
HDFS
简述
HDFS(Hadoop Distributed File System),作为Google File System(GFS)的实现,是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
适用、不适用的场景
HDFS特点:
- 高容错性、可构建在廉价机器上
- 适合批处理
- 适合大数据处理
- 流式文件访问
HDFS局限:
- 不支持低延迟访问
- 不适合小文件存储
- 不支持并发写入
- 不支持修改
HDFS架构
看两张HDFS的架构图。
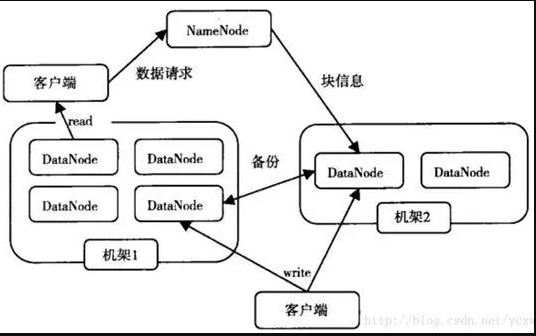
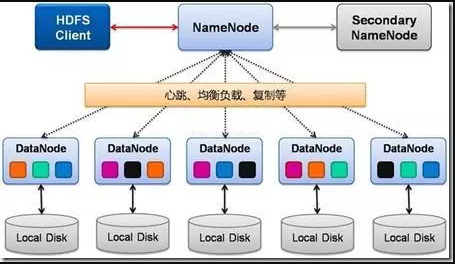
HDFS由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。
HDFS是一个主/从(Mater/Slave)体系结构,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。
HDFS客户端:就是客户端。
1、提供一些命令来管理、访问 HDFS,比如启动或者关闭HDFS。
2、与 DataNode 交互,读取或者写入数据;读取时,要与 NameNode 交互,获取文件的位置信息;写入 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
NameNode:即Master,
1、管理 HDFS 的名称空间。
2、管理数据块(Block)映射信息
3、配置副本策略
4、处理客户端读写请求。
DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
1、存储实际的数据块。
2、执行数据块的读/写操作。
Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
1、辅助 NameNode,分担其工作量。
2、定期合并 fsimage和fsedits,并推送给NameNode。
3、在紧急情况下,可辅助恢复 NameNode。
读、写文件过程
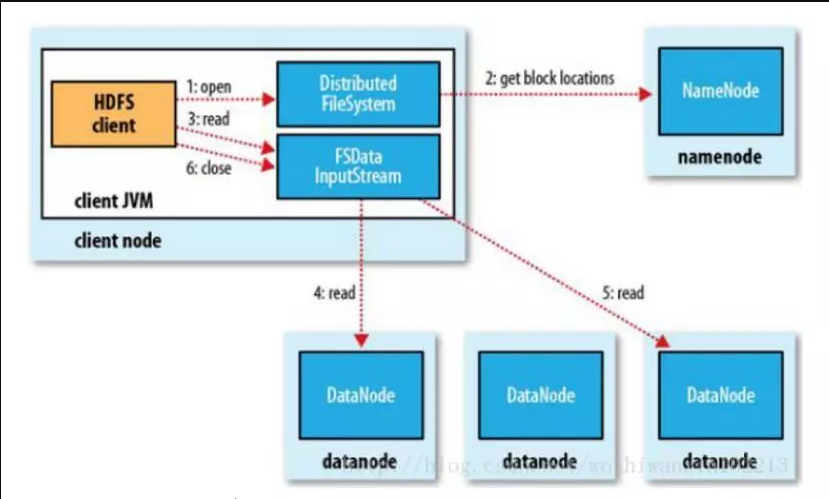
从HDFS读取内容
1、首先调用DistributedFileSystem对象的open方法,其实获取的是一个DistributedFileSystem的实例。
2、DistributedFileSystem通过RPC(远程过程调用)获得文件的第一批block的locations,同一block按照重复数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面。
3、前两步会返回一个FSDataInputStream对象,该对象会被封装成 DFSInputStream 对象,DFSInputStream可以方便的管理DataNode和NameNode数据流。客户端调用read方法,DFSInputStream就会找出离客户端最近的DataNode并连接DataNode。
4、数据从DataNode源源不断的流向客户端。
5、如果第一个block块的数据读完了,就会关闭指向第一个block块的DataNode连接,接着读取下一个block块。这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流。
6、如果第一批block都读完了,DFSInputStream就会去NameNode拿下一批blocks的location,然后继续读,如果所有的block块都读完,这时就会关闭掉所有的流。
向HDFS写入内容
1.客户端通过调用DistributedFileSystem的create方法,创建一个新的文件。
2.DistributedFileSystem通过RPC(远程过程调用)调用NameNode,去创建一个没有blocks关联的新文件。创建前,NameNode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,NameNode 就会记录下新文件,否则就会抛出IO异常。
3.前两步结束后会返回 FSDataOutputStream 的对象,和读文件的时候相似,FSDataOutputStream 被封装成 DFSOutputStream,DFSOutputStream 可以协调NameNode和 DataNode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data queue。
4.DataStreamer 会去处理接受 data queue,它先问询 NameNode 这个新的 block 最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的DataNode,把它们排成一个 pipeline。DataStreamer 把 packet 按队列输出到管道的第一个 DataNode 中,第一个 DataNode又把 packet 输出到第二个 DataNode 中,以此类推。
5.DFSOutputStream 还有一个队列叫 ack queue,也是由 packet 组成,等待DataNode的收到响应,当pipeline中的所有DataNode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
6.客户端完成写数据后,调用close方法关闭写入流。
7.DataStreamer 把剩余的包都刷到 pipeline 里,然后等待 ack 信息,收到最后一个ack 后,通知 DataNode 把文件标示为已完成。

副本存放策略
一般情况下副本系数为3,HDFS的副本放置策略是:将第一个副本放在本地节点,将第二个副本放在本地机架上的另一个节点,而第三个副本放到不同机架上的节点。
这种方式减少了机架间的写流量,从而提高了写的性能。机架故障的机率远小于节点故障。这种方式并不影响数据可靠性和可用性的限制,并且它确实减少了读操作的网络聚合带宽,因为文件块仅存在两个不同的机架,而不是三个。
文件的副本不是均匀的分布在机架当中,1/3的副本在同一个节点上,1/3副本在同一个机架上,另外1/3个副本均匀地分布在其他机架上。
流水线复制
假设HDFS副本系数为3,当本地暂时文件积累到一个数据块大小时,client会从NameNode获取一个列表用于存放副本。然后client开始向第一个DataNode数据传输,第一个DataNode一小部分一小部分地接收数据,将每一部分写入本地仓库,并同一时间传输该部分到列表中的第二个DataNode节点。第二个DataNode也是这样,一小部分一小部分地接收数据,写入本地仓库,并同一时候转发给下一个节点,数据以流水线的方式从前一个DataNode拷贝到下一个DataNode。最后,第三个DataNode接收数据并存储到本地。因此,DataNode能流水线地从前一个节点接收数据,并同一时间转发给下一个节点,数据以流水线的方式从前一个DataNode拷贝到下一个DataNode,并以相反的方向Ack前一个Node。
扩展:大数据存储生态圈简介
Hive与Hbase的数据一般都存储在HDFS上。HDFS为他们提供了高可靠性的底层存储支持。
Hive
Hive不支持更改数据的操作,Hive基于数据仓库,提供静态数据的动态查询。其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。
HBase
Hbase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
扩展:GFS简介(Google File System)
GFS、MapReduce、BigTable是Google大数据的三大理论。我们简单描述下GFS:
- 文件被分为许多固定大小的chunk,并分配一个全局唯一的64位Chunk标志;
- Master-Slave结构,Master节点记录节点及Chunk元信息;
- 为了保证可靠性,每个Chunk会被复制到多个Slave节点上;
- HDFS保证了CAP的CP,它的一致性如何实现的可以参考文末的引用文献。
参考文章:
https://blog.csdn.net/luoyhang003/article/details/72229121(GFS介绍)
https://blog.csdn.net/qiaojialin/article/details/71574203(GFS一致性总结)
https://blog.csdn.net/wypersist/article/details/79757242(HDFS核心技术详解)
https://blog.csdn.net/w1573007/article/details/52966742(Google三大理论)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号