
CH-10 容错机制
CH-10 容错机制
Flink有一套完整的容错机制来保证故障后的恢复,其中最重要的是检查点。本章将深入了解检查点的原理和Flink的容错机制。
10.1CheckPoint
-
触发保存时机
周期性保存,间隔时间可以设置
val env = StreamExecutionEnvironment.getExecutionEnvironment env.enableCheckpointing(1000) -
怎么保存状态
检查点的保存涉及到状态和数据流,我们在保存时,必须保证重启时能精准恢复,同时最小限度的影响当前的执行
最终的方案:当所有任务都恰好处理完一个相同的输入数据时,将状态保存下来,这样,一个数据要么是被所有任务完整地处理完,状态得到了保存;要么就是没处理完,状态全部没保存:这就相当于构建了一个事务。
-
保存的具体流程
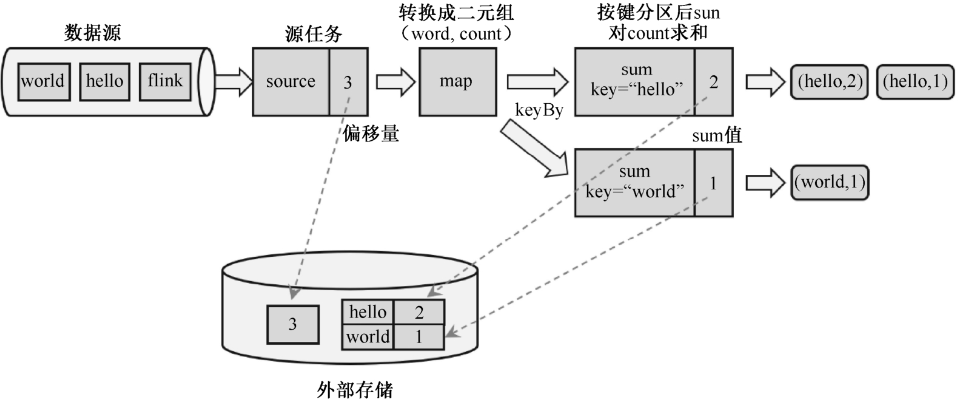
保存检查点的关键是:要等所有任务将
同一个数据处理完毕。以下图为例,
- 从Source开始,Source当前处理到第三个数据,存储Source的偏移量3
- 对之后有状态的算子,比如sum,当sum处理完三个数据时,将其状态保存下来(具体算法在[10.2节](#10.2 检查点算法))
- 之后的算子以此类推
10.1 从检查点中恢复
还是以前一个案例为例,我们存储了处理完第3个数据时的状态,之后继续处理,当处理到第5个数据时,在sum处发生了一场,Flink宕机,重启,我们将存储的状态恢复。
-
此时都是处理完第三个数据时的状态
-
Source将保存的偏移量提交给数据源,要求从第4个数据开始接收
-
之后就正常运行,当处理到第5个数据时,就追上了发生故障时的系统状态。
之后正常处理,就好像没有发生过故障一样;既没有丢掉数据也没有重复计算,这就保证了计算结果的准确。在分布式系统中,这叫作实现了
精确一次的状态一致性保证(exactly once)
从这里也可以看出,要正确从检查点中恢复,必须知道每个算子的类型和拓扑结构。因此我们在改动程序、修复bug时要保证状态的拓扑顺序和类型不变。
10.2 检查点算法
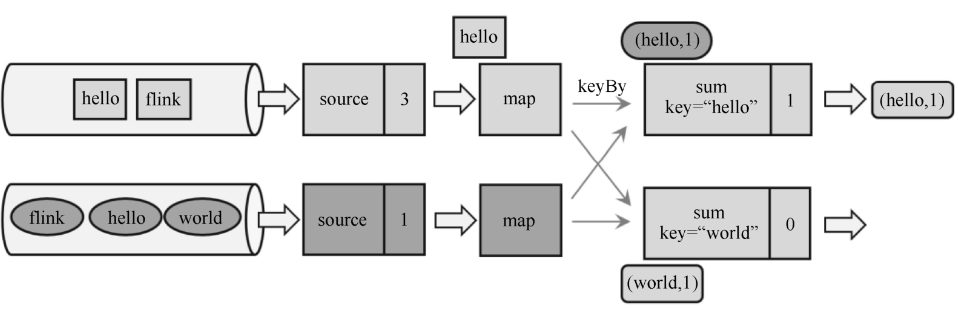
- JobManager发送指令,触发检查点的保存.
- 两个Source保存当前状态,同时向数据流插入分界线(分界线和水位线一样,都是一种特殊的数据,为了完成检查点保存。同时,分界线和水位线一样,当上下游并行度不同时,会向下游所有算子广播分界线)。
- map算子没有状态,不需要保存,略过
- 到达sum算子
- 每个map都会向上下两个sum分发分界线
- 如果
sum-1收到map-0的分界线- 之后如果收到
map-1的数据,继续执行 - 如果收到
map-0的数据,将其缓存起来,暂不执行,等到状态保存完再处理
- 之后如果收到
- 如果两个
sum都收到了分界线,即各分区的分界线都对齐了,那就保存当前状态到CheckPoint。
- 当
JobManager收到所有任务成功保存状态的信息,就可以确认当前检查点成功保存。之后遇到故障就可以从这里恢复了。
10.3 检查点配置项
-
启用检查点
// 传入保存检查点间隔时间 env.enableCheckpointing(1000) -
检查点存储
// 存储检查点到堆内存 env.getCheckpointConfig.setCheckpointStorage(new JobManagerCheckpointStorage) // 存储检查点到文件系统 env.getCheckpointConfig.setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://...."))默认使用堆内存,推荐使用文件系统,相关文档
-
设置检查点模式
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);有精确一次和至少一次两个选项
-
超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);保存检查点的用时一旦超出超时时间,就会被丢弃。
-
最小间隔时间
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);上一个检查点完成后,最多多久可以开始保存下一个检查点,即使已经达到了周期触发的时间点,只要没达到最小间隔时间,就不能开启下一次检查点的保存。这就为正常处理数据留下了充足的间隙。
当指定这个参数时,
maxConcurrentCheckpoints的值强制为1。 -
最大并发检查点数量
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);指定运行中的检查点最多可以有多少个。由于每个任务的处理进度不同,可能出现后面的任务还没完成前一个检查点的保存,前面任务已经开始保存下一个检查点了。这个参数限制同时进行的最大数量。
10.2 保存点
1.和检查点的异同
-
原理和算法与检查点完全相同。
-
保存点中的状态快照,是以算子id和状态名称组织起来的,相当于一个键值对。
env .addSource(new BasicEventSource) //指定算子id .uid("Source-Event") .keyBy(_.user) .process(new ...) //指定算子id .uid("Process-1") .print()为了方便后续维护,强烈建议为每一个算子手动指定id
-
最大的区别是触发时机。检查点由Flink自动管理、定期创建,发生故障后自动读取进行恢复;
保存点由用户手动触发保存,两者原理一致,但用途有所差别:检查点主要用来进行故障恢复,是容错机制的核心;保存点则用来做有计划的手动备份和恢复。
-
保存点可以当作一个运维工具。在需要的时候创建一个保存点,然后停止应用,调整之后再从保存点重启。适用的具体场景如下:
-
版本管理和归档存储
对重要的节点进行手动备份,设置为某一版本,归档存储应用程序的状态。
-
更新Flink版本。
当Flink版本升级时,程序本身一般是兼容的。不需要重新执行所有的计算,只要创建一个保存点,停掉应用、升级Flink后,从保存点重启就可以了。
-
更新应用程序。
前提是程序必须是兼容的,即状态的拓扑结构和数据类型都没变,这样才能从之前的保存点加载。
-
调整并行度。
应用运行过程中,发现需要的资源不足或已经有了大量剩余,可以通过从保存点重启的方式,将应用程序的并行度增大或减小。
-
2. 使用
使用检查的文档在这里https://nightlies.apache.org/flink/flink-docs-release-1.20/docs/ops/state/savepoints/
10.3 状态一致性
基本概念
一致性就是结果的正确性。
对于分布式系统,不同节点的数据应该总是一致的,即从不同节点能读取到相同的值
对于事务,要求提交更新操作后,能够读取到新的数据。
对于Flink,多个节点并行处理不同的任务,要保证计算结果的正确性,就不能漏掉任何数据,也不能重复处理数据。正常情况下结果是正确的,但在发生故障且需要恢复状态进行回滚时就需要更多的保障机制。通过检查点的保存保证了状态恢复后结果的正确性,所以主要讨论状态的一致性。
状态一致性有三种级别
-
最多一次。
任务发生故障时,最简单的做法就是直接重启,别的什么都不干,既不恢复丢失的状态,也不重放丢失的数据。
正常情况下每个数据都会被处理一次,遇到故障时就丢掉,所以就是
最多处理一次。尽管看起来比较糟糕,但如果主要诉求是“快”,而且能接受近似正确的结果,那么这个方案也不错。
-
至少一次
(at-least-once)如果希望至少不要丢掉数据。这就是
至少一次(at-least-once),即所有数据都不会丢,肯定被处理了;不过不能保证只处理一次,有些数据会被重复处理。在有些场景下,重复处理不影响结果的正确性,这种操作具有
幂等性。比如,统计电商网站的UV,需要对每个用户的访问数据进行去重,即使同一个数据被处理多次,也不会影响最终的结果,这时使用at-least-once完全没问题。为了达到
at-least-once,需要在发生故障时能够重放数据。最常见的做法是,将所有数据保存下来,只需要记录偏移量,当任务发生故障重启后,重置偏移量就可以重放数据。Kafka就是这种架构。 -
精确一次
(exactly-once)数据不能丢失,且只被处理一次,不会重复处理。
要做的这点,首先要达到
at-least-once,就是数据不丢失。所以同样需要数据重放机制。另外,还要有专门的设计保证每个数据只被处理一次。Flink中使用检查点(checkpoint)来保证exactly-once语义。
完整的流处理应用包括数据源、流处理器和外部存储系统三部分。这个完整应用的一致性就叫作端到端(end-to-end)的状态一致性,它取决于三个组件中最弱的那一环。能否达到at-least-once,主要看数据源能够重放数据;而能否达到exactly-once,流处理器内部、数据源、外部存储都要有相应的保证机制。接下来详细讨论端到端的exactly-once如何保证。
10.4 端到端精确一次
由于检查点保存的是之前所有任务处理完某个数据后的状态快照,所以重放之后的数据引起的状态改变一定不会包含在里面,最终每个数据只会被处理一次,因此流处理器的精确一次已经保证。
所以,端到端一致性的关键点,在于输入的数据源端和输出的外部存储端。
1.输入端保证
- 不重:保存检查点时,Source算子会保存当前处理的数据偏移量,保证了数据不会被重复处理
- 不漏:对于输入端而言,想要在故障恢复后不丢数据,外部数据源必须拥有重放数据的能力,比如Kafka就有这样的能力。从而保证数据不会丢失,
以上两点就是保证输入端精确一次的基本要求
2.输出端保证
对Flink来说,重复计算没有影响,因为状态已经回滚,最终改变只会发生一次;但对于外部系统来说,已经写入的结果无法收回,再次执行写入会把同一个数据写入两次。所以这时只保证了端到端的at-least-once语义。
为实现exactly-once,还需要对外部存储系统、Sink算子有额外的要求。能够保证exactly-once的写入方式有以下两种:
-
幂等写入
“幂等”操作:即一个操作可以重复执行很多次,但只导致一次结果更改。
最典型的就是HashMap的插入,如果是相同的键值对,重复插入不会改变什么。
所以这种方式限制在于外部存储必须支持幂等写入:比如Redis中键值存储,或者关系型数据库(如MySQL)中满足查询条件的更新操作。
-
事务写入
如果能够构建一个事务,让写入操作可以随着检查点来提交和回滚,那么自然就可以解决重复写入的问题了
事务写入的基本思想是这样的
用一个事务来进行数据向外部系统的写入,这个事务与检查点绑定。当Sink遇到
barrier时,保存状态的同时开启一个事务,接下来所有数据的写入都在这个事务中;等到当前检查点保存完毕,将事务提交,所有写入的数据就真正可用了。如果中间出现故障,状态会回退到上一个检查点,而当前事务没有正常关闭(因为当前检查点没有保存完),所以也会回滚,写入外部的数据就被撤销了。
事务写入有两种实现方式:预写日志和两阶段提交(2PC)。
-
WAL
先将数据放在log中,等到确认再写入外部系统,但是存在问题,因为WAL并不是外部系统提供的功能,如果log写入到外部系统的过程中如果出错,Flink无法察觉。
在Flink中,DataStream API提供了一个模板类GenericWriteAheadSink,用来实现这种事务型的写入方式。
-
两阶段提交(2PC)。
步骤:
- 当第一条数据到来或者收到检查点的分界线时,Sink任务都会启动一个事务。
- 接下来接收到的所有数据,都通过这个事务写入外部系统;这时,由于事务没有提交,因此数据尽管写入了外部系统,但是不可用,是“预提交”的状态。
- 当Sink任务收到JobManager发来检查点完成的通知时,正式提交事务,写入的结果就真正可用了。
Flink提供了
TwoPhaseCommitSinkFunction接口,方便自定义实现两阶段提交的SinkFunction实现,提供了真正端到端的exactly-once保证。但是两阶段提交虽然精巧,却对外部系统有很高的要求:
- 外部系统必须提供事务支持,或者Sink任务必须能够模拟外部系统上的事务。
- 在检查点的间隔期间里,必须能够开启一个事务,并接受数据写入。
- 在收到检查点完成的通知之前,事务必须是“等待提交”的状态。在故障恢复的情况下,这可能需要一些时间。如果这时候外部系统关闭事务(例如,超时了),那么未提交的数据就会丢失。
- Sink任务必须能够在进程失败后恢复事务。
- 提交事务必须是幂等操作。也就是说,事务的重复提交应该是无效的。
Kafka使用的2PC方案
-
3. Kafka实现端到端一致性
需要做的配置
-
必须启用检查点
-
在
FlinkKafkaProducer的构造函数中传入参数Semantic.EXACTLY_ONCE -
配置Kafka读取数据的消费者的隔离级别
这里所说的Kafka,是写入的外部系统。预提交阶段数据已经写入,只是被标记为未提交(uncommitted),
Kafka中默认的隔离级别isolation.level是
read_uncommitted,也就是可以读取未提交的数据。这样一来,外部应用就可以直接消费未提交的数据,对于事务性的保证就失效了。应该将隔离级别配置为read_committed,表示消费者遇到未提交的消息时应停止消费,直到消息被标记为已提交再次恢复消费。当然,这样做外部应用消费数据会有显著的延迟。 -
事务超时配置。
事务超时时间
transaction.timeout.ms默认是1小时,而Kafka集群配置的事务最大超时时间transaction.max.timeout.ms默认是15分钟。所以在检查点保存时间很长时,有可能出现Kafka已经认为事务超时了,丢弃了预提交的数据;而Sink任务认为还可以继续等待。如果接下来检查点保存成功,发生故障后回滚到这个检查点的状态,这部分数据就被真正丢掉了。所以这两个超时时间,前者应该小于等于后者。

