数据采集与融合技术作业1
作业1
我的getee仓库链接 https://gitee.com/LLLzt-III/crawl_project
作业1代码链接 https://gitee.com/LLLzt-III/crawl_project/tree/master/作业1
一、作业①:
- 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
- 输出信息:
![]()
1.1思路与步骤
-
确定目标网站和数据:
- 选择要爬取的网页(上海交通大学排名网:http://www.shanghairanking.cn/rankings/bcur/2020)。
- 明确要提取的数据,包括排名、学校名称、省市、学校类型和总分。
-
发送HTTP请求:
- 使用
requests库发送 GET 请求以获取网页内容。
- 使用
-
解析HTML内容:
- 使用
BeautifulSoup对返回的网页内容进行解析,创建一个soup对象。
- 使用
-
定位数据:
- 找到包含排名信息的
table标签,确定其结构。 - 使用
find()和find_all()方法定位表格的行(tr)和单元格(td)。
- 找到包含排名信息的
-
提取并输出数据:
- 遍历表格的每一行(跳过表头),提取所需信息并格式化输出。
-
测试与调试:
- 运行代码,检查输出结果是否符合预期,并进行调试和修改。
1.2作业代码与实现
import urllib.request
from bs4 import BeautifulSoup
# URL of the webpage
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
try:
# Open the URL
response = urllib.request.urlopen(url)
web_content = response.read()
# Parse the webpage content
soup = BeautifulSoup(web_content, 'html.parser')
# Find the table containing the ranking data
table = soup.find('table')
if table:
# Extract table rows
rows = table.find_all('tr')
# Iterate over rows and extract data
for row in rows[1:]: # Skip the header row
cells = row.find_all('td')
if len(cells) > 1: # Ensure the row contains data
ranking = cells[0].get_text(strip=True)
school_name = cells[1].get_text(strip=True)
province_city = cells[2].get_text(strip=True)
school_type = cells[3].get_text(strip=True)
total_score = cells[4].get_text(strip=True)
# Print the extracted information
print(f"{ranking}\t{school_name}\t{province_city}\t{school_type}\t{total_score}")
else:
print("没有找到包含排名数据的表格。")
except Exception as e:
print(f"解析网页时出错:{e}")
print("请检查网页链接的合法性,并确保网络连接正常。")
1.3运行结果:
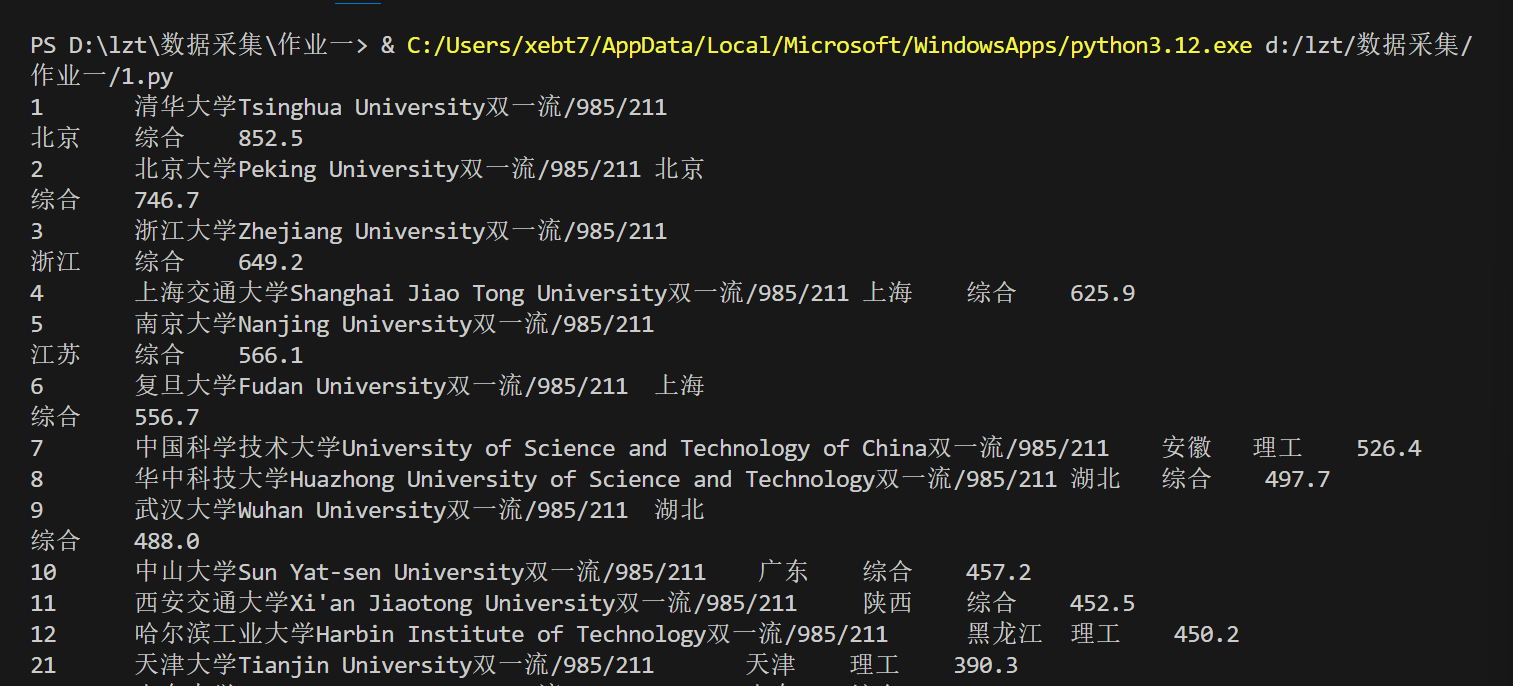
1.4代码解析:
- 请求网页:使用urllib进行网页请求。
- BeautifulSoup解析:使用
BeautifulSoup对页面内容进行解析,并定位到包含排名信息的table标签。 - 输出结果:遍历数据行,确保提取的信息有效并格式化输出。
1.5作业心得:
在进行此作业时,我学会了如何使用 requests 获取网页内容,并利用 BeautifulSoup 来解析 HTML 结构。爬取到的大学排名数据格式很清晰,便于进一步处理与分析。遇到的挑战是网页结构的理解,特别是如何准确定位包含目标数据的 HTML 标签。通过调试,我熟悉了 BeautifulSoup 的常用方法,如 find_all() 和 text 等。
二、作业②:
- 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
- 输出信息:
![]()

2.1思路与步骤
-
确定目标网站和数据:
- 选择一个商城网站(如淘宝)并确定搜索的关键词(如“书包”)。
- 明确要提取的数据,如商品名称和价格。
-
发送HTTP请求:
- 使用
requests发送 GET 请求获取搜索结果页的 HTML 内容。
- 使用
-
解析HTML内容:
- 通过正则表达式或
BeautifulSoup解析网页内容。
- 通过正则表达式或
-
解析数据:
- 用re库的正则表达式提取商品名称和价格。
-
输出结果:
- 将提取到的商品信息格式化输出,包括序号、商品名和价格。
-
测试与调试:
- 运行代码,检查提取的数据是否正确,并且调整正则表达式或解析方式。
2.2作业代码
import re
import urllib.parse
import urllib.request
import chardet
# 获取爬取网页的HTML文件
def getHTMLText(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}
try:
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
raw_data = response.read()
encoding = chardet.detect(raw_data)['encoding']
data = raw_data.decode(encoding)
return data
except Exception as err:
print(f"请求错误:{err}")
return ""
# 将html文件中的商品名称和价格用正则表达式提取
def parsePage(info, data):
print("解析数据中...")
# 提取价格
prices = re.findall(r'¥([\d,]+\.\d{2})', data)
# 提取商品名称
names = re.findall(r'alt=\'(.*?)\'', data)
for i in range(min(len(names), len(prices))):
price = prices[i].strip()
name = names[i].strip()
info.append([i + 1, price, name])
return info
# 格式化打印商品相关信息
def printGoodslist(info):
print("序号\t价格\t商品名称")
for i in info:
print(f"{i[0]}\t{i[1]}\t{i[2]}") # 直接输出序号、价格和商品名称
# 主函数:爬取网页,并格式化输出结果
def main():
goods = urllib.parse.quote("书包") # 设置搜索内容为"书包"
page = 1 # 可以设定默认获取第一页
print("正在爬取...")
url = f'https://search.dangdang.com/?key={goods}&act=input&page_index={page}'
info = []
data = getHTMLText(url)
if data:
print("HTML文本获取成功!")
parsePage(info, data)
printGoodslist(info)
else:
print("HTML文本获取失败。")
if __name__ == "__main__":
main()
2.3运行结果:
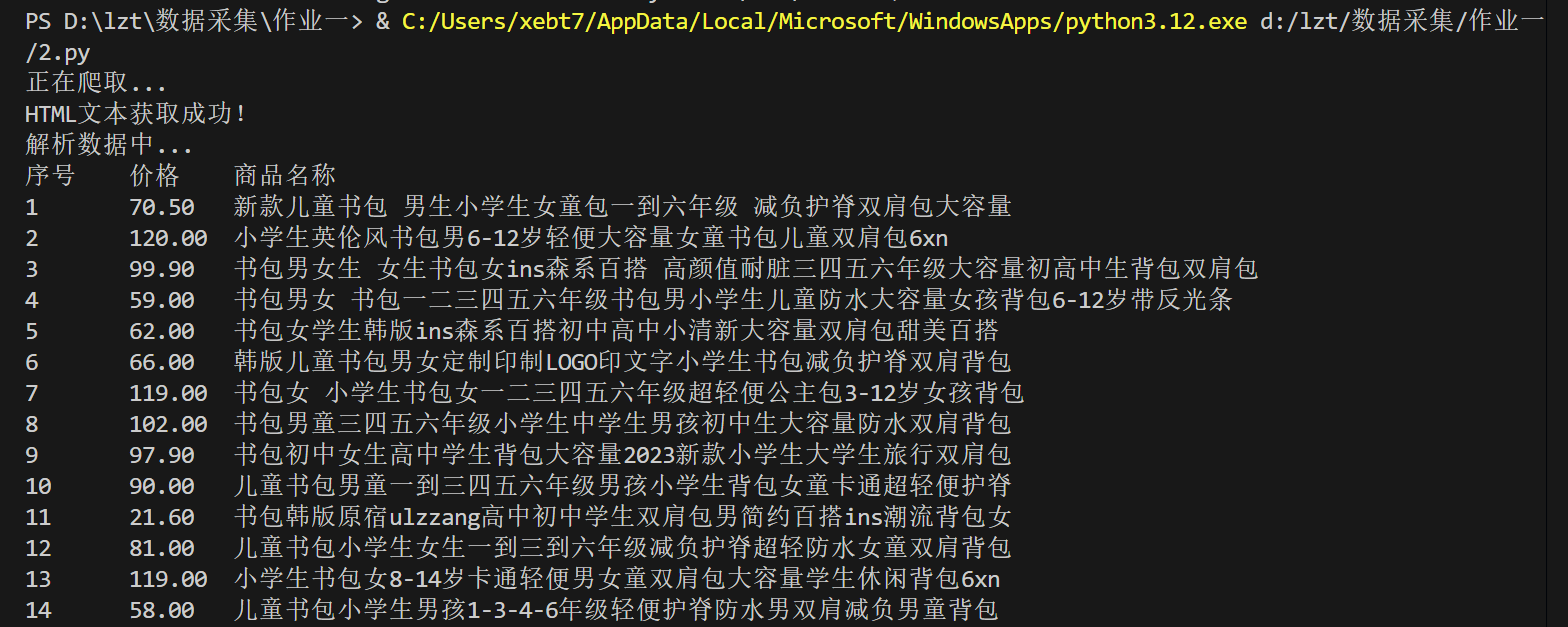
2.4代码解析:
- 获取HTML:使用urllib库发送HTTP请求,获取网页内容。
- 正则提取数据:通过正则表达式
re.findall()从网页内容中提取商品名称和价格。 - 输出结果:遍历提取的商品信息并打印。
2.5作业心得:
通过这个题目,我知道了正则表达式在爬虫中的重要性。正则可以高效地从复杂的 HTML 中提取出我们需要的数据。淘宝的网页数据是通过 JSON 格式加载的,而正则表达式使得解析变得更加简单。
三、作业③:
- 要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
- 输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
3.1思路与步骤
-
发送HTTP请求:
- 使用
requests发送 GET 请求获取网页的 HTML 内容。
- 使用
-
解析HTML内容:
- 使用
BeautifulSoup解析网页,并定位所有的<img>标签。
- 使用
-
筛选图片链接:
- 遍历所有
<img>标签,检查其src属性,筛选出以.jpg或.jpeg结尾的图片链接。
- 遍历所有
-
下载图片:
- 创建一个文件夹(如
images)以存储下载的图片。 - 使用
requests.get()下载每个符合条件的图片,并将其保存到本地。
- 创建一个文件夹(如
-
输出结果:
- 在下载过程中打印出每个成功下载的图片文件名,确认下载的成功。
-
测试与调试:
- 运行代码,检查是否成功下载所有符合条件的图片,并进行调试。
3.2作业代码与实现
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 目标网页URL
url = 'https://news.fzu.edu.cn/yxfd.htm'
# 发送HTTP请求
response = requests.get(url)
response.encoding = 'utf-8'
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 创建一个文件夹来保存图片
folder_name = '3-images'
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# 找到所有图片标签
img_tags = soup.find_all('img')
# 遍历图片标签并下载图片
for img in img_tags:
img_url = img.get('src')
if img_url:
# 确保图片格式为JPEG或JPG
if img_url.lower().endswith(('.jpg', '.jpeg')):
# 将相对路径转换为完整URL
img_url = urljoin(url, img_url)
try:
img_data = requests.get(img_url).content
img_name = os.path.join(folder_name, img_url.split('/')[-1])
with open(img_name, 'wb') as handler:
handler.write(img_data)
print(f"图片已下载:{img_name}")
except Exception as e:
print(f"下载图片失败:{img_url},错误:{e}")
3.3运行结果:

3.4代码解析:
- 请求网页:首先通过
requests.get()获取目标网页内容。 - 解析HTML:使用
BeautifulSoup解析网页,并查找所有的<img>标签。 - 筛选图片格式:检查图片 URL 是否以
.jpg或.jpeg结尾。 - 下载图片:将符合条件的图片下载并保存在本地文件夹
images中。
3.5作业心得:
这个题目让我学到了如何从网页中提取图片资源并将其保存到本地。使用 BeautifulSoup 提取 <img> 标签非常方便,而文件下载和存储则通过 requests 实现。最大的问题是图片的 URL 可能是相对路径,所以需要根据网页的基础 URL 补全图片的完整路径。
总结
通过本次作业,我深入了解了 Python 爬虫的基本使用方法,包括如何使用 requests 发送请求,如何通过 BeautifulSoup 解析 HTML,如何利用正则表达式提取数据等技术。爬虫的应用场景非常广泛,可以用来获取各类数据并加以分析。总之,这些作业不仅提高了我的编程能力,也增强了我解决实际问题的信心,为未来的学习奠定了良好的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号