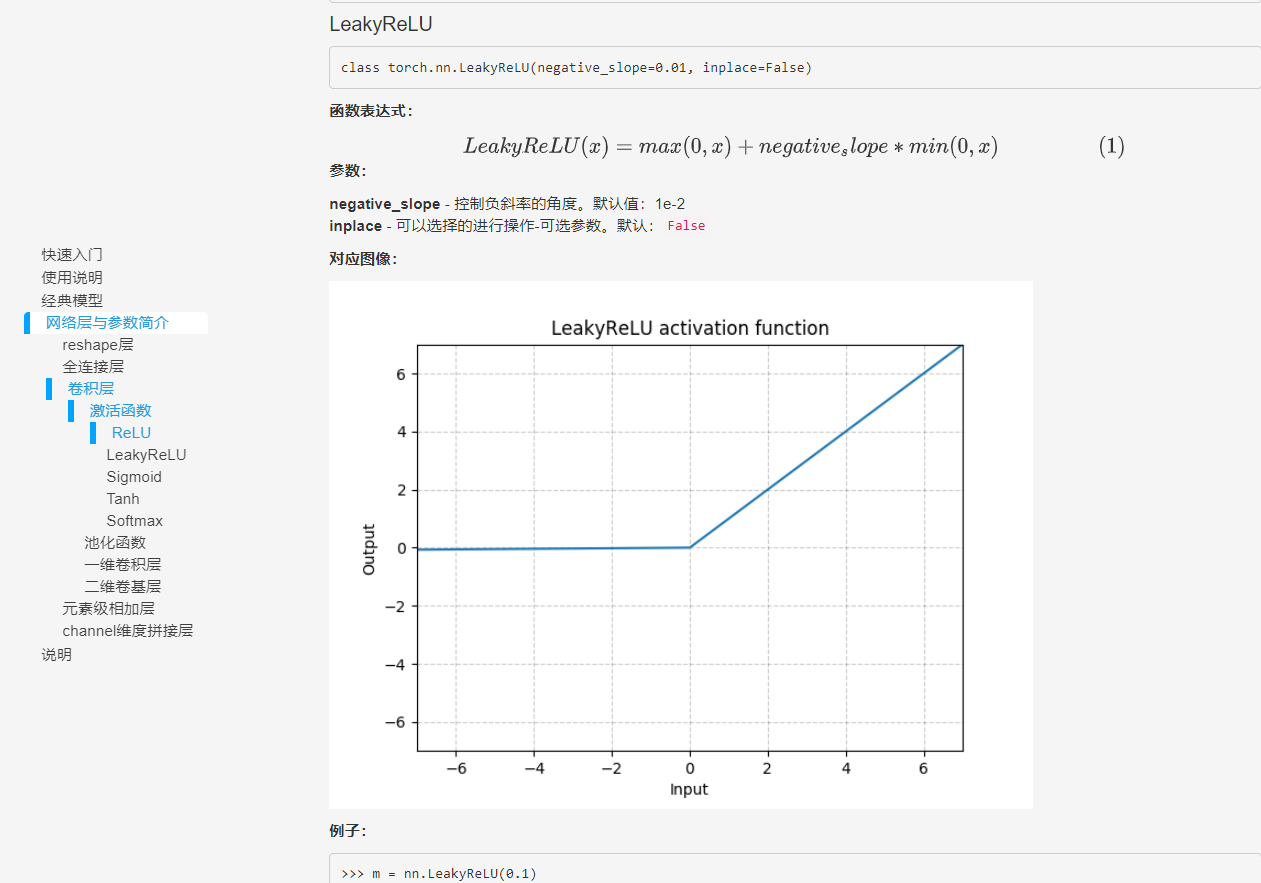 |
六、用户反馈&bug
我们测试得到的bug详见:测试报告α
以下4个评价,在用户体验上反映出了不同的bug:
1. 助教:
用户注册的时候是否会考虑到强校验呢?
试了一下,用户名长度、符号,密码长度、符号没有校验,没有邮箱验证。
安全性这方面,如果想攻击服务器的话,脚本批量发送POST请求会产生垃圾用户数据,量大可能会拖垮服务器。
这确实是我们没有考虑到的bug。
前端JS中对长度是有限制的,比较宽松。后端对应部分直接继承原本项目的代码,未做修改。邮箱验证后续版本会通过django相关插件实现,提升安全性。
2. 昂神:
建议把静态资源整合整合,现在资源请求太多了加载贼慢
还有有条件的话建议挂上cdn
以及感觉还算来得及的话,js部分可以整合整合逻辑,更来得及一点的话,可以干脆换上vue
在1核1G的服务器上挂载的静态资源太多,现已将gif及图片改成外链接的形式,缓解资源请求压力。后续考虑其他缓解方式。
3. 同学A:
不支持经典模型的导出,搭建一个模型对于一个新手来说还是太麻烦
建议设置一些典型的样例,不然根本不知道该怎样操作
本来在\(\alpha\) 阶段应该实现经典模型功能的。实际上后端json已经基本实现了。但无奈卡在了前端工具上,\(\beta\)阶段会实现这一功能。
4. 同学B:
你们的项目对于我来说没有什么吸引力,感觉拖来拖去还没有手写来得方便
建议添加一些新功能,比如inference,实时查看你们代码的效果
这位同学说的的确很正确,我们的项目对于多数人来说没有什么吸引力,很少会有人直接用我们的网站去写代码。后续添加inference(推理)功能,上传训练好的模型在线推理,用户可以在线运行。
七、总结&计划
1. 每人总结
| 总结 | 在Alpha阶段学到了什么 | 对软件工程的教育、课程的批评建议 |
|---|---|---|
| 孙烨 | 对于这一庞大的工程进行分解,合理分工,协作完成。在讨论和会议中锻炼自己组织和管理能力。 了解了如何做一个PM协调小组成员,清晰了项目从设计到发布维护的全过程。 |
老实说,课程设计的不是很人性化,让我想起上学期的无线网络系统:老师以为我们会了一切,却根本不能理解作为刚入门学生进行工程化项目的曲折之路,但是又一边Push进度,提出很多强制要求。 实际上痛苦过后才会有收获,被软工折磨的日日夜夜,成长和收获也是成正比的。 |
| 钟瑞豪 | 系统了解了前后端的各种框架/服务器部署相关知识,增强了与同组同学的合作。 系统了解了软件工程的相关知识并进行了实践 |
与其他老师的平行班级相比,分数基本一致,任务量感觉不在一个数量级。 |
| 吴凡 | 沟通的重要性 | 希望博客少一点 |
| 苏海翔 | 学到了django等模型框架(自己还稍微看了一点其他的框架,比如vue什么的),还有jsplumb这样的插件,掌握了如何快速套用前端模板的方法,同时对前端debug的方法更加熟悉。对于不同功能,不同样式的前端代码,都能快速读懂并进行需要的操作。 | 关于软件工程的教育,我觉得单靠项目+博客的形式,不足以使学生充分学习和体验工程化方法的每个步骤。 个人项目和结对项目的难度有点大,时间也比较紧,自由度也比较低,感觉不像是软件工程课的作业,而是编程课的作业。虽然在代码质量与代码测试方面学习到很多东西,但感觉还是应该选择一些需求比较模糊,而开发难度不是特别大的项目作为软工项目的题目。 另外,虽然课程上并没有明确的限制,但无论是从给定的题目来看,还是从各组最终选定的项目来看,项目的主题大多偏向于学习性质(特别是计算机学习),很多项目均把学生作为典型用户,有些项目的应用场景被限制在校园范围内。虽然这样的选择也有自己的道理,但考虑软件应用的广泛性,适当打开思维,拓宽选题思路也未尝不可。 |
| 陈从文 | pytorch神经网络概念知识,django的使用以及前后端交互和DEBUG的基本流程 了解了团队分工和软件开发的大致流程。 |
可以更多点实践知识少点理论知识,同时让助教参与到项目开发中。 |
| 许天立 | 软件开发的技能很多是我之前从没接触过的。比如说我们这次用的django这个框架,我在这之前就从来没用过,也没接触过任何一种框架。而现有的框架那么多,更新换代那么快,也不能说精通所有的框架,这个时候,学习能力很重要,alpha阶段,我最大的收获可能就是自学的能力 | 无 |
2. Beta阶段大体计划
在接下来的版本中,我们会更多地花时间去支持更多模型的搭建、丰富产品内容、提升用户体验。
包括\(\alpha\)阶段希望实现而尚未实现的:
- 支持网络封装成基本模块
- 经典模型(如U-Net, ResNet, AlexNet, VGG-16等)
已经实现还可以进一步改进的:
- 更精美的可视化
- 帮助文档的撰写
以及需要在未来实现的:
- 模型的本地部署与在线运行
- 集成tensorboard可视化
- 模型分享与交流
- 模型参数分析与可视化
在\(\beta\)阶段,我们会继续努力,争取完成以上预定的目标,提供一个尽可能实现的最好的产品

 浙公网安备 33010602011771号
浙公网安备 33010602011771号