Lab 1 记录
一、非并行版本分析
1.非并行版本MapReduce流程
- 通过第一个参数,传入Map和Reduce 函数
- 之后的参数为待处理文件名
- 读取文件
- 调用Map函数,对文件内容进行处理,生成KV对
- 对KV对进行sort
- 按照Key进行分组,然后对每组数据调用Reduce
- 将结果写入文件
二、Lab思路
概述:Worker向Coordinator申请任务
1. Coordinator
代码位置: mr/coordinator.go
结构体介绍
type Coordinator struct {
nReduce int32
stage int32
workerCnt int32
reduceJobIds []int
mapJobPendingList *HashSet
reduceJobPendingList *HashSet
jobProcessingList *HashSet
}
-
启动
- 启动时,设置Coordinator状态为Map,
- 初始化Job List,map Job的名字为文件名,reduce Job的名字为nReduce的编号
-
初始化
Worker有新
Worker来时,为其分配编号,并传回nReduce -
分发任务
Worker会定时请求任务
- 从
JobPendingList中选取Job - 将这个Job放入
JobProcessingList - 如果任务完成,将任务从JobProcessingList彻底删除
- 发送任务后,注册一个回调函数,如果10s后这个任务还在
JobProcessingList,说明任务超时,通过回调函数将任务放回JobWaitingList
- 从
-
任务完成
Worker任务完成时,将Job从List中删除
-
状态转换
如果所有任务都已完成,
任务名就是文件名:
- Map的任务名是
输入文件名 - Reduce的任务名是
nReduce编号
-
分发任务
Worker会定时发来任务请求,
-
从
JobWaitingList中选取任务给他 -
将这个任务放入
JobProcessingList -
如果任务完成,将任务从JobProcessingList彻底删除
-
发送任务后,注册一个回调函数,如果10s后这个任务还在
JobProcessingList,说明任务超时,通过回调函数将任务放回JobWaitingList
-
-
当
JobWaitingList和JobProcessingList皆为空时,意味着任务完成,Coordinator可以退出 -
只有当Map完成时,才可进行Reduce
-
Map阶段
-
Reduce阶段
-
Worker
代码地址:mr/worker.go
1.Map Worer
读取文件,调用Map函数处理,将结果按照Hash值分配到nReduce个文件
中间文件名mr-X-Y
- X:Map编号
- Y:Reduce编号
2.Reduce Worker
结果文件名:mr-out-X
- X:Reduce编号
注:为应对两个Worker同时处理某个任务、以及任务失败时的情况,Worker创建文件时,为其添加特殊后缀,比如mr-X-Y创建为mr-X-Y_123456。在任务处理完成,向coordinate汇报时,修改回正确文件名mr-X-Y。
结果
代码地址:
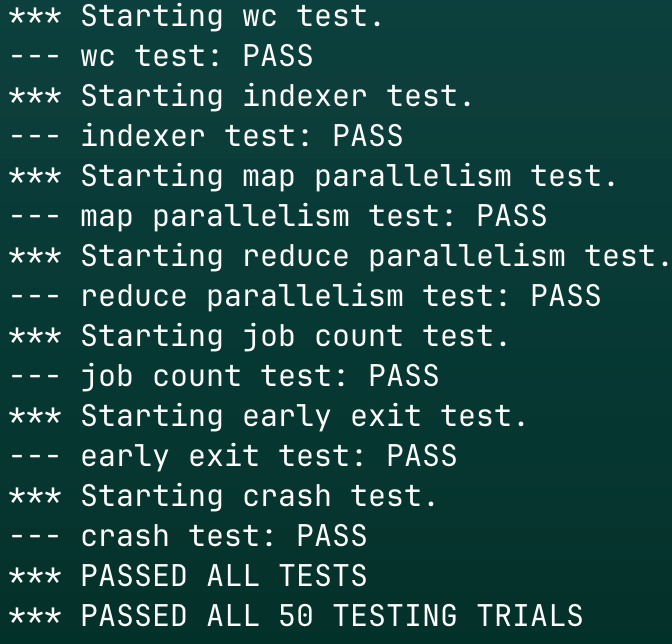
测试结果
通过了50次测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号