


揭秘支付对账:确保每一分钱的安全之旅
-
1 背景介绍
-
1.1 对账定义
-
2 总览
-
2.1 业务现状
-
2.2 整体架构
-
3 设计思路
-
4 数据准备
-
4.1 内部数据
-
4.2 外部数据
-
4.3 海量数据的解决方案
-
5 数据核对
-
5.1 对账时机
-
5.2 对账粒度
-
5.3 对账方式
-
6 差错处理
-
7 小结与展望
1 背景介绍
随着转转业务的迅速发展,业务场景日益复杂,单量与日俱增,支付部门每天与外部渠道的交易额也呈现水涨船高的趋势。迭代速度加快,故障概率也增大,这增加了资金安全的风险,对转转、用户包括商家都是不容忽视的挑战。系统化保障资金安全成为至关重要的任务,其中“对账”显得尤为核心。本文将深入探讨转转支付在“对账”这一领域的实践和解决方案,以更全面地阐述这一关键问题。
对账在财务范畴,这是一个必要做的工作。从业务视角看,如今的交易链条越来越长,数据在众多系统之间难免会出现丢失或者差错的情况,所以为了业务的正常运转并及时发现问题,需要确保系统间数据的一致性。从公司的角度看,需要确保“不少收一分钱,不多付一分钱”。
1.1 对账定义
对账就是“账证实”的核对,“账”是账目,“证”是凭证,“实”是实际资金或者商品。常见的核对模式有三种:账证核对、账账核对、账实核对,确保账证实两两的一致性。
- 在本文中,对账是指在固定周期内,支付使用方(转转)和支付提供方(第三方支付)相互确认交易、资金的正确性,保证双方的交易、资金一致正确。
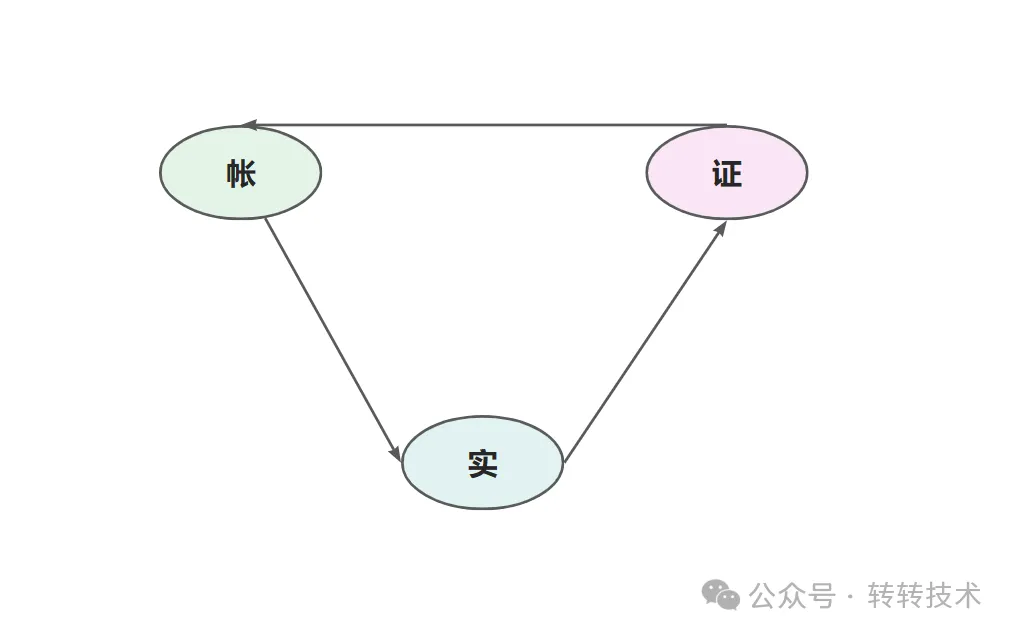
对账定义
2 总览
2.1 业务现状
为了确保数据的一致性,我们需要进行对账。这包括比对转转自家的交易数据与三方支付公司提供的数据,以确保交易的准确性和完整性。
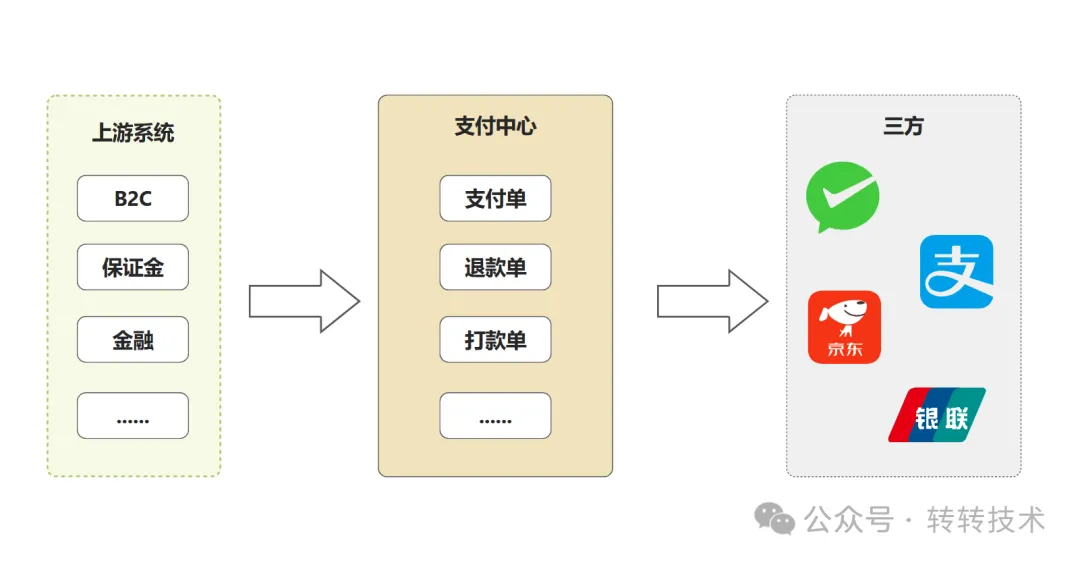
2.2 整体架构
转转的对账体系根据对账时机可分为在线对账与离线对账。在线对账领域,根据实时性可进一步细分为实时对账与准实时对账。此外,根据数据来源的不同,对账可以划分为业务对账与渠道对账。渠道对账在实现方式上属于离线对账,本文将专注于探讨转转在渠道对账方面的系统设计与实现。
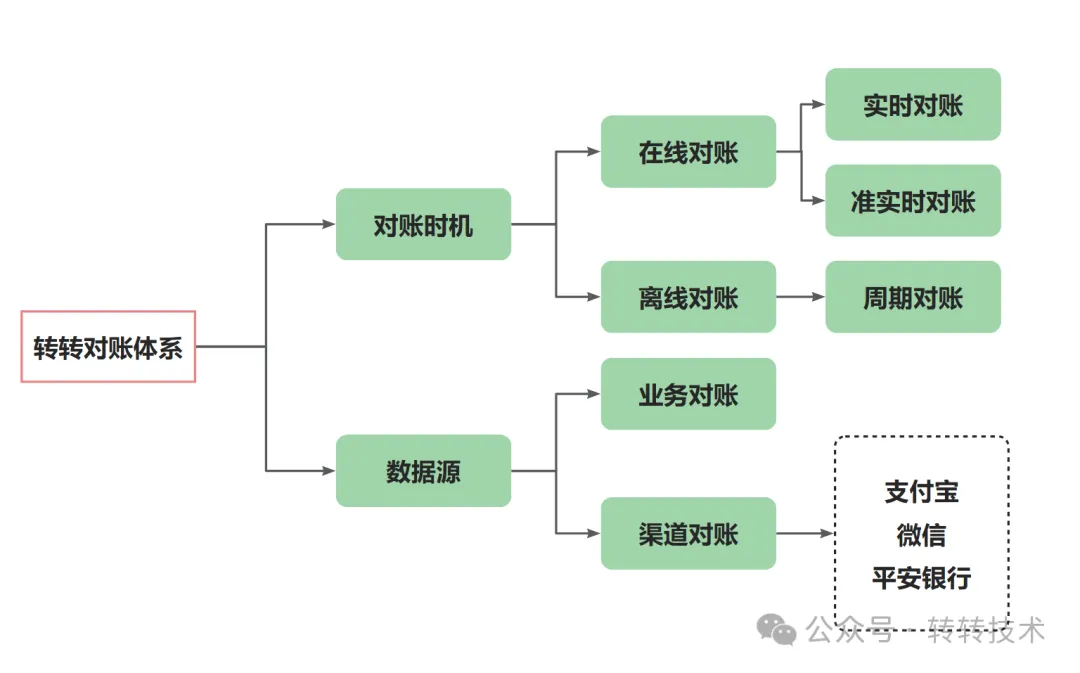
转转对账体系
渠道对账主要包括两个模块,即离线对账平台和平账中心。其中,离线对账平台又分为数据接入层和数据核对层。
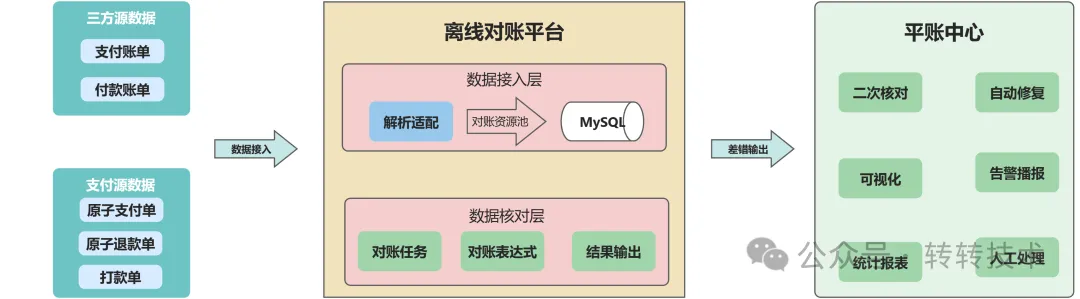
整体架构
3 设计思路
从整体来看,按照时序维度的先后,系统对账主要分为三阶段的工作。分别是数据准备、数据核对和差错处理。在对账专业概念中,数据核对和差错处理又叫轧账和平账。三个环节紧密相连,从前期准备、问题发现、问题处理三个角度展开对账工作。
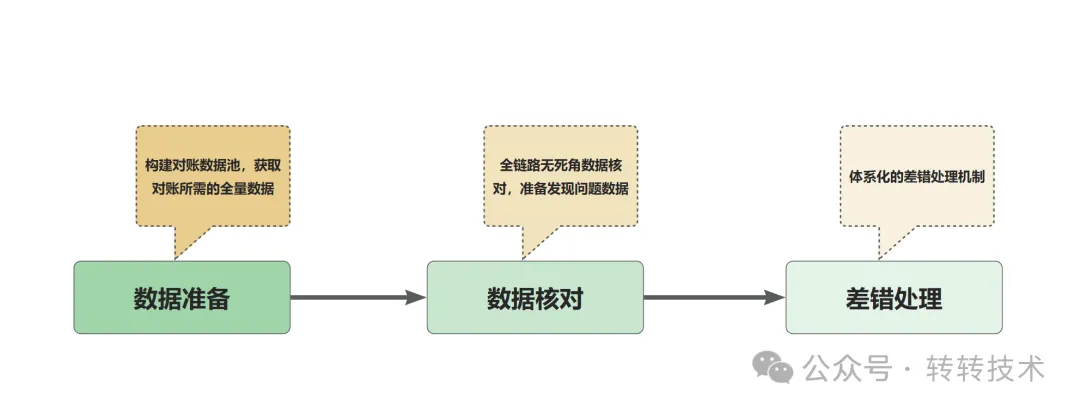
设计思路
4 数据准备
数据准备,顾名思义,我们需要把对账所需的全部数据,接入到我们的对账系统。该模块主要针对两个方向:
- 转转内部数据。
- 外部渠道账单。
4.1 内部数据
在数据准备阶段针对内部数据我们有以下几种不同的数据接入模式:
- 数据拉取:对账系统主动拉取数据,经过数据加工,将数据存储到对账数据池。此种方式对上游侵入性较高,同时也需要考虑拉取频率等服务间调用的性能问题。
- 文件推送:上游系统定期(如每日凌晨2:00)生成文件,按照约定规范进行命名,将文件推送至对账系统指定服务器(FTP)。这种方式需要业务系统一定的开发量,出现差错时纠正效率慢,业务调整时也需要调整文件的生成策略,维护成本略高。
- MQ推送:业务方按照要求在指定时机发送约定格式的MQ消息,对账系统订阅MQ。
- binlog:对账系统监听业务库表的binlog收集数据源。此种方式对比上游系统手动发MQ,实现了对上游系统的0侵入性。
监听binlog这种方式是我们的最优选择,同时我们也支持文件推送作为补偿手段,用于处理历史数据的对账。binlog方式对于上游系统来讲无感知,但是对账系统需要做好数据过滤、数据幂等、数据更新等方面的处理。
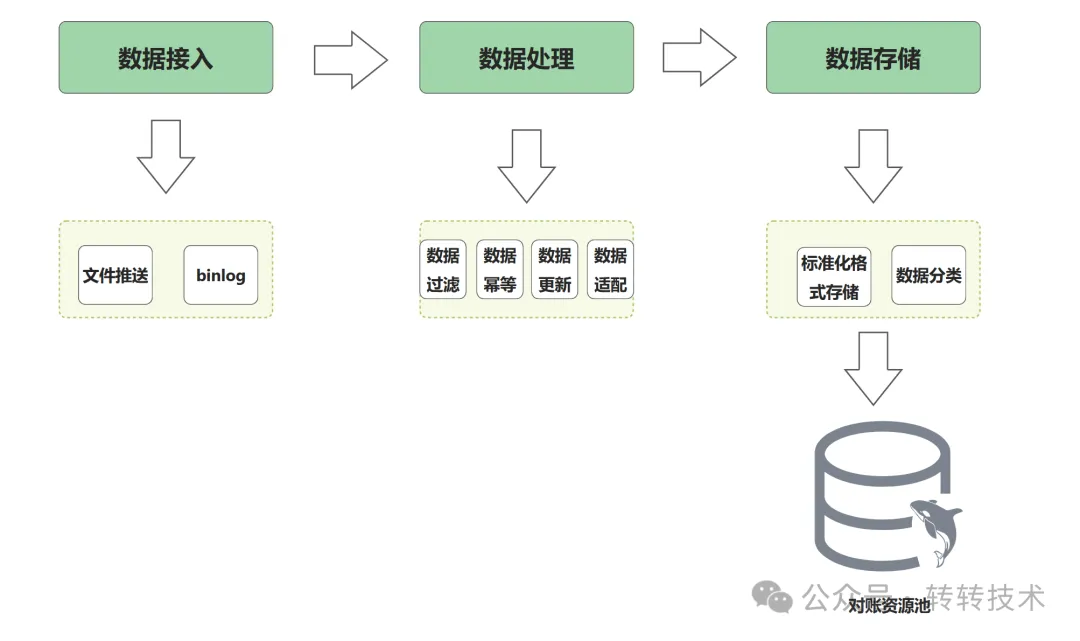
本地数据源
4.2 外部数据
外部数据特指通道方的账单,可以通过通道方的专属接口下载对账文件。这里着重解决以下几个问题:
- 三方账单就绪时间不一。例如:微信早上10点可下载对账文件,微企付11点才能下载。
- 三方账单文件后缀不一(txt、xlsx)。
- 重复对账需要重复下载三方账单。
- 三方文件的下载功能。
方案:通过任务驱动账单的下载,并下载至本地服务器。
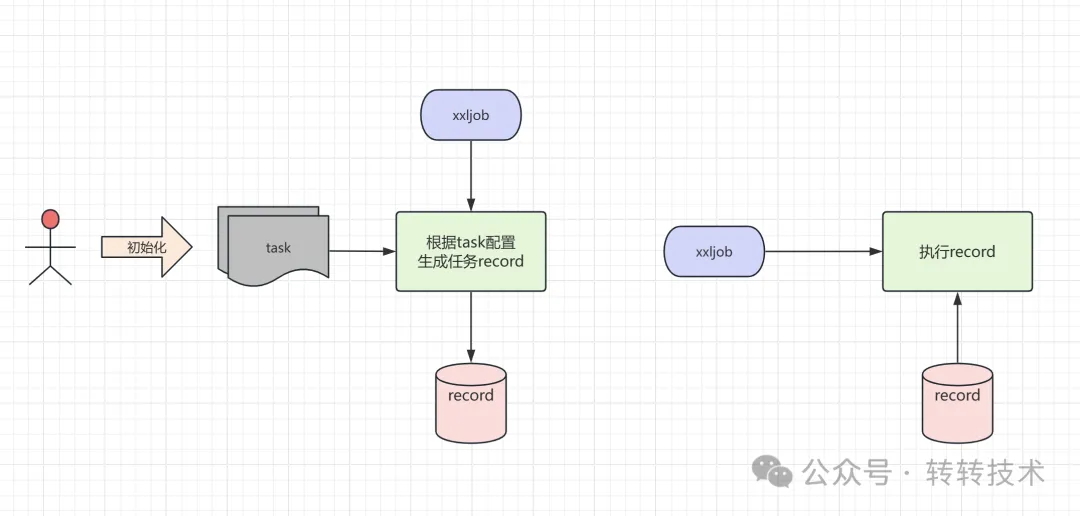
任务驱动下载
- 通过在不同渠道对应的task上配置不同的预期下载时间,进而通过定时任务调度实现错峰分散下载。出现异常时适时延后任务调度便于重试。
- 将三方文件统一转为.csv后缀文件并保存至本地,避免重复下载,实现文件的读统一。
4.3 海量数据的解决方案
随着数据规模的增长,未来对账系统肯定也会遇到很多来自海量数据的问题,目前在转转接入的有限对账场景下就已达到100w/天的数据量,单表存储几乎是不可能的。目前比较通用的解决办法有分库分表或冷热库。其中分库分表又分为水平分和垂直分等等。在此我们简单对比一下几种方式的优缺点和适应的场景。
| 优点 | 缺点 | |
|---|---|---|
| 分库分表 | 整体的最大连接数增加,数据分散至多张表,写性能与读性能均有明显提升 | 非分表键数据库查询有性能浪费,分库事务复杂 |
| 冷热库 | 热库由于量小,单表读写性能高 | 冷库数据修改需要兼容 |
| ES/Hive | 数据查询性能高 | 数据一致性略差、额外的数据抽取工作 |
针对对账数据源使用场景的特点:数据修改、查询不频繁、超过1个月的数据很少再次使用,超过1个自然年的数据几乎“永久”不再使用。我们选择的解决方式是分表+Hive数据归档的方式,其中MySQL存储的是近一个自然年的数据并按月分表,一年前的数据定期抽取至Hive归档存储。
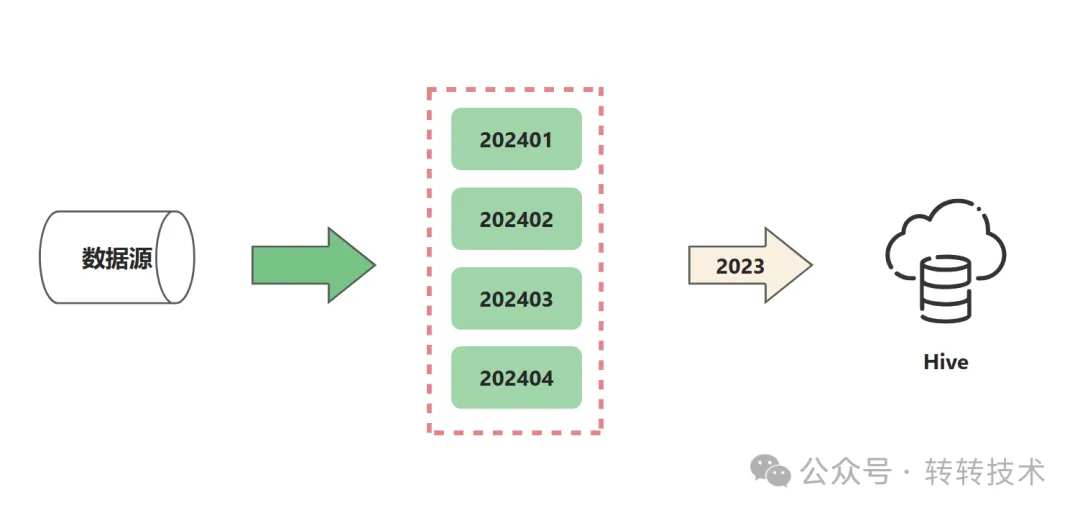
数据存储
5 数据核对
5.1 对账时机
对账时机分为离线对账和在线对账。离线对账主要是通过固定的周期进行对账。这里我们选择离线对账且周期为最短周期(T+1)。
5.2 对账粒度
对账粒度分两种:
- 明细对账。对双方的每条数据依次进行比对。可以准确定位问题数据。
- 总数对账。选择一个维度,进行总数级别的对账。总数级别的对账好处是对账口径的设计比较简单,可以快速实现,不易出错。
我们选择的是双线并行,资金汇总比对快速发现问题,逐条核对可以定位具体问题。

对账粒度
5.3 对账方式
我们考虑了两种对账方式,包括通过将内部外部两份数据源写入到Hive数据源中,通过SQL的方法逐单比对以及单独持久化三方文件内容到数据库,采用逐行读取账单逐行发送MQ,接受MQ再核对本地单据的方式。
| 方案 | 优点 | 缺点 |
|---|---|---|
| Hive SQL对账 | 不占用线上核心集群资源,SQL比对速度快 | Hive SQL编写相对复杂,对账结果难维护 |
| MQ分发对账 | 数据分散,单机压力小,逻辑清晰,对账结果易维护 | 效率相对低,需要处理MQ并发消费、消费失败等场景 |
最终从运营的便利性角度考量我们选用的是MQ的方式进行对帐。
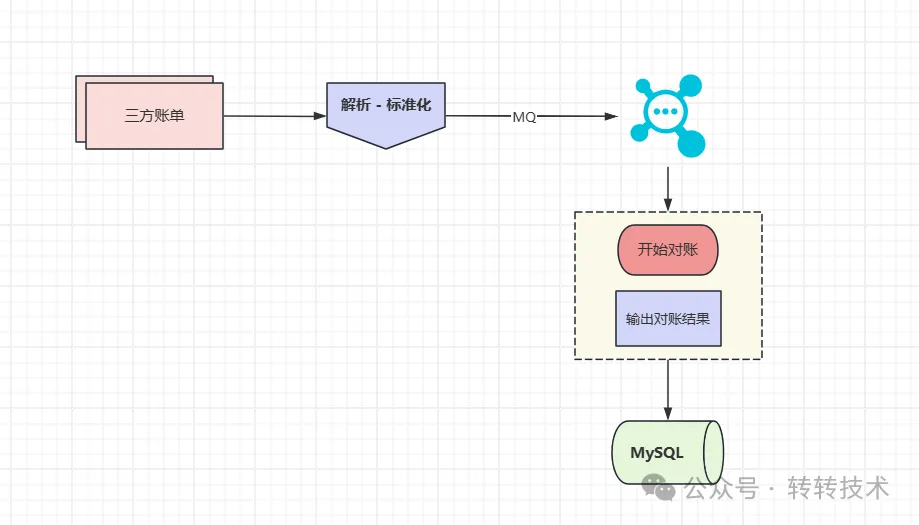
对账方式
6 差错处理
差错处理阶段,我们核心关心的是对账异常的数据。所以会对对账异常的数据进行存储,核心信息包括:对账场景、错误类型、数据处理节点状态等,这个阶段会建立一个统一的差错处理驱动模型。可以通过定时任务定期轮询差错记录的方式发起差错处理流程,也可以在对账的过程中自动识别异常单据进行补偿。
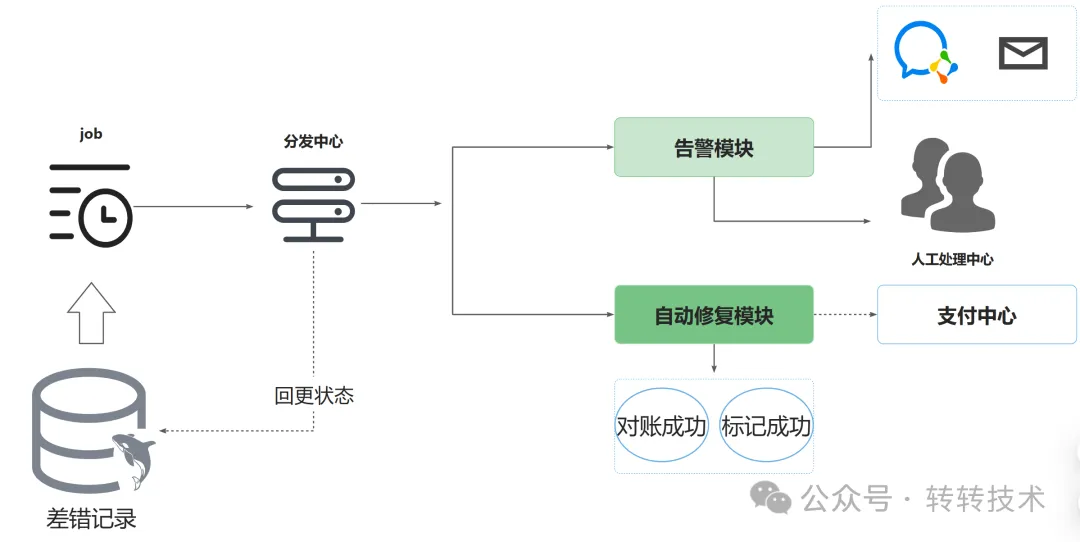
差错处理
7 小结与展望
基于上述对账思路,我们设计了一个涵盖三个模块并紧密协作的一体化对账系统。这个系统能够高效地完成渠道对账工作,及时发现并修复数据不一致的问题,确保每一分钱的安全流转。通过这套对账系统,我们不仅减少了客户投诉,还提高了资金流向的透明度,为转转业务的健康发展保驾护航。
另外,目前转转支付对账体系涉及的场景还不够全面,缺乏清结算系统内部、清结算与上游、保证金等等业务模块之间的对账,未来的目标聚焦于站在更高的视角接入更多的业务场景实现全链路无死角核对,同时也要考虑业务接入的成本问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号