格间计算性能提升方案
一般情况下,如果报表中存在很多格间计算(即单元格之间的关联计算),那么通常会影响报表性能。这是因为:
1、格间计算很难分步骤编写,导致运算过程很难优化。
2、格间计算可能需要多次遍历单元格集才能完成运算。
3、格间计算往往要利用较多隐藏格作为中间变量。而隐藏格除格值外,还记录了很多与显示相关的属性值,比如:字体、颜色、显示方式等。即便设置了单元格隐藏,但这些属性还在,依然会占用内存,影响计算速度。
不过在润乾报表的集算脚本支持下,这个问题能够得到很好的解决。下面我们就通过一个典型的例子——《雇员销售情况排名》报表,来看下传统方式和润乾报表的对比:
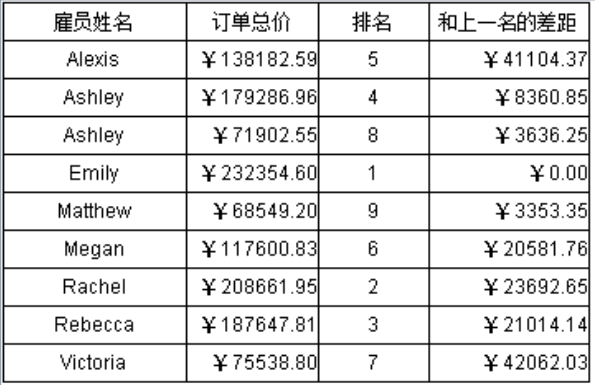
报表要求如下:
按照员工姓名排序,根据订单总价计算排名,并且计算“和上一名的差距”。
一、传统实现方式
1、首先定义 sql 数据集 ds1,其 sql 如下:
SELECT EMPLOYEE.EID,MAX(EMPLOYEE.NAME) 姓名,sum(订单明细. 数量 * 订单明细. 单价) 订单总价 FROM EMPLOYEE, 订单, 订单明细 WHERE 订单. 订单 ID = 订单明细. 订单 ID AND EMPLOYEE.EID = 订单. 雇员 ID group by EMPLOYEE.EID order by 姓名
可以看到,为了让输出结果要按姓名排序,SQL 中要写作“ORDER BY 姓名”。
2、报表设计

其中,
雇员姓名、订单总价:直接来自 sql。
排名:C2 单元格利用格间计算实现排名计算。计算当前订单总价的排名时,需要先找出所有订单总价中比本格值大的单元格,然后符合条件的单元格数加一就是排名。也就是说每计算一个雇员的排名,就要遍历一边所有的订单总价。
类似地,D2 计算“和上一名的差距”时还要再做一次按条件遍历。这个遍历还存在引用关系的处理,要等排名列计算完才能算差距列,但报表计算次序一般是从上到下的,中途处理引用关系会导致多次失败的试算(试图计算某格,如果发现该格引用的格未计算就要存放等待着下一轮再计算),失败的试算会浪费大量时间。
上述格间计算对订单总价遍历了 n 次,n 是雇员个数,两个格间运算的总体复杂度是 2*N*N。
二、润乾报表方案
采用润乾报表方案(结合集算器实现),可以编写过程化的集算脚本代替格间计算,从而提升报表性能。
1、编写集算器脚本
对于本报表,编写脚本如下(保存为 sales.dfx):
| A | |
|---|---|
| 1 | =connect(“demo”) |
| 2 | =A1.query(“SELECT EMPLOYEE.EID,MAX(EMPLOYEE.NAME) 姓名,sum(订单明细. 数量 * 订单明细. 单价) 订单总价,null 排名,0 和上一名的差距 FROM EMPLOYEE, 订单, 订单明细 WHERE 订单. 订单 ID = 订单明细. 订单 ID AND EMPLOYEE.EID = 订单. 雇员 ID group by EMPLOYEE.EID order by 订单总价 desc”) |
| 3 | =A1.close() |
| 4 | =A2.run(#: 排名,if(#!=1, 订单总价 [-1]- 订单总价,0): 和上一名的差距) |
| 5 | =A4.sort(姓名) |
| 6 | return A5 |
代码说明:
A1:连接数据库。
A2:用 sql 计算订单总价,并按照订单总价降序排序。
A3:关闭数据库。
A4:对 A2 循环计算,“排名”等于当前记录的行号 #,“和上一名的差距”等于用上一行的订单总价减去当前行的订单总价,如果是第一行就直接为 0。
A5:按照姓名重新排序。
A6:返回结果集给报表。
可以看到集算脚本仅用一次遍历加一次排序就完成了排名和上一名的差距的计算,也不存在试算以解决引用关系的问题,所有计算都能一次成功进行。本方案的整体复杂度是 N(遍历计算)+N*logN(排序),比之前的格间计算快得多。
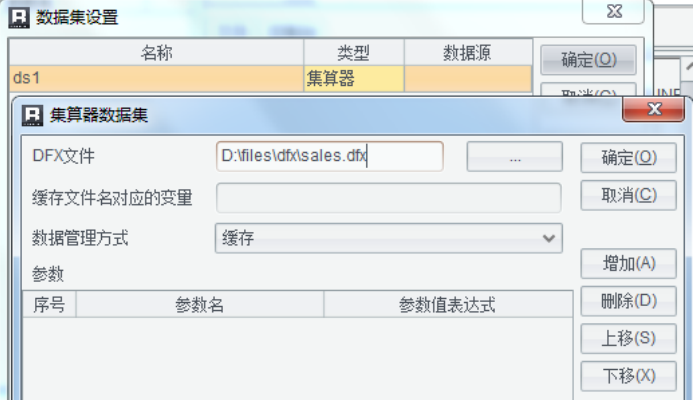
2、配置报表数据集
在报表设计器中定义集算数据集,调用 sales.dfx:
3、设计报表
设计表样如下:

posted on 2019-05-14 14:35 IBelieve002 阅读(254) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号