

数据转换:split-apply-combine模式
本文主要介绍数据转换中的split-apply-combine模式,包括baseR、plyr中的相关函数的应用。
split-apply-combine模式
大型数据集通常是高度结构化的,结构使得我们可以按不同的方式分组,有时候我们需要关注单个组的数据片断,有时需要聚合不同组内的信息,并相互比较。
因此对数据的转换,可以采用split – apply – combine模式来进行处理:
split:把要处理的数据分割成小片断;
apply:对每个小片断独立进行操作;
combine:把片断重新组合。
利用这种模式解决问题在很多数据分析或编程问题中都会出现:
Python当中,是map( ),filter( ),reduce( );
Google 有MapReduce;
R 当中是split( ),*apply( ),aggregate( )…,以及plyr包。
baseR
在R当中,split这个步骤是由split( ),subset( )等等函数完成的。
函数split()可以按照分组因子,把向量,矩阵和数据框进行适当的分组。它的返回值是一个列表,代表分组变量每个水平的观测。这个列表可以使用sapply(),lappy()进行处理(apply – combine步骤),得到问题的最终结果。
split( )的基本用法是:group <- split(X,f),其中X 是待分组的向量,矩阵或数据框。f是分组因子。
split还有一个逆函数,unsplit,可以让分组完好如初。
在base包里和split功能接近的函数有cut(对属性数据分划),strsplit(对字符串分划)以及
subset(对向量,矩阵或数据框按给定条件取子集)等。
接下来的apply – combine步骤主要由apply函数族完成。
apply :Apply Functions Over Array Margins
by :Apply a Function to a Data Frame Split by Factors
eapply :Apply a Function Over Values in an Environment
lapply :Apply a Function over a List or Vector
mapply :Apply a Function to Multiple List or Vector Arguments
rapply :Recursively Apply a Function to a List
tapply :Apply a Function Over a Ragged Array
除此之外,还有可作为lapply变形的sapply,vapply和 replicate,共计10个函数。

- apply函数通过对数组,矩阵,或非空维数值的数据框的“边缘”(margin)即行或列运用函数。返回值为向量,数组或列表。
函数形式
apply(X, MARGIN, FUN, ...)
其中,X:数组(矩阵);
MARGIN:函数要作用的下标向量,对于矩阵,1表示行,2表示列,1:2表示行和列;
FUN:函数名或函数表达式。
- by函数是tapply的一个面向用户的友好包装版,是一个使用因子来对数据框按行进行分组并对每个子集运用函数的方法。它的对象数据被默认强制转换为数据框。它返回一个 类属性为by的对象,simplify i= false是,返回值是列表,否则是列表或数组。
by(data, INDICES, FUN, ..., simplify = TRUE)
参考:
https://site.douban.com/182577/widget/notes/10567181/note/245088040/
https://site.douban.com/182577/widget/notes/10567181/note/245242931/
plyr包
plyr包可以针对不同的数据类型,在一个函数内同时完成split-apply-combine三个步骤,从而实现最大限度的高效和简洁。plyr包特别适合处理大型数据集问题,比如对空间数据的空间位置或时间序列面板数据的时间点建模,或者在高维数组中进行数据探索等等。
plyr的基本函数集如下:
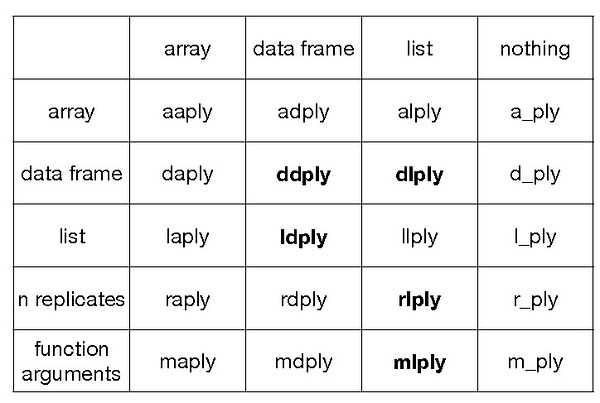
命名规则:前三行是基本类型。
根据输入类型和输出类型:a=array,d=data frame,l=list,_表示输出放弃。第一个字母表示输入,第2个字母表示输出。
后两行是对应apply族的replicates和mapply这两个函数,分别表示n次重复和多元函数参数的情况,第2个字母还是表示输出类型。
参数说明:这些函数有两到三个主要参数,依赖于输入的类型:
- a*ply( .data, .margins, .fun, ..., .progress = "none")
- d*ply( .data, .variables, .fun, ..., .progress = "none")
- l*ply( .data, .fun, ..., .progress = "none")
参数.data是我们要用来分片-计算-合并的;参数.margins或者.variables描述了分片的方式;
参数.fun表示用来处理的函数,其它更多的参数是传递给处理函数的;参数.progress用来控制显示一个进度条。
本来是搞不清楚这几个函数到底有哪几个参数的,实在不好记。但是其实认真思考的话,才懂得上面所说的(主要参数依赖于输入类型)的意思,就例如输入类型时向量a时,其分片的话只能按照维度分,于是便有了.margins参数,输入类型为数据框d时,分片只能是某一个特征向量.variables,而列表的分片只能是其元素了,唯一确定,便不需指定了。
输入类型有三种,每一种类型给出了如何进行分片的不同方法。
简单来说:
a*ply( ):数组(包括矩阵和向量)按维数分为低维的片。
d*ply( ):数据框被变量组合分成子集。
l*ply( ):列表的每个元素就是一个分片。
因此,对输入数据集的分片,不是取决于数据的结构,而是取决于所采用的方法。
一个对象采用a*ply( )分片必须对应dim( )且接受多维的索引;采用d*ply( )分片,要利用split( )并强制转换为列表;采用l*ply( ),需要用length() and [。
所以数据框可以被传递给a*ply( ),可以象2维的矩阵那样处理,也可以传递给l*ply( ),被视为一个向量的列表。
三种类型各自的特点:
(a): 输入数组(a*ply( ))
a*ply( )的分片特点在于.margins参数,它和apply很相似。
对于2维数组,.margins可以取1,2,或者c(1:2),对应2维数组的3种分片方式。
如图,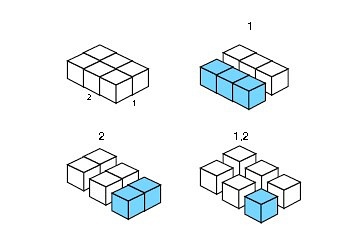
对于3维数组,则有7种分片方式:
.margins对应更高维的情况,可能会面临一种爆发式的组合。
(b)输入数据框(d*ply( ))
使用d*ply时,需要特别指定分组所用的变量或变量函数,它们会被首先计算,然后才是整个数据框。
有下面几种指定方式:
- (var1)。按照变量var1的值来对数据框分组
- 多重变量
- .(a,b,c)。将按照三个变量的交互值来分组。这种形式输出的时候,有点复杂。如果输出为数组,则数组会有三个维度,分别以a,b,c的值作为维数名。如果输出为数据框,将会包含a,b,c取值的三个额外的列。如果输出为列表,则列表元素名为按周期分割的a,b,c的值。
- 作为列名的字符向量:c("var1", "var2")。
- 公式~ var1 + var2。
(c)输入列表(l*ply( ))
l*ply( )不需要描述如何分片的函数,因为列表本身就是按照元素的分划。使用l*ply( )相当于a*ply( )作用于一维数组的效果。
参考:
https://site.douban.com/182577/widget/notes/10567181/note/246634257/
https://site.douban.com/182577/widget/notes/10567181/note/246993843/
plyr案例:https://site.douban.com/182577/widget/notes/10567181/note/251668932/
https://site.douban.com/182577/widget/notes/10567181/note/252096396/
