
wordcount(C语言)
写在前面
上传的作业代码与测试代码放在GitHub上了 https://github.com/IHHHH/gitforwork
本次作业用的是C语言来完成,因为个人能力与时间关系,只完成了基本功能,扩展功能和高级功能很遗憾没有完成。
基本功能
wc.exe -c file.c //返回文件 file.c 的字符数
wc.exe -w file.c //返回文件 file.c 的单词总数
wc.exe -l file.c //返回文件 file.c 的总行数
wc.exe -o outputFile.txt //将结果输出到指定文件outputFile.txt
PSP表格
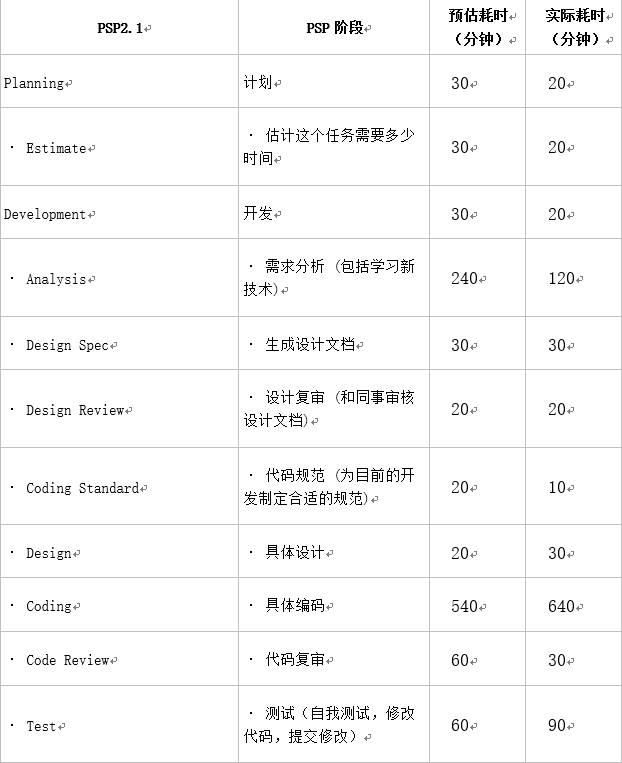
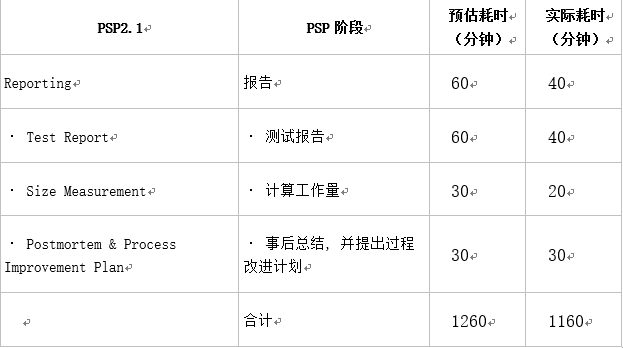
- 关于预估耗时比实际耗时多的原因,并不是因为能力比预估的高,而是一下几点原因:
- 预估耗时是以完成除高级功能外所有功能,包括基本功能和扩展功能,而实际任务中,并没有实现扩展功能,仅仅完成了基本功能
- 完成较少的功能代表着需要较少的时间来学习新的函数和语法
- 报告因为ddl的原因写得比较匆忙,所用时间较少
- 预估耗时是六个该项作业的估计时间,实际上有很多其他事情要处理,并没有留下这么多时间,也就是说其他的事情通过尽量压缩来尽量满足预留时间。
设计思路
- 实现将数据写入指定文件,读取指定文件的数据并输出
- 实现读取指定文件的行数,字符数,单词数并直接输出
- 从用户输入的字符串中提取相应的处理字,文件名并直接输出
- 将提取到的关键字与之前实现的功能进行对接
- 测试程序的一般情况与临界情况
程序分析
char* t; //result
char* wr; //output
char a[50]; //记录输入数据
char b[50]; //记录读取的文件地址
char WC[1000]; //保存打开的文件内容
int col_count(const char* t); //统计字符数
int col_row(const char* t); //统计行数
int col_word(const char* t); //统计单词数
void result(const char* t, const char* a, int num); //产生结果文件
void output(const char* t, const char* w, int count, int row, int word);//产生输出文件
通过两个指针记录可能出现的两个文件地址字符串的首地址,为了简便,b数组中相应数据的位置与a相同,通过指针进行读取。
for (int i = 0; a[i] != NULL; i++)
{
if(a[i] == '-')
if (a[i+1] == 'o')
for (int j = i+1; a[j] != NULL; j++)
{
if (a[j] == ' ')
if (a[j + 1] != ' '&&a[j + 1] != '-') //输出文件入口判断
{
wr = a + j + 1;
break;
}
}
}
通过对输入信息的判断来提取代表文件地址的字符串
for (int i = 1; a[i] != NULL; i++)
{
if (a[i - 1] == ' ')
if (a[i] != ' '&&a[i] != '-') //目标文件名入口判断
{
int j = i;
while (a[i] != ' '&&a[i] != NULL) //目标文件名出口判断
{
b[i] = a[i];
i++;
}
t = b + j;
break;
}
}
默认读取的文件在需要写入的文件前,因此读取的文件判断相对复杂,需要对入口和出口同时进行判断
if(a[i] == '-')
{
if (a[i + 1] == 'c')
{
count = col_count(t);
printf_s("字符数:%d", count);
result(t, "字符数", count);
printf_s("\n");
}
if (a[i + 1] == 'l')
{
row = col_row(t);
printf_s("行数:%d", row);
result(t, "行数", row);
printf_s("\n");
}
if (a[i + 1] == 'w')
{
word = col_word(t);
printf_s("单词数:%d", word);
result(t, "单词数", word);
printf_s("\n");
}
if (a[i + 1] == 'o')
{
output(t, wr, count, row, word);
printf_s("\n");
}
}
通过“-”后面的不同情况应用不同的函数
int col_count(const char* t)
{
char data;
FILE *fp;
errno_t err;
int count = 0;
err = fopen_s(&fp, t, "r");
if (err != 0)
{
printf("can't open file\n");
count = -1;
}
while ((data = getc(fp)) != EOF)
{
WC[count] = data;
count++;
}
fclose(fp);
return count;
}
int col_row(const char* t)
{
char data;
FILE *fp;
errno_t err;
int row = 0;
err = fopen_s(&fp, t, "r");
if (err != 0)
{
printf("can't open file\n");
row = -1;
}
while ((data = getc(fp)) != EOF)
if (data == '\n')
row++;
fclose(fp);
return row;
}
int col_word(const char* t)
{
char data;
FILE *fp;
errno_t err;
int word = 0;
int i = 0;
err = fopen_s(&fp, t, "r");
if (err != 0)
{
printf("can't open file\n");
word = -1;
}
while ((data = getc(fp)) != EOF)
{
WC[i] = data;
i++;
}
if (WC[0] != ' ' && WC[0] != ',' && WC[0] != '\n')
word++;
for (i = 0; WC[i] != NULL; i++)
{
if (WC[i] == ' ' || WC[i] == ',' || WC[i] == '\n')
if (WC[i + 1] != ' ' && WC[i + 1] != ',' && WC[i + 1] != '\n')
word++;
}
fclose(fp);
return word;
}
以上三个函数为需要实现功能函数,均用getc()函数对文件按照一个字符一个字符的方式读取,不同的是自变量的递增条件
判断字符数时,每读取一个就加1,初值为0
判断行数时,每读取一个换行符加1,初值为1
判断单词数时,进行单词的开头与结尾判断,每对应一次加一,但根据判断条件不同,有时要加上开头或者结尾的一个单词
void result(const char* t, const char* a, int num)
{
FILE *wt;
errno_t err;
err = fopen_s(&wt, "result.txt", "a+");
if (err != 0)
{
printf("can't write file\n");
}
fprintf(wt, "%s,%s:%d\n", t, a, num);
fclose(wt);
}
void output(const char* t, const char* w, int count, int row, int word)
{
FILE *wt;
errno_t err;
err = fopen_s(&wt, w, "a+");
if (err != 0)
{
printf("can't write file\n");
}
fprintf(wt, "%s,字符数:%d,行数:%d,单词数:%d", t, count, row, word);
fclose(wt);
}
写文件函数,a+表示不擦除之前所写的内容,且去掉之前的停止符EOF
测试
测试思路
测试要覆盖可能出现的左右情况,尽量找到代码中可能蕴含的错误并改正,因此,测试设计应该覆盖判断中的各种边界情况,,满足基本功能的所有需求,-c –w –l -o
用于测试的输入
-c test.txt
-w test.txt
-l test.txt
-c –w test.txt
-c –l test.txt
-w –l test.txt
-c –w –l test.txt
-c test.txt –o output.txt
-w test.txt –o output.txt
-l test.txt –o output.txt
-c –w test.txt –o output.txt
-c –l test.txt –o output.txt
-w –l test.txt –o output.txt
-c –w –l test.txt –o output.txt
没有写测试脚本,但测试均可通过,表示基本功能没有问题
不足
除了扩展功能和高级功能没有完成外,有以下几个不足
- 生成的result.txt和outut.txt由于没有在程序内部进行清空,会导致在多次运行后,文件内部信息比较杂乱
- 默认先-c-w-l读取文件,再-o保存数据,因此无法在二者翻转时进行正确执行,但由于需求内没有标明,没有考虑该种情况,希望老师验收时注意
- 有多个功能聚集在主函数内部,比较杂乱,没有比较好的代码优化。
收获
本次作业除了加强编程能力外,让我们对时间安排有了更充分的理解,理解了上课所学习的基本内容,初步理解的测试的相关方法,希望能在今后的学习中对软件测试有更加深刻的理解和学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号