
Python 机器学习及实践 Codeing 模型实用技巧 (特征提升 模型正则化 模型检测 超参数搜索)
之前的数据都是经过了规范化处理,而且模型也大多数采用了默认的初始化配置
但是在世纪研究和工作种接触到的数据都是这样规整的吗?难道默认配置就最佳的吗?
3.1模型实用技巧
一旦我们确定使用某个模型 本书所提供的程序库就可以帮助我们从标准的训练数据种,依靠默认的配置学习到模型所需要的参数;
接下来,我们便可以利用这组得来的参数指导模型在测试数据上进行预测,进而对模型的表现进行评价
但是这套方案不能保证:
①所有用于训练的数据特征都是最好的
②学习得到的参数一定是最优的
③默认配置下的模型总是最佳的
Together 我们可以从多个角度对在前面使用过的模型进行性能提升 (预处理数据 控制参数 优化模型配置)
特征提升(特征抽取和特征筛选)
特征抽取
所谓特征抽取 就是逐条将原始数据转化维特征向量的形式 这个过程同时涉及对数据特征的量化表示
原始数据 :
1数字化的信号数据(声纹,图像)
2还有大量符号化的文本
①我们无法直接将符号化的文字本身用于计算任务 而是需要通过某些处理手段 ,预先将文本量化为特征向量
有些用符号表示的数据特征已经相对结构化,并且以字典这种数据结构进行存储。
这时我们使用DictVectorizer 对特征进行抽取和向量化
measurements=[{'city':'Dubai','temperature':33.},{'city':'London','temperature':12.},
{'city':'San Fransisco','temperature':18.}]
from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer() #初始化DictVectorizer()特征抽取器
print(vec.fit_transform(measurements).toarray()) #输出转化后的特征矩阵
print(vec.get_feature_names()) #输出各个维度特征含义
#DictVectorizer()特征抽取器对类别型特征进行了one-hot处理,对数值型特征没做进一步处理
DiceVectorizer 对特征的处理方式(字典):
1类别行 使用0/1二值方式
2数字型 维持原始数值即可
②另外一些文本数据更为原始 知识一系列的字符串 我们采用词袋法对特征进行抽取和向量化
词袋法的两种计算方式
CountVectorizer
TfidVectorizer
(a.)CountVectorizer——每个词(Term)在该训练文本中出现的频率(Term Frequency);
(b.)TfidfVectorizer——除了考量某一词汇在当前文本中出现的频率(Term Frequency)外,还要关注包含这个词汇的文本条数的倒数(Inverse Document Frequency)。训练文本的条目越多,TfidfVectorizer这种特征量化的方式就更有优势,因为计算词频(Term Frequency)的目的在于找出对所在文本的含义更有贡献的重要词汇
如果一个词几乎在每篇文章中都出现,说明这个词是常用词,不会帮助模型对文本进行分类。此外,在每条文本中都出现的常用词汇成为停用词(Stop Words),停用词在文本特征抽取时需要过滤掉。
#使用CountVectorizer 并且在不去掉停用词的条件下,对文本进行量化的朴素贝叶斯分类性能预测 from sklearn.datasets import fetch_20newsgroups#20类新闻文本 from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import classification_report news=fetch_20newsgroups(subset='all') X_train,X_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25,random_state=33) count_vec=CountVectorizer() #默认形式初始化词频统计器(不去停用词) X_count_train=count_vec.fit_transform(X_train) X_count_test=count_vec.transform(X_test) mnb_count=MultinomialNB() mnb_count.fit(X_count_train,y_train) #用朴素贝叶斯分类器对词频统计器(不去停用词)处理后的样本进行参数学习 print('The accuracy of classifying 20newsgroups using Naive Bayes(CountVectorizer without filtering stopwords):', mnb_count.score(X_count_test,y_test)) y_count_predict=mnb_count.predict(X_count_test) print(classification_report(y_test,y_count_predict,target_names=news.target_names))
#使用TfidVectorizer 并且在不去掉停用词的条件下,对文本进行量化的朴素贝叶斯分类性能预测 from sklearn.datasets import fetch_20newsgroups from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import classification_report news=fetch_20newsgroups(subset='all') X_train,X_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25,random_state=33) tfidf_vec=TfidfVectorizer() #默认形式初始化tfidf统计器(不去停用词) X_tfidf_train=tfidf_vec.fit_transform(X_train) X_tfidf_test=tfidf_vec.transform(X_test) mnb_tfidf=MultinomialNB() mnb_tfidf.fit(X_tfidf_train,y_train) #用朴素贝叶斯分类器对tfidf统计器(不去停用词)处理后的样本进行参数学习 print('The accuracy of classifying 20news with Naive Bayes(TfidfVectorizer without filtering stopwords):', mnb_tfidf.score(X_tfidf_test,y_test)) y_tfidf_predict=mnb_tfidf.predict(X_tfidf_test) print(classification_report(y_test,y_tfidf_predict,target_names=news.target_names)) #在训练文本量较多的时候,利用TfidfVectorizer压制一些常用词汇对分类决策的干扰
#分别使用CountVectorizer与TfidVectorizer 并且在去掉停用词的条件下,对文本进行量化的朴素贝叶斯分类性能预测 from sklearn.datasets import fetch_20newsgroups from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB news=fetch_20newsgroups(subset='all') X_train,X_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25,random_state=33) count_filter_vec=CountVectorizer(analyzer='word',stop_words='english') #初始化词频统计器(去停用词) X_count_filter_train=count_filter_vec.fit_transform(X_train) X_count_filter_test=count_filter_vec.transform(X_test) mnb_count_filter=MultinomialNB() mnb_count_filter.fit(X_count_filter_train,y_train) print('The accuarcy of classifying 20newsgroups using Naive Bayes(CountVetorizer by filtering stopwords):', mnb_count_filter.score(X_count_filter_test,y_test)) y_count_filter_predict=mnb_count_filter.predict(X_count_filter_test) from sklearn.metrics import classification_report print(classification_report(y_test,y_count_filter_predict,target_names=news.target_names)) tfidf_filter_vec=TfidfVectorizer(analyzer='word',stop_words='english') #初始化tfidf统计器(去停用词) X_tfidf_filter_train=tfidf_filter_vec.fit_transform(X_train) X_tfidf_filter_test=tfidf_filter_vec.transform(X_test) mnb_tfidf_filter=MultinomialNB() mnb_tfidf_filter.fit(X_tfidf_filter_train,y_train) print('The accuracy of classifying 20newsgroups with Naive Bayes(TfidfVectorizer by filtering stopwords):', mnb_tfidf_filter.score(X_tfidf_filter_test,y_test)) y_tfidf_filter_predict=mnb_tfidf_filter.predict(X_tfidf_filter_test) print(classification_report(y_test,y_tfidf_filter_predict,target_names=news.target_names))
特征筛选
良好的数据特征组合不需要太多,便可以使模型的性能表现突出。
冗余的特征不会影响到模型的性能,不过却使得CPU的计算做了无用功
主成分分析主要用于去除多余的那些线性相关的特长组合,原因在于这些冗余的特征组合并不会对模型训练有更多贡献。而不良的特征自然会降低模型的精度。
特征筛选与PCA 这类通过选择主成分进行对特征进行重建的方法略有区别:对于PCA而言,我们经常无法解释重建之后的特征;
但是特征筛选不存在对特征值的修改 而更加侧重于寻找那些对模型的性能提升较大的少量特征。
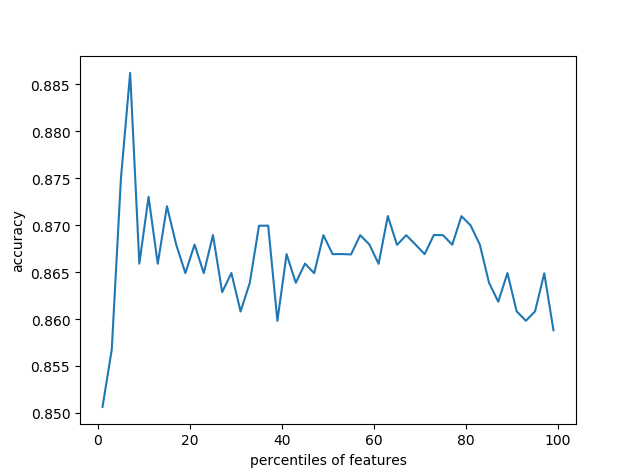
#使用Titanic数据集,通过特征筛选的方法一步步提升决策树的预测性能 import pandas as pd titanic=pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt') y=titanic['survived'] #分离特征与标签 X=titanic.drop(['row.names','name','survived'],axis=1) X['age'].fillna(X['age'].mean(),inplace=True) #填充缺失值 X.fillna('UNKNOWN',inplace=True) from sklearn.cross_validation import train_test_split X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.25, random_state=33) from sklearn.feature_extraction import DictVectorizer vec=DictVectorizer() X_train=vec.fit_transform(X_train.to_dict(orient='record')) #类别型特征向量化one-hot X_test=vec.transform(X_test.to_dict(orient='record')) print(len(vec.feature_names_)) #使用决策树模型对所有特征进行预测并评估 from sklearn.tree import DecisionTreeClassifier dt=DecisionTreeClassifier(criterion='entropy') dt.fit(X_train,y_train) dt.score(X_test,y_test) from sklearn import feature_selection fs=feature_selection.SelectPercentile(feature_selection.chi2,percentile=20) #筛选前20%特征建模 X_train_fs=fs.fit_transform(X_train,y_train) dt.fit(X_train_fs,y_train) X_test_fs=fs.transform(X_test) dt.score(X_test_fs,y_test) from sklearn.cross_validation import cross_val_score import numpy as np percentiles=range(1,100,2) results=[] for i in percentiles: fs=feature_selection.SelectPercentile(feature_selection.chi2,percentile=i) X_train_fs=fs.fit_transform(X_train,y_train) scores=cross_val_score(dt,X_train_fs,y_train,cv=5) #通过交叉验证,按固定间隔2%的步长筛选特征 results=np.append(results,scores.mean()) print(results) opt=np.where(results==results.max())[0] print('Optimal number of features %d' % percentiles[opt[0]]) import pylab as pl pl.plot(percentiles,results) pl.xlabel('percentiles of features') pl.ylabel('accuracy') pl.show() from sklearn import feature_selection fs=feature_selection.SelectPercentile(feature_selection.chi2,percentile=7) #使用最佳筛选后的特征进行相同建模 X_train_fs=fs.fit_transform(X_train,y_train) dt.fit(X_train_fs,y_train) X_test_fs=fs.transform(X_test) dt.score(X_test_fs,y_test)
模型正则化
欠拟合与过拟合
模型的泛化能力:模型对未知数据的预测能力
拟合:机器学习模型在训练的过程中,通过更新参数,使模型不断契合可观测数据(训练集)的过程
存在过拟合和欠拟合两种模型的状态
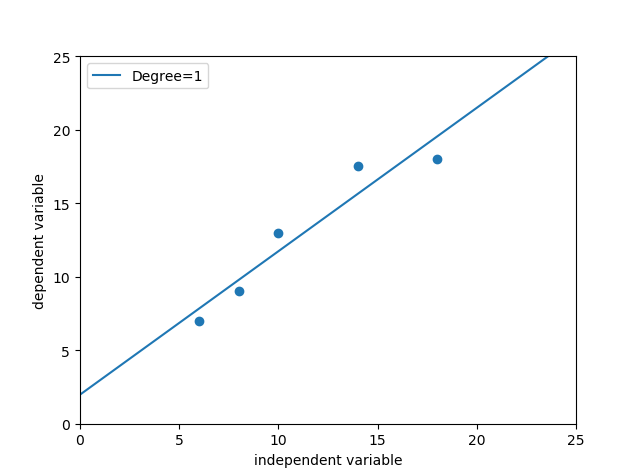
#使用线性回归模型在披萨训练样本上进行拟合 X_train=[[6],[8],[10],[14],[18]] y_train=[[7],[9],[13],[17.5],[18]] from sklearn.linear_model import LinearRegression regressor=LinearRegression() #默认配置初始化线性回归模型 regressor.fit(X_train,y_train) #根据训练集数据建模 import numpy as np xx=np.linspace(0,26,100) #构建测试集 xx=xx.reshape(xx.shape[0],1) yy=regressor.predict(xx) import matplotlib.pyplot as plt plt.scatter(X_train,y_train) plt1,=plt.plot(xx,yy,label='Degree=1') plt.axis([0,25,0,25]) plt.xlabel('independent variable') plt.ylabel('dependent variable') plt.legend(handles=[plt1]) plt.show() print('The R-squared value of Linear Regressor performing on the training data is', regressor.score(X_train,y_train))
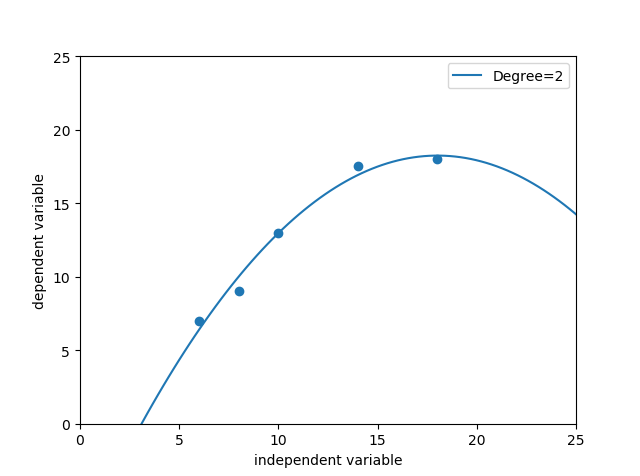
#使用二次多项式回归模型在披萨训练样本上进行拟合 X_train=[[6],[8],[10],[14],[18]] y_train=[[7],[9],[13],[17.5],[18]] from sklearn.preprocessing import PolynomialFeatures poly2=PolynomialFeatures(degree=2) #多项式特征产生器 X_train_poly2=poly2.fit_transform(X_train) #X_train_poly2即为由训练集构造出的二次多项式特征 from sklearn.linear_model import LinearRegression regressor_poly2=LinearRegression() regressor_poly2.fit(X_train_poly2,y_train) #建模生产的二次多项式回归模型 import numpy as np xx=np.linspace(0,26,100) xx=xx.reshape(xx.shape[0],1) xx_poly2=poly2.transform(xx) #对测试集数据构造二次多项式特征 yy_poly2=regressor_poly2.predict(xx_poly2) import matplotlib.pyplot as plt plt.scatter(X_train,y_train) plt2,=plt.plot(xx,yy_poly2,label='Degree=2') plt.axis([0,25,0,25]) plt.xlabel('independent variable') plt.ylabel('dependent variable') plt.legend(handles=[plt2]) plt.show() print('The R-squared value of Polynomial Regressor(Degree=2) performing on the training data is', regressor_poly2.score(X_train_poly2,y_train))
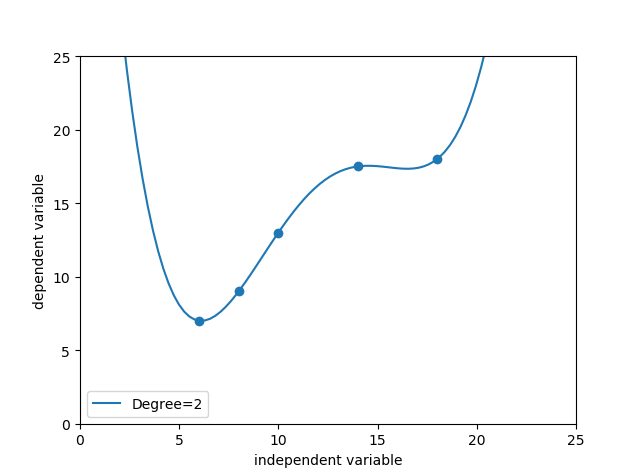
#使用4次多项式回归模型在披萨训练样本上进行拟合 X_train=[[6],[8],[10],[14],[18]] y_train=[[7],[9],[13],[17.5],[18]] from sklearn.preprocessing import PolynomialFeatures poly4=PolynomialFeatures(degree=4) #多项式特征产生器 X_train_poly4=poly4.fit_transform(X_train) #X_train_poly2即为由训练集构造出的二次多项式特征 from sklearn.linear_model import LinearRegression regressor_poly4=LinearRegression() regressor_poly4.fit(X_train_poly4,y_train) #建模生产的二次多项式回归模型 import numpy as np xx=np.linspace(0,26,100) xx=xx.reshape(xx.shape[0],1) xx_poly2=poly4.transform(xx) #对测试集数据构造二次多项式特征 yy_poly2=regressor_poly4.predict(xx_poly2) import matplotlib.pyplot as plt plt.scatter(X_train,y_train) plt2,=plt.plot(xx,yy_poly2,label='Degree=2') plt.axis([0,25,0,25]) plt.xlabel('independent variable') plt.ylabel('dependent variable') plt.legend(handles=[plt2]) plt.show() print('The R-squared value of Polynomial Regressor(Degree=2) performing on the training data is', regressor_poly4.score(X_train_poly4,y_train))
#评估3种回归模型在测试数据集上的性能表现 X_test=[[6],[8],[11],[16]] y_test=[[8],[12],[15],[18]] print('Linear regression:',regressor.score(X_test,y_test)) X_test_poly2=poly2.transform(X_test) print('Polynomial 2 regression:',regressor_poly2.score(X_test_poly2,y_test)) X_test_poly4=poly4.transform(X_test) print('Polynomial 4 regression:',regressor_poly4.score(X_test_poly4,y_test))
Together
当模型复杂度很低 模型不仅没有对训练集上的数据有良好的拟合状态,而且在测试集上也表现平平,这种情况叫欠拟合,如线性回归预测
但是,当我们意味追求很高的模型复杂度,尽管模型几乎完全拟合了全部训练数据 但模型也变得非常波动 几乎丧失了对未知数据的预测能力 ,这种情况叫过拟合,如四次多项式回归预测。
避免欠拟合 在要求增加模型复杂度 提高在可观测数据上的表现的同时 又需要兼顾模型的泛化力 防止发生过拟合。
正则化方法(L1正则化和L2正则化)
正则化的目的在于提高模型在未知测试数据上的泛化力,避免参数过拟合
因此,正则化的常见方法都是在原模型优化目标的基础上,增加对参数的惩罚项
L1正则化是让参数向量中的许多元素趋向于0,让有效特征变得稀疏,对应的L1正则化模型称为Lasso。
L2正则化是让参数向量中的大部分元素都变得很小,压制了参数之间的差异性,对应的L2正则化模型称为Ridge
#Lasso模型在4次多项式特征上拟合的拟合 from sklearn.linear_model import Lasso lasso_poly4=Lasso() #默认配置初始化Lasso lasso_poly4.fit(X_train_poly4,y_train) #利用Lasso对四次多项式特征回归拟合 print(lasso_poly4.score(X_test_poly4,y_test)) #在测试集上进行评估 print(lasso_poly4.coef_) #输出Lasso模型的参数列表 print(' ') print(regressor_poly4.score(X_test_poly4,y_test)) #对比看一下不加正则化项的四次多项式回归拟合 print(regressor_poly4.coef_) #Ridge模型在4次多项式特征上的拟合表现 from sklearn.linear_model import Ridge ridge_poly4=Ridge() #默认配置初始化Ridge ridge_poly4.fit(X_train_poly4,y_train) #利用Ridge对四次多项式特征回归拟合 print(ridge_poly4.score(X_test_poly4,y_test)) #在测试集上进行评估 print(ridge_poly4.coef_) #输出Ridge模型的参数列表 print(np.sum(ridge_poly4.coef_**2)) print(' ') print(regressor_poly4.coef_) #对比看一下不加正则化项的四次多项式回归拟合 print(np.sum(regressor_poly4.coef_**2))
模型检验
在实际生活种(比赛)我们不知道 模型对测试集预测的答案 (当我们书中没有测试集数据的情况下)
我们把现有的数据进行采样分割 成 训练集和开发集(验证集)
模型校验方式 留一验证 交叉验证
留一验证(用于早期)
随机采样一定比例作为训练集 ,留下的作为验证集 通常比例为7 3 但是由于对于验证集合随机采样的不确定性 使模型的性能不稳定
交叉验证(留一验证的高级版本)
多次进行留一验证 后求得平均结果
超参数搜索
多数情况先,超参数的选择是无限的。因此在有限的时间内,除了可以验证预设几种超参数组合以外,也可以通过启发式的搜索方式对超参数组合进行调优(网格搜索),同时由于超参数的验证过程之间彼此独立,因此为并行计算提供了可能(并行搜索)。
网格搜索
对多种超参数组合的空间进行暴力搜索。每一套超参数组合被带入到学习函数中作为新的模型,并且为了比较新模型之间的性能,每个模型都会采用交叉验证的方法在多组相同的训练集和开发数据集下进行评估
#使用单线程对文本分类的朴素贝叶斯模型的超参数组合执行网格搜索 from sklearn.datasets import fetch_20newsgroups import numpy as np from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.pipeline import Pipeline from sklearn.model_selection import GridSearchCV news=fetch_20newsgroups(subset='all') #选取前3000条数据 X_train,X_test,y_train,y_test=train_test_split(news.data[:3000],news.target[:3000],test_size=0.25,random_state=33) #使用Pipline 简化系统搭建流程 将文本抽取与分类器模型串联起来 clf=Pipeline([('vect',TfidfVectorizer(stop_words='english',analyzer='word')),('svc',SVC())]) #超参数svc_gamma有4个 svc_C有3个 超参数组合一共有12种 使用np.logspace函数来选取超参数 parameters = {'svc__gamma': np.logspace(-2, 1, 4), 'svc__C': np.logspace(-1, 1, 3)} gs=GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3) gs.fit(X_train,y_train) gs.best_params_,gs.best_score_ print(gs.score(X_test,y_test))
关于网格搜索的参数:
GridSearchCV(estimator,param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True,cv=None, verbose=0,
pre_dispatch='2*n_jobs', error_score='raise',return_train_score=True)
estimator:所使用的分类器。
param_grid:值为字典或者列表,即需要最优化的参数的取值。
scoring :准确度评价标准,默认None。
cv :交叉验证参数,默认None,使用三折交叉验证(cv=3)。
refit :默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
n_jobs: 并行数,int:个数,-1:跟CPU核数一致, 1:默认值。
pre_dispatch:指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,
而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
并行搜索
n_jobs=-1是用cpu所有的核训练 即并行的方式
#使用多个线程对文本分类的朴素贝叶斯模型的超参数组合执行并行化的网格搜索 from sklearn.datasets import fetch_20newsgroups import numpy as np from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.pipeline import Pipeline from sklearn.model_selection import GridSearchCV news=fetch_20newsgroups(subset='all') #选取前3000条数据 X_train,X_test,y_train,y_test=train_test_split(news.data[:3000],news.target[:3000],test_size=0.25,random_state=33) #使用Pipline 简化系统搭建流程 将文本抽取与分类器模型串联起来 clf=Pipeline([('vect',TfidfVectorizer(stop_words='english',analyzer='word')),('svc',SVC())]) #超参数svc_gamma有4个 svc_C有3个 超参数组合一共有12种 使用np.logspace函数来选取超参数 parameters = {'svc__gamma': np.logspace(-2, 1, 4), 'svc__C': np.logspace(-1, 1, 3)} #初始化配置并行网格搜索 n_jobs=-1代表使用该计算机的全部CPU gs=GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3,n_jobs=-1) gs.fit(X_train,y_train) gs.best_params_,gs.best_score_ print(gs.score(X_test,y_test))

