数据文件合并与拆分
在数据处理业务中,经常要把文件结构相同或近似相同的数据文件合并成一个文件,或者将一个比较大的数据文件拆分成小的数据文件。本文将介绍文本文件和 Excel 文件合并及拆分会遇到的几种情况,并提供用 esProc SPL 编写的代码示例。esProc 是专业的数据计算引擎,SPL 中有完善的文件导入、导出及目录操作函数,非常适合做数据文件的合并及拆分工作。
一、 文件合并
1. 同构文本文件合并
在某个文件目录下有多个文本文件,这些文件表头和列结构完全相同,只是数据行数和数据内容不同,需要将这些文件的数据全部合并到一个文本文件中,共用同一个表头。
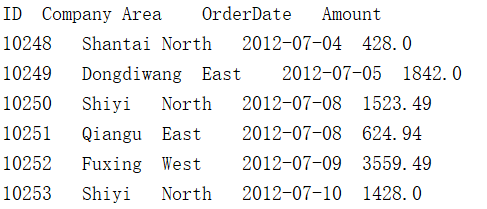
示例:在e:/orders目录下有每日的订单文本文件,每个文件的结构相同,第一行是列名,第二行开始是数据,如下图所示,请将它们合并成一个订单表文件orders.txt。
esProc SPL脚本如下:
| A | 注释 | |
| 1 | =directory@p("e:/orders/*.txt") | 返回orders目录所有txt文件的完整路径名 |
| 2 | =A1.conj(file(~).import@t()) | 合并所有文件的数据 |
| 3 | =file("e:/orders.txt").export@t(A2) | 将合并后的数据写入orders.txt文件 |
如果e:/orders还有子目录,子目录中的txt文件也需要一起合并,那么把A1格改成=directory@ps("e:/orders/*.txt"),选项@s表示递归查找所有子目录下的文件。
上面这段脚本是假设内存能够装下合并以后的全部数据,如果装不下,那么应该用下面这段脚本:
| A | B | C | |
| 1 | =directory@p("e:/orders/*.txt") | =file("e:/orders.txt") | |
| 2 | for A1 | =file(A2).cursor@t() | |
| 3 | if #A2==1 | =B1.export@t(B2) | |
| 4 | else | =B1.export@a(B2) |
A1 列出目录中的所有txt文件的完整路径名称,如果要查找子目录,则加上@s选项
A2 对列出的文件进行循环
B2 用游标读取每一个文件,@t表示第一行是列名
B3-C4 将B2游标中数据导出,第一次要导出列名,其后用@a进行追加
2. 结构近似的文本文件合并
如果文件结构并不是完全相同,比如列的顺序不一样、列数不一样,但各文件都含有共同的几列,想要把这些共同列的数据都合并到一个文件中。合并这些文件时,需要按指定顺序读出每个文件中的这些共同列数据。
示例:还是上面这个例子,已知所有订单文件都有ID、Company、Area、OrderDate、Amount这5列,但各文件中列的顺序并不相同,有的文件还有其它一些列,请将各文件中的这5列数据合并到orders.txt文件中。
esProc SPL脚本如下:
| A | 注释 | |
| 1 | =directory@p("e:/orders/*.txt") | 返回orders目录所有txt文件的完整路径名 |
| 2 | =A1.conj(file(~).import@t(ID,Company,Area,OrderDate,Amount)) | 按指定的5列顺序读出各文件数据,然后合并所有文件的数据 |
| 3 | =file("e:/orders.txt").export@t(A2) | 将合并后的数据写入orders.txt文件 |
同样地,如果内存装不下合并后的所有数据,则使用下面这段脚本:
| A | B | C | |
| 1 | =directory@p("e:/orders/*.txt") | =file("e:/orders.txt") | |
| 2 | for A1 | =file(A2).cursor@t(ID,Company,Area,OrderDate,Amount) | |
| 3 | if #A2==1 | =B1.export@t(B2) | |
| 4 | else | =B1.export@a(B2) |
3. 文件名转成列数据
在合并数据的同时,需要为合并后的数据增加一列,并用合并前的文件名给此列赋值,以便标记数据类别或来源。
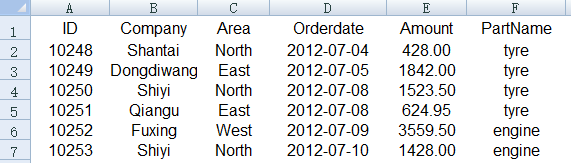
示例:在e:/orders目录下有各种零件的订单Excel文件,文件名就是零件的名字,比如tyre.xlsx、engine.xlsx……等,每个文件的结构相同,第一行是列名,第二行开始是数据,如下图所示,请将它们合并成一个订单表文件orders.xlsx,并增加一列PartName用来记录零件的名字。
esProc SPL脚本如下:
| A | 注释 | |
| 1 | =directory@p("e:/orders/*.xlsx") | 返回orders目录所有Excel文件的完整路径名 |
| 2 | =A1.conj((fn=filename@n(~),file(~).xlsimport@t().derive(fn:PartName))) | 先将文件名定义为临时变量fn,读入文件后,增加一列PartName,并用fn赋值。最后将各文件数据合并 |
| 3 | =file("e:/orders.xlsx").xlsexport@t(A2) | 将合并后的数据写入orders.xlsx文件 |
同样地,如果内存装不下合并后的所有数据,则使用下面这段脚本:
| A | B | C | |
| 1 | =directory@p("e:/orders/*.xlsx") | =file("e:/orders.xlsx") | |
| 2 | for A1 | =file(A2).xlsimport@tc().derive(filename@n(A2):PartName) | |
| 3 | if #A2==1 | =B1.xlsexport@ts(B2) | |
| 4 | else | =B1.xlsexport@as(B2) |
合并后的orders.xlsx文件部分数据如下图所示:
二、 文件拆分
1. 分组拆分
对文件中数据进行分组,把每组数据单独存为一个文件,用组名为文件命名。
示例:在订单表Excel文件中有各种零件的订单,请把同种零件的订单各存为一个Excel文件,以便发送给零件生产部门。
esProc SPL脚本如下:
| A | B | |
| 1 | =file(“e:/orders/orders.xlsx”).xlsimport@t() | =A1.group(partName) |
| 2 | for B1 | =file("e:/parts/"+A2(1).partName+”.xlsx”).xlsexport@t(A2) |
A1 读入所有原始数据
B1 按partName分组
A2 循环每个零件组的订单信息
B2 以零件名称作为文件名,导出零件信息
如果原文件很大,不能全部装入内存,那么应该使用游标方式读数,脚本如下:
| A | B | C | D | |
| 1 | =file(“e:/orders/orders.xlsx”).xlsimport@tc() | |||
| 2 | for A1,50000 | =A2.group(partName) | ||
| 3 | for B2 | =file("e:/parts/"+B3(1).partName+”.xlsx”) | ||
| 4 | if C3.exists() | =C3.xlsexport@a(B3) | ||
| 5 | else | =C3.xlsexport@t(B3) | ||
A1 创建游标读取原始数据
A2 循环游标读数,每次读50000行(读多少行根据内存大小决定)
B2 对每次读取的数据按partName分组
B3 循环每组零件
C3 以零件名称作为文件名创建文件对象
C4-D5 如果文件已存在,则用@a追加写入零件订单信息,不存在则用@t先写入列名再导入数据
2. 记录占据多行的拆分
在文本文件中,一条数据记录是由多行数据组成的,在拆分成小文件时,要识别哪几行是同一条数据记录,保证同一条数据记录不会被拆分到两个文件中。
示例1:有网站运行日志文件log.txt,每条日志由5行组成,现在需要把这个日志文件拆分成一些小文件,每个文件由1000条日志组成。
esProc SPL脚本如下:
| A | B | |
| 1 | =file(“e:/log.txt”:”UTF-8”).cursor@s() | |
| 2 | for A1,5000 | =file(“e:/log/log_”/#A2/”.txt”).export(A2) |
A1 用游标读取日志文件数据,@s表示将整行读成一个字符串
A2 循环游标,每次取5000行,刚好是1000条日志
B2 按循环序号生成日志文件名,如log_1.txt、log_2.txt……,然后将当前取出的所有行写入
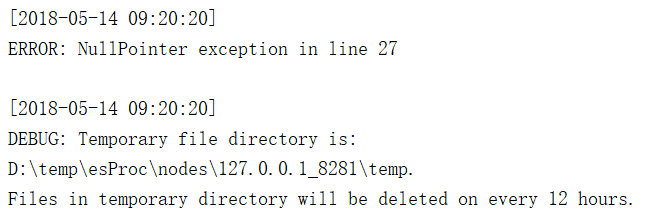
示例2:有程序运行日志文件log.txt如下图所示,每条日志由不确定的几行组成,每条日志由中括号开头,其后只要不是中括号开头的行,都与它属于同一条日志。现在需要把这个日志文件拆分成一些小文件,每个文件由1000条日志组成。
esProc SPL脚本如下:
| A | B | |
| 1 | =file(“e:/log.txt”:”UTF-8”).read@n() | =A1.select(~!="") |
| 2 | =B1.group@i(pos(~,"[")==1).cursor() | |
| 3 | for A2,1000 | =file(“e:/log/log_”/#A3/”.txt”) |
| 4 | =A3.(~.(B3.write@a(~))) |
A1 打开日志文件读取数据,@n表示将每一行读成一个字符串,所有串组成一个序列返回
B1 筛选出非空的行
A2 按行是否用中括号开头作为分组条件,中括号开头的作为一个新组,不是则并到当前组。最后把所有组序列转换成游标
A3 循环游标,每次取1000个组,即1000条日志
B3 按循环序号生成日志文件名,如log_1.txt、log_2.txt……
B4 两层循环,外层是循环1000个组,内层循环每组的成员(即数据行),将每行追加写入文件
posted on 2020-11-20 11:37 IBelieve002 阅读(183) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号