
[阅读笔记] Application Defined On-chip Networks for Heterogeneous Chiplets: An Implementation Perspective
近日读了一篇和自己工作内容非常契合的paper, 作者是华为海思的工程师们,通讯作者是夏晶,文章主要是介绍chiplet现状以及提出的一种无buffer的环形总线NOC的结构,由于本人常年从事总线设计工作,读起来非常得心应手,在此写一些总结和感想。
首先介绍一下这篇paper的主要内容:
核心思想: 提出一种bufferless multi-ring NoC
针对场景: 异构的chiplet-based SoC. 包括但不限于Server-CPU, AI-Processor, Baseband-Processor, IO Die等
动机: 最近chiplet非常火,前一阵Intel还推出了UCIe的统一标准(chiplet为什么这么火的原因在这里就不详细讲了,比如因为摩尔定律不再严格使用,比如因为多工艺降低成本,比如xxx,分析这类原因的文章非常多,包括之前我们组和清华大学交叉学院的马恺声老师也一起探讨过,他写过一篇公众号文章,介绍的还是非常详细的,有兴趣可以参考阅读.), 而chiplet的互联NoC是一个关键的技术点,同时针对不同的SOC,NoC所需要满足的要求侧重点也有所不同,为了满足这些需求,所以提出了这种NoC架构.
NoC设计需要做的trade-off决策: Application, architecture, physical design.
NoC设计的主要指标:
1. Network Latency: 像Server-CPU, 对访存的延迟非常敏感,这里的NoC主要需要保证latency的减少
2. Network Bandwidth: 像AI-Processor, 海量的数据处理,主要看NoC的带宽
3. Network Area Efficiency: 这里主要是从后端的角度,SoC越来越复杂,想达到timing closure, 对面积的要求非常高
后面文章花了一个大章节主要讲NoC co-design(软件应用角度,设计角度,后端角度)方法论的来源,比如从market的需求,比如从计算的特性等,反正NoC很关键,需要提升上面的关键指标.
NoC方案用的协议: CHI协议,这里有一点让我意外的是,Server-CPU用CHI协议是天然成立的,ARM也一直在推CMN一致性总线IP,但是AI-processor, 这篇文章说也用了CHI协议,同时有cache相关的行为。而我的理解是,各个AI core很少有共享同一份数据的使用场景,多是串行化的,也就是第一个core处理后的数据给第二个core使用,一般也不需要保持core间的一致性,所以,这里为什么用CHI协议,我是比较好奇的
然后文章提出了bufferless multi-ring NoC:
Application: 提供15TB/s以上的带宽,低延迟
Architecture: Flexible
Physical Implementation: 简化,提高distance per cycle
这个方案的最大特点: No buffer. 这里主要说的是NoC本身采用无buffer的设计方式,好处是降低电路复杂度和能耗. 我的理解是他只是尽量减少了XP(Crosspoint)上所使用的buffer,事实上后面也有提到在不同的node上根据不同的原因也会有buffer的存在,尤其是要解决deadlock问题时,更增加了buffer的使用,所以对bufferless,我们只了解他的设计思想就可以.
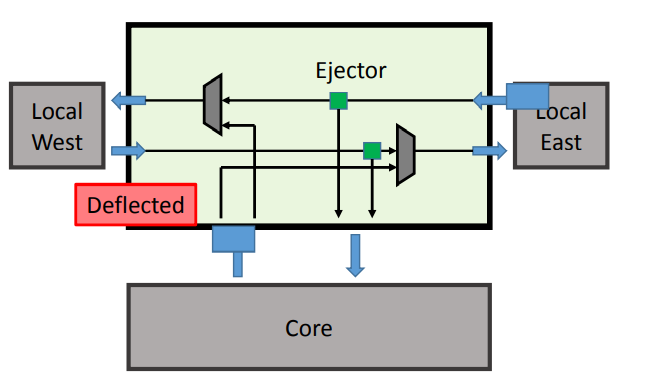
Deflection routing: 这个词文章没有做过多的解释,我研究了一下Onur Mutlu教授2014年的一个PPT,"Design and Evaluation of Hierarchical Rings with Deflection Routing", 从PPT上看,和海思的这篇文章思想几乎完全一样(这不算抄袭么,好奇),也是把所有的local router的buffer移除,并去掉bridge router绝大多数的buffer. Routing方式就是有flit就给他做路由偏转,如下图
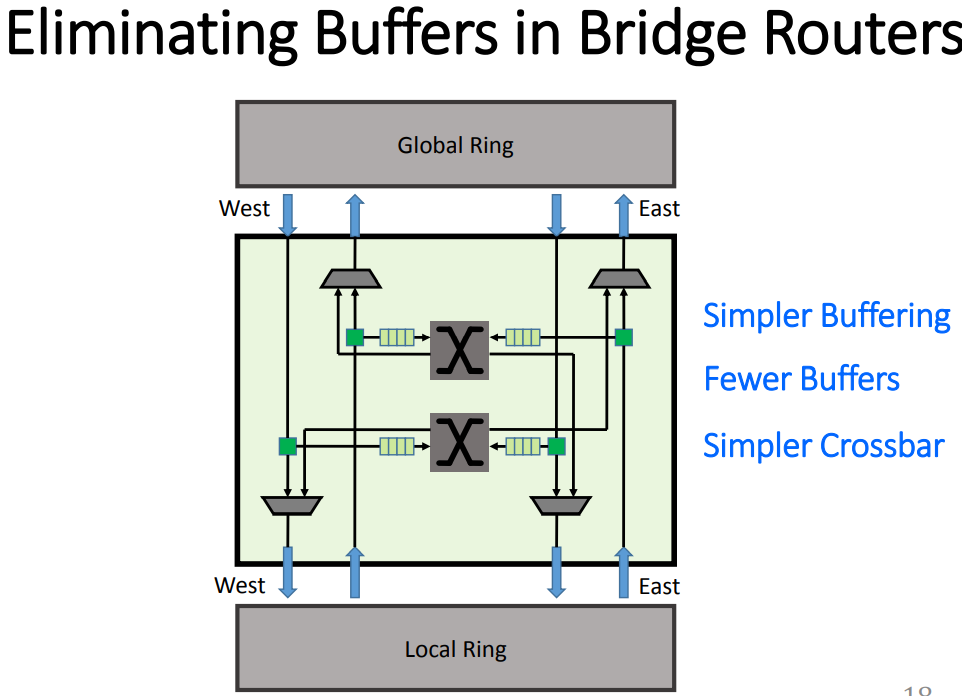
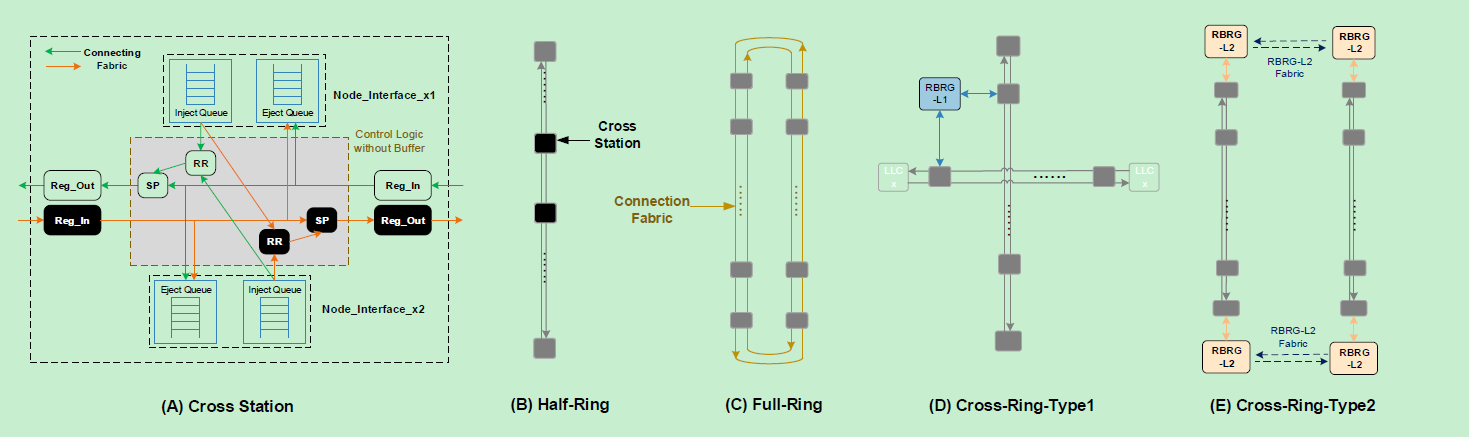
然后文章主要介绍了这种NoC的实现方法,左边这个图和上面PPT的内容就非常类似了,讲的是一个router对flit的处理方式,后面是环形总线的大致结构,D和E的区别是片内总线还是片间总线
然后介绍了server和AI SoC的架构,基本上从下面两张图就可以看出实现的思想和结构
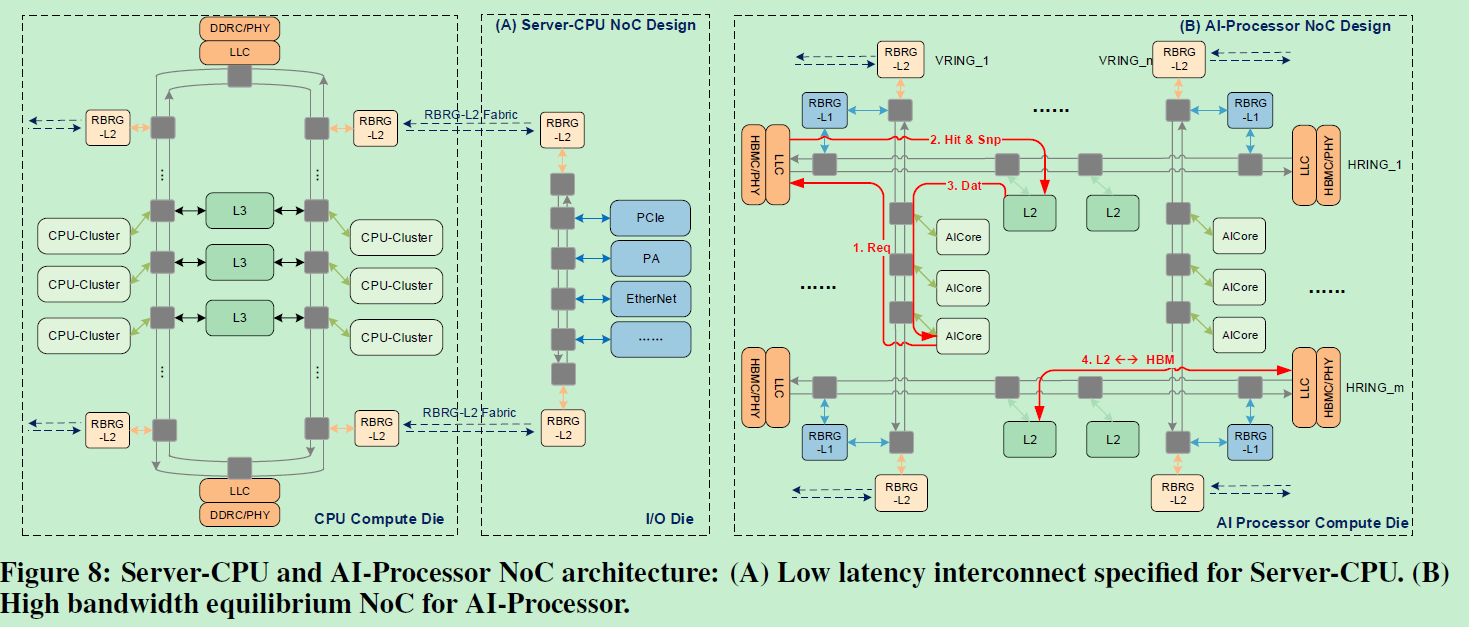
事实上,这个架构我整体看下来,觉得新颖的地方其实并不多,主要是bufferless的这个理念,其他的环形总线嵌套早在多年前就有实现,而且里面的具体实现在华芯通的第一颗芯片上就非常详细,几乎是一样的架构,而且paper里所述deadlock-free的场景和解决办法也非常熟悉,这个死锁相关信息概述如下:
Ringbus上面的传输是用Token/Credit作为信令的,也就是paper说的I-tag和E-tag,当多个ringbus有汇聚点的时候,产生跨ring的行为,就有可能造成死锁的场景. 当每个flit都想传输到另一个ring的时候,而两个ringbus都没有资源供使用,就会死锁。
常见的解决办法是virtual channel.也就是用一个额外的slot reservation来解决掉某一个transaction. 文章认为这种解决方法会增加latency, 所以采用了"SWAP"机制
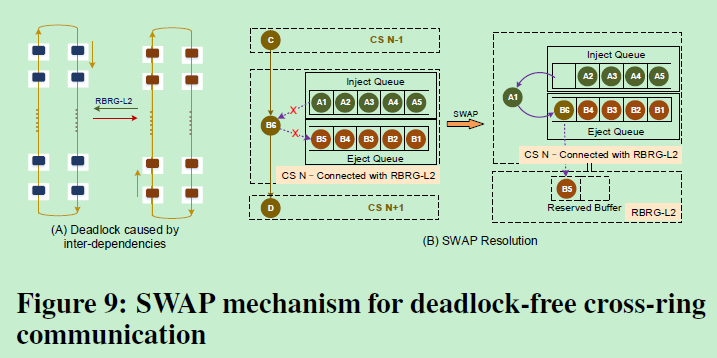
Deadlock detection and deadlock resolution:
什么情况认为发生了deadlock呢?当系统发现某个Cross point上,有连续fail掉的inject flits,且超过了一个阈值cycle数,就认为Eject Queue和可以使用的Tx buffer被全部占用,Inject Queue就无法发送新的传输.
此时跨ring的bridge进入到死锁恢复模式(Deadlock resolution mode), 此模式会把预留的Tx buffer给死锁的flit使用, Eject Queue的一个Flit被push到预留buffer里,从而空出来一个位置用于cross-ring flit.这种和Virtual channel的本质区别是什么呢,其实我没太懂。。。
后面paper介绍了各种实验数据,大概表示我这种NoC比别人的好blablabla, 不在此详述了.
说一点自己的想法,最近我也开始了解Chiplet相关的信息,文章里讲的更多是协议层上的实现,而chiplet的实现需要的是协议层和物理层的协同工作,是用Serdes还是用并行总线(类似intel AIB, 或者Apple M1 Ultra),还有工艺的问题等等。海思确实厉害,我相信他们已经可以把这套NoC在chiplet互联的协议层实现了,只是我更感兴趣的是整体的一个结构,一起针对chiplet所做的一些优化。ARM_Based主流的chiplet实现还是用CMN转CXS协议,通过CCIX或CXL连接到Compute die或者Accelerator die上面. 另外,片内的NoC主流已经是mesh架构了,这里讲的仍然是ringbus, 估计海思更核心的mesh不想往外说吧。
另外从一位朋友那儿了解的,这篇paper主要突出实现,而非创新性,工程量确实是很大的.
