
SSD 车辆检测 实现
part1 模型实现部部分
1我们使用builde_model 来实现模型的构建
def build_model(image_size, n_classes, mode='training', l2_regularization=0.0, min_scale=0.1, max_scale=0.9, scales=None, aspect_ratios_global=[0.5, 1.0, 2.0], aspect_ratios_per_layer=None, two_boxes_for_ar1=True, steps=None, offsets=None, clip_boxes=False, variances=[1.0, 1.0, 1.0, 1.0], coords='centroids', normalize_coords=False, subtract_mean=None, divide_by_stddev=None, swap_channels=False, confidence_thresh=0.01, iou_threshold=0.45, top_k=200, nms_max_output_size=400, return_predictor_sizes=False):
解释一下这个函数的参数
Arguments: image_size (tuple): The input image size in the format `(height, width, channels)`. n_classes (int): The number of positive classes: 5. mode (str, optional): training:相对坐标 inference:绝对坐标 One of 'training', 'inference' and 'inference_fast'. In 'training' mode, the model outputs the raw prediction tensor, while in 'inference' and 'inference_fast' modes, the raw predictions are decoded into absolute coordinates and filtered via confidence thresholding, non-maximum suppression, and top-k filtering. The difference between latter two modes is that 'inference' follows the exact procedure of the original Caffe implementation, while 'inference_fast' uses a faster prediction decoding procedure. l2_regularization (float, optional): The L2-regularization rate. Applies to all convolutional layers. min_scale (float, optional): minS 和 maxS The smallest scaling factor for the size of the anchor boxes as a fraction of the shorter side of the input images. max_scale (float, optional): The largest scaling factor for the size of the anchor boxes as a fraction of the shorter side of the input images. All scaling factors between the smallest and the largest will be linearly interpolated. Note that the second to last of the linearly interpolated scaling factors will actually be the scaling factor for the last predictor layer, while the last scaling factor is used for the second box for aspect ratio 1 in the last predictor layer if `two_boxes_for_ar1` is `True`. scales (list, optional): 一个list 包含每一层的anchor 占比 A list of floats containing scaling factors per convolutional predictor layer. This list must be one element longer than the number of predictor layers. The first `k` elements are the scaling factors for the `k` predictor layers, while the last element is used for the second box for aspect ratio 1 in the last predictor layer if `two_boxes_for_ar1` is `True`. This additional last scaling factor must be passed either way, even if it is not being used. If a list is passed, this argument overrides `min_scale` and `max_scale`. All scaling factors must be greater than zero. aspect_ratios_global (list, optional): 全局长宽比 The list of aspect ratios for which anchor boxes are to be generated. This list is valid for all predictor layers. The original implementation uses more aspect ratios for some predictor layers and fewer for others. If you want to do that, too, then use the next argument instead. aspect_ratios_per_layer (list, optional): 每一层长宽比设定 A list containing one aspect ratio list for each predictor layer. This allows you to set the aspect ratios for each predictor layer individually. If a list is passed, it overrides `aspect_ratios_global`. two_boxes_for_ar1 (bool, optional): 在长宽比为1的情况下 是否考虑使用2个box 第二个的比例 是取下一层的 S与当前层S 来计算集合平均值 如第一层s = 0.2 第二层s = 0.34 Only relevant for aspect ratio lists that contain 1. Will be ignored otherwise. If `True`, two anchor boxes will be generated for aspect ratio 1. The first will be generated using the scaling factor for the respective layer, the second one will be generated using geometric mean of said scaling factor and next bigger scaling factor. steps (list, optional): 前一像素个点的anchor 到 下一像素个点 滑动的步长 默认为 输入原图 如300*300 除以 当前feature map 长宽 如 10*10 `None` or a list with as many elements as there are predictor layers. The elements can be either ints/floats or tuples of two ints/floats. These numbers represent for each predictor layer how many pixels apart the anchor box center points should be vertically and horizontally along the spatial grid over the image. If the list contains ints/floats, then that value will be used for both spatial dimensions. If the list contains tuples of two ints/floats, then they represent `(step_height, step_width)`. If no steps are provided, then they will be computed such that the anchor box center points will form an equidistant grid within the image dimensions. offsets (list, optional): 起始anchor 的 中心位置 可设置为None `None` or a list with as many elements as there are predictor layers. The elements can be either floats or tuples of two floats. These numbers represent for each predictor layer how many pixels from the top and left boarders of the image the top-most and left-most anchor box center points should be as a fraction of `steps`. The last bit is important: The offsets are not absolute pixel values, but fractions of the step size specified in the `steps` argument. If the list contains floats, then that value will be used for both spatial dimensions. If the list contains tuples of two floats, then they represent `(vertical_offset, horizontal_offset)`. If no offsets are provided, then they will default to 0.5 of the step size, which is also the recommended setting. clip_boxes (bool, optional): 是否对超出边界的anchor 进行剪切操作 默认为False 剪切效果不是很好 If `True`, clips the anchor box coordinates to stay within image boundaries. variances (list, optional): 默认为1 作者设定的值 A list of 4 floats >0. The anchor box offset for each coordinate will be divided by its respective variance value. coords (str, optional): 标定框表示的形式 'centroids' for the format `(cx, cy, w, h)` 'minmax' for the format `(xmin, xmax, ymin, ymax)` 'corners' for the format `(xmin, ymin, xmax, ymax) The box coordinate format to be used internally by the model (i.e. this is not the input format of the ground truth labels). Can be either 'centroids' for the format `(cx, cy, w, h)` (box center coordinates, width, and height), 'minmax' for the format `(xmin, xmax, ymin, ymax)`, or 'corners' for the format `(xmin, ymin, xmax, ymax)`. normalize_coords (bool, optional): 是否使用归一化的形式来表示像素的坐标 Set to `True` if the model is supposed to use relative instead of absolute coordinates, i.e. if the model predicts box coordinates within [0,1] instead of absolute coordinates. subtract_mean (array-like, optional): 均值化 把图像像素变为【-127,+127】 `None` or an array-like object of integers or floating point values of any shape that is broadcast-compatible with the image shape. The elements of this array will be subtracted from the image pixel intensity values. For example, pass a list of three integers to perform per-channel mean normalization for color images. divide_by_stddev (array-like, optional): 归一化 均值化之后缩放到0,1 之间 或正负0.5之间 `None` or an array-like object of non-zero integers or floating point values of any shape that is broadcast-compatible with the image shape. The image pixel intensity values will be divided by the elements of this array. For example, pass a list of three integers to perform per-channel standard deviation normalization for color images. swap_channels (list, optional): 对通道 进行操作 默认为False Either `False` or a list of integers representing the desired order in which the input image channels should be swapped.
image_size:模型的输入形状
n_classes:检测的类别送数
mode: training:相对坐标 inference:绝对坐标 相对坐标就是相对于整个feature 的比例值 绝对目标就真实的像素值
One of 'training', 'inference' and 'inference_fast'. In 'training' mode,
l2_regularization:l2正则化的系数
min_scale (float, optional):
max_scale (float, optional)
minS 和 maxS 论文中 anchor 现对于 featuremap的 比例值 一个是最大值 一个是最小值 最小值是第一个预测层的比例 最大值是最后一层预测层的比例
scales (list, optional):一个list 包含每一层的anchor 占比
aspect_ratios_global (list, optional):
全局长宽比
aspect_ratios_per_layer (list, optional):
每一层长宽比设定
two_boxes_for_ar1 (bool, optional):
在长宽比为1的情况下 是否考虑使用2个box
第二个的比例 是取下一层的 S与当前层S 来计算集合平均值
如第一层s = 0.2 第二层s = 0.34
steps (list, optional):
前一像素个点的anchor 到 下一像素个点 滑动的步长
offsets (list, optional):
起始anchor 的 中心位置 可设置为None
clip_boxes (bool, optional):
是否对超出边界的anchor 进行剪切操作 默认为False 剪切效果不是很好
variances (list, optional):
默认为1 作者设定的值
coords (str, optional):
标定框表示的形式
'centroids' for the format `(cx, cy, w, h)`
'minmax' for the format `(xmin, xmax, ymin, ymax)`
'corners' for the format `(xmin, ymin, xmax, ymax)
normalize_coords (bool, optional):
是否使用归一化的形式来表示像素的坐标
divide_by_stddev (array-like, optional):
归一化 均值化之后缩放到0,1 之间 或正负0.5之间
divide_by_stddev (array-like, optional):
归一化 均值化之后缩放到0,1 之间 或正负0.5之间
swap_channels (list, optional):
对通道 进行操作 默认为False
confidence_thresh (float, optional): 检测目标的概率的阈值 达到这个阈值认为 正确检测到了 目标 A float in [0,1), the minimum classification confidence in a specific positive class in order to be considered for the non-maximum suppression stage for the respective class. A lower value will result in a larger part of the selection process being done by the non-maximum suppression stage, while a larger value will result in a larger part of the selection process happening in the confidence thresholding stage. iou_threshold (float, optional): 非极大值抑制 中的iou操作表示两个anchor 的重合区域 我们把 两个anchor iou 超过这个阈值我们认为检测到了同一个目标 A float in [0,1]. All boxes that have a Jaccard similarity of greater than `iou_threshold` with a locally maximal box will be removed from the set of predictions for a given class, where 'maximal' refers to the box's confidence score. top_k (int, optional): 保留概率最高的k个边界框 假如一共检测3个 可以设定3 The number of highest scoring predictions to be kept for each batch item after the non-maximum suppression stage. nms_max_output_size (int, optional): The maximal number of predictions that will be left over after the NMS stage. return_predictor_sizes (bool, optional): 返回没个输出层的特征图大小 可用于调试 If `True`, this function not only returns the model, but also a list containing the spatial dimensions of the predictor layers. This isn't strictly necessary since you can always get their sizes easily via the Keras API, but it's convenient and less error-prone to get them this way. They are only relevant for training anyway (SSDBoxEncoder needs to know the spatial dimensions of the predictor layers), for inference you don't need them.
part2模型的实现
conv1 = Conv2D(32, (5,5), strides=(1,1), padding="same", kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv1')(x1) conv1 = BatchNormalization(axis=3, momentum=0.99, name='bn1')(conv1) conv1 = ELU(name='elu1')(conv1)#指数线性单元 poo11 = MaxPooling2D(pool_size=(2,2), name='pool1')(conv1) conv2 = Conv2D(48, (3, 3), strides=(1, 1), padding="same", kernel_initializer='he_normal',kernel_regularizer=l2(l2_reg), name='conv2')(poo11) conv2 = BatchNormalization(axis=3, momentum=0.99, name='bn2')(conv2) conv2 = ELU(name='elu2')(conv2) # 指数线性单元 poo12 = MaxPooling2D(pool_size=(2, 2), name='pool2')(conv2) conv3 = Conv2D(64, (3, 3), strides=(1, 1), padding="same", kernel_initializer='he_normal',kernel_regularizer=l2(l2_reg), name='conv3')(poo12) conv3 = BatchNormalization(axis=3, momentum=0.99, name='bn3')(conv3) conv3 = ELU(name='elu3')(conv3) # 指数线性单元 poo13 = MaxPooling2D(pool_size=(2, 2), name='pool3')(conv3) conv4 = Conv2D(64, (3, 3), strides=(1, 1), padding="same", kernel_initializer='he_normal',kernel_regularizer=l2(l2_reg), name='conv4')(poo13) conv4 = BatchNormalization(axis=3, momentum=0.99, name='bn4')(conv4) conv4 = ELU(name='elu4')(conv4) # 指数线性单元 poo14 = MaxPooling2D(pool_size=(2, 2), name='pool4')(conv4) conv5 = Conv2D(48, (3, 3), strides=(1, 1), padding="same", kernel_initializer='he_normal',kernel_regularizer=l2(l2_reg), name='conv5')(poo14) conv5 = BatchNormalization(axis=3, momentum=0.99, name='bn5')(conv5) conv5 = ELU(name='elu5')(conv5) # 指数线性单元 poo15 = MaxPooling2D(pool_size=(2, 2), name='pool5')(conv5) conv6 = Conv2D(48, (3, 3), strides=(1, 1), padding="same", kernel_initializer='he_normal',kernel_regularizer=l2(l2_reg), name='conv6')(poo15) conv6 = BatchNormalization(axis=3, momentum=0.99, name='bn6')(conv6) conv6 = ELU(name='elu6')(conv6) # 指数线性单元 poo16 = MaxPooling2D(pool_size=(2, 2), name='pool6')(conv6) conv7 = Conv2D(32, (3, 3), strides=(1, 1), padding="same", kernel_initializer='he_normal',kernel_regularizer=l2(l2_reg), name='conv7')(poo16) conv7 = BatchNormalization(axis=3, momentum=0.99, name='bn7')(conv7) conv7 = ELU(name='elu7')(conv7) # 指数线性单元 poo17 = MaxPooling2D(pool_size=(2, 2), name='pool7')(conv7)
一共7层卷积层用于特征提取
其中4,5,6,7用于ssd的检测
#分类 classes4 = Conv2D(n_boxes[0] * n_classes, (3, 3), strides=(1,1), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='classes4')(conv4) classes5 = Conv2D(n_boxes[1] * n_classes, (3, 3), strides=(1,1), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='classes5')(conv5) classes6 = Conv2D(n_boxes[2] * n_classes, (3, 3), strides=(1,1), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='classes6')(conv6) classes7 = Conv2D(n_boxes[3] * n_classes, (3, 3), strides=(1,1), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='classes7')(conv7) #定位 boxes4 = Conv2D(n_boxes[0] * 4, (3, 3), strides=(1,1), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='boxes4')(conv4) boxes5 = Conv2D(n_boxes[1] * 4, (3, 3), strides=(1,1), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='boxes5')(conv5) boxes6 = Conv2D(n_boxes[2] * 4, (3, 3), strides=(1,1), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='boxes6')(conv6) boxes7 = Conv2D(n_boxes[3] * 4, (3, 3), strides=(1,1), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='boxes7')(conv7) #生成anchor box anchors4 = AnchorBoxes(img_height, img_width, this_scale=scales[0], next_scale=scales[1], aspect_ratios=aspect_ratios[0], two_boxes_for_ar1= two_boxes_for_ar1, this_steps=steps[0], this_offsets=offsets[0], clip_boxes=clip_boxes, variances= variances, coords=coords, normalize_coords=normalize_coords, name='anchors4')(boxes4) anchors5 = AnchorBoxes(img_height, img_width, this_scale=scales[1], next_scale=scales[2], aspect_ratios=aspect_ratios[1], two_boxes_for_ar1= two_boxes_for_ar1, this_steps=steps[1], this_offsets=offsets[1], clip_boxes=clip_boxes, variances= variances, coords=coords, normalize_coords=normalize_coords, name='anchors5')(boxes5) anchors6 = AnchorBoxes(img_height, img_width, this_scale=scales[2], next_scale=scales[3], aspect_ratios=aspect_ratios[2], two_boxes_for_ar1= two_boxes_for_ar1, this_steps=steps[2], this_offsets=offsets[2], clip_boxes=clip_boxes, variances= variances, coords=coords, normalize_coords=normalize_coords, name='anchors6')(boxes6) anchors7 = AnchorBoxes(img_height, img_width, this_scale=scales[3], next_scale=scales[4], aspect_ratios=aspect_ratios[3], two_boxes_for_ar1= two_boxes_for_ar1, this_steps=steps[3], this_offsets=offsets[3], clip_boxes=clip_boxes, variances= variances, coords=coords, normalize_coords=normalize_coords, name='anchors7')(boxes7)
#softmax loss classes_softmax = Activation('softmax', name='classes_softmax')(classes_concat) #total loss predictions = Concatenate(axis=2, name='predictions')([classes_softmax, boxes_concat, anchors_concat])
2训练部分
模型参数
img_height = 300 # 图像的高度 img_width = 480 # 图像的宽度 img_channels = 3 # 图像的通道数 intensity_mean = 127.5 # 用于图像归一化, 将像素值转为 `[-1,1]` intensity_range = 127.5 # 用于图像归一化, 将像素值转为 `[-1,1]` n_classes = 5 # 正样本的类别 (不包括背景) scales = [0.08, 0.16, 0.32, 0.64, 0.96] # Anchor 的 scaling factors. 如果设置了这个值, 那么 `min_scale` 和 `max_scale` 会被忽略 aspect_ratios = [0.5, 1.0, 2.0] # 每一个 Anchor 的长宽比 two_boxes_for_ar1 = True # 是否产生两个为长宽比为 1 的 Anchor steps = None # 可以手动设置 Anchor 的步长, 不建议使用 offsets = None # 可以手动设置左上角 Anchor 的偏置, 不建议使用 clip_boxes = False # 是否将 Anchor 剪切到图像边界范围内 variances = [1.0, 1.0, 1.0, 1.0] # 可以将目标的坐标 scale 的参数, 建议保留 1.0 normalize_coords = True # 是否使用相对于图像尺寸的相对坐标
loss设定
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0) ssd_loss = SSDLoss(neg_pos_ratio=3, alpha=1.0) model.compile(optimizer=adam, loss=ssd_loss.compute_loss)
图像增强
data_augmentation_chain = DataAugmentationConstantInputSize(random_brightness=(-48, 48, 0.5), random_contrast=(0.5, 1.8, 0.5), random_saturation=(0.5, 1.8, 0.5), random_hue=(18, 0.5), random_flip=0.5, random_translate=((0.03,0.5), (0.03,0.5), 0.5), random_scale=(0.5, 2.0, 0.5), n_trials_max=3, clip_boxes=True, overlap_criterion='area', bounds_box_filter=(0.3, 1.0), bounds_validator=(0.5, 1.0), n_boxes_min=1, background=(0,0,0))
encorder 操作
predictor_sizes = [model.get_layer('classes4').output_shape[1:3], model.get_layer('classes5').output_shape[1:3], model.get_layer('classes6').output_shape[1:3], model.get_layer('classes7').output_shape[1:3]] ssd_input_encoder = SSDInputEncoder(img_height=img_height, img_width=img_width, n_classes=n_classes, predictor_sizes=predictor_sizes, scales=scales, aspect_ratios_global=aspect_ratios, two_boxes_for_ar1=two_boxes_for_ar1, steps=steps, offsets=offsets, clip_boxes=clip_boxes, variances=variances, matching_type='multi', pos_iou_threshold=0.5, neg_iou_limit=0.3, normalize_coords=normalize_coords)
generator
train_generator = train_dataset.generate(batch_size=batch_size, shuffle=True, transformations=[data_augmentation_chain], label_encoder=ssd_input_encoder, returns={'processed_images', 'encoded_labels'}, keep_images_without_gt=False) val_generator = val_dataset.generate(batch_size=batch_size, shuffle=False, transformations=[], label_encoder=ssd_input_encoder, returns={'processed_images', 'encoded_labels'}, keep_images_without_gt=False)
训练过程中的设置
model_checkpoint = ModelCheckpoint(filepath='ssd7_epoch-{epoch:02d}_loss-{loss:.4f}_val_loss-{val_loss:.4f}.h5', monitor='val_loss', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1) csv_logger = CSVLogger(filename='ssd7_training_log.csv', separator=',', append=True) early_stopping = EarlyStopping(monitor='val_loss', min_delta=0.0, patience=10, verbose=1) reduce_learning_rate = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=8, verbose=1, epsilon=0.001, cooldown=0, min_lr=0.00001) callbacks = [model_checkpoint, csv_logger, early_stopping, reduce_learning_rate]
训练设置
batch_size = 16
initial_epoch = 0 final_epoch = 50 steps_per_epoch = 500
训练的结果
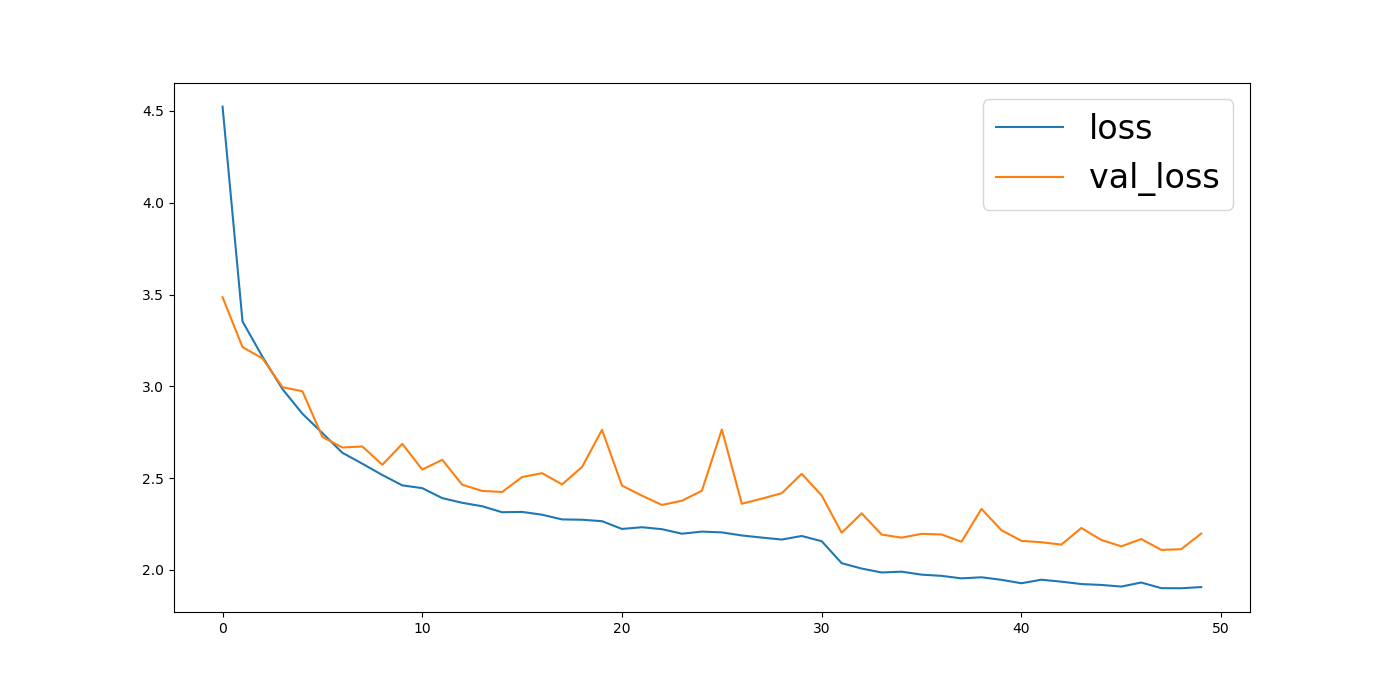
训练过程中记录的loss

可以看到最后第46个epoch并不比45次的模型准确,程序就没有保存46次训练的权重。其他也同理。
效果最好的是第48次的权重。
整体仍有下降的趋势。可以继续多训练写epoch。使模型更准确。
这是我们保存的权重文件
测试一下模型的效果
图片1
图像名: ./driving_datasets/1478899079843657225.jpg 人工标注的值: [[ 1 83 144 105 158] [ 1 124 142 138 153] [ 1 174 138 194 156] [ 1 183 139 235 178] [ 1 189 138 197 149] [ 1 209 137 219 147] [ 2 139 134 160 151]] 预测值: 类别 概率 xmin ymin xmax ymax [[ 1. 0.98 175.51 138.55 195.6 157.32] [ 1. 0.72 183.55 134.15 242. 175.66] [ 1. 0.59 80.93 142.11 108.24 158.76]]
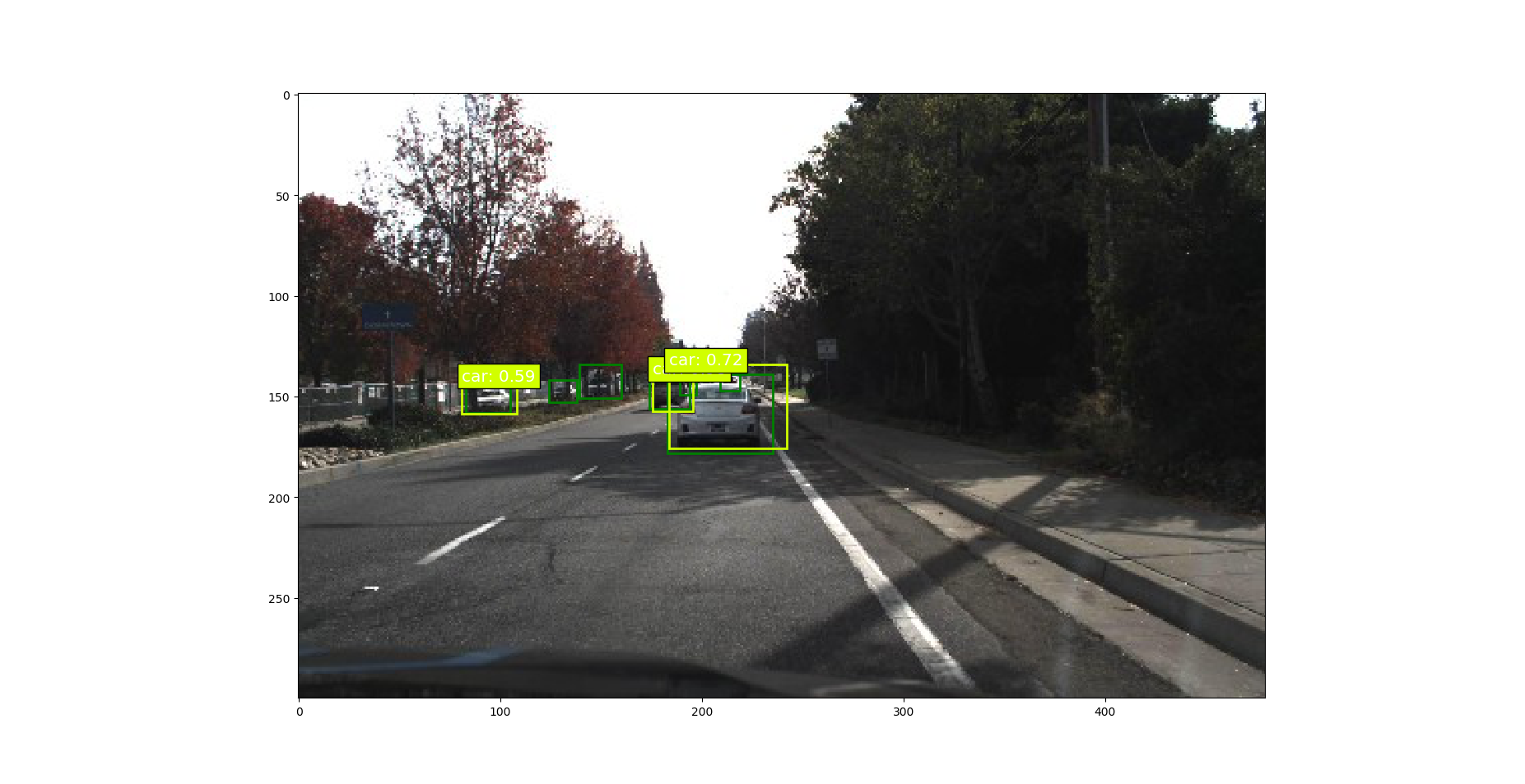
一共人工标注有6个目标。我们模型检测到其中的3个。可以看到模型对于较近的目标识别的还是比较准确的。图片中两辆车(未检测到的)距离较远而且有树木的遮挡。还有一辆距离较远 目标比较小而且有些模糊。
再试试其他图片


可以看到模型不是很准确 我们多训练些epoch.
训练更多的epoch 来提升模型的准确度
initial_epoch = 0 final_epoch = 100 steps_per_epoch = 1000
查看训练的结果
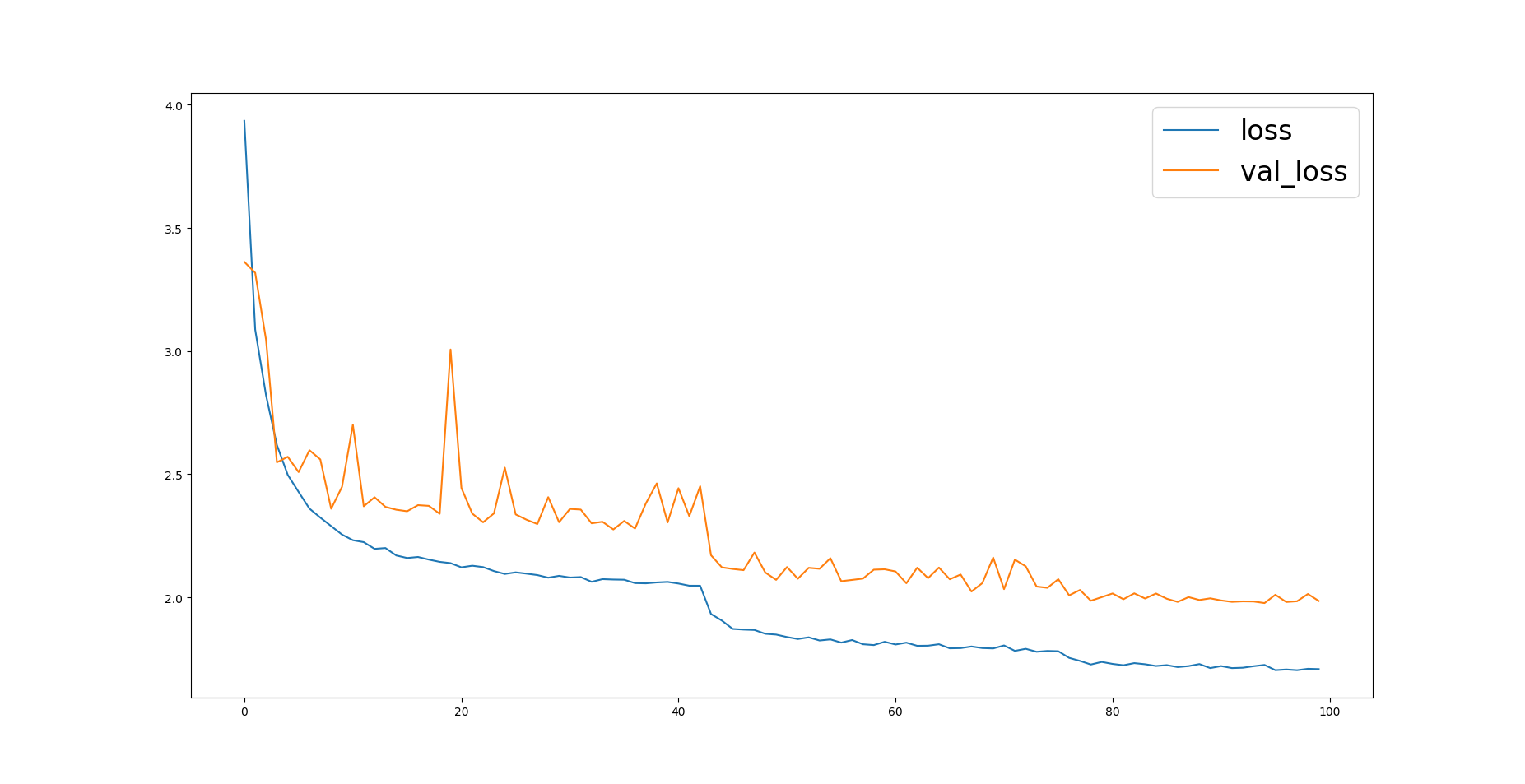

可以看到loss和之前相比与了明显的下降。
测试
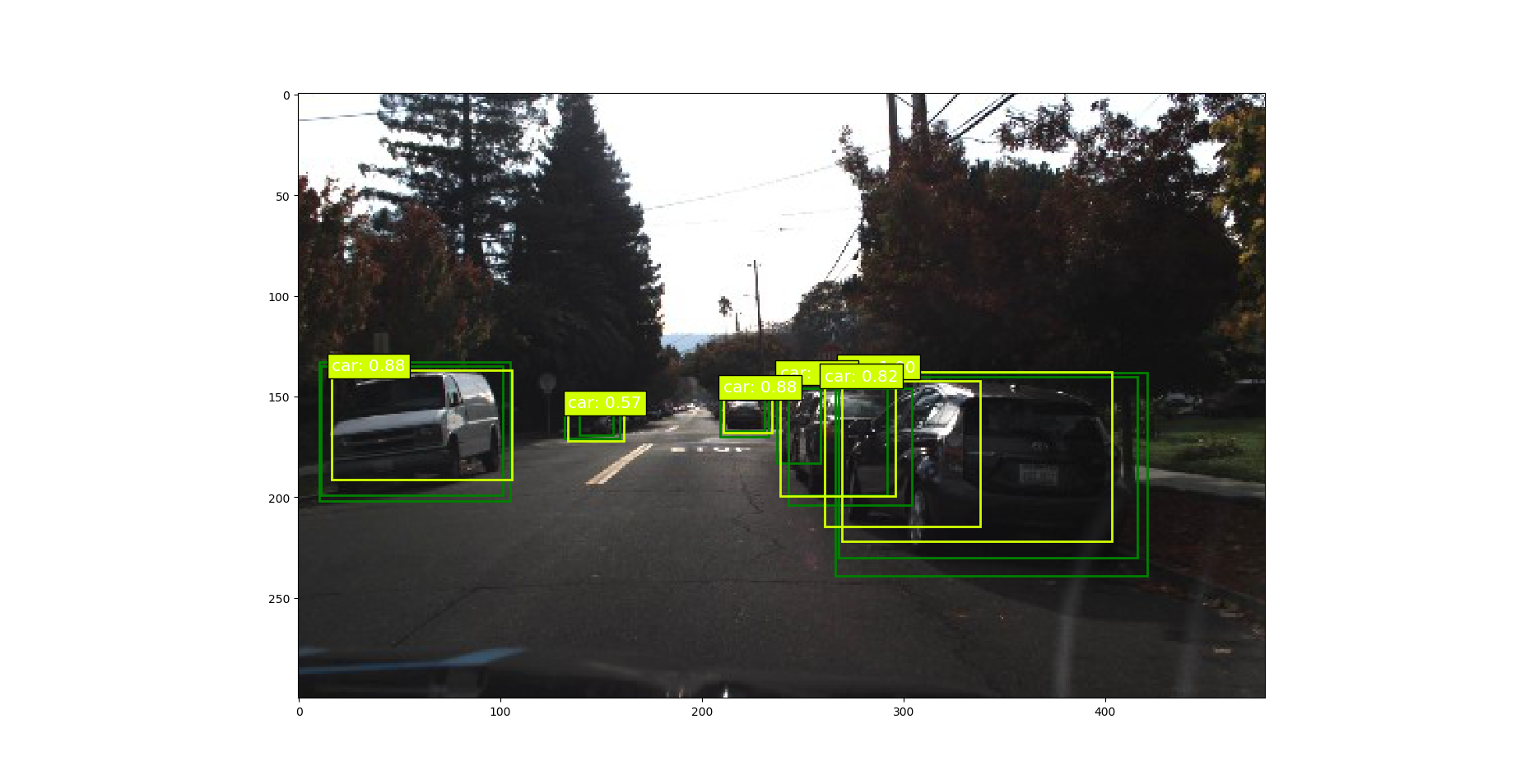
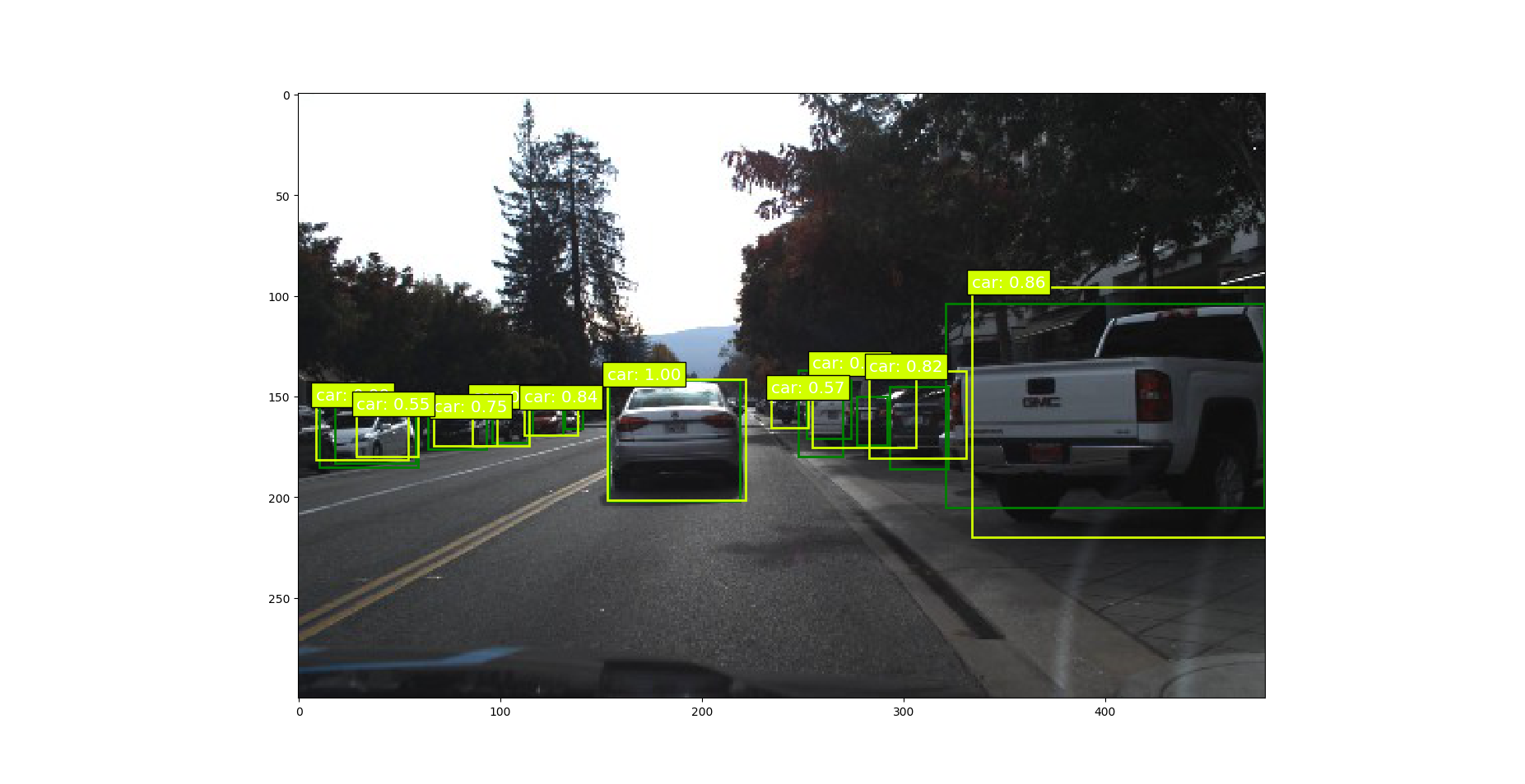
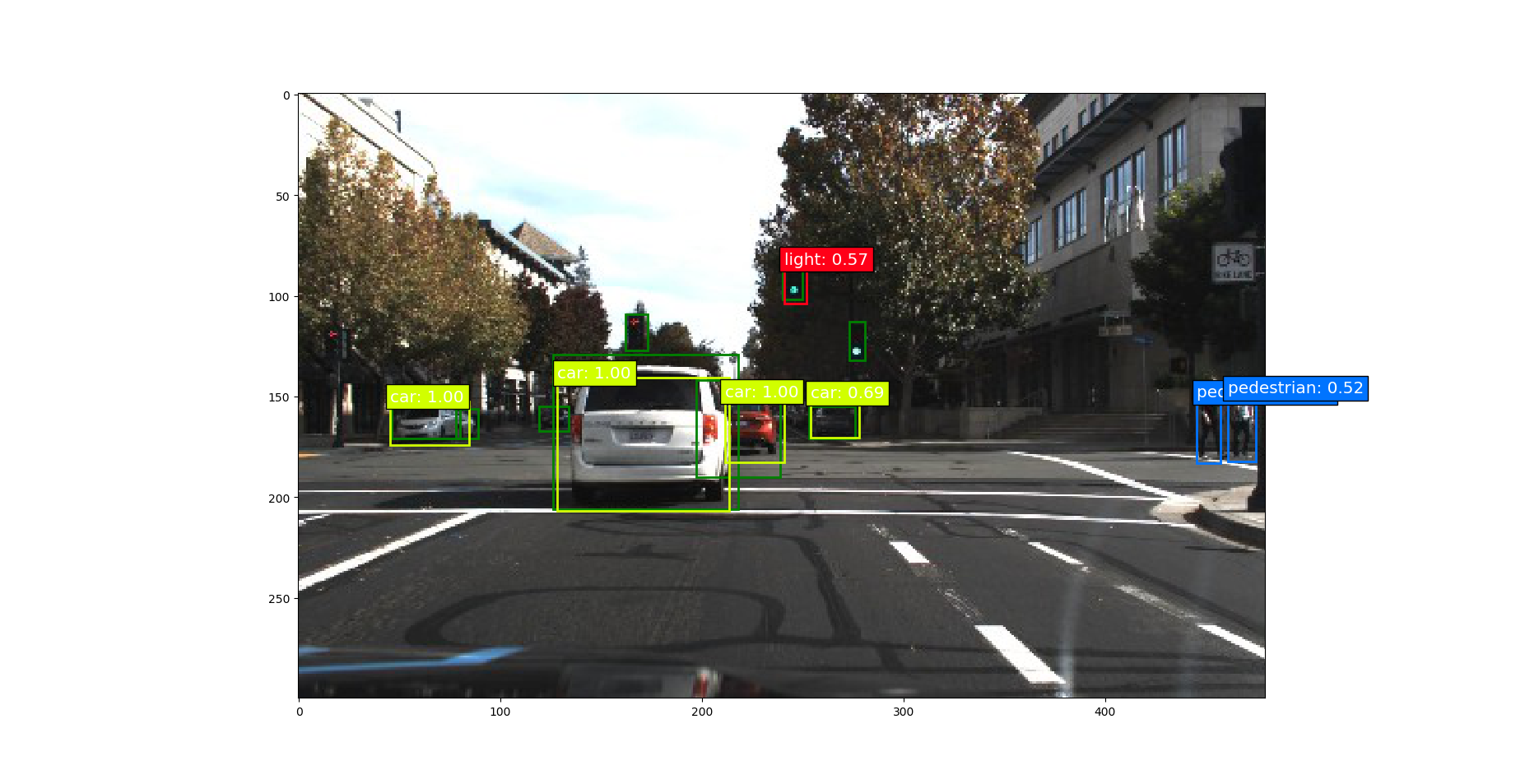
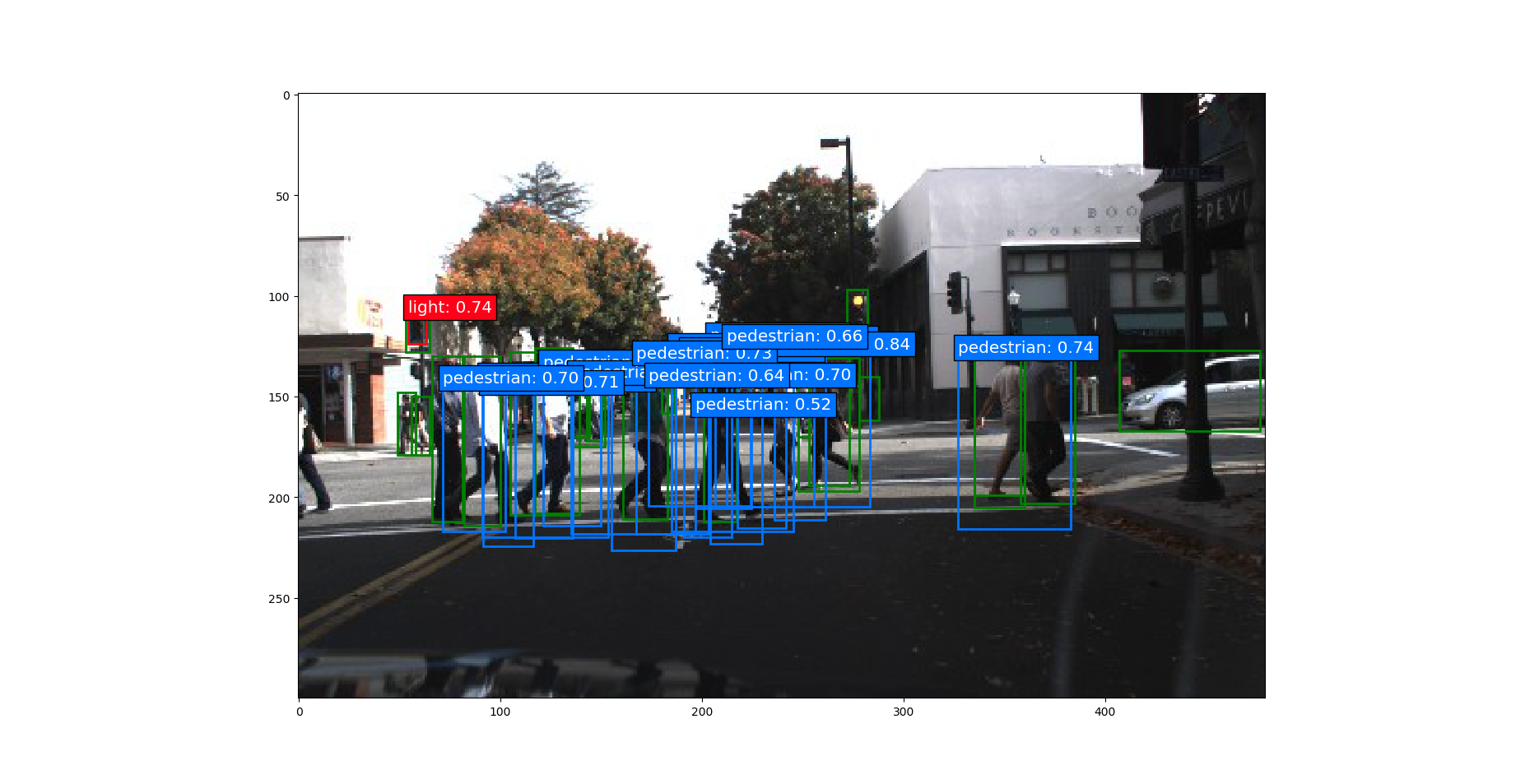
总结
1模型的loss仍然有下降的趋势,可以多训练些轮次、
2模型对远处特别小的目标很难识别,模糊的目标,遮挡的目标,还有阴影处的目标。
3数据的标注有些问题,有些交目标未标注,这对我们模型训练过程中会有干扰。

