

DBMS(mysql)
Navicat快捷键
运行全部代码: Crtl +R
运行选中代码: Crtl + Shift +R
DDL:
对数据库的操作:
创建数据库操作:create database 数据库名 or create database if not exists 数据库名
显示数据库操作:show databases;
删除数据库操作:drop database 数据库名 or drop database if exists 数据库名
使用数据库操作: use 数据库名
对表的操作:
查询表:show tables; 查询表结构: desc 表名
创建表:create table 表名 ( 字段名1 数据类型1,
字段名2 数据类型2 ........
);
删除表:drop 表名; or drop if exists 表名;
修改表:
修改表名:alter table 表名 rename to 新的表名;
添加列 alter table 表名 add 列名 数据类型;
修改数据类型 alter table 表名 modify 列名 新数据类型;
修改列名和数据类型 alter table change 列名 新列名 新数据类型;
删除列 alter table 表名 drop 列名
# sql里的数据类型:
数值类型:整型 tinyint(1B),smallint(2B) ,mediumint(3B),int(4B),bigint(8B),float(4B),double(8B)
日期和时间类型:date,time,year,datetime,timestamp
字符串类型:char(定长),varchar(不定长)
DML
添加数据
给指定列添加数据 insert into 表名(列1,列2......) values(值1,值2....)
给全部列添加数据 insert into 表名 values(值1,值2....);
批量添加数据 insert into 表名(列名1,列名2.....) values(值1,值2),(值1,值2),(值1,值2)....;
insert into 表名 values(值1,值2,.....),(值1,值2,.......),.....;
修改数据
update 表名 set 列名='值' [where 条件];
删除 delete from 表名 where 条件
DQL(查询,比较复杂却最常用)
查询语法
select 字段列表 from 表名列表 where 条件列表 group by 分组字段 having 分组后条件 order by 排序字段 limit 分页限定
起别名 :as 关键字
条件查询: select * from 表名 where 列名 between A and B ;
不等号 :!= ,<>
或者 :or , in(A,B,C);
null值得比较不能用== 或 != 比较 要用 is 或者是 is not;
特殊查询:例如 要查询 姓马的人 则 查询条件为 where name(列名) like '马%';
第二个字是花 where name like '_花%';
名字里含德的人 where name like '%德%';
排序查询:升序 select * from users(表名) order by age(列名) asc(升序);
降序 select *from users(表名) order by age(列名) desc(降序);
分组查询(group by): 聚合函数:select 聚合函数(列名) from 表名;
count(列名):统计数量; select count(列名) from 表名; -- count 统 计内容不能为空
max(列名):最大值; select max(列名) from 表名;
min(列名):最小值;
sum(列名):求和;
avg(列名):求平均值
分组查询: select 字段列表 from 表名 where 条件 group by 分组字段名 having 分组后条件过滤;
select id,username from users from group by id
select id,username,count(*) from users from group by id
select id,username from users from where id!= 1 group by id
select id,username from users from where id!= 1 group by id having id>2
where 和 having 之间的区别: where 分组前执行 以where 后的条件进行分组 ;having 是在分组之后对已分组德内容进行过滤
执行顺序: where > 聚合函数 > having
分页查询:select 字段列表 from 表名 limit 起始索引, 查询条目数;
-- 从0开始,查三条
select * from users limit 0,3;
-- 在对数据库进行分页后 可以使数据分页。
约束:
约束的概念:
1.约束是作用于表中列上的规则,用于限制加入表中的数据。2.约束保证了数据库中数据德正确性、有效性和完整性。
约束的分类:
1.非空约束 not null
2.唯一约束 unique
3.主键约束 primary key
4.检查约束 check mysql 不支持检查约束
5.默认约束 default
6.外键约束 foreign key 两个表之间简历连接
外键约束: create table 表名(
列名 数据类型 ,
......
[constraint] [外键名称] foreign key (外键类名) references 主表(主表列名));
建表后: alter table 表名 add constraint 外键名称 foreign key (外键字段名称) references 主表(主表列名);
数据库设计
简介
(产品经理) (架构师) (开发工程师) (测试工程师) (运维工程师)
软件研发步骤:需求分析 —》 设计 —》 编码—》 测试—》 安装步骤
(产品原型) (软件结构设计) (数据库设计) (接口设计) (过程设计)
数据库设计概念
建立数据库中的表结构 以及 表与表之间的关联关系
有那些表?表与表之间的关系?
数据库设计步骤
1.需要分析。
2.逻辑分析。 E-R图
3.物理设计。根据数据库的特点把逻辑设计转换为物理设计(表)
4.维护设计。
表关系之一对多
例如:部门与员工
表关系之多对多
例如:商品和订单
可以建立一个第三方中间表 该中间表 确立两个外键 分别关联其他两个表的对应主键。
表关系之一对一
例如:用户 和 用户详情
将一个整表进行拆分, 设置一个唯一外键 将表与表之间进行关联
数据库设计案例
专辑案例分析:
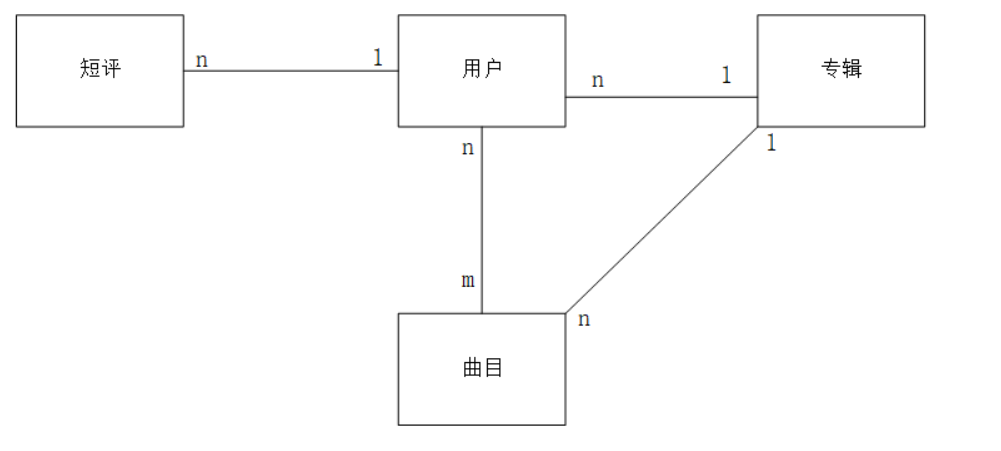
多表查询
select * from emp,dept; -- 从两条表查询 这样查出来的数据 是两表的笛卡尔积
可以使用where 语句判断(内连接),如
select * from emp,dept where emp.id ==dept.id;
内连接
隐式内连接: 使用 where 语句 可以给表起别名
显示内连接: select * from emp inner join dept on emp.dep_id = dept.did;
外连接
select 字段列表 from 表1 left [outer] join 表2 on 条件;
子查询
嵌套查询方法;在查询方法里嵌套有查询作为条件判断;
子查询: select * from emp where salary >(select salary from emp where name = '猪八戒'));
事务
数据库的事务是一种机制、操作序列,包含一组命令;
开启事务:数据库可以按命令进行操作;start transaction 或者begin 在当前sql中数据会发生变换,而在其他用户查询时不会发生变换
提交事务:在提交事务后,数据库可以执行开启事务中的假设性命令;commit
回滚事务:开启事务中的命令出现异常,事务回滚。roolback
事务四大特征
原子性;事务是不可分割的最小操作单位,要么同时成功,要么同时失败。
一致性;事务完成时,必须使所有数据都保持一致状态
隔离性;多个事务之间,操作的可见性
持久性;事务一旦提交或回滚,他对数据库中的数据的改变就是永久的。一般的命令 是自动提交的 select @@autocommit =0; -- 该语句可以修改提交方式,使之变为手动提交。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程