
Python刷题-4
Python刷题-4
1、Python不支持的数据类型有( A )
A、char
B、int
C、float
D、list
注意:
string 不是 char!!!!
可变数据类型:列表list[ ]、字典dict{ }
不可变数据类型:整型int、字符串str' '、元组tuple()
2、下列程序打印结果为: [1, 2, 3, 4, 5, 5, 7]
nl = [1,2,5,3,5]
nl.append(4) #在列表的末尾插入4,[1,2,5,3,5,4]
nl.insert(0,7) #在列表0索引处插入7,[7,1,2,5,3,5,4]
nl.sort() #对列表升序排列,[1,2,3,4,5,5,7]
print nl
append()方法是指在列表末尾增加一个数据项。
extend()方法是指在列表末尾增加一个数据集合。
insert()方法是指在某个特定位置前面增加一个数据项。
nl=[1,2,5,3,5];
nl.append(4)得nl=[1,2,5,3,5,4];
nl.insert(0,7)得nl=[7,1,2,5,3,5,4];
nl.sort()输出[1,2,3,4,5,5,7]
3、以下代码输出为: 10
list1 = {'1':1,'2':2}
list2 = list1
list1['1'] = 5
sum = list1['1'] + list2['1']
print(sum)
b = a: 赋值引用,a 和 b 都指向同一个对象。
list1 和 list2 指向的是同一块内存空间
list1['1']=5 ------> 改变了这一块内存空间中'1'的value值
执行这一步后内存空间存储的数据变为:{'1': 5, '2': 2}
因此 sum = list1['1']+list2['1']=5+5=10
4、Python调用read()函数可实现对文件内容的读取
read()读整个文件;readline()读一行;readlines()读所有行到list
1.read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它范围为字符串对象。 2.readline()方法每次读出一行内容,所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
3.readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存。
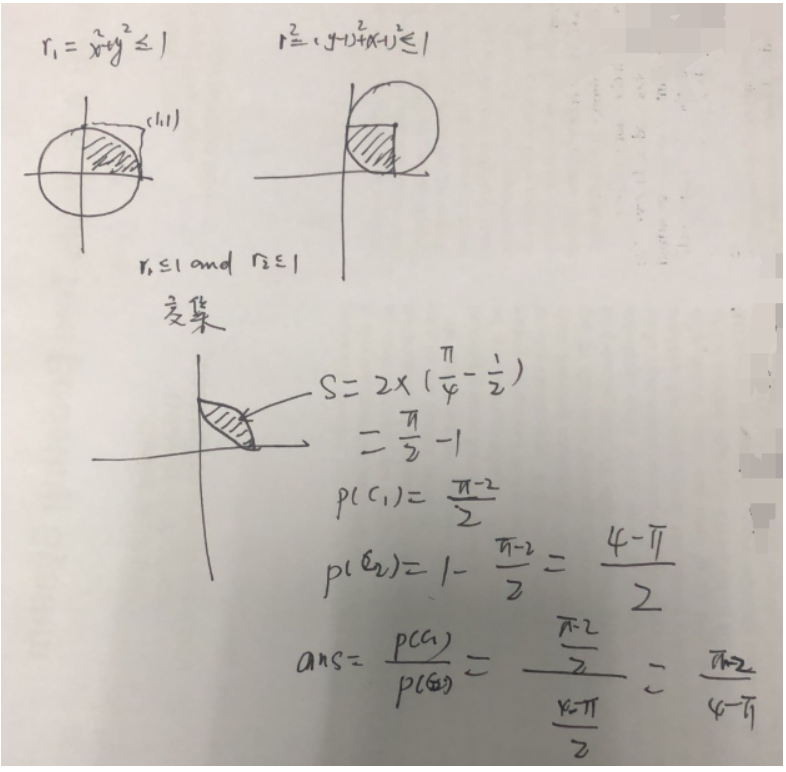
5、下面的python3函数,如果输入的参数n非常大,函数的返回值会趋近于以下哪一个值(选项中的值用Python表达式来表示)()
import random
def foo(n):
random.seed()
c1 = 0
c2 = 0
for i in range(n):
x = random.random()
y = random.random()
r1 = x * x + y * y
r2 = (1 - x) * (1 - x) + (1 - y) * (1 - y)
if r1 <= 1 and r2 <= 1:
c1 += 1
else:
c2 += 1
return c1 / c2
A、 4 / 3
B、 (math.pi - 2) / (4 - math.pi)
C、math.e ** (6 / 21)
D、math.tan(53 / 180 * math.pi)
7、下列代码运行结果是?( C )
a = 'a'
print a > 'b' or 'c'
A、a
B、b
C、c
D、True
E、False
由于比较运算符优先级大于逻辑运算符,根据上表,当 a > 'b',即 'a' > 'b' 为 Fasle 时('a' 的 ASCII 码比 ‘b’ 小),返回值为 'c',故答案选C。

9、下列程序打印结果为( B )
import re
str1 = "Python's features"
str2 = re.match( r'(.*)on(.*?) .*', str1, re.M|re.I)
print str2.group(1)
A、Python
B、Pyth
C、thon’s
D、Python‘s features
多个标志可以通过按位 OR(|) 来指定
re.M:多行匹配,影响 ^ 和 $
re.I:使匹配对大小写不敏感
分组:即用圆括号将要提取的数据包住,通过 .group()获取,一般和“|”结合使用
re.match( r'(.*)on(.*?) .*', str1, re.M|re.I),将on左边和右边分组
>>print(str2.group(0))
Python's features
>>print(str2.group(1))
Pyth
>>print(str2.group(2))
's
str1 = "Python's features"
r'(.*)on(.*?) .*'
有几个()就有几个group
group(0) = group() = Python's features
第一个()=group(1)
第二个()=group(2)
.*适配所有
?到后面的空格为止
.匹配单个任意字符
*匹配前一个字符出现0次或无限次
?匹配前一个字符出现0次或1次
(.*)提取的数据为str1字符串中on左边的所有字符,即Pyth
(.*?)提取的数据为str1中on右边,空格前面,即's

