Lab4 记录
Part A:无快照的KVServers
KVServer整体结构如下
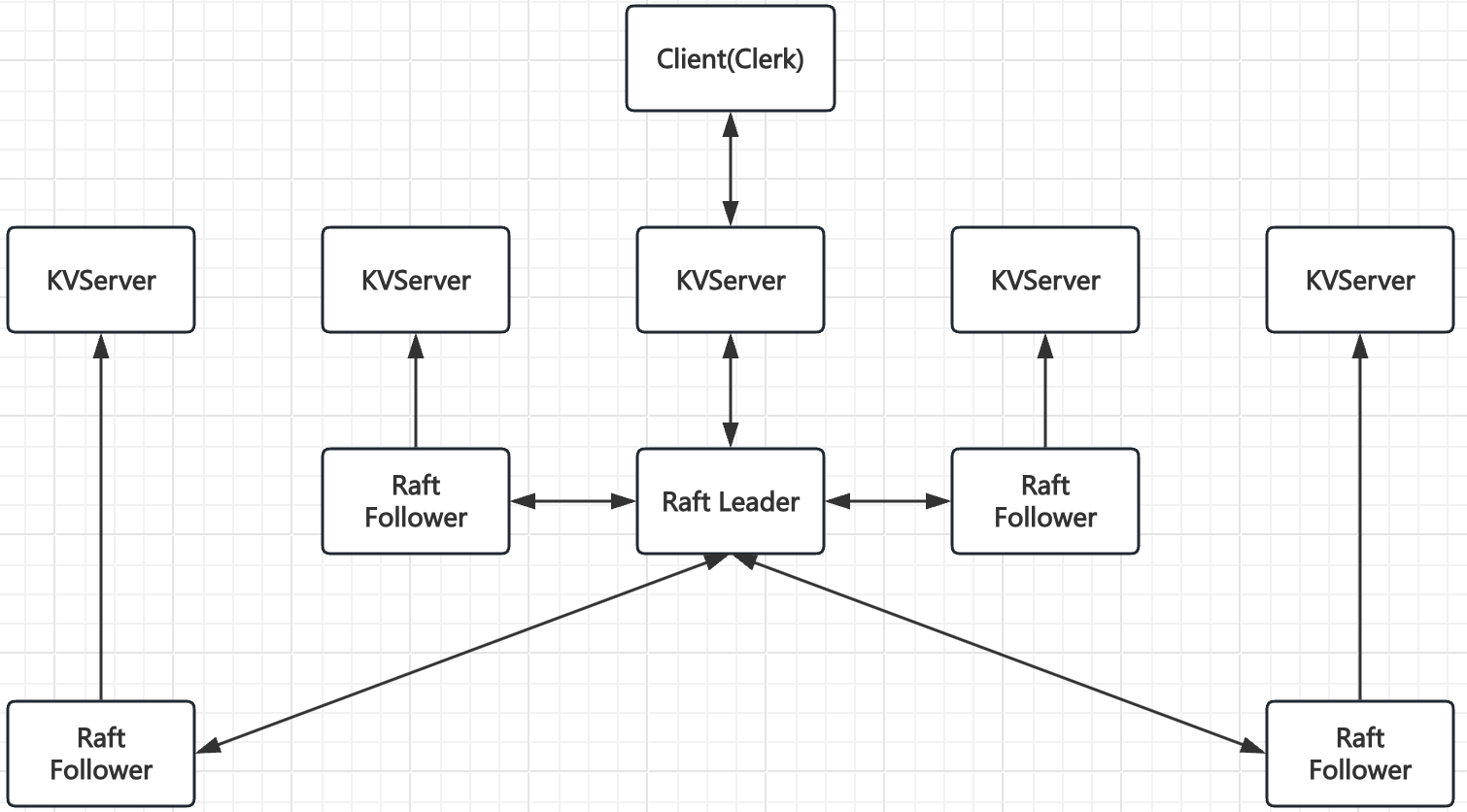
每个KvServer对应一个Raft Server,该Raft Server可能是Leader或Follower
- Client向KVServer发送请求,如果该KVServer对应的Raft Server不是Leader,直接返回Error,Clerk向其他KVServer发起请求
- KVServer将命令提交到Raft Leader,如果执行完成,Raft Server会通过applyChan将命令发送回KVServer
- KVServer将接收到的命令执行到本地状态机
- 返回结果到Clerk
第一步
Task
第一个任务是实现一个没有消息丢失和服务器失败情况下的解决方案。
可以将Lab 2中的客户端代码(kvsrv/client.go)复制到kvraft/client.go 中。你需要添加逻辑,以决定每个请求应该发送到哪个kvserver。记住,Append()不再返回值。
继续在server.go中实现Put()、Append()和Get()的处理函数。这些处理函数应该使用Start()将一个操作(Op)加入Raft日志中;你需要在server.go中填充 Op结构体的定义,使其能够描述Put/Append/Get操作。每个Server应在Raft 提交操作时(即操作出现在applyCh上时)执行Op命令。RPC处理函数应该注意到 Raft何时提交了它的Op,然后回复该RPC请求。
当你通过第一个测试 “One client” 时,任务就完成了。
KvRaft中,Client通过Clerk提交Command,
每个KvServer对应一个Raft Server
Clerk将命令提交给KvServer
-
如果这个KvServer对应的Raft Server不是Leader
返回false,并返回LeaderID
Client根据LeaderID重新发起
-
KvServer提交Command到Raft Leader
-
一旦命令执行完成,Raft会通过ApplyChan将commit的命令发送过来
KvServer根据发过来的命令判断哪个指令执行完成,向对应的调用返回结果
第二步
Task
添加代码以处理故障和重复的Clerk请求,包括这样的场景:Clerk在某个任期内向kvserver的Leader发送请求,因等待回复超时,在新任期内又将请求发送给了新的Leader。这个请求只能被执行一次。这里的说明文档提供了有关重复检测的指导。你的代码需要通过
go test -run 4A测试。
提示:
- 你需要处理这样的情况:一个Leader调用了Start()处理Clerk的RPC请求,但在该请求提交到日志之前失去了领导权。这种情况下,你应该让Clerk重新发送请求到其他服务器,直到找到新的Leader。可以通过以下方式实现:kvserver检测Leader是否失去领导权,比如发现Raft的任期发生了变化,或者在Start()返回的索引处出现了不同的请求。如果原来的Leader被网络分区隔离,它可能不知道新的Leader出现了;但同样处于该分区内的客户端也无法联系到新Leader,因此在这种情况下,允许服务器和客户端无限期等待,直到分区恢复。
- 你可能需要修改Clerk以记录上一次RPC请求中找到的Leader,并在下一次RPC 时首先将请求发送给该服务器。避免浪费时间去寻找Leader,从而更快地通过某些测试。
- 你应该使用类似于Lab 2的重复请求检测机制。该机制能够快速释放服务器内存,例如通过每个新的RPC可以默认表示客户端已经接收了上一次RPC的回复。你可以假设每个客户端一次只会向Clerk发起一个调用。你可能需要根据实际情况,修改 Lab 2中重复检测表里存储的信息。
-
Leader失效处理
所有命令,一旦调用了Client,Client必须不断重试直到执行成功,不能执行失败
Client
- 发送Log到KvServer
- 如果超时没有回复,则可能是Server失效,切换Server重试
KvServer
- 接收Client的Request
- 提交Log到Raft,保存返回的Index,Term,以及Log到Slice中
- Leader失效:
- 通过rf.getState()获取Raft状态,如果Term发生改变,或者已经不是Leader,就返回ErrWrongLeader
- 如果返回的CommitLog Msg对应的Index和本地存储的Log不同,同样返回ErrWrongLeader,让Client重试
- 收到Raft发回的CommitLog Msg,把对应的Log从Slice中去除
-
重复请求处理
和Lab2一样的处理思路
-
处理分区partition
如果KvServer提交了命令到Raft,而且该Raft是Leader,如果一直不返回,那就持续等待
坑点
-
这一节有些问题是因为Raft的问题导致的,最好能通过Raft测试100遍,差不多就没有大问题了。
-
同一Index位出现了不同的Log,以及Term发生改变,上述两种情况发生时都需要重新提交Log
-
但对于Term改变,重新提交Log可能会出现重复日志的情况,
比如分区的情况,一共五个Raft Server,其中0,1,2一组,3,4一组
0是Leader,日志来临时,0将日志复制给了2
之后3回到集群,2被断开,因为3,4一直在进行选举但又不可能选举成功(Server数小于一半),因此必然Term很大,0给3发送心跳消息,就会发现Term大于自身,因为0转换Follower,准备重新选举,这是我们的KvServer也发现Term发生了变化,于是重新提交Log
之后3又被断开,2回来并赢得选举,这时新Log提交给了2,2成功将新的日志项与前一个日志项复制到所有Server,于是就发生了重复日志
重复日志的处理方法
- 记住Client一次只会发送一个Request到KvServer,一个Request没有成功以前,不会发送新的Request
- 因为网络延迟导致的重复请求,只会发送给同一个Server
- 当Client收到结果后,不会再出现重复请求
结果
代码地址:https://github.com/INnoVationv2/6.5840/tree/Lab4/PartA

Part B: 使用快照的KV service
目前的KVServer不会调用Raft的Snapshot(),因此重新启动的服务器必须重播完整的Raft日志才能恢复其状态。现在,使用Lab 3D中的Raft的Snapshot()方法,修改kvserver与Raft配合使用,以节省日志空间并减少重新启动时间。
Tester将maxraftstate传递给StartKVServer()。maxraftstate表示持久 Raft状态的最大允许大小(单位为字节,包括日志,但不包括快照)。你应该将 maxraftstate与persister.RaftStateSize()进行比较。每当你的KVServer检测到Raft状态大小接近此阈值时,应通过调用Raft的Snapshot来保存快照。如果maxraftstate为-1,则不必快照。maxraftstate适用于你的Raft作为persister.Save()的第一个参数传递的GOB编码字节。
修改你的kvserver,使其能够检测持久化的Raft状态是否过大,并将快照交给Raft。当kvserver重新启动时,它应该从persister读取快照,并从快照中恢复其状态。
提示
- 思考一下kvserver何时应该对其状态进行快照,以及快照中应包含哪些内容。Raft使用
Save()将每个快照以及相应的Raft状态存储在persister中。你可以使用ReadSnapshot()读取最新存储的快照。 - kvserver必须能够在跨越检查点时检测到日志中的重复操作,因此用于检测这些操作的任何状态都必须包含在快照中。
- 将快照中存储的结构的所有字段必须以大写字母开头
- 您的Raft库中可能存在本实验中暴露的错误。如果您对 Raft 实现进行了更改,请确保它继续通过所有实验 3 测试。
- Lab 4 测试的合理时间是400秒实际时间和700秒CPU时间。此外,
go test -run TestSnapshotSize应花费少于20秒的实际时间。
思路
-
Raft中保存的什么?
是所有日志序列
Raft Server重启后,重播所有Log到KvServer,KVServer接收到日志后,一个一个将日志应用到本地db,这样状态就恢复如初了
-
快照保存的什么?
快照保存的是,某个Commit Index之前所有日志的最终结果,即KVServer中的KV状态
-
如何进行快照?
- 每次接收到Raft Server发来的log时,将
persister.RaftStateSize()和maxraftstate进行比较,当大小接近时,调用Snapshot - 将KVServer的当前状态通过Snapshot发送给Raft Server
- 每次接收到Raft Server发来的log时,将
-
传给Snapshot()的KVServer当前状态需要哪些字段?
- 当前的KV状态
- LastLogIndex
- 防止重复请求的相关字段
- prevCmd
- submitCmd
- history
- matchIndex
坑
Leader:0
其他4个Follower:1,2,3,4
- 来了一个新日志
- Leader发送给了1 2 3,发送完成后达成共识,回复Client已经执行完成
- Client收到后,应用日志到自身状态机,并发现状态大小已达到MaxRaftState
- 调用Leader生成了snapshot
- Leader接下来发送日志给4,因为已经生成snapshot,于是发送snapshot给0
- 此时4刚好收到Raft发来的前一个日志,并且Raft Server4同样到达MaxRaftState,于是生成snapshot
- 4收到Leader发来的snapshot,保存下来,并尝试发送给KVServer
- 但此时,KVServer卡在生成snapshot的lock之前
如果前面Raft实现没有问题,PartB很简单,但是很多时候生成Snapshot,接收Snaoshot之间会死锁,可以不断打印协程数量,如果发现协程数量急剧攀升,八成就是死锁了。
这种情况Debug也比较麻烦,建议:查看Log,如果发现某个Server在某个时间点后再也没有打印任何日志,那应该就是这个Server出现了死锁,详细看看这个Server最近做了哪些操作,然后仔细分析。
结果
代码地址:https://github.com/INnoVationv2/6.5840/tree/Lab4/PartB
全部测试结果
go test -failfast
Test: one client (4A) ...
... Passed -- 15.1 5 35348 5889
Test: ops complete fast enough (4A) ...
... Passed -- 1.1 3 4015 0
Test: many clients (4A) ...
... Passed -- 15.1 5 19773 3676
Test: unreliable net, many clients (4A) ...
... Passed -- 19.2 5 4770 566
Test: concurrent append to same key, unreliable (4A) ...
... Passed -- 3.9 3 314 52
Test: progress in majority (4A) ...
... Passed -- 0.6 5 57 2
Test: no progress in minority (4A) ...
... Passed -- 1.1 5 129 3
Test: completion after heal (4A) ...
... Passed -- 1.0 5 56 3
Test: partitions, one client (4A) ...
... Passed -- 22.5 5 45475 3300
Test: partitions, many clients (4A) ...
... Passed -- 22.7 5 18715 1760
Test: restarts, one client (4A) ...
... Passed -- 18.9 5 27998 4693
Test: restarts, many clients (4A) ...
... Passed -- 19.0 5 10847 2042
Test: unreliable net, restarts, many clients (4A) ...
... Passed -- 22.7 5 4372 480
Test: restarts, partitions, many clients (4A) ...
... Passed -- 25.6 5 14712 1506
Test: unreliable net, restarts, partitions, many clients (4A) ...
... Passed -- 27.6 5 5485 326
Test: unreliable net, restarts, partitions, random keys, many clients (4A) ...
... Passed -- 32.3 7 13263 672
Test: InstallSnapshot RPC (4B) ...
... Passed -- 2.5 3 950 63
Test: snapshot size is reasonable (4B) ...
... Passed -- 0.7 3 3207 800
Test: ops complete fast enough (4B) ...
... Passed -- 0.7 3 4015 0
Test: restarts, snapshots, one client (4B) ...
... Passed -- 19.4 5 134165 23573
Test: restarts, snapshots, many clients (4B) ...
... Passed -- 19.7 5 5871 892
Test: unreliable net, snapshots, many clients (4B) ...
... Passed -- 17.4 5 3875 468
Test: unreliable net, restarts, snapshots, many clients (4B) ...
... Passed -- 22.3 5 4154 467
Test: unreliable net, restarts, partitions, snapshots, many clients (4B) ...
... Passed -- 28.8 5 4461 259
Test: unreliable net, restarts, partitions, snapshots, random keys, many clients (4B) ...
... Passed -- 35.0 7 11036 447
PASS
ok 6.5840/kvraft 395.967s

 浙公网安备 33010602011771号
浙公网安备 33010602011771号