Windows 10 + Cuda 8.0 + vs 2013 环境搭建
小白一个,从开始从老师那里听说了GPU编程这一回事,回去就自己尝试配置编程环境。虽然在博客上看了大佬们的教程,对我这个菜鸟来说很困难,感觉不是很详细。
按照其中一个的教程配置了不下10次,我同学的是配置好了,但是我的怎么都运行不了。
但在我的坚持下,环境总算是搭建成功了,我这篇博客主要参考了 https://blog.csdn.net/kyocen/article/details/51424161 和 https://blog.csdn.net/qq_31932151/article/details/76430184 两篇博客,感谢大佬们的帮助!!!
我就用我亲身体验,写下这篇博客,以供初学者参考,希望大家能指出其中不足之处,谢谢!
我的电脑配置是Windows 10 家庭版64位
一、准备工作
1.下载Cuda
1.查看你的显卡是否支持Cuda
https://developer.nvidia.com/cuda-gpus 如果能在这个页面中能找到你的GPU,便支持Cuda
2.查看GPU支持最高版本Cuda
打开 NVIDIA控制面板——帮助——系统信息——组件
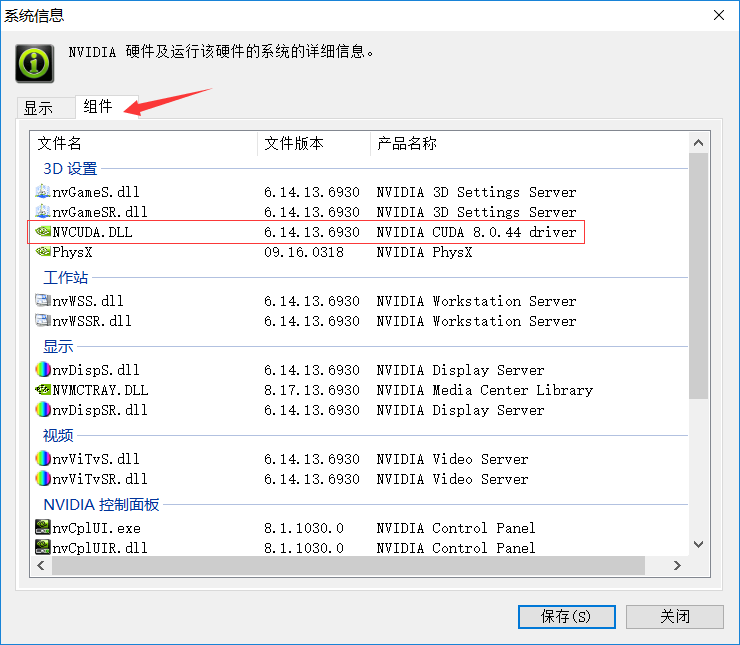
我得显卡是NVIDIA GeForce GTX 950M,最高可以支持到 Cuda 8.0.44
3.下载Cuda
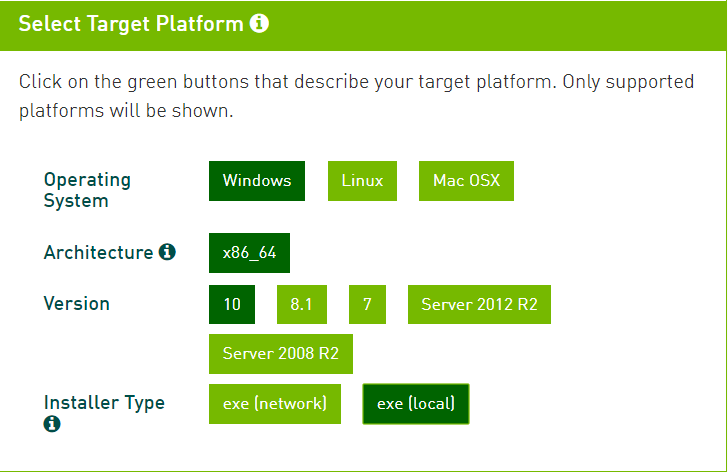
去官网下载对应的版本的Cuda
https://developer.nvidia.com/cuda-toolkit-archive
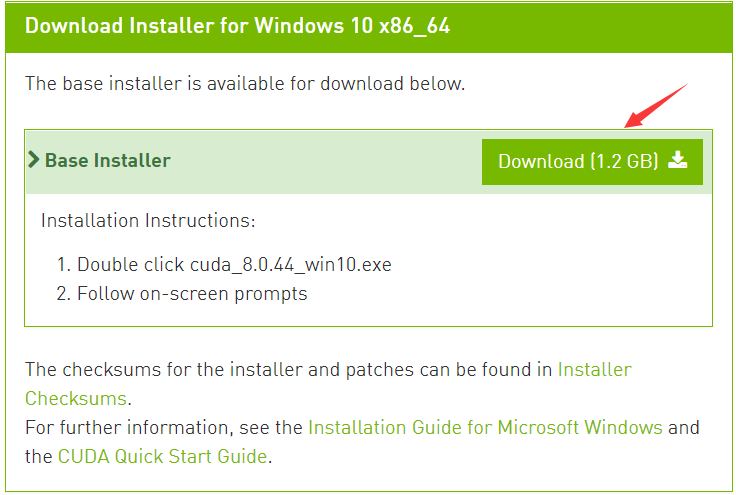
选择好正确的平台下载
2.下载vs2013
可以去官网:https://visualstudio.microsoft.com/vs/older-downloads/ 登陆微软账号后下载,或者去msdn:https://msdn.itellyou.cn/ 下载 vs2013
二、安装
1.安装vs2013
按照步骤安装就行
2.安装Cuda
自定义安装
全选
然后等待一段时间,时间比较长
三、配置
1.配置系统环境变量
右键此电脑——属性——高级系统设置——环境变量——系统变量——新建

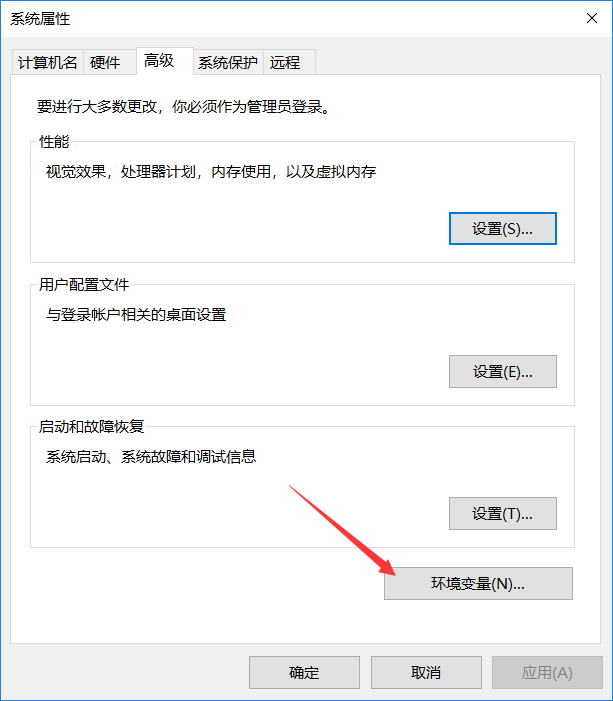
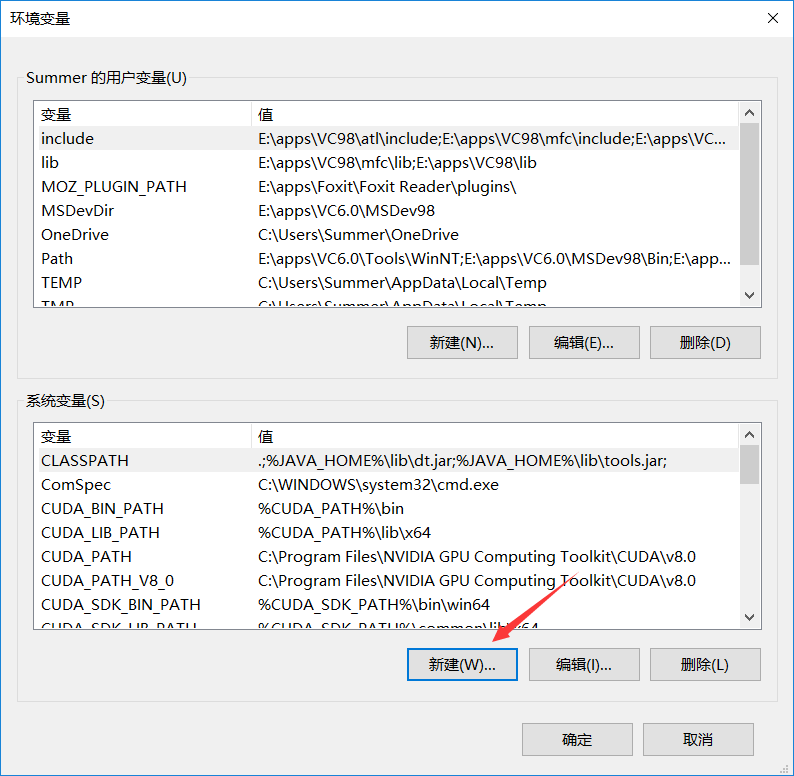
| 变量名 | 变量值 |
| CUDA_BIN_PATH | %CUDA_PATH%\bin |
| CUDA_LIB_PATH | %CUDA_PATH%\lib\x64 |
| CUDA_PATH | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0 |
| CUDA_PATH_V8_0 | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0 |
| CUDA_SDK_BIN_PATH | %CUDA_SDK_PATH%\bin\win64 |
| CUDA_SDK_LIB_PATH | %CUDA_SDK_PATH%\common\lib\x64 |
| CUDA_SDK_PATH | C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0 |
添加系统变量,将以上变量名和变量值分别添加到系统变量里面
找到Path系统变量
编辑——新建
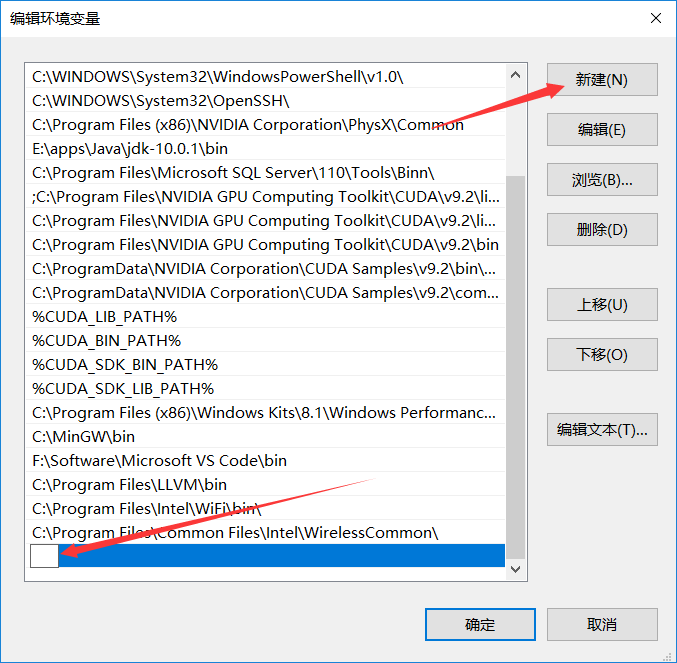
分别把
%CUDA_LIB_PATH%
%CUDA_BIN_PATH%
%CUDA_SDK_BIN_PATH%
%CUDA_SDK_LIB_PATH%
添加进去
添加完毕后,切记重启电脑使系统环境变量生效!!
2.配置vs2013
1.创建一个Visual C++ 空项目
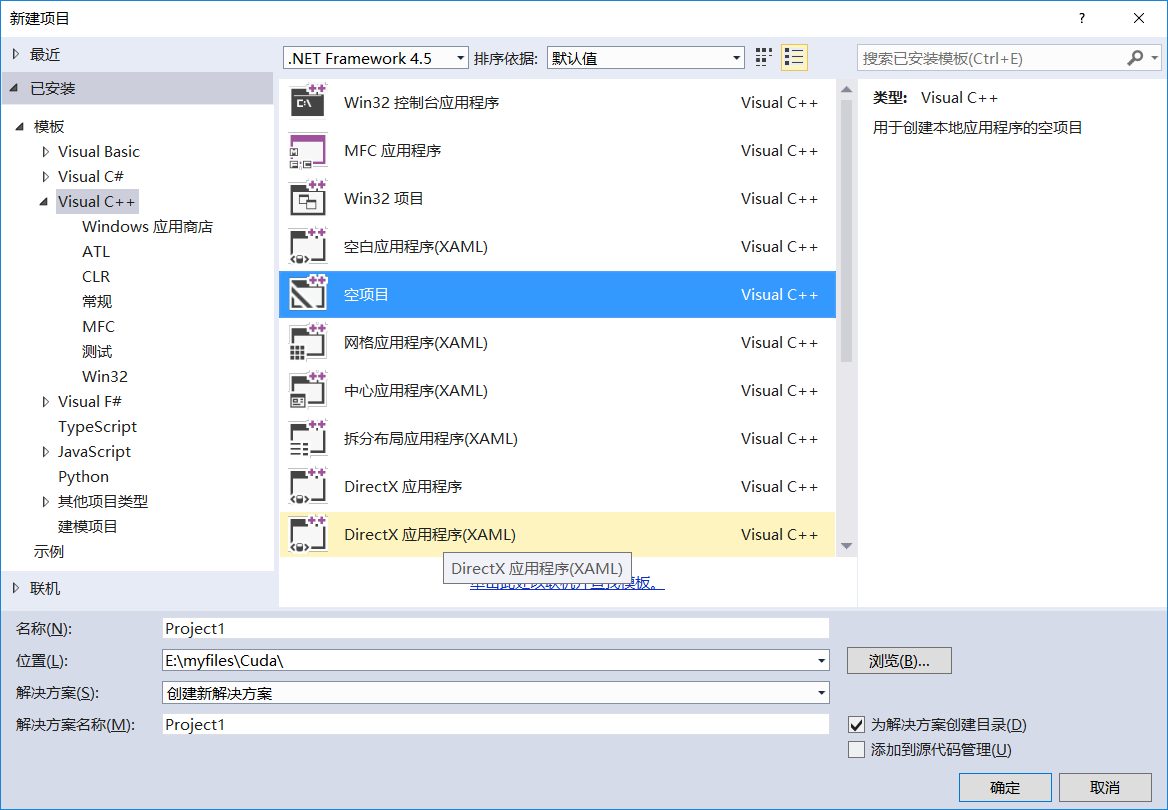
2.添加源文件右键源文件——添加——新建项
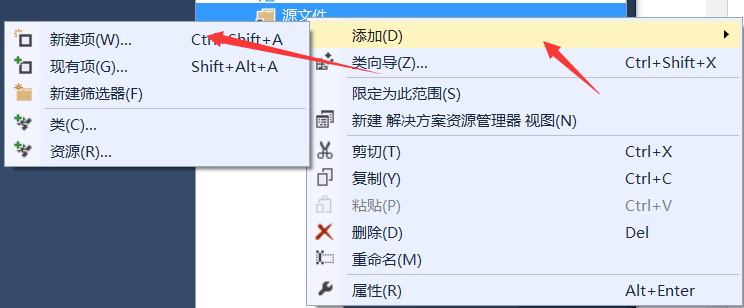
把 .cpp后缀改为.cu,取名为test
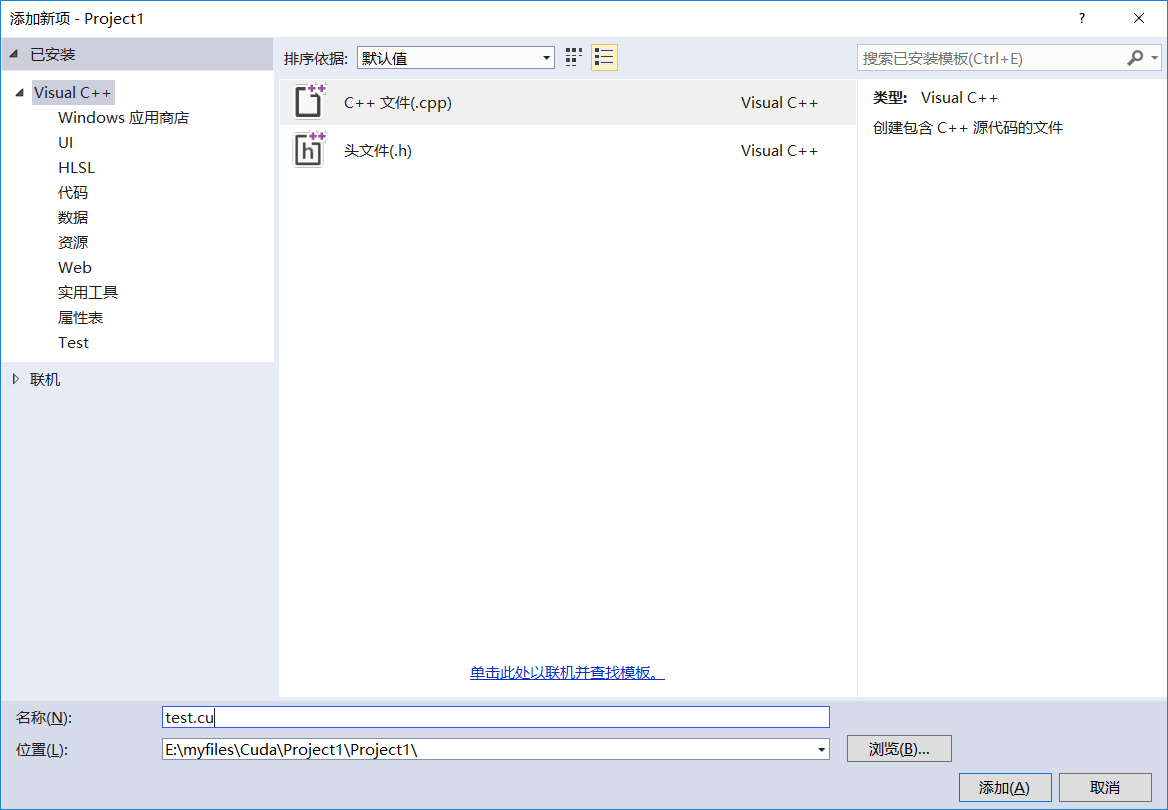
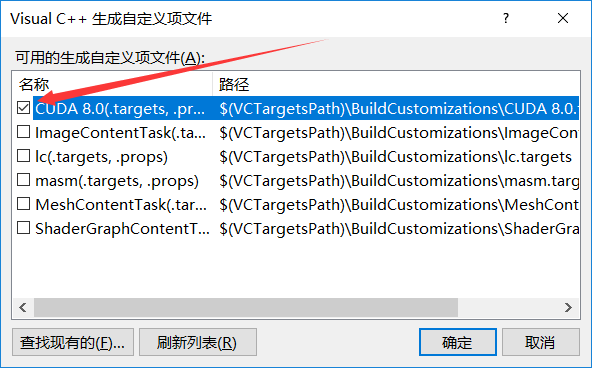
3.右键工程——生成依赖项——生成自定义
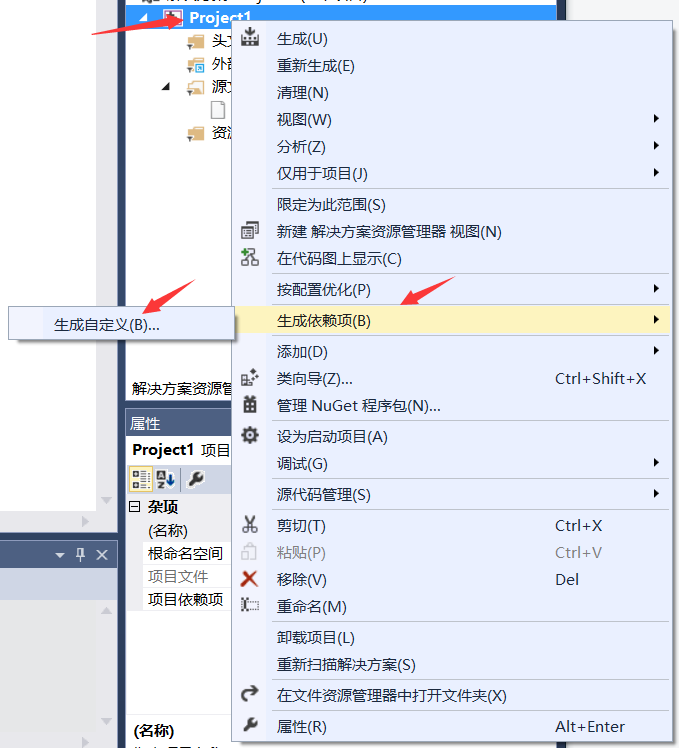
4.选择Cuda 8.0
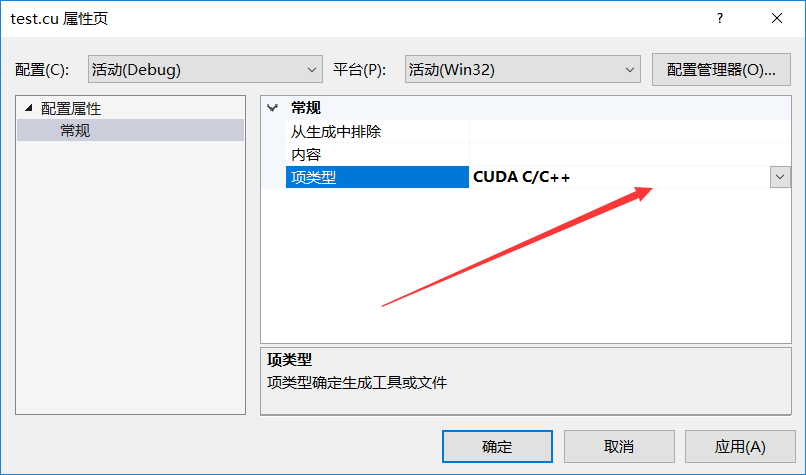
5.右键源文件:test.cu——>属性,打开属性对话框,在常规属性页下, 将项类型改为:CUDA C/C++
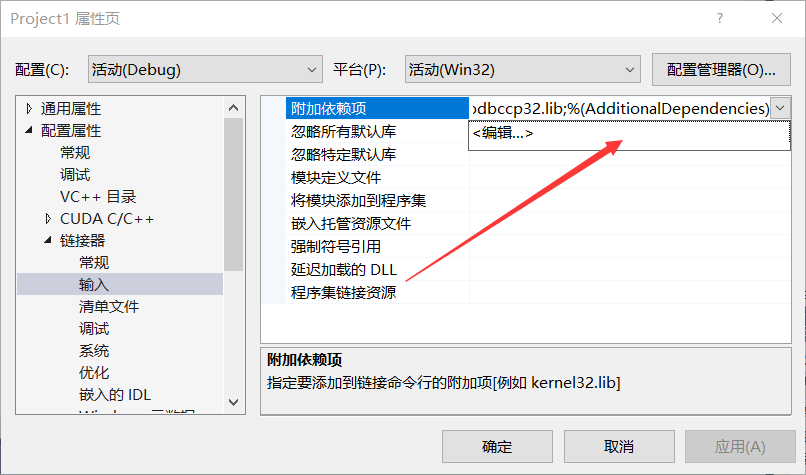
6.右键工程——>属性——>配置属性——>链接器——>输入——>附加依赖项。
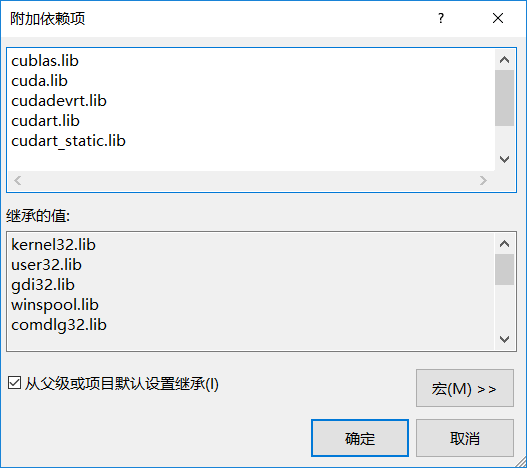
cublas.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
nvcuvid.lib
OpenCL.lib
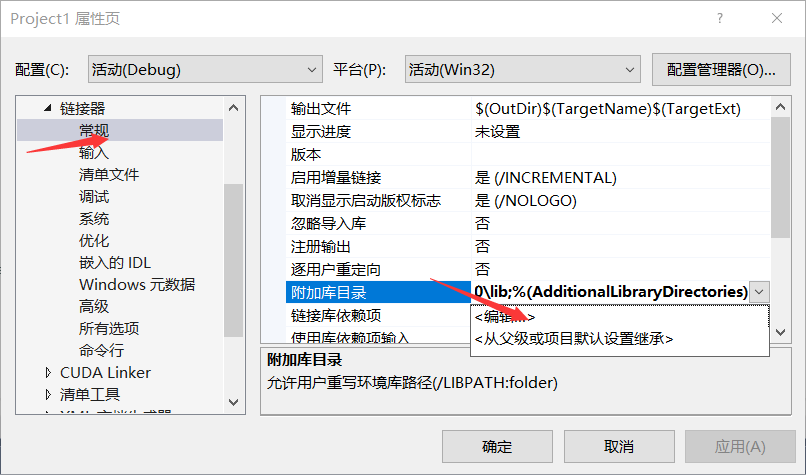
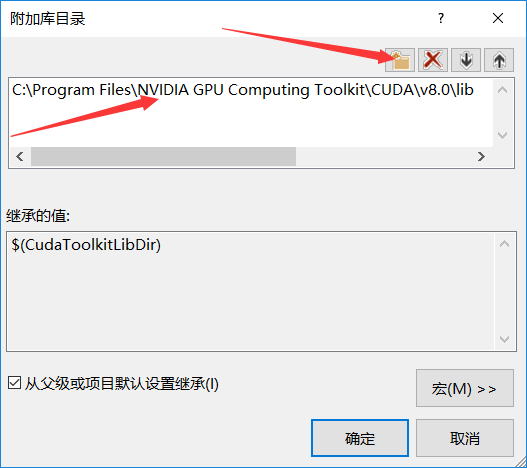
7.然后点击“常规”——>附加库目录
我的库目录为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib ,图如下

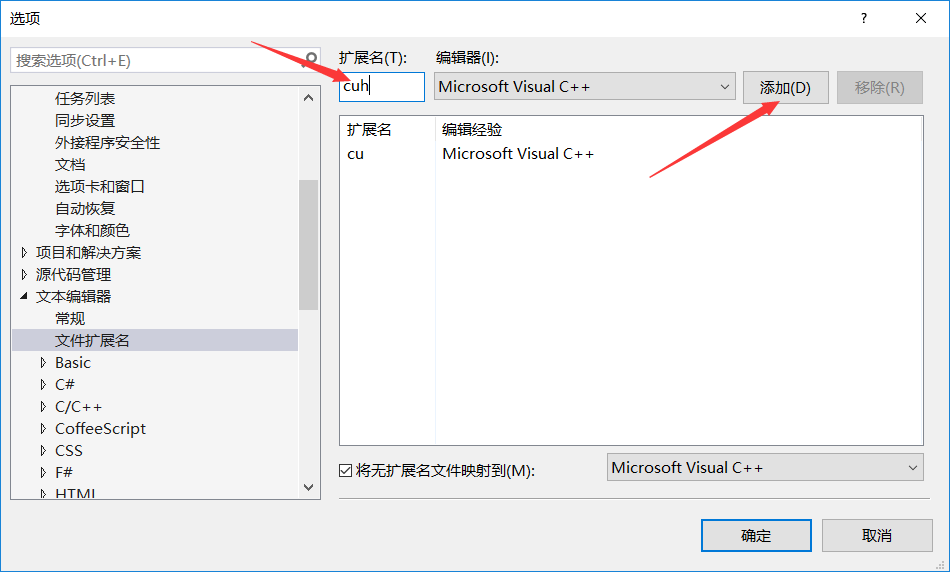
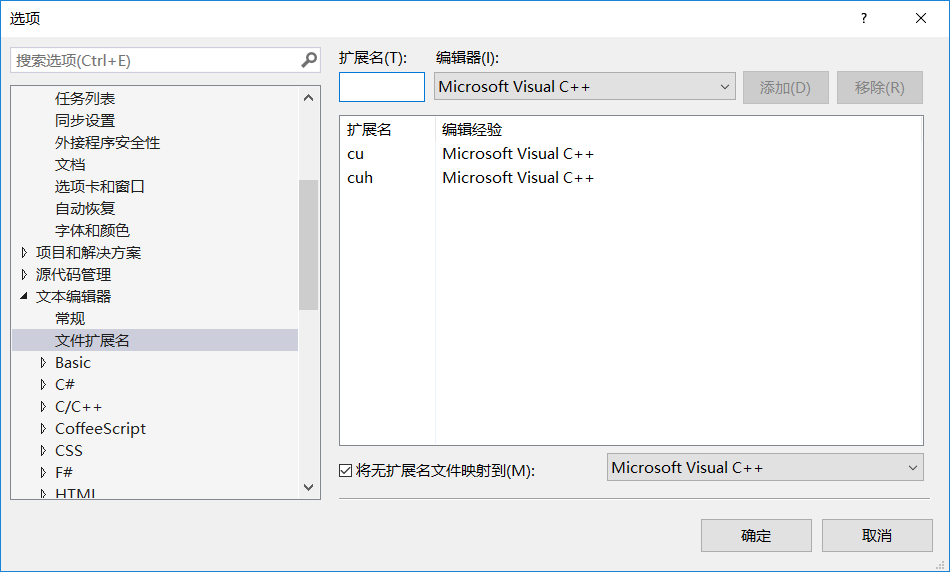
8.工具——选项——文本编辑器——文件扩展名——>添加cu \cuh两个文件扩展名
9..cu文件中C/C++关键字高亮
让CUDA的关键字,如__device__、dim3之类的文字高亮,头文件中引入device_launch_parameters.h文件
10.简单测试
#include <iostream> #include "cuda_runtime.h" #include "device_launch_parameters.h" using namespace std; __global__ void add(int a, int b, int *c) { *c = a + b; } int main(){ int c; int *dev_c; cudaMalloc((void**)&dev_c, sizeof(int)); add << <1, 1 >> >(2, 7, dev_c); cudaMemcpy(&c, dev_c, sizeof(int), cudaMemcpyDeviceToHost); cout << "2+7=" << c << endl; cudaFree(dev_c); system("pause"); return 0; }
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号