Python数据分析之pandas入门
一、pandas库简介
pandas是一个专门用于数据分析的开源Python库,目前很多使用Python分析数据的专业人员都将pandas作为基础工具来使用。pandas是以Numpy作为基础来设计开发的,Numpy是大量Python数据科学计算库的基础,pandas以此为基础,在计算方面具有很高的性能。pandas有两大数据结构,这是pandas的核心,数据分析的所有任务都离开它们,分别是Series和DataFrame。
二、pandas库的安装
paandas安装较为简单,如果使用Anaconda的话,就在终端输入命令 “conda install pandas” 就能安装;如果电脑安装了pip的话,就在终端输入命令 “pip install pandas” 就能安装成功。安装完成后,可以在终端输入 “import pandas as pd” ,测试pandas是否安装成功。
三、Series的使用
Series用来表示一维数据结构,跟数组类似,它由两个相关联的数组组成,其中一个叫index的数组用来存储标签,这些标签与另一个数组中的元素一一对应。如下图所示:

声明Series对象时,需要调用Series()构造函数,并传入一个数组作为Series的主数组,比如:
import pandas as pd ser=pd.Series([12,33,55,66]) print(ser) '''输出为 0 12 1 33 2 55 3 66 dtype: int64 '''
运行上面的代码,可以知道,如果不指定标签,那么默认标签就是从0开始递增,我们也可以在声明一个Series对象时给它指定标签:
import pandas as pd ser=pd.Series([12,33,55,66],index=['a','s','d','f']) print(ser) '''输出为: a 12 s 33 d 55 f 66 dtype: int64 '''
我们可以通过Series的index很方便得到其内部元素,或者为某元素赋值:
import pandas as pd ser=pd.Series([12,33,55,66]) print(ser[2]) ser[2]=99 print(ser[2]) '''输出为: 55 99 '''
Series对象可以进行运算,比如加减乘除,也可以使用Numpy中的数学函数来对它进行计算:
import pandas as pd ser=pd.Series([12,33,55,66]) ser2=ser/2 print(ser2) import numpy as np print(np.log(ser)) '''输出为: 0 6.0 1 16.5 2 27.5 3 33.0 dtype: float64 0 2.484907 1 3.496508 2 4.007333 3 4.189655 dtype: float64 '''
从上面可以看出,Series对象似乎跟字典很相似,我们可以把Series对象当作字典来使用,我们在创建Series对象时,将创建好的字典传入Series的构造函数即可,这样字典的键就组成了索引数组,每个索引对应的元素就是字典中对应的值:
import pandas as pd dic={'wife':'kathy','son':'mary','mother':'lily','father':'tom'} ser=pd.Series(dic) print(ser) '''输出为: wife kathy son mary mother lily father tom dtype: object '''
四、DataFrame的使用
DataFrame这种数据结构针对的是多维数据,由按一定顺序排列的多列数据组成,列之间的数据类型会不同,如下图所示:
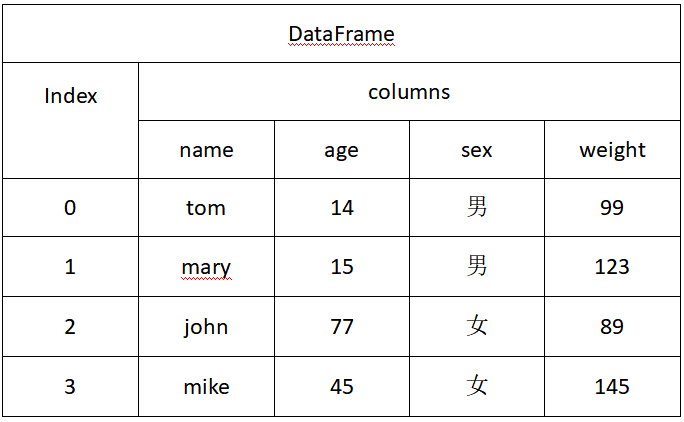
从图中可以看出,DataFrame对象有两个索引数组,第一个数组index与行相关,这与Series相似,每个index标签与所在行的所有元素相关联。它的第二个数组包含一系列标签,每个标签下包含一列数据。可以将DataFrame理解为由多个Series对象组成的字典,每一列的名称为字典的键,Series作为字典的值。
创建DataFrame对象的常用方法就是传递一个字典对象给DataFrame()构造函数:
import pandas as pd dic={'name':['tom','mary','john','mike'],'age':[14,15,77,45],'sex':['男','男','女','男']} frame=pd.DataFrame(dic) print(frame) '''输出为: name age sex 0 tom 14 男 1 mary 15 男 2 john 77 女 3 mike 45 男 '''
跟Series对象类似。DataFrame如果没有明确指定标签,那么它的默认标签也是从0开始递增。如果我们想知道DataFrame对象所有列的名称,则调用columns属性就可以了,获取索引列表的话就调用index属性,调用values属性将获取所有的元素。可以给DateFrame对象添加列:
import pandas as pd dic={'name':['tom','mary','john','mike'],'age':[14,15,77,45],'sex':['男','男','女','男']} frame=pd.DataFrame(dic) frame['weight']=[89,99,145,123] print(frame) '''输出为: name age sex weight 0 tom 14 男 89 1 mary 15 男 99 2 john 77 女 145 3 mike 45 男 123 '''
在数据处理中,有有时也会用到DataFrame的转置操作,即把行变为列,列变为行,调用DataFrame的T属性即可完成转置:
import pandas as pd dic={'name':['tom','mary','john','mike'],'age':[14,15,77,45],'sex':['男','男','女','男']} frame=pd.DataFrame(dic) print(frame.T) '''输出为: 0 1 2 3 name tom mary john mike age 14 15 77 45 sex 男 男 女 男 '''
五、Series与DataFrame对象之间的运算
pandas允许Series对象与DataFrame对象进行运算,定义Series和DataFrame对象时,把Series对象的索引和DataFrame的列名称保持一致:
import pandas as pd import numpy as np frame=pd.DataFrame(np.arange(16).reshape((4,4)),index=['age','name','sex','weight'],columns=['john','tom','mary','cathy']) print(frame) ser=pd.Series(np.arange(4),index=['john','tom','mary','cathy']) print(ser) res=frame-ser print(res) '''输出为: john tom mary cathy age 0 1 2 3 name 4 5 6 7 sex 8 9 10 11 weight 12 13 14 15 john 0 tom 1 mary 2 cathy 3 dtype: int32 john tom mary cathy age 0 0 0 0 name 4 4 4 4 sex 8 8 8 8 weight 12 12 12 12 '''
可以看出,DataFrame对象的各元素分别减去了Series对象中索引与之相同的元素,DataFrame对象每一列的所有元素都执行了减法操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号