
10.18小测(流量人数统计)
题目要求:给出result.txt文件,导入到mysql中,清洗日期格式,统计视频流量,可视化展示。
需要数据分析的内容:
(1)统计最受欢迎的视频/文章的Top10访问次数 (video/article)
(2)按照地市统计最受欢迎的Top10课程 (ip)
(3)按照流量统计最受欢迎的Top10课程 (traffic)
软件准备:要准备虚拟机,zookeeper,hadoop,hive,正常启动服务。
这些都可以在尚硅谷或者黑马视频学习教程里安装,按着步骤来不会错的。
数据格式:
有俩个思路:
一种是把result.txt导入本地mysql中,完成日期格式清洗,再导入到hive中,完成查询操作,完成可视化。
第二种是直接导入到hive中,完成查询操作后,完成可视化。
我的做法:
导入到hive中,清洗日期格式有困难,所以我先在本地mysql完成日期格式清洗,把清洗好的数据导入hive,完成统计数据操作和可视化操作。
txt文件导入mysql,这个百度一下就有了,导入成功后,进行日期格式清洗。
txt文件中的日期格式是10/Nov/2016:00:01:02 +0800 这种格式,要换成2016-11-10 00:01:03这种,我是去java程序中完成的。
代码:
public static String[][] b = new String[2000][2]; //读出正确日期格式字符串以及对应的ID存入数组中 public static void qingXi() { //建立连接 Connection connection=DBUtil.getConnection(); PreparedStatement preparedStatement = null; ResultSet rs=null; //准备查询SQL语句 String sql = "select ip,Data from b"; Date parse_date; String finalDate = ""; try { int i = 0; preparedStatement = connection.prepareStatement(sql); rs=preparedStatement.executeQuery(); SimpleDateFormat input_date = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss"); SimpleDateFormat output_date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); while (rs.next()) { String date = rs.getString("Data"); String ip = rs.getString("ip"); //将date根据“ ”分割成字符串数组 String[] a = date.split(" "); //将Nov改成11 a[0] = a[0].replaceAll("Nov", "11"); try { //将ID和清理好的数据格式存入二维数组中 parse_date = input_date.parse(a[0].trim()); finalDate = output_date.format(parse_date); b[i][0] = finalDate; b[i][1] = ip; i++; } catch (ParseException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }catch(SQLException e) { e.printStackTrace(); }finally { DBUtil.close(rs, preparedStatement, connection); } } //根据ID修改数据库中字符串 public static void run() { Connection connection=DBUtil.getConnection(); PreparedStatement preparedStatement = null; //准备修改SQL语句 String sql="update b set Data=? where ip = ?"; int i = 0; try { while(true) { //修改数据库中的SQL preparedStatement = connection.prepareStatement(sql); preparedStatement.setString(1, b[i][0]); preparedStatement.setString(2, b[i][1]); preparedStatement.executeUpdate(); i++; if(b[i][0] == null) { break; } } }catch(SQLException e) { e.printStackTrace(); }finally { //关闭资源 DBUtil.close(preparedStatement,connection); } } //主函数 public static void main(String[] args) { qingXi(); run(); }
在数据库中把清洗好的日期格式数据导出为csv文件,把csv放入虚拟机中。
用 <hive load data local inpath '路径' into table 表名; 导入到创建好的表中。
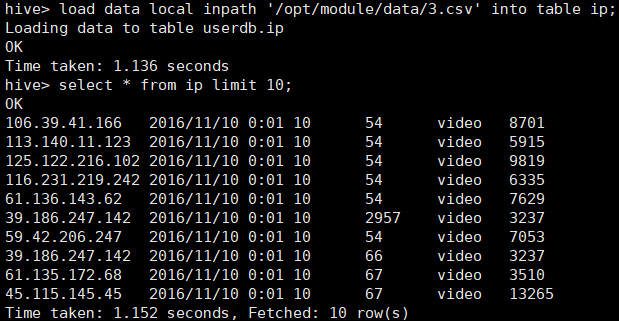
在数据表中进行数据统计,本质就是SQL语句,完成各个题目的数据统计。
用FineBI连接hive,完成可视化操作。(FineBI使用在黑马的hadoop教程最后,具体的看FineBI文档,可以完成数据下钻和联动)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号