
Lab3 记录
Part 3A: leader election
1.选举主要流程
- 新服务器加入集群
服务器在启动时状态是Follower。只要持续接收到Leader或Candidate的心跳信息,就继续保持Follower状态。
- 开始选举
每个Server都有一个随机的选举超时时间,选举超时在一个固定区间内随机选择(例如,150-300毫秒)
如果Follower在选举超时时间内未收到有效的心跳信息,就认为当前没有有效Leader,转换自己为Candidate,发起选举。
心跳消息:一般是不包含日志条目的
AppendEntries RPC
- 投票规则
服务器收到RequestVote RPC时,根据以下规则进行投票:
服务器以先到先得的方式投票,且每个任期只能投一票。
- 如果收到的RPC的任期小于服务器当前的任期,拒绝投票。
- 如果服务器已经为当前任期投过票,或收到的RPC中的日志不如自己的日志新(最后一个条目的任期较旧或者任期相同但是编号较小),拒绝投票。
- 如果以上情况都不满足,服务器会为Candidate投票,并重置自己的选举超时时间。
- 选举过程
- 若选举过程中,
Candidate收到其他Leader的心跳信息,且该Leader的任期大于等于候选人的任期,那么Candidate会承认新Leader并转回Follower状态;反之继续进行选举。
- 选举结果
- 若Candidate获得的选票超过半数(3/5),则赢得选举,成为新Leader。同时向所有Server发送心跳消息,以防止新的选举。
- 若选举超时,没有选出Leader,即没人获得多数票,一般是因为同时有多个Follower成为了Candidate。这种情况下,Candidate会等待一个随机的
选举超时时间,增加任期,重新开始新一轮选举。
2.各组件逻辑
-
各组件都要遵守的规则
任意RPC中包含的term大于自身term,则更新自己的term,并将自己转为follower状态,本节主要是心跳RPC和RequestVote RPC
-
随机超时检测
ticker()功能:检测是否需要进行选举,使用Goroutine并行运行
-
role == Leader:跳过所有检测
-
role != Leader:
若未收到心跳消息或未投票给任何人,举行选举
-
-
接收到心跳消息
-
如果心跳Term<当前Term,拒绝心跳,直接返回
心跳TermTerm==当前Term或心跳TermTerm>当前Term,则重置超时检测 -
若
role==Candidate或role==Leader&&心跳Term>当前Term-
转回Follower
-
更新当前Term为心跳Term
-
更新LeaderID为心跳发送方
-
更新VoteFor为心跳发送方
-
-
-
接收到投票请求
说明已经有人开始选举,因此重置超时检测器,推迟自身可能要开始的选举
-
如果请求投票
RPC Term<当前Term,拒绝 -
如果请求投票
RPC Term>当前Term,投票更新自身Term
如果当前Role!=Follower,转回Follower
-
如果请求投票
RPC Term==当前Term,且当前Term没有投过票,投票
-
-
接收心跳超时,开始选举
-
配置自身角色
- Role切换为Candidate
- 投票给自己
- 当前Term+1
-
向其他Server请求投票
票数过半,当选Leader
- 切换Role为Leader
- 更新LeaderID为自己
- 启动心跳发送程序
-
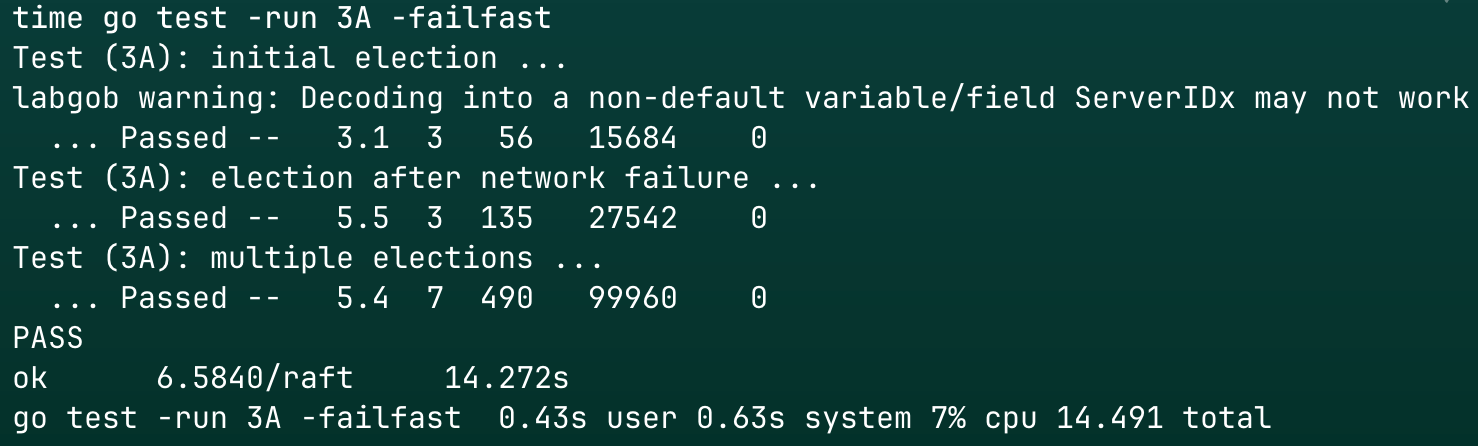
3.结果
测试6K次
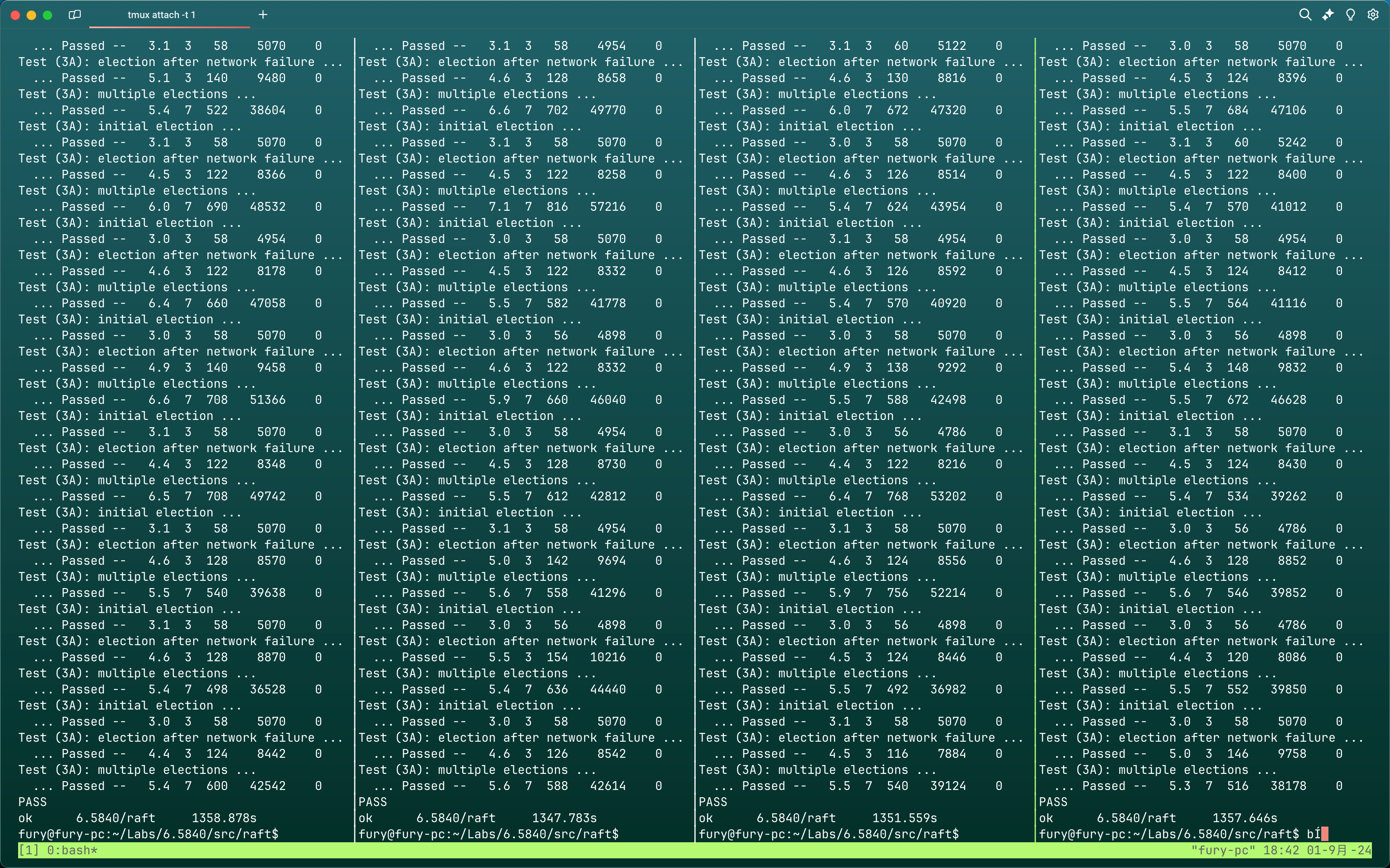
单次用时
代码地址:https://github.com/INnoVationv2/6.5840/tree/Lab-3A-Dev/src/raft
go test -run 3A -count 1000 -failfast -timeout 3000m -race
Part 3B: log
-
完善结构体,将图2中State、AppendEntries RPC、RequestVote RPC的所有参数都写进代码
-
先从5.3节开始,实现不出错情况下Raft的处理逻辑,从Leader当选后开始
当Leader收到客户端提交的命令时
- 根据客户端命令创建新的日志条目,日志条目由命令和任期编号组成。
- 向所有Follower
并行发送AppendEntries RPC,其中包含待复制的旧条目、新条目、前一个日志条目的索引和任期。 - Follower收到
AppendEntries RPC后,先检查其中的前一个日志条目的索引和任期是否与自己的日志匹配。若匹配,则添加新条目并回复成功。若不匹配,则拒绝并回复失败。 - 当Leader收到包括Leader在内超过半数Follower的确认后,日志条目就被认为是
safely replicated。 - 之后,Leader执行条目到自己的状态机,然后将已执行的最大日志目录编号Index记录下来,下次与Follower通信时,会将其附上,这样Follower就知道Index之前的条目都已执行,然后Follower就也会执行这些条目到自己状态机。
- 将日志条目执行到状态机后,返回操作结果给客户端。
-
接下来实现日志修复逻辑
Leader发生崩溃时,可能会导致日志不一致,旧Leader可能没有完全复制日志到其他服务器,Follower可能缺少leader的条目、也可能有Leader没有的条目。
在Raft中,Leader会强制Follower复制自己的日志以保持一致。Follower日志中的冲突条目会被Leader日志覆盖。
日志冲突处理步骤:
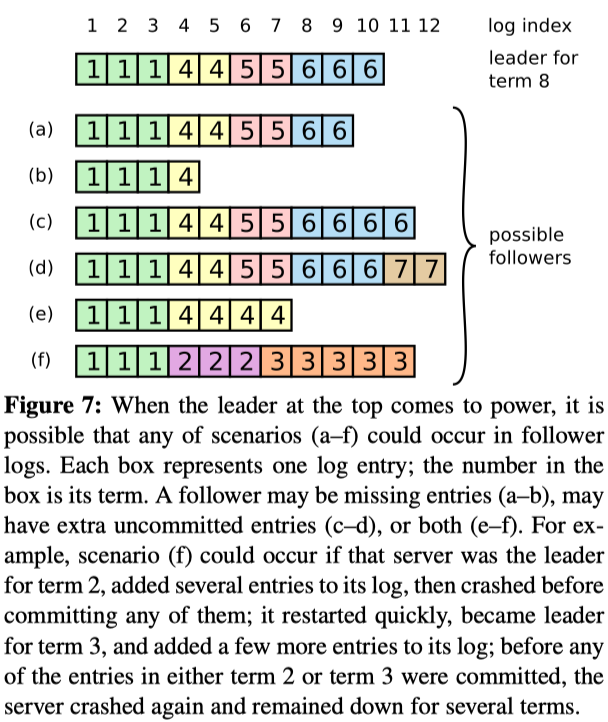
- Leader为每个Follower维护一个nextIndex,这是Leader下一次给Follower发生日志条目的起始编号
- Leader首次当选时,将所有nextIndex值初始化为日志中最后一个值之后的索引(图7中的11)。如果Follower与Leader的日志不一致,下一次AppendEntries RPC肯定会失败。失败后,Leader减少nextIndex并重试AppendEntries RPC。最终,nextIndex将达到和Follower日志匹配的点。
- 成功匹配后,AppendEntries将成功,Follower将删除日志中的所有冲突条目,并从Leader日志中追加条目。一旦AppendEntries成功,Follower与Leader的日志将一致,并且在该Term内始终保持一致。
-
继续实现论文中,为保证Raft正确性所做的一系列限制
-
选举限制
防止未包含所有已提交条目的Candidate赢得选举
收到投票请求时,投票人会将Candidate日志和自己的日志进行对比,
- 如果Candidate的日志和投票人的至少一样新,投票
- 如果投票人的日志比Candidate更新,不投票
日志
新的定义:通过比较日志中最后一个条目的Index和Term来确定。 -
前一个Term的日志项
对前一个Term的日志,不通过计算副本数规则提交,只对当前Term的日志项通过计算副本数提交,因为根据
Log Matching属性,所有之前的条目都会被间接提交。
-
注:最近进行过日志发送或正在进行日志发送的话,本轮发送心跳暂停
一些坑
-
当发送非心跳消息到Follower超时时,若还是Leader,且term未变,需要持续重试
-
Follower在接收到AppendEntries时,更新CommitIndex同样要遵循只提交当前任期日志项的原则
-
Leader发送成功,更新NextIndex和MatchIndex时,先比较大小再更新,因为发的早的消息可能回复的比发的晚的消息更早
如下两条消息
{PrevLogIndex:5 PrevLogTerm:2 LeaderCommit:5 Len:4} {PrevLogIndex:5 PrevLogTerm:2 LeaderCommit:5 Len:5}第一条回来,NextIndex应该更新为10,第二条回来,NextIndex应该更新为11
但是第二条如果回来的比第一条晚,NextIndex就会->11->10,从而出错
-
创建AppendEntries时,使用Copy,而不是切片引用,会出现DataRace
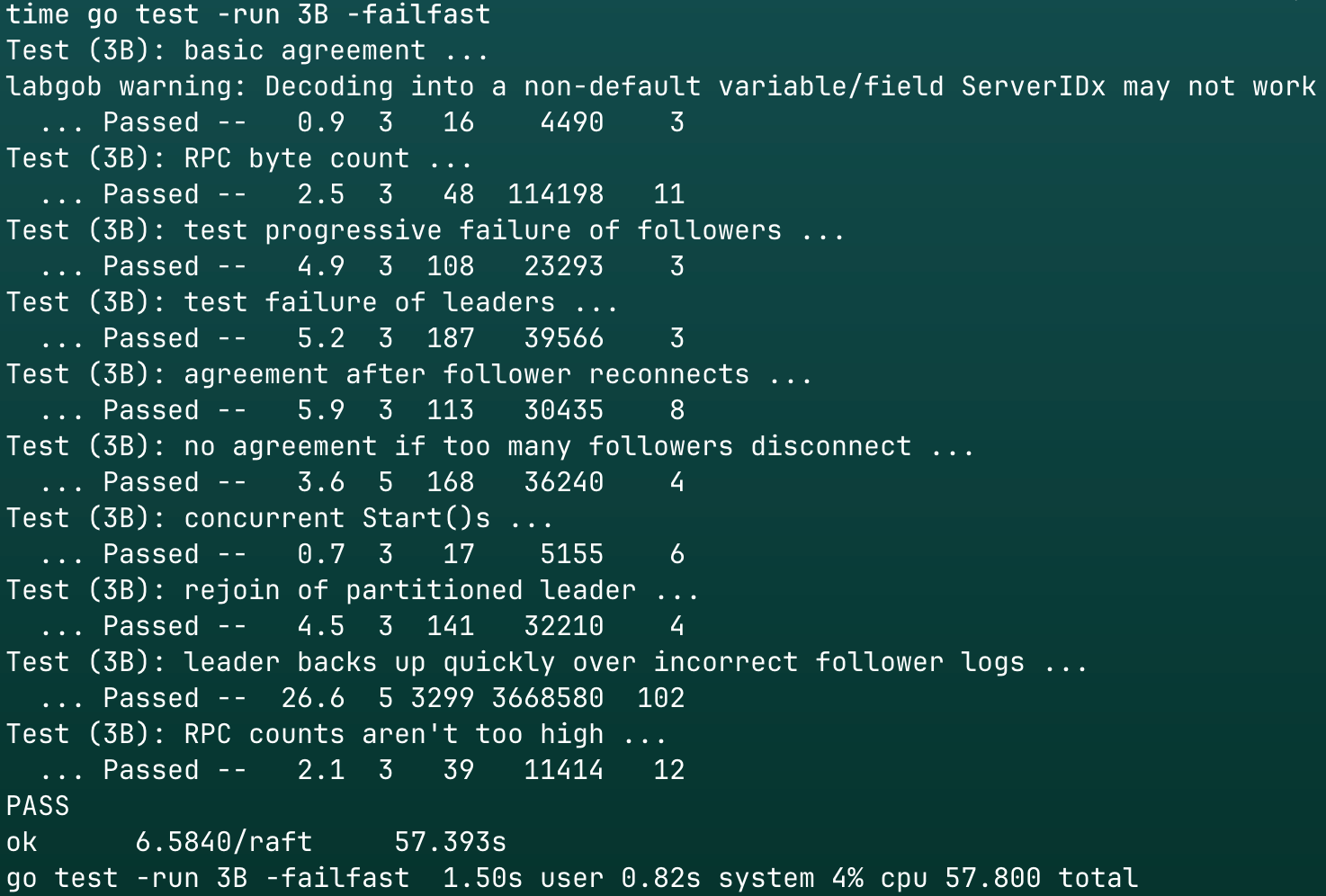
结果
3B测试100次
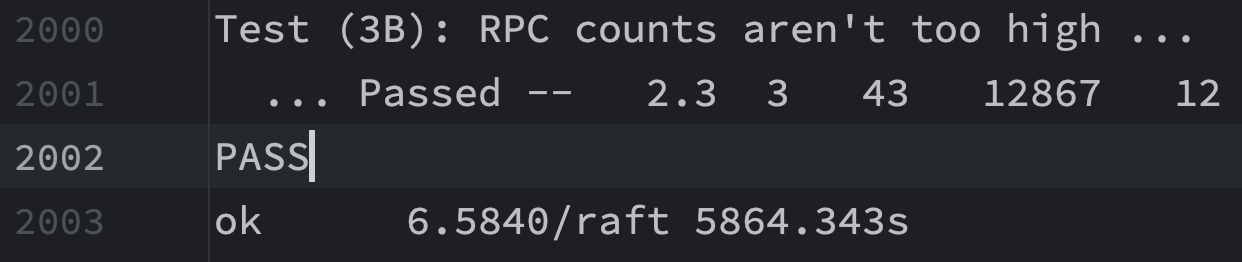
单次用时
Part 3C: persistence
这章就是在Persistent state发生改变时,及时持久化
如果测试报错,99%都是前两节没有写好
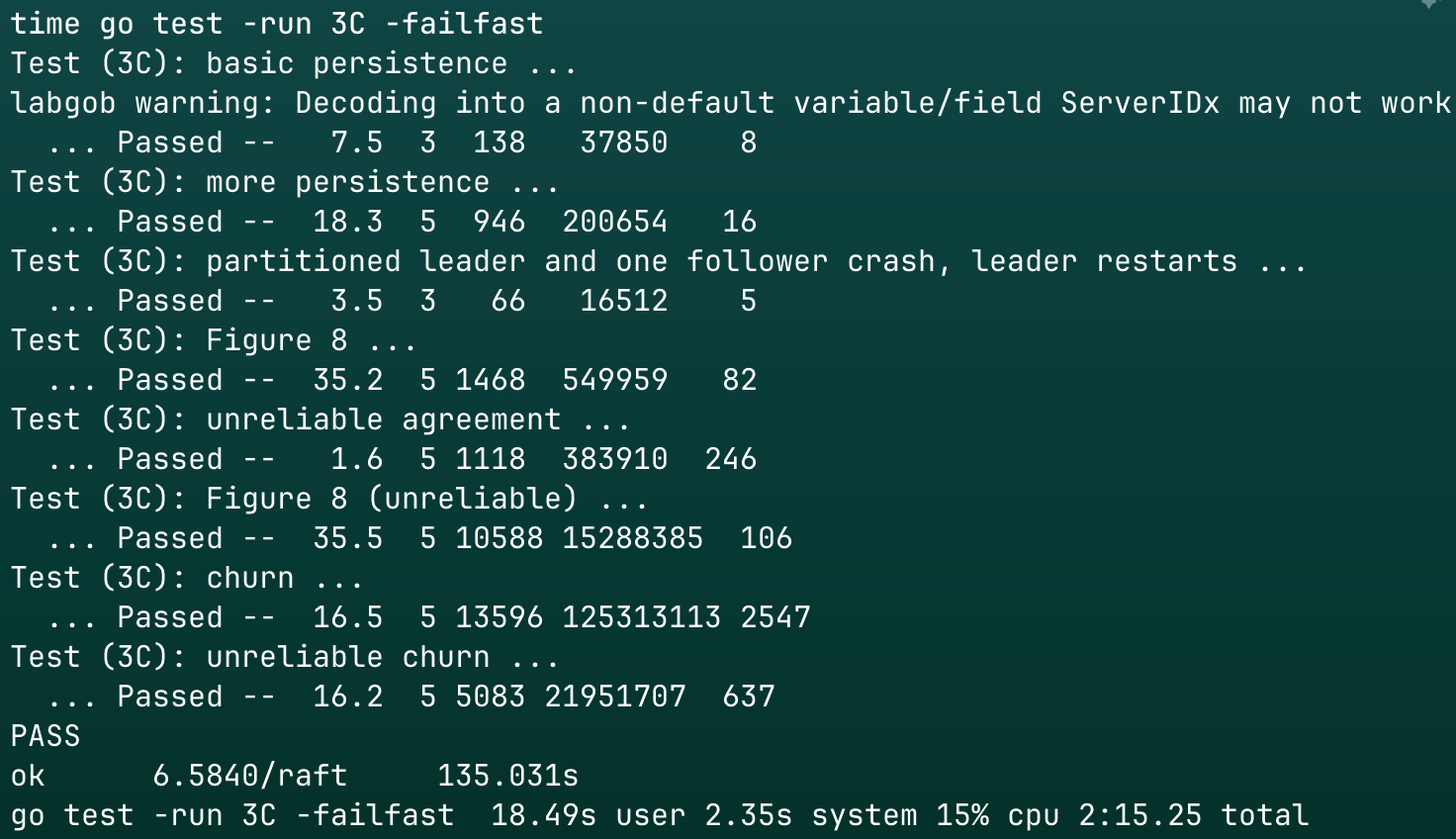
结果
3C测试100次

单次用时
Part 3D: log compaction
-
Snapshot的定义:snapshot中保存的是已Commited日志的压缩,比如x+2 x-1,则Snapshot只需要存储x=1
-
当接收到Snapshot时,可以直接将其发送给tester,无需等待CommitIndex的确认,因为Leader的CommitIndex一定大于Snapshot
-
Snapshot中保存的是已Commited日志,所以和Commit日志一样,只能向前推进,不能后退
关于这一点有一种情况需要处理
三个Server
Leader最大Log Index为140,snapshop包含Index135之前的日志
Follower1 和Leader同步
Follower2 最大Log Index也是140,但是Snapshot只包含Index 120之前的日志
之后Leader失效,Follower2当选Leader,发送snapshot给Follower1,Follower2已经有了更新的snapshot,所以没有更新
Follower2将nextIndex[1]更新为121,下次发送日志prevLogIndex就是120,此时Follower会发现找不到Index 为120的日志
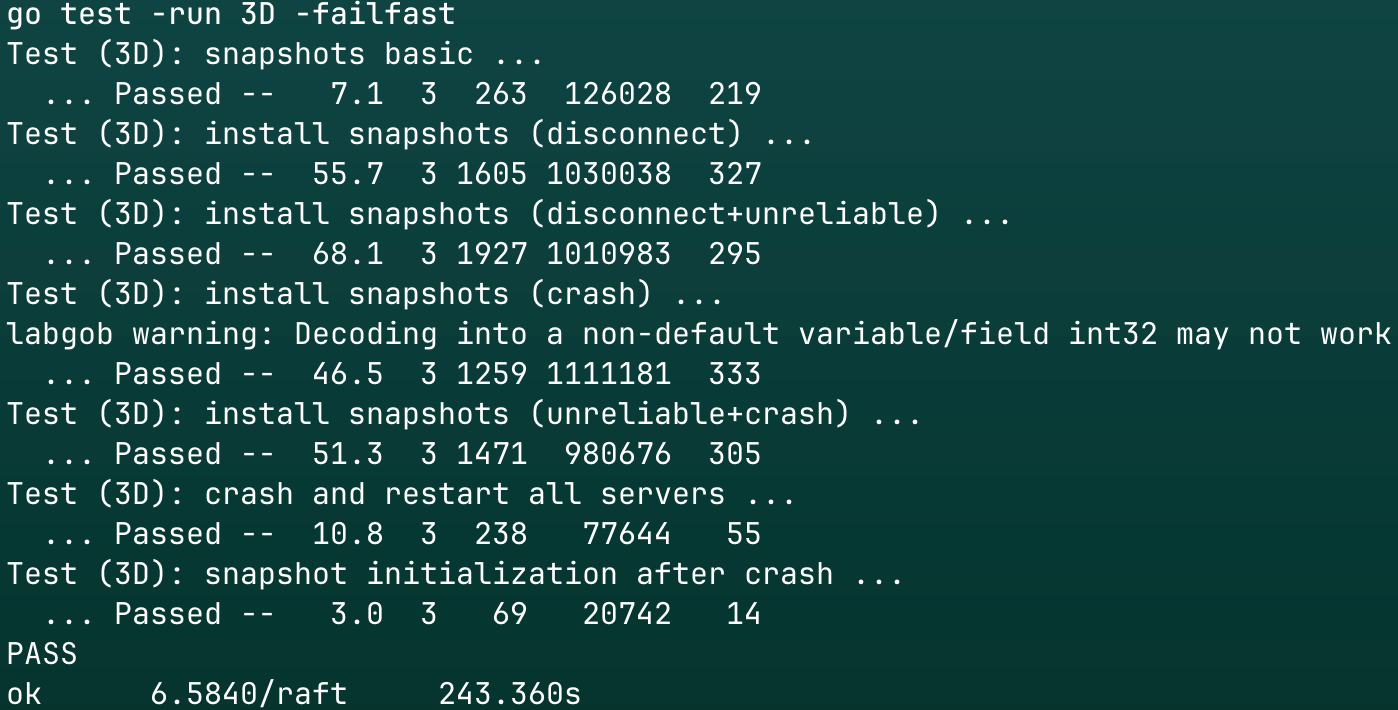
结果
测试100次

单次用时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号