

1~4章
零、Linux文件基本操作
在Linux平台,可以认为socket是一种特殊的文件,使用相同的API进行操作。
1.文件描述符
用一个数字指代某个文件,对文件描述符进行操作,就会修改文件内容,
每个进程的文件描述符都是从0开始且独享的
有3个特殊的文件描述符无需创建即可使用
| 文件描述符 | 对象 |
|---|---|
| 0 | 标准输入 |
| 1 | 标准输出 |
| 2 | 标准错误 |
2.open
第一个参数是文件路径,第二个参数是文件打开模式
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 成功返回文件描述符,失败返回-1
int open(const char *path, int flag)
| 打开模式 | 含义 |
|---|---|
| O_CREAT | 必要时创建文件 |
| O_TRUNC | 删除全部现有数据 |
| O_APPEND | 追加 |
| O_RDONLY | 只读 |
| O_WRONLY | 只写 |
| O_RDWR | 读写 |
这些参数都是宏,实际都是二进制的值,所以可以同时以多个模式打开, 使用OR进行合并传递
O_CREAT | O_TRUNC
3.close
#include<unistd.h>
// 成功返回0, 失败-1
int close(int fd)
4. write
#include<unistd.h>
// 成功返回写入字节数, 失败返回-1
ssize_t write(int fd, const void *buf, size_t nbytes);
/*
fd: 文件描述符
buf: 待写入数据所在地址(指针)
nbytes: 要写入的字节数
*/
5. read
#include<unistd.h>
// 成功返回接收字节数(遇到文件末尾返回0), 失败返回-1
ssize_t read(int fd, void *buf, size_t nbytes);
/*
1.fd: 文件描述符
2.buf: 接收数据的地址值
3.nbytes: 最大可接收字节数
*/
一.Socket
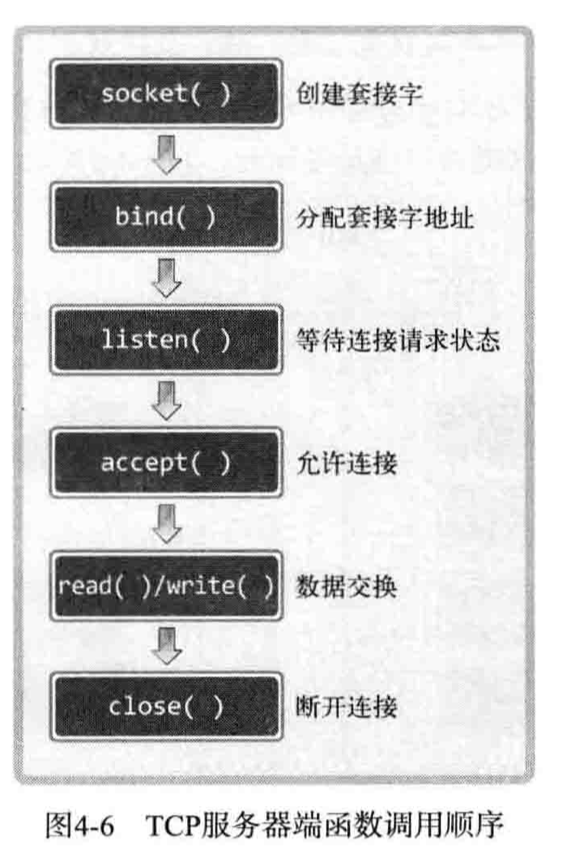
Socket的详细介绍在这里
简单的说,Socket就是一组系统调用,是一个文件,提供以下两点功能:
- 将应用程序数据从用户缓冲区中复制到TCP/UDP内核发送缓冲区,以交付内核来发送数据,或者从内核TCP/UDP接收缓冲区中复制数据到用户缓冲区,以读取数据
- 应用程序可以通过Socket修改内核中各层协议的某些头部信息和数据结构,从而控制底层通信的行为。
大致行为如下
- 接收数据:网卡 → 网卡驱动 → OS进程里的TCP通信组件 → Socket文件 → 用户进程
- 发送数据:用户进程 → Socket文件 → OS进程里的TCP通信组件 → 网卡驱动 → 网卡
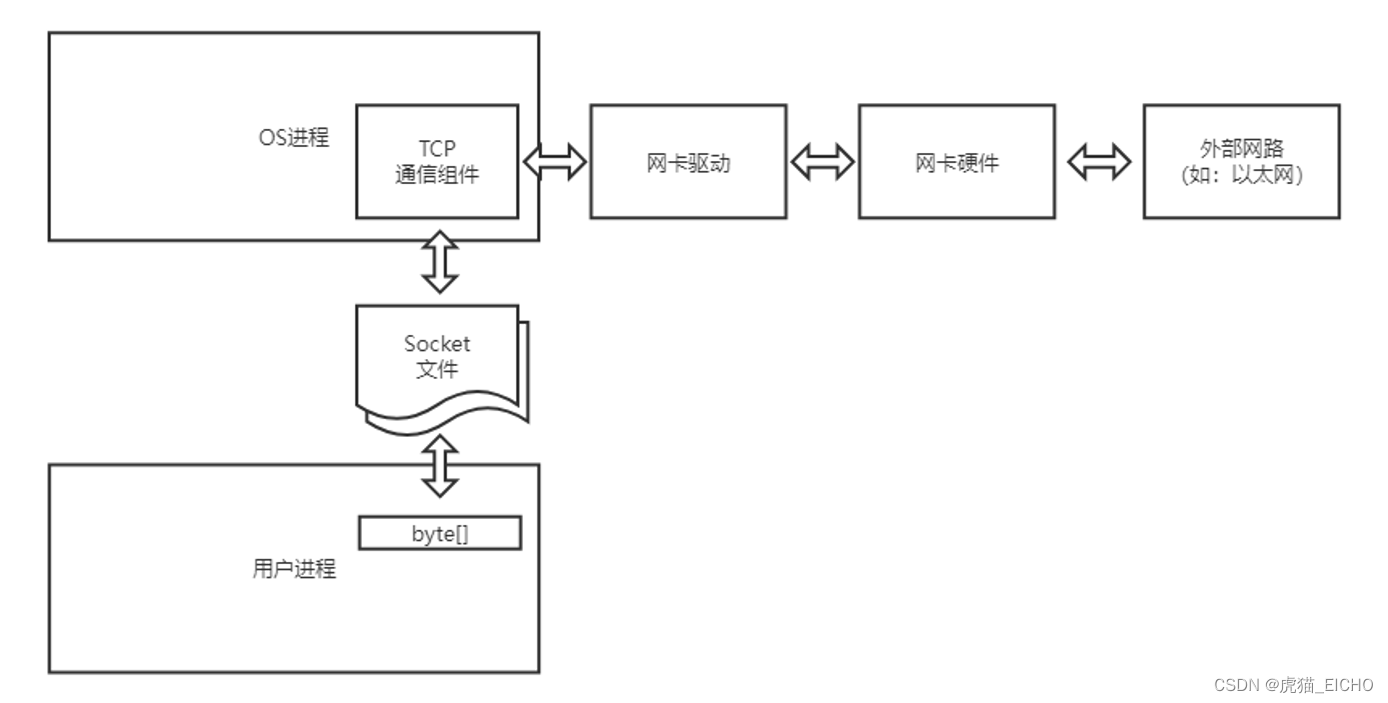
socket和文件的操作基本一样
#include <sys/socket.h>
// 成功返回文件描述符,失败返回-1
int socket(int domain, int type, int protocol);
/*
1.domain: Socket使用的协议族
2.type: Socket类型
3.prorocal: 通信协议
*/
1.1 协议族
| 名称 | 协议族 |
|---|---|
| PF_INET | IPV4 |
| PF_INET6 | IPV6 |
| PF_LOCAL | 本地通信 |
| PF_PACKET | 底层套接字 |
| PF_IPX | IPX NOVELL |
1.2 Socket类型
1.面向连接的套接字
TCP --
SOCK_STREAM
特性
- 丢失重传,保证数据不会丢失
- 按序到达
- 传输的数据不存在数据边界
关于第三点,就是socket内部有缓冲(buffer),发送方调用三次write写入三个数据包到缓冲区内,接收方一次read就可读取全部数据,而不是三次,read和write的调用次数之间没有关系,即不存在数据边界
如果缓冲满了数据是否会丢失?
不会,会停止接收数据,等缓冲区有空位再继续接收,接收时如果出现数据丢失,会要求发送方重传.
可自行搜索滑动窗口
2.面向消息的套接字
UDP --
SOCK_DGRAM
特性
- 不可靠
- 无需传输
- 有数据边界
- 每次传输的数据大小有限制
read和write的次数一一对应
1.3 通信协议
IPV4中,面向连接的传输协议只有TCP,面向消息的传输协议只有UDP,
一般情况下传递前两个参数即可创建Socket。第三个参数传入0即可,除非遇到以下这种情况:
“同一协议族中存在多个数据传输方式相同的协议”
int tcp_socket = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP);
int udp_socket = socket(PF_INET, SOCK_DGRAM, IPPROTO_UDP);
二、Bind()
向Socket分配网络地址
代码
#include<sys/socket.h>
// 成功返回0,失败返回-1
int bind(int sockfd, struct sockaddr *myaddr, socklen_t addrlen);
/*
sockfd: 套接字文件描述符
myaddr: 要绑定的地址信息
addrlen: 第二个结构体变量长度
*/
#include<arpa/inet.h>
#include<string.h>
#include<sys/socket.h>
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof serv_addr);
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(atoi(argv[1]));
bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof serv_addr);
2.1 网络地址信息的表示
struct sockaddr_in
struct sockaddr_in {
__uint8_t sin_len;
sa_family_t sin_family; // 协议族
in_port_t sin_port; // 16位端口号
struct in_addr sin_addr; // 32位IP地址
char sin_zero[8]; // 不使用
};
typedef __uint32_t in_addr_t;
struct in_addr {
in_addr_t s_addr;
};
一些定义好的数据类型
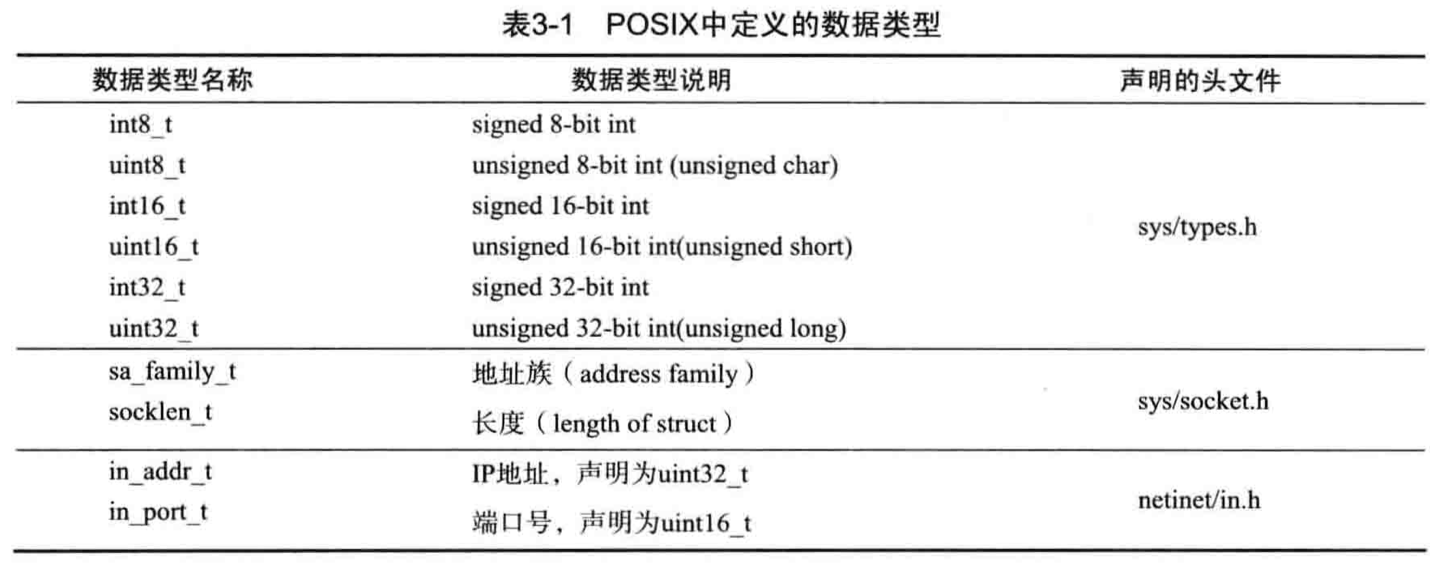
sin_family
| 地址族 | 含义 |
|---|---|
| AF_INET | 供IPV4使用 |
| AF_INET6 | 供IPV6使用 |
| AF_LOCAl | 本地通信使用 |
sin_addr
struct in_addr内部只有一个变量in_addr_t s_addr,为什么要专门定义一个结构体?
《UNIX网络编程》有讲原因:
早期的版本(4.2BSD)把in_aadr定义为union,方便灵活访问32位IPv4地址,或者其中任意4字节。
这被用在地址被划分成A、B和C三类的时期,便于获取地址中的任意字节。然而随着子网划分和CIDR的出现,地址类正在消失,联合不再需要。如今大多数系统已经废除了该union,转而把in_addr定义为仅有一个in_addr_t字段的结构。
我之前介绍过union
尝试实现union
union in_addr_test{
struct{uint8_t fir:8, sec:8, thi: 8, four: 8;} ip_split;
in_addr_t s_addr;
};
struct sockaddr_in_test {
__uint8_t sin_len;
sa_family_t sin_family;
in_port_t sin_port;
in_addr_test sin_addr;
char sin_zero[8];
};
sin_zero
无特殊含义,只是为了和struct sockaddr大小保持一致所添加,必须填充为0
bind()接收的第二个参数是struct sockaddr:
struct sockaddr {
sa_family_t sa_family; // 地址族
char sa_data[14]; // 地址信息
};
sa_data存储IP地址和端口号等信息,未使用的地方填0,但是这样做,数据操作很麻烦,容易出错,所以有了struct sockaddr_in,方便填充地址,也不易出错,但每次传递给bind()时都需要转换数据类型
2.2 网络字节序和地址变换
-
大端序: 低位高字节
-
小端序: 低位低字节
常用家用机一般都是小端序,但是网络传输使用大端序,需要进行字节序转换
常用字节序转换函数
// h: 主机(host)字节序
// n: 网络(network)字节序
//host to network short, 把一个short型数据从主机字节序转化为网络字节序
unsigned short htons(unsigned short);
unsigned short ntohs(unsigned short);
unsigned long htonl(unsigned short);
unsigned long ntohl(unsigned short);
主机序可能是小端,也可能是大端,如果是大端,直接填入也可以,但是可移植性会减弱,而且不安全。
除了向struct sockaddr_in填充数据外,其他时候无需考虑字节序问题,会自动完成
IP地址格式化
1.inet_addr
#include<arpa/inet.h>
in_addr_t inet_addr(const char* string);
将字符串类型的点分十进制IP地址(例如: 192.168.0.101)转换为32位整型数据并返回
2.inet_aton
#include<arpa/inet.h>
// 成功返回1, 失败返回0
int inet_aton(const char* string, struct in_addr* addr);
// string是点分十进制IP地址字符串
// addr是保存转换结果变量的地址值
inet_addr转换完还需要填充进结构体,使用inet_aton传入结构体,会自动完成填充
3.inet_ntoa
#include<arpa/inet.h>
char* inet_ntoa(struct in_addr adr);
//成功时返回转换的字符串地址值,失败时返回-1
传入struct in_addr,返回ip地址
INADDR_ANY
一个特殊的IP地址,使用这个ip地址,程序会自动获取当前计算机的IP地址,然后进行监听,如果一个计算机有多个网卡,工作在多个IP地址,则可同时接收不同IP地址的数据
三.Listen()
进入等待连接状态
#include<sys.socket.h>
//成功返回0, 失败返回-1
int listen(int socket, int backlog);
// socket: 进入等待连接状态的socket
// backlog: 连接请求等待队列的长度

客户端请求连接,请求在被受理前,将一直处于等待状态
客户端连接请求本身也是从网络中接收到的一种数据,要想接收就需要套接字。因此第一个参数传递的socket的任务就是接收连接请求
第二个参数决定了等待队列的大小。即连接请求等待队列,准备好服务器端套接字和连接请求等待队列后,这种可接收连接请求的状态称为等待连接请求状态。
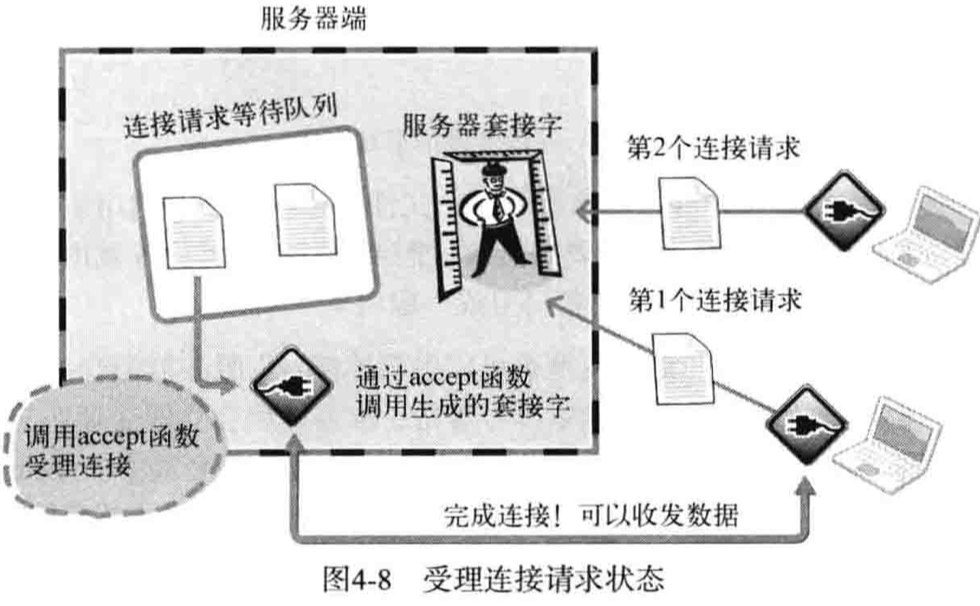
四.accept()
#include<sys/socket.h>
// 成功返回新创建的socket, 失败-1
int accept(int sock, struct sockaddr* addr, socklen_t* addrlen);
// sock: Server Socket的文件描述符
// addr: 保存客户端地址信息
// addrlen: 第二个参数的size,调用完成后,会被填入客户端的地址长度
accept()从等待队列中取出1个连接请求,创建套接字并完成连接请求,之后可通过新创建的socket与客户端完成信息传递
调用成功时,accept()内部将产生用于数据I/O的套接字,并返回其文件描述符。需要强调的是,IO套接字是自动创建的,并自动与发起连接请求的客户端建立连接。图4-8展示了accept函数调用过程。
五.connect()
connect用来和server进行连接,
调用connect,会自动给client端分配ip和端口号,
client端的IP和端口号无需手动指定,可以在调用connect时自动分配
