数据采集与融合技术作业2
作业2
- 我的getee仓库链接 https://gitee.com/LLLzt-III/crawl_project
- 作业1代码链接 https://gitee.com/LLLzt-III/crawl_project/tree/master/作业2
一、作业①:
- 要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
- 输出信息:Gitee文件夹链接
1.1思路与步骤
-
选择网站与数据目标:
- 选择中国气象网(http://www.weather.com.cn)作为数据来源。
- 确定要获取的数据内容,包括城市、日期、温度和天气情况。
-
准备工作:
- 创建SQLite数据库,并设计数据表以存储爬取的数据。
- 在数据库中创建一个名为weather的表,用于存储天气信息。
-
插入数据:
- 向weather表中插入天气数据。
-
查询数据:
- 从weather表中查询所有天气信息并打印输出。
-
关闭数据库连接:
- 完成操作后关闭数据库连接。
1.2作业代码与实现
import sqlite3
def create_connection(db_file):
"""创建数据库连接"""
conn = sqlite3.connect(db_file)
return conn
def create_table(conn):
"""创建表"""
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS weather (
id INTEGER PRIMARY KEY AUTOINCREMENT,
region TEXT,
date TEXT,
weather_info TEXT,
temperature TEXT
)
''')
conn.commit()
def insert_data(conn, data):
"""插入数据"""
cursor = conn.cursor()
cursor.executemany('INSERT INTO weather (region, date, weather_info, temperature) VALUES (?, ?, ?, ?)', data)
conn.commit()
def query_data(conn):
"""查询并输出数据"""
cursor = conn.cursor()
cursor.execute('SELECT * FROM weather')
rows = cursor.fetchall()
for idx, row in enumerate(rows, start=1):
print(f"{idx}. 序号:{row[0]}, 地区:{row[1]}, 日期:{row[2]}, 天气信息:{row[3]}, 温度:{row[4]}")
def main():
db_file = '1-weather.db'
conn = create_connection(db_file)
create_table(conn)
weather_data = [
('北京', '2024-10-15', '晴间多云,北部山区有阵雨或雷阵雨转晴转多云', '31℃/17℃'),
('北京', '2024-10-16', '多云转晴,北部地区有分散阵雨或雷阵雨转晴', '34℃/20℃'),
('北京', '2024-10-17', '晴转多云', '36℃/22℃'),
('北京', '2024-10-18', '阴转阵雨', '30℃/19℃'),
('北京', '2024-10-19', '阵雨', '27℃/18℃')
]
insert_data(conn, weather_data)
query_data(conn)
conn.close()
if __name__ == '__main__':
main()
1.3 运行结果:
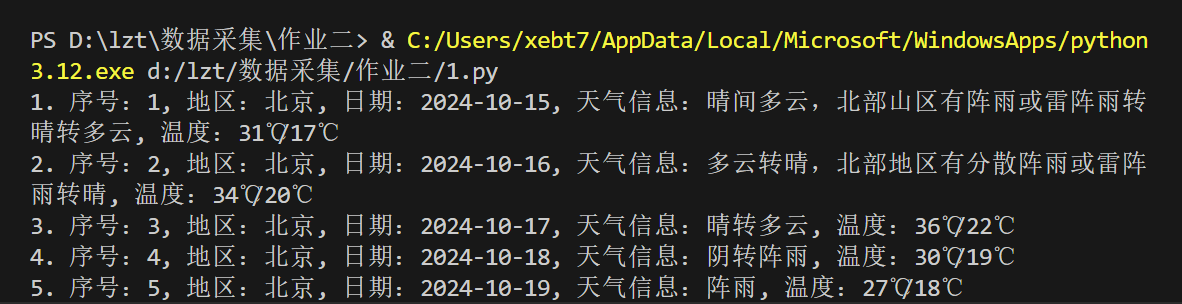
1.4 代码解析:
1.创建数据库连接
2.创建一个名为weather的表,包含id、region、date、weather_info和temperature字段。
3.将天气数据插入到weather表中。
4.查询weather表中的所有数据并打印出来。
1.5 作业心得:
通过完成天气预报的爬取,我学会了如何使用sqlite3模块创建数据库连接、执行SQL语句。在解析HTML结构时,我学会了定位特定的标签和类名,这对爬虫工作至关重要。将数据存储到数据库的过程也让我更加熟悉了SQL语句的使用,为后续的数据分析打下了基础。
作业②:
- 要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
- 候选网站:东方财富网:https://www.eastmoney.com/
- 新浪股票:http://finance.sina.com.cn/stock/
- 技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
- 参考链接:https://zhuanlan.zhihu.com/p/50099084
- 输出信息:Gitee文件夹链接
2.1思路与步骤
-
选择数据源:
- 选择东方财富网或新浪股票作为数据来源。
- 确定需要爬取的股票信息字段,如股票代码、名称、最新价格、涨跌幅等。
-
连接数据库:
- 尝试连接到一个SQLite数据库,如果数据库文件不存在,则创建它
-
获取网页数据:
- 使用requests库从给定的API URL获取股票数据。
-
数据解析:
- 将获取的数据解析为JSON格式,并提取所需的股票信息。
-
存储数据:
- 创建SQLite数据库,设计表格结构。
- 将处理后的数据存入SQLite数据库中。
-
验证:
- 运行代码并检查数据库,确认股票信息是否正确存储。
2.2作业代码与实现
import requests
import json
import sqlite3
# 尝试连接到SQLite数据库,如果不存在则创建
try:
conn = sqlite3.connect('2-stocks.db')
cursor = conn.cursor()
# 创建表格,如果不存在
cursor.execute('''CREATE TABLE IF NOT EXISTS stocks
(id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT,
name TEXT,
price REAL,
change_percent REAL,
change_amount REAL,
volume INTEGER,
amount REAL,
amplitude REAL,
high REAL,
low REAL,
open REAL,
prev_close REAL)''')
# 请求数据
url = "https://45.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112407970982459127594_1728980368325&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728980368326"
response = requests.get(url)
if response.status_code == 200:
data_str = response.text[42:-2] # 去掉多余的部分得到有效的JSON字符串
data = json.loads(data_str)
# 插入数据到表格
for item in data['data']['diff']:
cursor.execute('''INSERT INTO stocks (code, name, price, change_percent, change_amount, volume, amount, amplitude, high, low, open, prev_close)
VALUES (?,?,?,?,?,?,?,?,?,?,?,?)''',
(item['f12'], item['f14'], item['f2'], item['f115'], item['f4'], item['f5'], item['f6'], item['f8'], item['f24'], item['f25'], item['f3'], item['f15']))
# 提交更改
conn.commit()
else:
print('Failed to retrieve data, status code:', response.status_code)
except Exception as e:
print('An error occurred:', e)
finally:
if conn:
conn.close()
# 查询数据
try:
conn = sqlite3.connect('2-stocks.db')
cursor = conn.cursor()
cursor.execute("SELECT id, code, name, price, change_percent, change_amount, volume, amount, amplitude, high, low, open, prev_close FROM stocks")
rows = cursor.fetchall()
# 打印表格标题
print("序号\t股票代码\t股票名称\t最新报价\t涨跌幅\t涨跌额\t成交量\t成交额\t振幅\t最高\t最低\t今开\t昨收")
2.3 运行结果:

2.4 代码解析:
- 尝试连接到SQLite数据库
- 创建股票数据表
- 从API获取数据,插入数据到数据库。
4.查询并打印股票数据。
2.5 作业心得:
在爬取股票信息时,我发现使用API获取数据的效率高于直接爬取网页。通过调试工具的使用,我知道了如何监测网络请求并获取所需数据,这种技术在处理需要实时数据更新的应用中非常有用。
作业③:
- 要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
技巧:分析该网站的发包情况,分析获取数据的api - 输出信息:Gitee文件夹链接
![]()
3.1思路与步骤
-
选择目标网站:
- 访问上海交通大学排名网(https://www.shanghairanking.cn/rankings/bcur/2021)。
- 确定要爬取的字段,包括排名、大学名称、城市、类型和总分。
-
创建数据库连接:
- 使用sqlite3库连接到SQLite数据库,如果数据库文件不存在,则创建它。
-
请求网页:
- 使用requests库从给定的URL获取数据。
-
解析数据:
- 从响应文本中解析出参数名称和对应的中文含义。
-
保存数据到Excel:
- 将DataFrame中的数据保存为Excel文件。
-
完成与验证:
- 执行爬虫代码,检查数据库中的数据。
- 确保每个字段的数据正确且完整。
3.2作业代码与实现
import requests
import pandas as pd
import re
import sqlite3
from sqlite3 import Error
# 创建数据库连接
def create_connection(db_file):
"""创建数据库连接"""
conn = None
try:
conn = sqlite3.connect(db_file)
print(f"成功连接到数据库: {db_file}")
except Error as e:
print(f"数据库连接失败: {e}")
return conn
# 创建表格
def create_table(conn):
"""创建表格"""
try:
sql_create_table = """ CREATE TABLE IF NOT EXISTS university_rankings (
id INTEGER PRIMARY KEY AUTOINCREMENT,
ranking INTEGER NOT NULL,
name TEXT NOT NULL,
province TEXT NOT NULL,
category TEXT NOT NULL,
score REAL NOT NULL
); """
cursor = conn.cursor()
cursor.execute(sql_create_table)
print("表格创建成功")
except Error as e:
print(f"创建表格失败: {e}")
# 插入数据
def insert_data(conn, ranking, name, province, category, score):
"""插入数据"""
sql_insert = ''' INSERT INTO university_rankings(ranking, name, province, category, score)
VALUES(?,?,?,?,?) '''
cursor = conn.cursor()
cursor.execute(sql_insert, (ranking, name, province, category, score))
conn.commit()
# 设置 URL
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
# 发送 GET 请求
request = requests.get(url=url)
# 提取数据
name = re.findall(',univNameCn:"(.*?)",', request.text) # 获取学校名称
score = re.findall(',score:(.*?),', request.text) # 获取学校总分
category = re.findall(',univCategory:(.*?),', request.text) # 获取学校类型
province = re.findall(',province:(.*?),', request.text) # 获取学校所在省份
# 获取参数名称
code_name = re.findall('function(.*?){', request.text)
start_code = code_name[0].find('a')
end_code = code_name[0].find('pE')
code_name = code_name[0][start_code:end_code].split(',') # 将function中的参数取出并存在code_name列表中
# 获取参数对应的含义
value_name = re.findall('mutations:(.*?);', request.text)
start_value = value_name[0].find('(')
end_value = value_name[0].find(')')
value_name = value_name[0][start_value + 1:end_value].split(",") # 将参数所对应的含义取出存在value_name列表中
# 创建 DataFrame
df = pd.DataFrame(columns=["排名", "学校", "省份", "类型", "总分"])
# 填充 DataFrame 和插入数据库
for i in range(len(name)):
province_name = value_name[code_name.index(province[i])][1:-1]
category_name = value_name[code_name.index(category[i])][1:-1]
df.loc[i] = [i + 1, name[i], province_name, category_name, score[i]]
insert_data(conn, i + 1, name[i], province_name, category_name, score[i])
# 打印 DataFrame
print(df)
# 将数据保存到 Excel 文件
df.to_excel("3-ranking.xlsx", index=False)
3.3 运行结果:
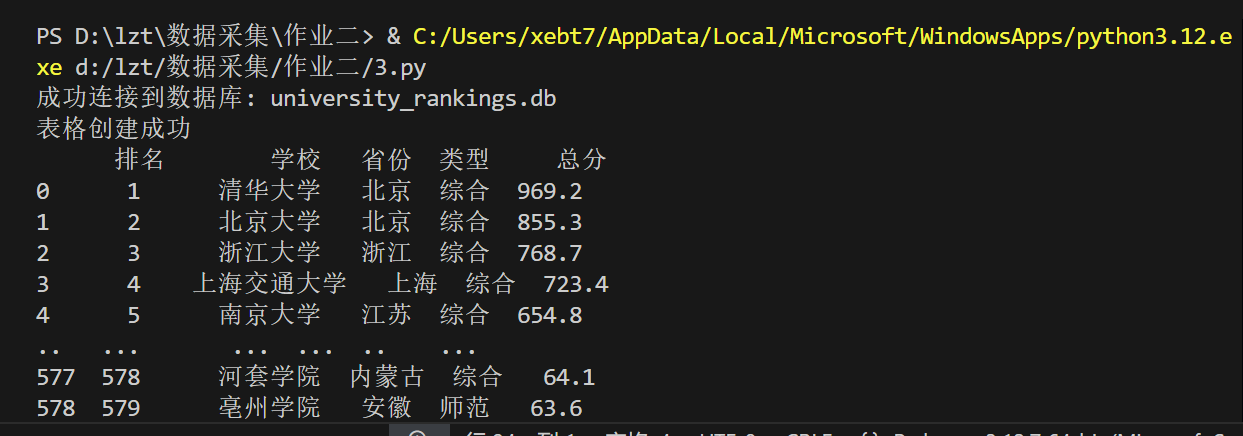
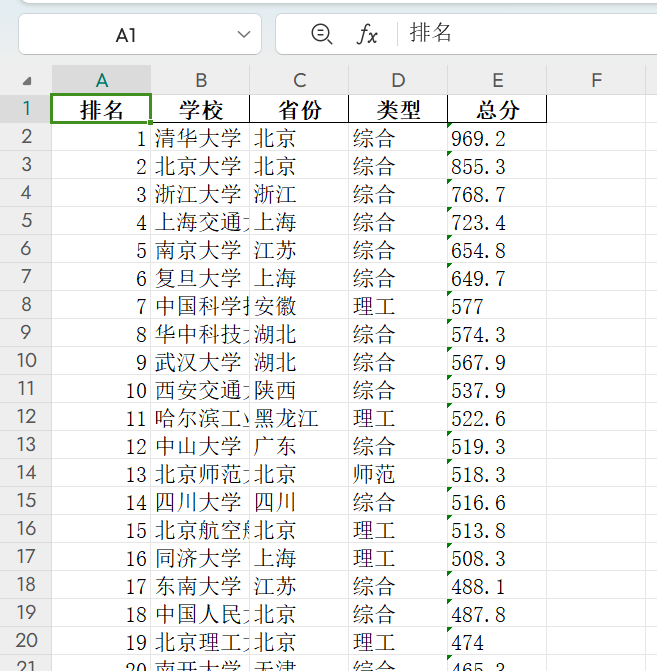
3.4 代码解析:
1.创建数据库连接,创建表格,插入数据。
2.设置 URL,发送 GET 请求,提取数据。
3.创建 DataFrame,创建数据库连接和表格,打印 DataFrame。
4.将数据保存到 Excel 文件,关闭数据库连接。
3.5 F12 调试分析的过程录制 Gif

3.6 作业心得:
爬取大学排名数据的过程让我更加深入地理解了使用requests库发送网络请求并获取数据,使用正则表达式提取所需信息。使用pandas库将数据保存为Excel文件,方便数据的进一步分析和共享。在开发过程中,我知道了如何调试和测试代码,确保每个部分都能正常工作。
总结与展望
通过这次作业,我深入了解了 如何使用requests库来发送HTTP请求并获取网络数据,如何利用正则表达式提取数据和数据导出到Excel等技术。我认识到了代码的模块化和异常处理在实际编程中的重要性,同时也锻炼了我的问题解决能力和调试技巧。这些作业为我未来在数据科学和软件开发领域的进一步学习和探索打下了坚实的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号