多层次报表的性能优化方案
多层次报表是常见的报表形式,典型的如分组报表和主子报表。其中的关联运算(组与明细、主表和子表)由于有层次而不能直接在数据库中完成,需要在报表端完成。而报表端一般只能采用排序和遍历的方法实现关联,性能又比较差。
本文介绍的润乾报表可以利用层次数据集(需要结合集算器实现)在数据源计算过程中完成关联计算,并且将有层次的结果集直接传送给报表进行呈现,从而做到在关联计算中充分利用集算器的高效算法,达到优化性能的目标。
下面通过一个主子报表的实例看一下使用过程与效果。
报表描述
使用订单表和订单明细表,查询每个订单详情以及该订单下的订单明细,报表格式如下:
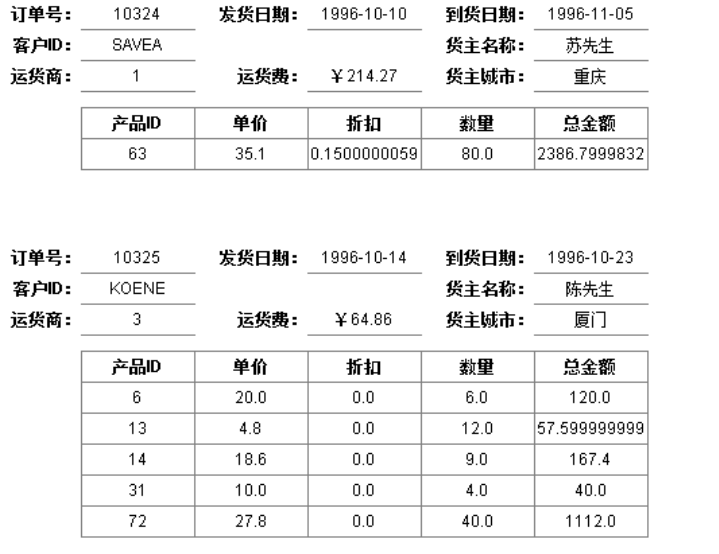
环境及数据描述
测试机型:Dell Inspiron 3420
CPU:Intel Core i5-3210M @2.50GHz *4
RAM:4G
HDD:西数 WDC(500G 5400 转 / 分)
操作系统:Win7(X64) SP1
JDK:1.6
数据库:hsqldb
润乾报表版本:2018
表数据
| 表名 | 字段数 | 数据量 | |
|---|---|---|---|
| 订单表 | 15 | 854 | |
| 订单明细表 | 5 | 434315 |
实现步骤
编写计算脚本
首先使用集算器(专门用于数据计算,为报表提供数据源支持的工具)编写计算脚本(orders.dfx),完成数据计算并返回层次数据集。
| A | |
|---|---|
| 1 | =connect(“demo”) |
| 2 | =A1.query(“select 订单 ID, 订单编号, 发货日期, 到货日期, 客户 ID, 货主名称, 运货商, 运货费, 货主城市 from 订单”) |
| 3 | =A1.query@x(“select * from 订单明细”) |
| 4 | >A2.run(订单编号 =A3.select( 订单 ID==A2. 订单编号)) |
| 5 | return A2.select(订单编号!=[]) |
A1:连接数据源;
A2-A3:分别查询订单和订单明细表数据;
A4:根据订单编号关联订单和订单明细表;
A5:报表返回订单编号不为空的结果集。
编制报表
新建报表模板后,数据集选择“集算器”,在数据集编辑窗口指定上述编辑好的 dfx 文件,完成数据集创建。
报表中层次数据集效果
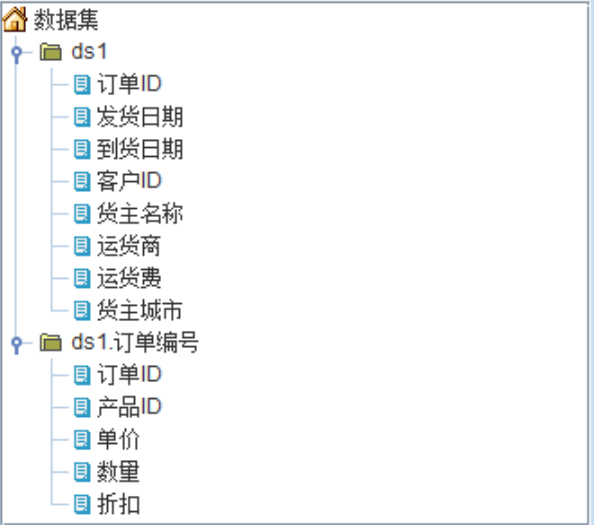
设置报表模板表达式:

不同于在报表中关联,使用层次数据集可通过集算脚本返回的单个结果集完成主子报表的制作,从而获得了更高的性能。为了对比,下面看一下在报表中直接关联的实现方式:
不使用层次数据集实现
数据集
ds1: select 订单 ID, 订单 ID 订单编号, 发货日期, 到货日期, 客户 ID, 货主名称, 运货商, 运货费, 货主城市 from 订单
ds2: select * from 订单明细
报表模板
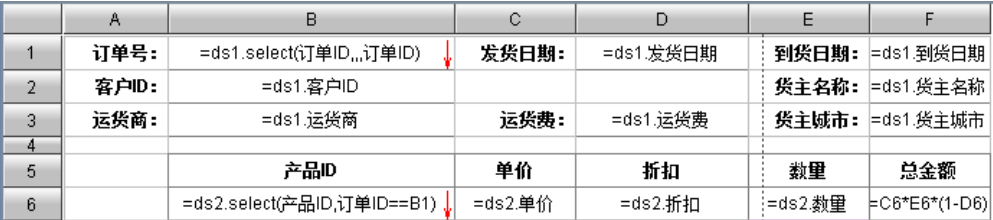
效果对比
下表对比了使用层次数据集前后的时间开销,单位为秒。

可以看到,使用层次数据集带来了明显的效果提升。这是因为在单元格中完成主子表的关联,只能使用遍历算法(针对单条主记录去寻找关联的子记录),因此效率不高。而集算器采用了更高效的 hash 关联方案,事先将所有子记录按 hash 代码对应到主记录上(代码中的 run 函数, 速度比遍历快 5-10 倍),使得主子表的数据源准备(数据计算)效率大大提升,从而可以获得更高的整体运算性能。
posted on 2019-05-28 10:58 IBelieve002 阅读(430) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号